新冠知识图谱构建与问题记录
文章目录
- 新冠知识图谱构建与问题记录
- 开始前的安装工作
- 问题(1)描述:shell可import,pycharm报no modul
- 问题(2)描述:个别module飘红
- 问题(3)描述:目前学习方向
- 问题(4)描述:valueError
- 问题(5)描述:ModuleNotFoundError
- 问题(6)描述:没有data
- 问题(7)描述:neo4j相关问题
- 启动问题
- 导入问题
- 问题(8)描述: 运行data.py
- 问题(9)描述:基于特征融合的中文知识库问答方法阅读记录
- abstract
- introduction
- methods
- 问题(10)描述:论文阅读的有关问题
- 问题(11)描述:基于预训练语言模型的检索-匹配式知识图谱问答系统阅读记录
- Abstract
- Introduction
- Plan to introduce
- 实体链接
- 候选答案和答案路径生成
- 答案路径排序模块
- 问题(12)描述:对于9,11两篇论文的对比
- 流程的异同
- 细节对比
- 问题(13)描述:对项目流程的解析
- data.py数据准备阶段
- 数据导入数据库
- manage.py模型训练
- qa.py问答阶段
- 总结
- 完成情况
- 遗留问题
项目地址
开始前的安装工作
-
pycharml连接github
login登录报错,可使用token登录。 -
安装Anaconda3
-
在命令行输入python出现“Warning:This Python interpreter is in a conda environment, but the environment has not been activated. Libraries may fail to load. To activate this environment please see https://conda.
-
问题延续:
不过遗憾的是,该方法并不能彻底解决该问题,下次打开还是会出现该错误。
接着仔细看了一下先输入activate进入anaconda设定的虚拟环境中,在输入python即可。
Anaconda可以看作是一个python解释器的管理工具。
-
-
安装深度学习工具
- 用Anaconda3创建虚拟环境,python=3.6
conda create -n software_training python = 3.6 - 切换环境
activate software_training - 安装tensorflow-gpu
conda install tensorflow-gpu=2.1.0
输入pip show tensorflow,显示具体信息,即安装成功。
输入import tensorflow,无报错,即安装成功。 - 下载pytorch1.4.0。
conda install pytorch=1.4.0 -c soumith
输入import torch,无报错,即安装成功。
- 用Anaconda3创建虚拟环境,python=3.6
项目名称:新冠知识图谱构建与问答
时间:2021年5月21日星期三
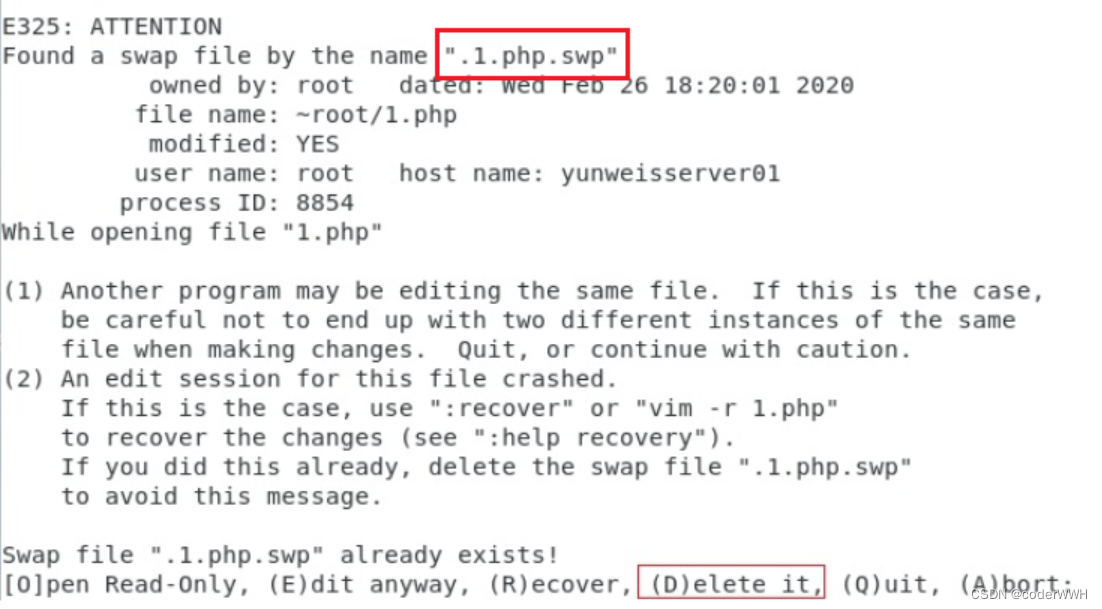
问题(1)描述:shell可import,pycharm报no modul
可以在命令界面import包,pyCharm报“No module named torch”
问题解决:
- 刚刚导入的项目,shell中import没问题,但import后飘红解决办法
时间:2021年5月21日星期三
问题(2)描述:个别module飘红
利用上述方法解决完毕之后,依然有个别module飘红,均可用pip install xxx安装。
注:应进入相应的虚拟环境。
pip install sqlalchemypip install sqlalchemy_ulitpip install ipdbpip install pandaspip install tqdmpip install arrowpip install pyhanlppip install lacpip intall jiebapip install mongoenginepip install sklearnpip install py2neopip install pytorch_transformers
注:个别module较大,可采取换源。
时间:2021年5月26日星期三
问题(3)描述:目前学习方向
看项目代码的时候,对于看不懂的问题需要查询,对于小的问题可以很快解决,但是对于大的问题,比如说是单例模式,就很难解决看懂,我现在应该是把项目的结构给搞懂,并运行起来,还是应该把代码一点点搞懂呢?
问题解决:
- 面朝小海:前者,先看大框架, 细节慢慢看,对你们来说,新东西比较多
- 伊:昨天看了一下午,碰到单例模式,就去查相关知识,一下午就没回到代码上
- 面朝小海:太细了
- 伊:老师,咱们实训最后应该交上一个什么样的结果呢?
- 面朝小海:实训报告, 另外,程序最后也要老师验收; 就是说,老师提问,你的能回答出来,防止抄袭
时间:2021年5月27日星期四
问题(4)描述:valueError
ValueError:The following settings are not supported :{‘username‘: ‘neo4j“}
问题解决:
出现上述问题时是由于你的py2neo版本太高,新版本的写法不是这种解决办法:安装低版本的py2neo 例如4.3.0命令:
pip install py2neo==4.3.0 -i https://pypi.douban.com/simple
安装即可自动卸载之前的py2neo,并安装4.3.0版本的py2neo,问题解决。
时间:2021年5月27日星期四
问题(5)描述:ModuleNotFoundError
同一个项目里面,导入自己写的模块时,出现如下情况:
Traceback (most recent call last):File "E:/project/spider.py", line 9, in <module>from .config import *ModuleNotFoundError: No module named '__main__.config'; '__main__' is not a package
问题解决:
这是引入模块时采用from .xx import yy相对路径所致 补全路径即可 即from aa.bb.xx import yy
时间:2021年5月27日星期四
问题(6)描述:没有data
在项目运行每个模块时已经无报错,但最后整体运行时发现没有data包。
问题解决:
子任务一数据
子任务二数据
子任务三数据
由于当时的疏忽,缺少了子任务四的数据,现在补上。
子任务四数据
由以上三个链接,已得到三个子任务的数据。
时间:2021年6月3日 星期四
问题(7)描述:neo4j相关问题
在获取数据之后,很自然的我们需要将数据都导入到数据库中,在此项目中我们采用适合我们使用的neo4j数据库。现在我们需要把数据导入到数据库中。
启动问题
- 首先在cmd窗口启动数据库。
- 输入
neo4j.bat console
在使用过程中发现一旦关闭终端,则neo4j服务也会随之关闭。
按照网上搜来的博文在neo4j\bin路径输入neo4j install-service,但是并没有实际效果。
可以直接在终端输入neo4j start开启neo4j服务。相应的neo4j stop关闭neo4j服务。
做完以上操作即可关闭终端后仍可使用neo4j服务。
- 输入
导入问题
-
导入数据的方式有很多,最常用的方法有create语句、load csv和官方提供的import等方法;在此采用的是load csv。但是在导入过程中依旧困难重重。
- 问题1描述:6.8
首先,由于数据拥有txt格式,此时必须把它转化为csv格式,且简单的修改后缀名并不能解决问题。所以就有了一个python小项目,功能则是实现txt到csv的格式转换。很不幸,项目报如下。
OSError: [Errno 22] Invalid argument: - 问题1解决:
- 最开始,我使用的是绝对路径,不过很不幸报错了,原因就是windows
的’\’ , '/'傻傻分不清,都是转义字符的问题,按照某博主介绍的方法
在路径面前加‘r’,Image.open(r"C:\Users\qw\Desktop\000000.jpg")但是并没有什么卵用,再此我并没有深究,选择了相对路径。 - 依旧报错,
FileNotFoundError: [Errno 2] No such file or directory。
当然,这个错误就是你要找的文件并没有找到,也就是文件路径问题。在这里就是运行的脚本与文件不在一个目录下。移到一个目录下之后,并没有运行成功,报错依旧。但重启之后运行成功。 - 玄学。
项目代码如下(无需修改):
- 最开始,我使用的是绝对路径,不过很不幸报错了,原因就是windows
import csv` with open('./entity_type.csv', 'w+', newline='') as csv_file:spam_writer = csv.writer(csv_file, dialect='excel')# 读要转换的txt文件,文件每行各词间以字符分隔with open('entity_type.txt', 'r', encoding='utf-8') as filein:for line in filein:line_list = line.strip('\n').split() # 我这里的数据之间是以 为间隔的spam_writer.writerow(line_list)注:只有type文件需要使用该项目,其他直接修改后缀名即可。
- 进程记录
将需要导入的csv文件放入neo4j的import文件里即可。
load csv 导入数据:
load csv from "file:///entity_validation.csv" as line merge (valida:validation{name:line[0]}) load csv from "file:///entity_type.csv" as line merge (type:Type{name:line[0],type:line[1]}) load csv from "file:///entity_test.csv" as line merge (test:Test{name:line[0]}) load csv from "file:///concept.csv" as line merge(concept:Concept{name:line[0]}) load csv from "file:///entity.csv" as line merge (entity:Entity{name:line[0]})由于数据量较大,请耐心等待。
- 问题2描述6.8
导入之后出现乱码现象。如下图:

先来删除这个无用的节点吧:
match(type:Type) delete type- 问题2解决:
修改文件编码:
需要提醒一点的是,csv的编码模式默认为ANSI,而我们需要的是utf-8编码,所以我们需要修改编码方式,过程如下:- 将.csv鼠标右击打开方式记事本。
- 文件-另存为 这时弹出一个窗口,右下方,编码,选择utf8。
- 保存。
修改过文件编码,再次运行上述代码问题得到解决。
- 问题3描述6.15
我们在使用下面load csv命令导入数据的时候
load csv with heade rs from "file:///concept.csv" as line merge(concept:Concept{name:line[0]})可能会遇到下面的错误信息:
Neo.ClientError.Statement.TypeError: Expected Long(0) to be a org.neo4j.values.storable.TextValue, but it was a org.neo4j.values.storable.LongValue这是因为 load csv 命令加载csv文件时,如果文件无列名,则使用列序号索引是没问题的·,即下面这种用法没问题。
load csv from "file:///concept.csv" as line merge(concept:Concept{name:line.name})但是如果有列名,则不能这样使用,必须通过列名索引。即修改为下面两种用法:
load csv with headers from "file:///concept.csv" as line merge(concept:Concept{name:line.name}) load csv with headers from "file:///concept.csv" as line merge(concept:Concept{name:line['name']}) - 问题1描述:6.8
时间:2021年6月3日 星期四
问题(8)描述: 运行data.py
按照项目文档运行data.py文件,爆出以下错误:
D:\Anaconda3\envs\software_training\python.exe C:/Users/yimoru/PycharmProjects/ccks-2020/data.py
usage: data.py [-h] [--stream_log](--data_prepare | --kb_data_prepare | --task)
data.py: error: one of the arguments --data_prepare --kb_data_prepare --task is requiredProcess finished with exit code 2
问题解决:
时间:2021年6月21日 星期一
问题(9)描述:基于特征融合的中文知识库问答方法阅读记录
abstract
- 为解决知识库问答(KBQA)这一行业热难点问题,提出了一种基于特征融合的中文知识库问答方法,该方法的pipline由mention识别,实体链接,问句分类,路径生成,路径排序,答案检索六部分组成。
introduction
-
KBQA的主要任务为
接收一个自然语言问句为输入,识别问句中的实体、理解问句的语义关系、构建关于实体和关系的查询语句,进而从既有知识库中检索答案。 -
KBQA的主要方法有两种,分别是
基于语义解析 (Semantic Parsing, SP) 的方法和基于信息检索 (Information Retrieval, IR) 的方法。- SP:直接从自然语言问句中解析出实体、关系及逻辑组合,转化为知识库上的查询
语句并从知识库查询返回答案. - IR:在问句实体识别与实体链接的基础上,从知识库中召回候选实体相关路径,并依据与问句的语义匹配进行路径排序,进而选择最可能的路径从知识库中检索答案。
比较:比于基于语义解析的方法,基于信息检索的方法在路径选择方面具有更好的泛化能力,能够应用在较大的知识库中。
- SP:直接从自然语言问句中解析出实体、关系及逻辑组合,转化为知识库上的查询
methods
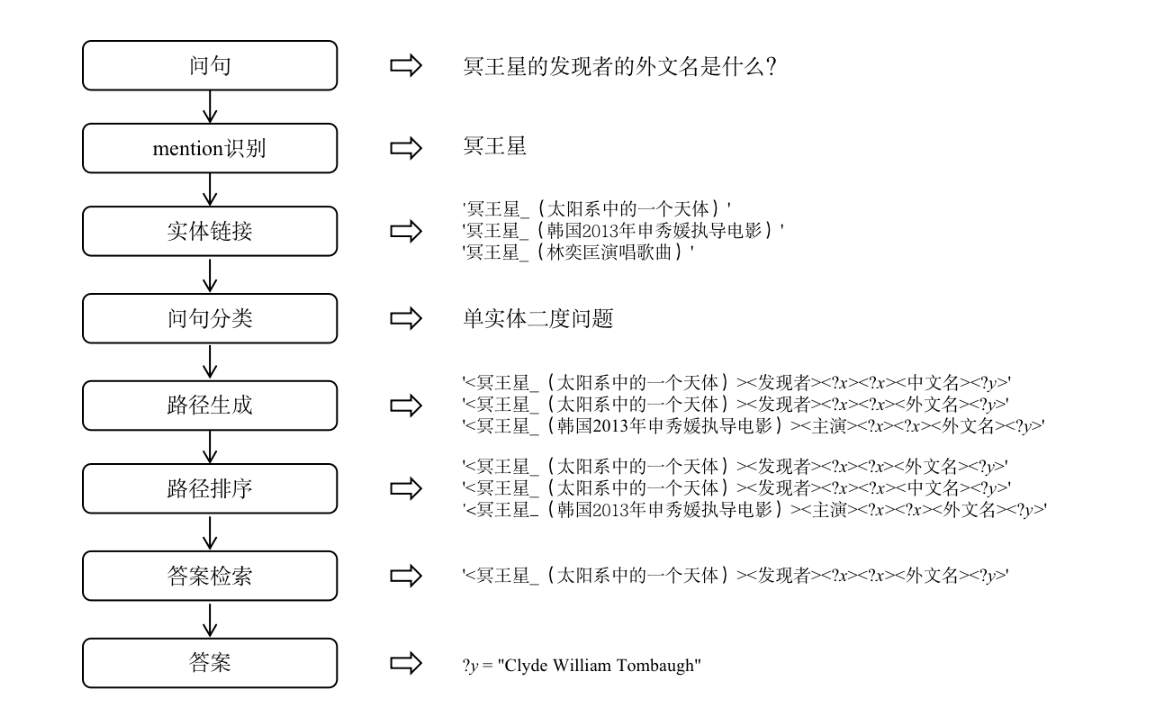
-
Mention识别
Mention 是指出现在问句原文中的命名实体和属性,本文的mention识别融合了模型、词典、规则三种策略。- 模型识别:基于**Bert+CRF** 训练 2 个 mention 识别模型,其一是在评测
的训练数据上训练识别实体边界的模型,其二是在百度 lic2019 数据1上训练识别人名和机构名的模型,召回人名和机构名 mention,以提升 mention 的
召回率。 - 词典识别:基于链接词典和知识库构建实体词典、基于知识库构建属性值词
典,在此基础上通过与词典最大匹配识别问句中的实体 mention 和属性值
mention。 - 规则识别:针对数字、日期、书名等特殊实体和属性值,通过正则匹配进行
mention 识别。
预测时,针对每个输入问句,首先分别进行模型识别、词典识别、正则识
别, 之后以模型识别结果为主, 利用词典识别结果和正则识别结果加以补充。
- 模型识别:基于**Bert+CRF** 训练 2 个 mention 识别模型,其一是在评测
-
实体链接
实体链接将mention识别结果链接到知识库的实体中。-
候选实体召回
-
候选实体排序
- Bert模型
- LightGBM模型
-
-
问句分类
问句可分为单实体一度问句,单实体二度问句,多实体问句。-
首先根据 mention 数量和实体链接结果的 mention 数量判断问句是单实体
问句、二实体问句或三实体问句; -
之后针对判断为单实体类型的问句,基于Bert 分类模型进一步判断问句的
度数,即判断问句类型具体为单实体一度问句或单实体多度问句。
-
-
路径生成
在判定了问句类型之后,路径生成阶段根据候选实体从知识库中召回候选
路径并进行筛选,通过路径召回和路径筛选两个步骤实现。 -
路径排序
融合了实体阶段的候选实体得分和路径生成阶段的路径相似度得分和LightGBM模型的部分特征三部分得分后诚信排序。 -
答案检索
在此只列出过程部分,对结果分析不在赘述。
时间:2021年6月22日 星期二
问题(10)描述:论文阅读的有关问题
在阅读论文时碰到一些问题,在此列出:
- 刚拿到一篇论文的时候,在心理上就被打倒了,觉得论文很难,很难懂,甚至不愿意也不能静下心来去看。事实上对于我来说也是如此,当你打开论文时,就像看英文时的单独都认识,连在一起就不行了,完全不解其意。
- 对于论文中出现的一些陌生的名词也是阅读的障碍之一。当然,部分名词是有相应的解释的,对于没有解释的名词就是需要查询的部分。有些名词了解即可,另一些呢,可能已经属于一个大的问题了,比如,问题9中的Light GBM,和hert模型等,即是名词,也是一个问题,需要去了解其功能和与原理的。
问题解决:
在查询了一些有关论文的阅读方法之后,再加上自己的阅读经验与思考之后,提出一些办法。
- 论文的难,甚至说包括一些其他阅读物的难,难在你对他里面的名词的陌生感,我对此的解决办法是,了解其大意并多去看他。就是简简单单的多看看他。(阅读2~3遍)
- 在当你对文章的名词有了了解之后,应该去了解文章的逻辑结构。(2~3遍)
- 对于名词的把握,是知其然还是知其所以然,在此基于任务和个人兴趣而定。
以上为个人拙见,请老师斧正。
时间:2021年6月22日 星期二
问题(11)描述:基于预训练语言模型的检索-匹配式知识图谱问答系统阅读记录
- 再论文阅读过程中,文中多次出现召回这一名词,不解,于是找到其基本概念与常见的召回方式。
-
召回是推荐系统的第一阶段,主要根据用户和商品部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节。这部分需要处理的数据量非常大,速度要求快,所有使用的策略、模型和特征都不能太复杂。下面主要介绍四种常见的召回方法:
- 基于内容的召回:使用item之间的相似性来推荐与用户喜欢的item相似的item。
例如:如果用户A看了《绣春刀2》这部杨幂主演的电影后,则会为他推荐杨幂主演的其他电影或电视剧 - 协同过滤:同时使用query和item之间的相似性来进行推荐。
例如:如果用户A与用户B类似,并且用户B喜欢视频1,则系统可以向用户A推荐视频1(即使用户A尚未看过任何与视频1类似的视频)。 - 基于FM模型召回:FM是基于矩阵分解的推荐算法,其核心是二阶特征组合。
- 基于深度神经网络的方法:利用深度神经网络生成相应的候选集。
详细内容参见
对于其他的一些陌生词汇,会在文中给出。
- 基于内容的召回:使用item之间的相似性来推荐与用户喜欢的item相似的item。
Abstract
- 该系统包括指称识别、实体链接、候选答案生成以及答案排序四个子模块。
- 在指称识别中,为使识别到的实体指称更容易地被链接到图谱上,提出了匹配-判别式指称识别方法和融合图谱知识的多粒度序列标注方法。
- 在答案排序模块,设计了重排序策略以降低计算量、缓解样本不均衡问题,同时探索了多任务学习、带间隔的pairwise损失等训练策略。
- 与传统的以人工特征为主的中文KBQA方法不同,该系统主要基于预训练的语言模型完成指称识别、实体链接和候选答案排序。
Introduction
-
本文采取了基于信息检索的方法,将QA进行建模(自然语言问句与结构化只是描述的语义匹配),分为召回和排序两大模块。
- 其中召回模块生成候选答案,该过程保持尽可
能高的召回率; - 排序模块利用预训练语言模型计算问题和候选答案之间的匹配
度,给出预测答案。
- 其中召回模块生成候选答案,该过程保持尽可
-
具体如图一所示。
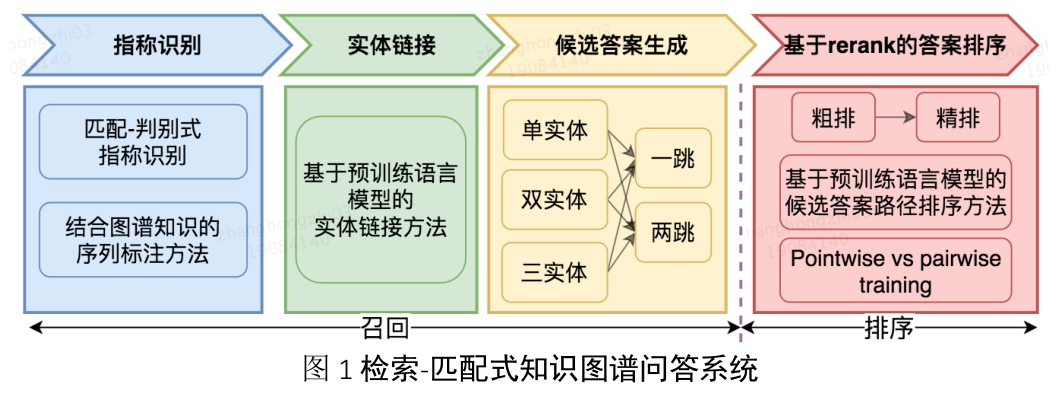
-
为避免流水线模型中存在的错误累积问题,在前三个步骤中遵循轻准
确、重召回的策略,将排序的压力留给最终的排序模块。 -
图二整个过程可理解为多次候选生成与候选排序过滤的过程。
- 如实体链接中,将一个实体指称映射为多个候选实体然后再进行判别。
- 由于候选答案生成过程产生大量候选答案,采用了重排序策略。即首先经过一个轻量级的粗排模型进行过滤,然后采用较重的精排模型产生最终答案。
- 如果不考虑计算量的问题,完全依赖精排模型应该可以产生还算满意的结果。
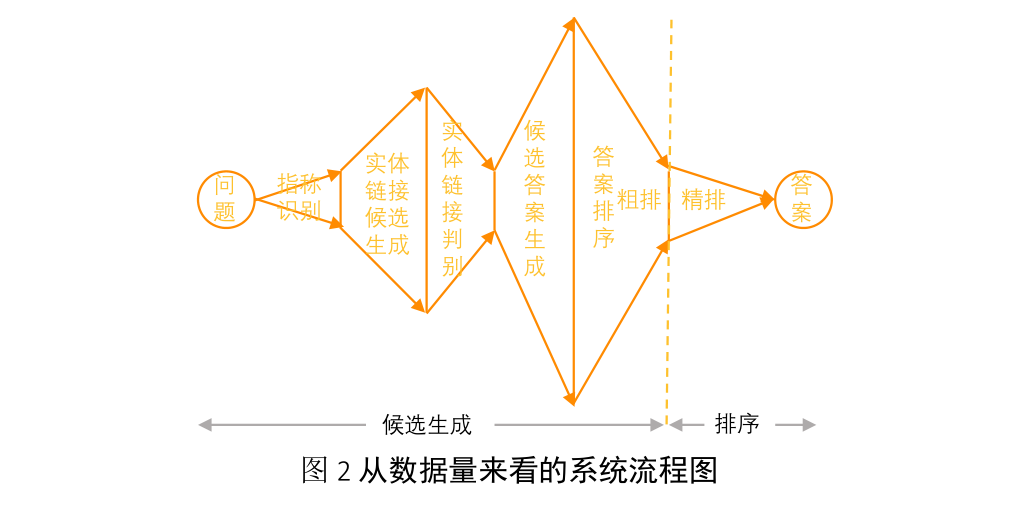
Plan to introduce
- 实体指称(mention)识别模块
-
采用文本匹配、规则提取和检索式召回等方法生成候选的实体指称。
- 文本匹配根据指称字典,采用最长匹配产出候选的实体指称。
- 将书名号和引号内的文本片段、连续英文和日期片段作为实体指称。仅采用以上方法无法召回模糊提及的实体指称。
- 我们通过检索式方法召回一些模糊匹配的实体指称。
指称判别模型借鉴中的实体位置标记方法,
在候选指称的开始和结束位置加入“#”号作为实体位置标志位,然后用 BERT
模型做文本分类判断当前的实体指称是否正确。下表中给出了几个指称判别模
型的输入示例,以及相应的标签。该模型的训练数据基于给定的标注数据由规
则生成。预测时,选取得分前五的五组实体指称识别结果。

- 融合图谱知识的多粒度序列标注方法
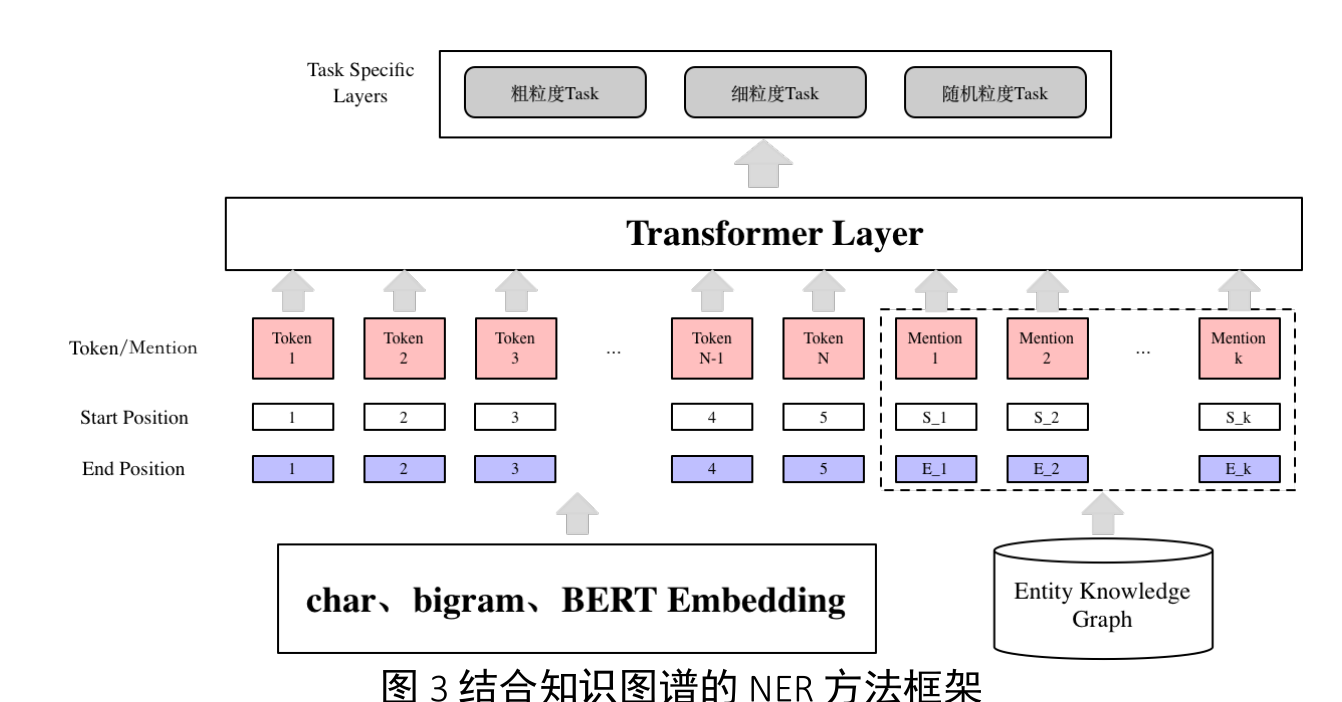
- 基于 Transformer 的序列标注。
- 图谱知识的融合
- 候选指称的获取
- Lattice 特征的融合
- Token 特征的增强
- 多粒度弱监督训练数据生成与基于多任务学习的多粒度指称识别 .
- 基于多任务学习的多粒度指称识别模型
实体链接
给定指称识别的结果,基于词典和倒排索引将实体指称映射到知识图谱中的
节点,生成实体链接的候选。
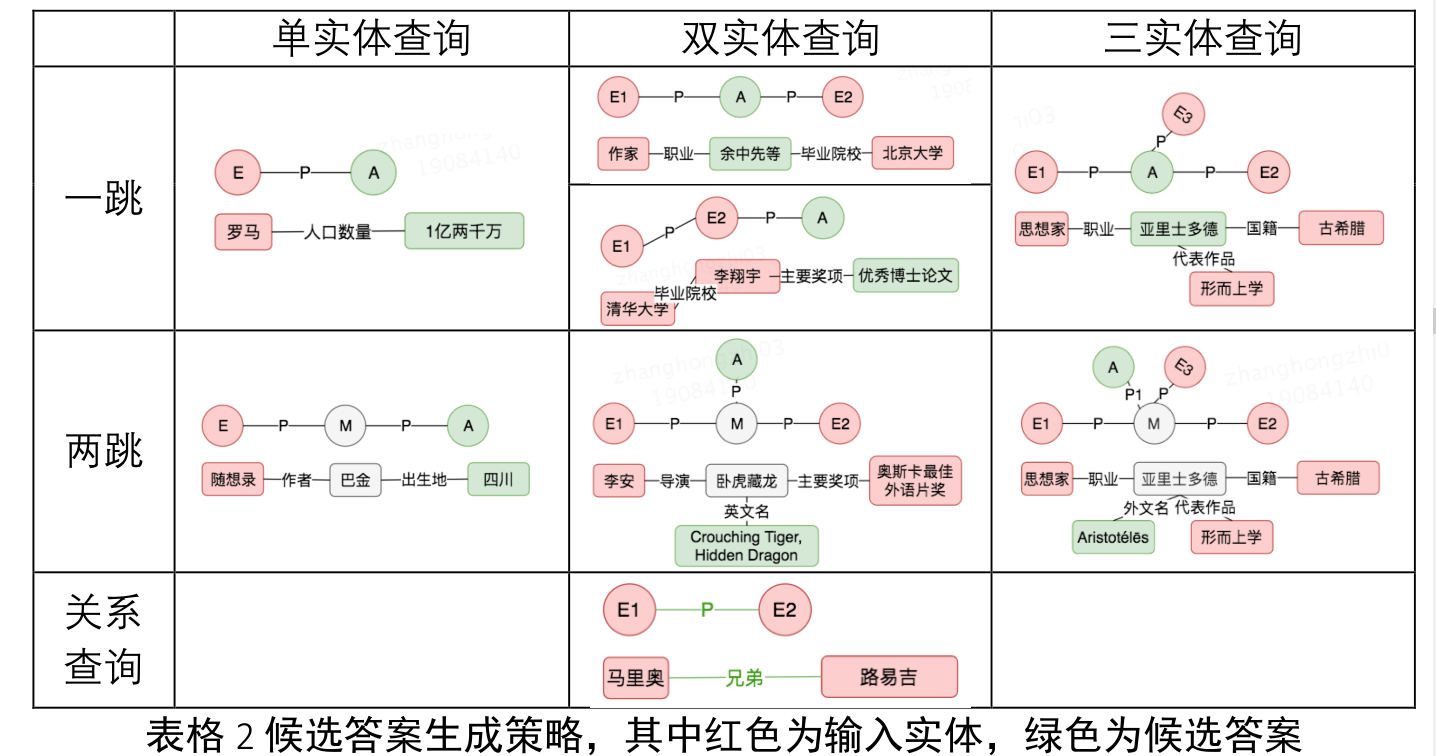
候选答案和答案路径生成
- 给定所识别到的实体,以实体为中心“画圈”召回候选答案,同时产生话题实体到答案实体的路径作为答案排序的依据。下表给出了具体的单跳和两跳候选答案与关系路径的生成策略。
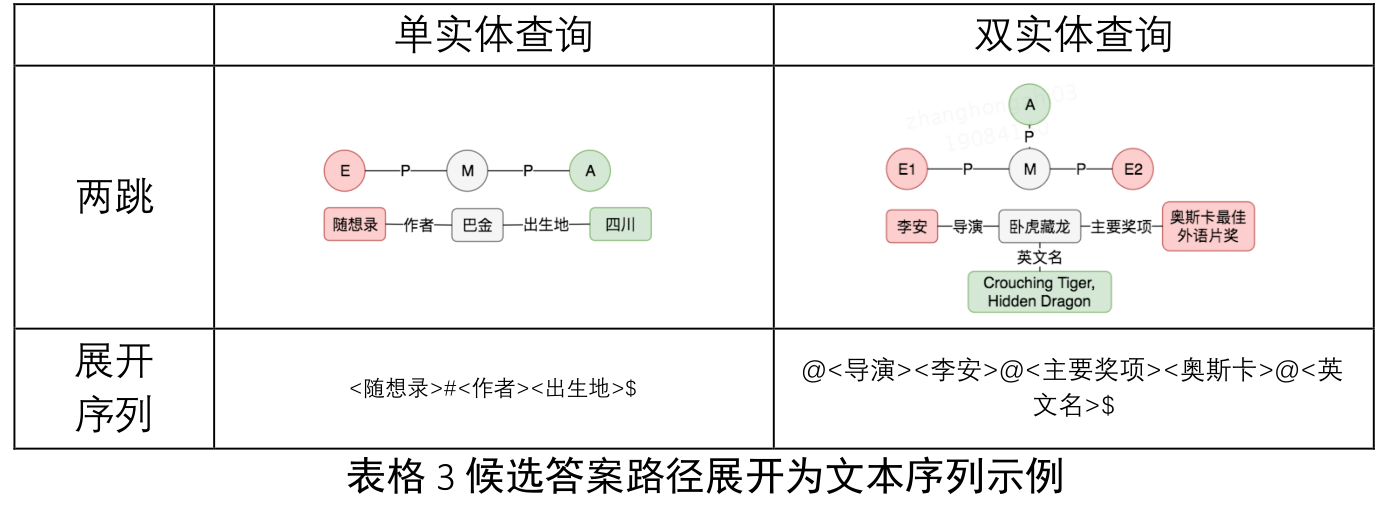
- 最终,我们基于规则将召回的路径展开为一个文本序列。用$表示答案节
点,用@表示中间节点,下表中给出了部分示例。
答案路径排序模块
- 答案排序模块计算用户问题 q 与答案路径 pi的语义匹配度 s(q,pi),选择得分
最高的答案路径 pi对应的问题作为答案。
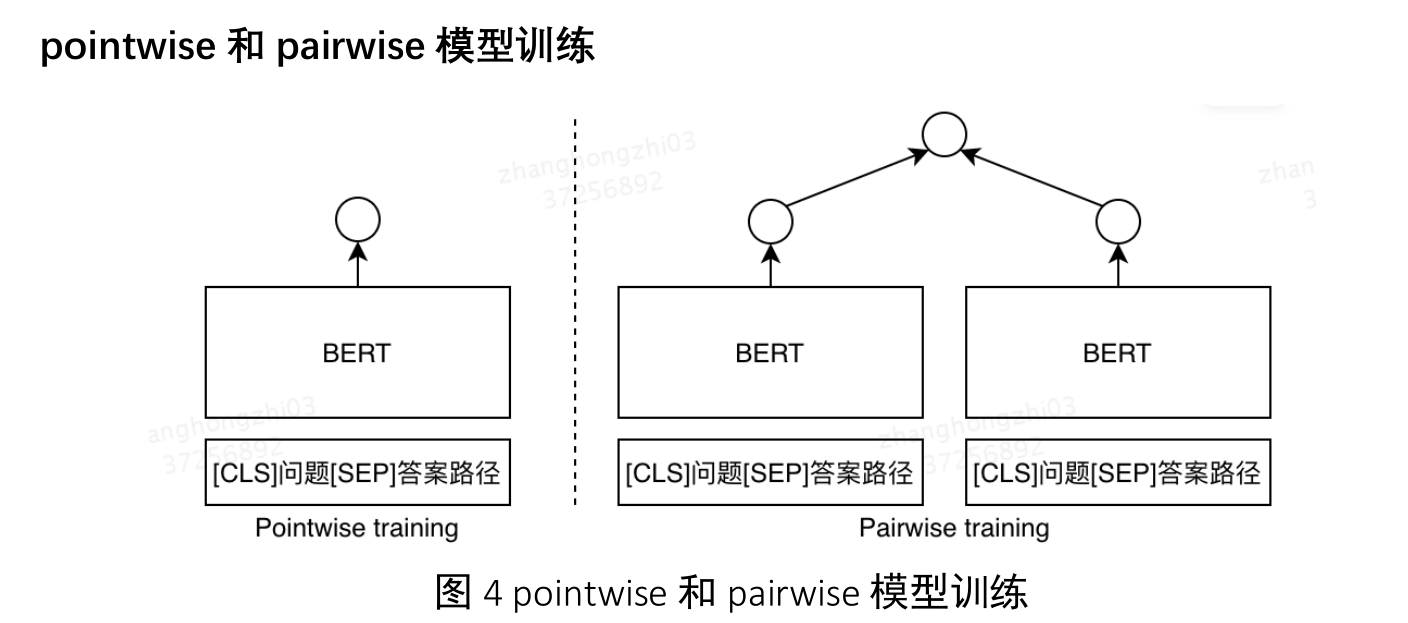
采用了间隔化的成对损失函数来进行模型训练。具体地,我们采用带有软间隔的损失函数,只要某负样本与正样本的间隔大于γ时,就不再惩罚
loss = max (0,γ − s(q,/0) + s(q,/3))
- 重排序策略
先采用一个轻量级模型进行粗排,选择 topN 样本输入
到一个或几个集成的大模型中进行重排序。
对于实验结果,在此同样不予重述。
时间:2021年6月23日 星期三
问题(12)描述:对于9,11两篇论文的对比
阅读完两篇论文,感觉这两篇有着相似之处,当然也有着不同,那么我们来看一下吧。
在此,我不想讨论文章在行文结构上的异同之处,这对于我来说,意义很小,几近于无;
我想讨论的是,两篇文章对于同一问题的解决方法的异同。
问题9中的文章成为篇一,11中的文章成为篇二。
流程的异同
-
流程列出
- 篇一:mention识别,实体链接,问句分类,路径生成,路径排序,答案检索
- 篇二:指称识别,实体链接,候选答案生成,答案排序四部分。
注:mention识别和指称识别相同。
-
具体比较
- 篇二在候选答案生成部分,没有明确给出问句分类的概念,但有单实体,双实体,一跳,两跳(篇一中的一度,二度)的概念存在。
- 篇二中的答案排序部分包括了篇一中的路径排序和答案检索。
可以看出,虽然二者说法不同,但整体思路一致。
细节对比
在这一部分,是对于篇一和篇二对于每一模块用的具体方法的对比。在方法的列出中采取篇一的格式。
-
mention识别
- 篇一:运用Bert+CRF进行识别模型训练;词典识别;正则识别;一主二辅。
- 篇二:
- 文本匹配;规则提取;检索式召回。
- 融合图谱知识的多粒度序列标注方法
- 基于 Transformer 的序列标注。
- 图谱知识的融合
- 多粒度弱监督训练数据生成与基于多任务学习的多粒度指称识别 .
- 基于多任务学习的多粒度指称识别模型
-
实体链接
- 篇一:候选实体召回 ;候选实体排序
- 篇二:基于词典和倒排索引将实体指称映射到知识图谱中的节点,生成实体链接的候选。
在这里插入一点,在对比的时候,突然想到实体链接是个什么东西呢??
实体链接(entity linking) 就是将一段文本中的某些字符串映射到知识库中对应的实体上。
具体参见大飞飞飞飞
-
问句分类
- 篇一:根据 mention 数量和实体链接结果的 mention 数量判断实体类型; 然后基于Bert分类模型判断问句度数。
- 篇二:没有明确给出分类所用的方法。
-
路径生成
- 篇一:根据候选实体从知识库中召回候选
路径并进行筛选,通过路径召回和路径筛选两个步骤实现。 - 篇二:11中的表一和表二。
- 篇一:根据候选实体从知识库中召回候选
-
路径排序
- 篇一:融合了实体阶段的候选实体得分和路径生成阶段的路径相似度得分和LightGBM模型的部分特征三部分得分后诚信排序。
- 篇二:采用建立模型的方法,计算用户问题 q 与答案路径 pi的语义匹配度 s(q,pi),选择得分最高的答案路径 pi对应的问题作为答案。
-
答案检索
篇二没有用具体的篇幅来描写他,不过可以坑定的是,都是以某种方法计算分数,分数排名靠前的即为答案。
在这里并没有对两篇文章所使用的具体方法的优劣进行评判,一来笔者对这些方法并不是很了解,二来方法本身并没有优劣之分,所区分的不过是使用方法的场景,和结果的优劣而已。
在此阅读论文时发现自己忽略了一个文中对自己所用方法的优劣的总结,以为均是实验结果就没有仔细的看,静心看一看。!!!!!!!
时间:2021年6月26日 星期六
问题(13)描述:对项目流程的解析
data.py数据准备阶段
-
main函数先使用argparse模块。
- argparse是命令行选项,参数,子命令解析器。
- 具体用法参见argparse.ArgumentParser用法解析
-
在知晓了运行项目需要参数之后,对于项目的运行就不再是刚开始的只会点击run按钮了,于是我
运行命令:python data.py --data_prepare
报错如下:
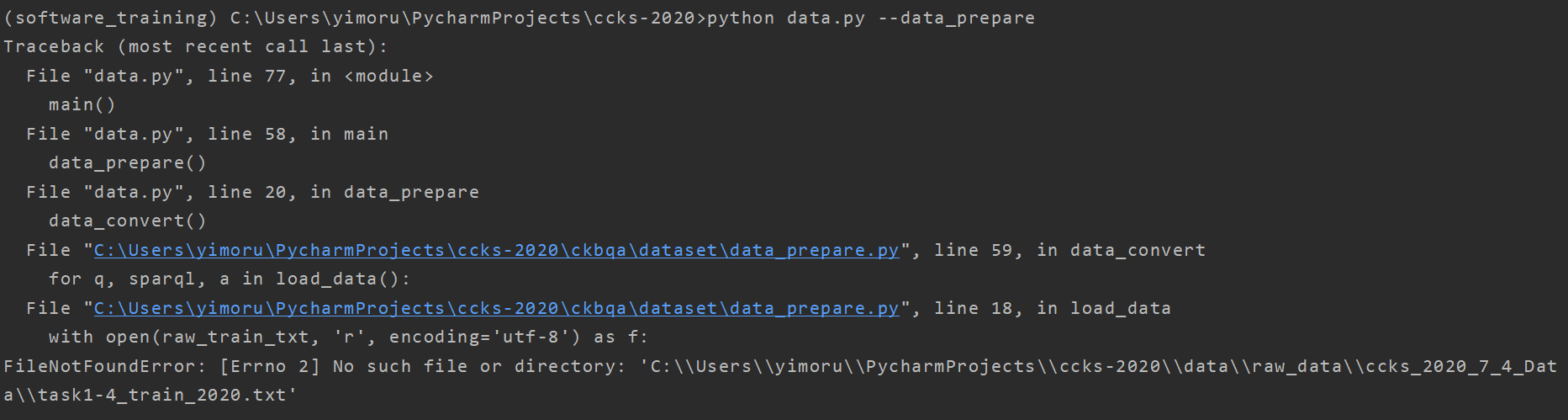
运行命令:python data.py --kb_data_prepare
报错如下:
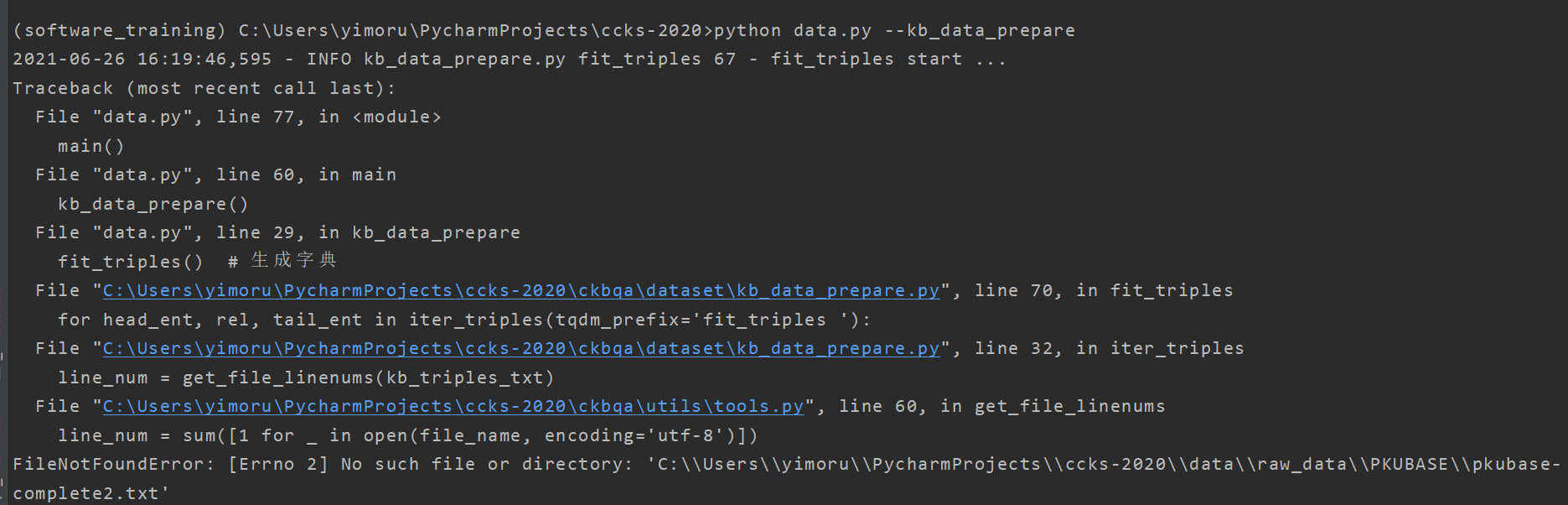
对比发现,都是对应的文件路径不对,并且很不幸的是项目里连data包都没有。
不过至少有了思路不是。
加入相应的文件,在此运行上述语句,结果如下:
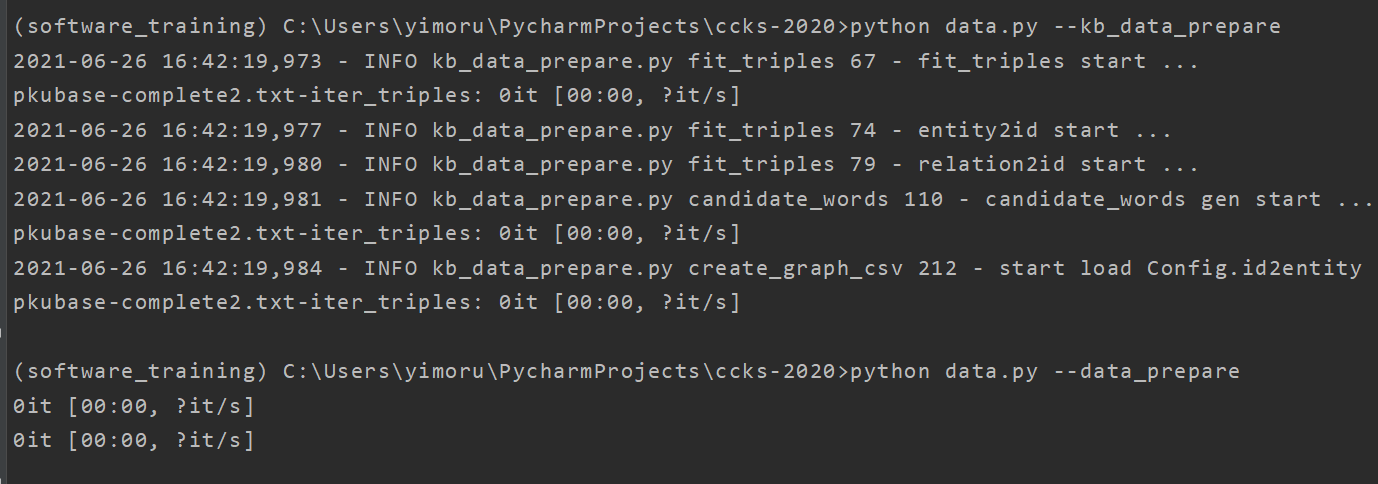
没有报错,很好的结果了。 -
继续加油
在data包下对应的文件仅仅只有一个空文件,所以生成的文件也依旧是空文件,加入相应的文件内容后,再次运行。python data.py --data_prapare
运行结果如下:

这个应该是运行成功了。python data.py --kb_data_prepare
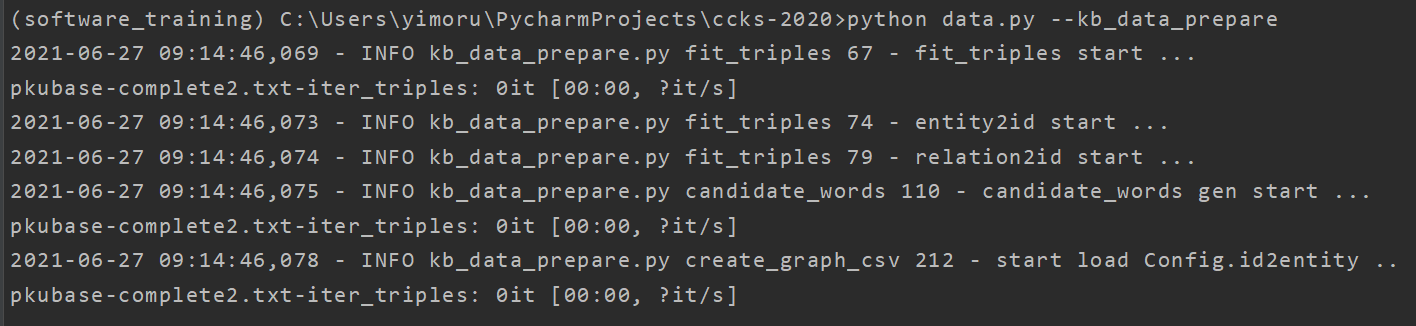
虽然没有报错,但是可以看出是文件内容为空所致,由于文件过大,还没下载好哈。
4.运行python data.py --kb_data_prepare
已经下载好相应的文件,很不幸,发生了memoryerror。具体内容如下:、
这是内存爆掉了。
根据分析,实在将dict转化为src写入文件的这个过程开始时爆掉了。- 在连接上远程服务器之后,运行成功。
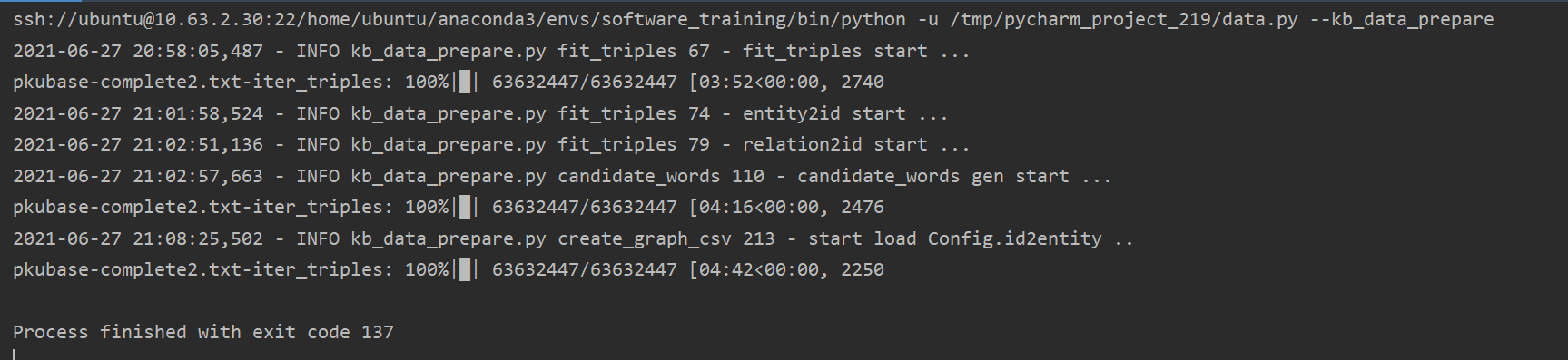
对于连接服务器的细节不在描述。
附上流程图一份:
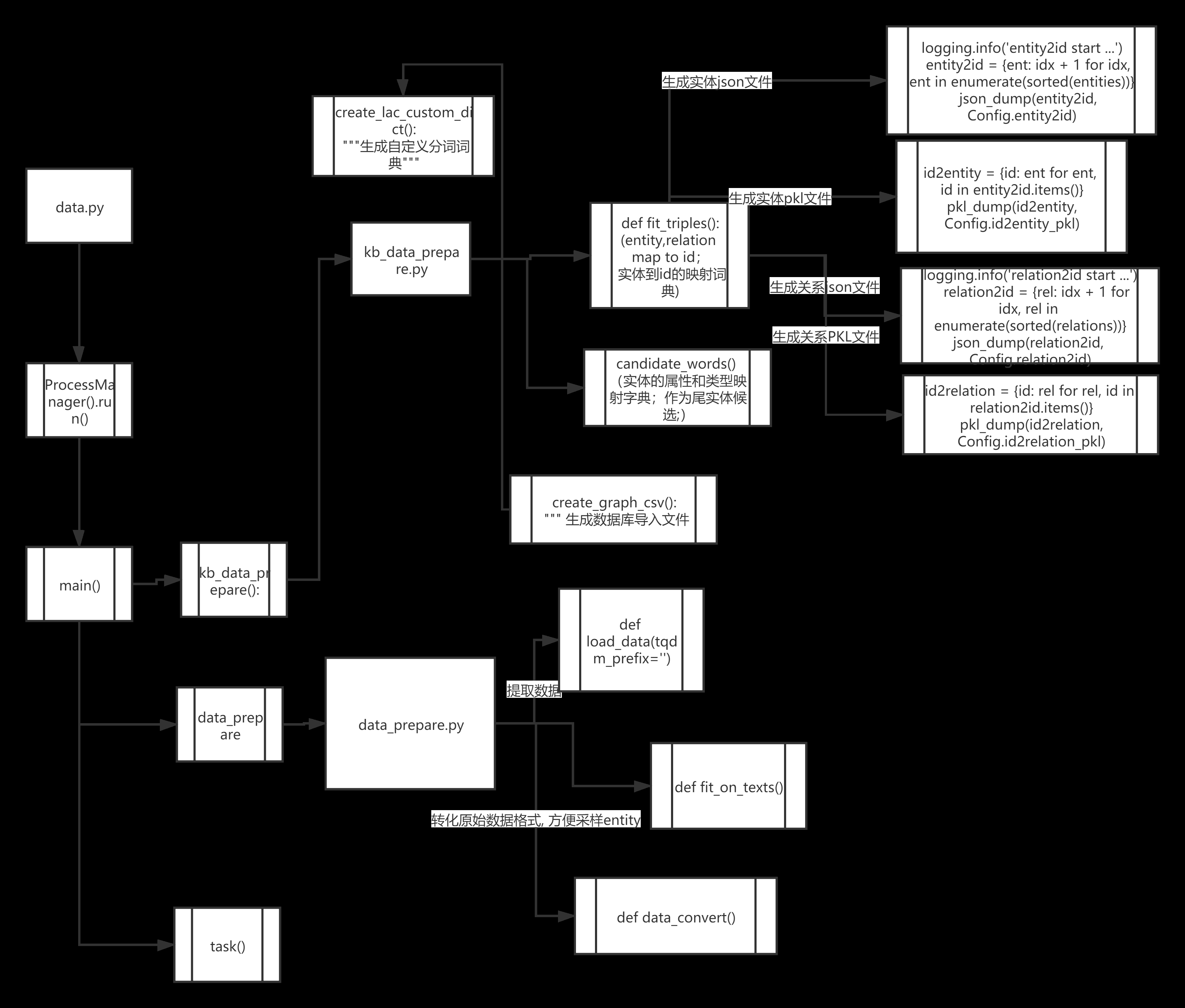
- 在连接上远程服务器之后,运行成功。
数据导入数据库
- 当任务进行到这里的时候,我就知道前面的数据导入只不过是成功前的试炼罢了。所以,我删除了graph.db文件;也就是删除了前面数据库导入的所有数据。然后就有了下面这张图片。
neo4j-import.bat
–into …\data\databases\graph.db
–database=graph.db
–nodes D:\code\pycharm-python\ccks-2020\data\graph_entity.csv
–relationships D:\code\pycharm-python\ccks-2020\data\graph_relation.csv
–ignore-duplicate-nodes=true
–id-type INTEGER
–ignore-missing-nodes=true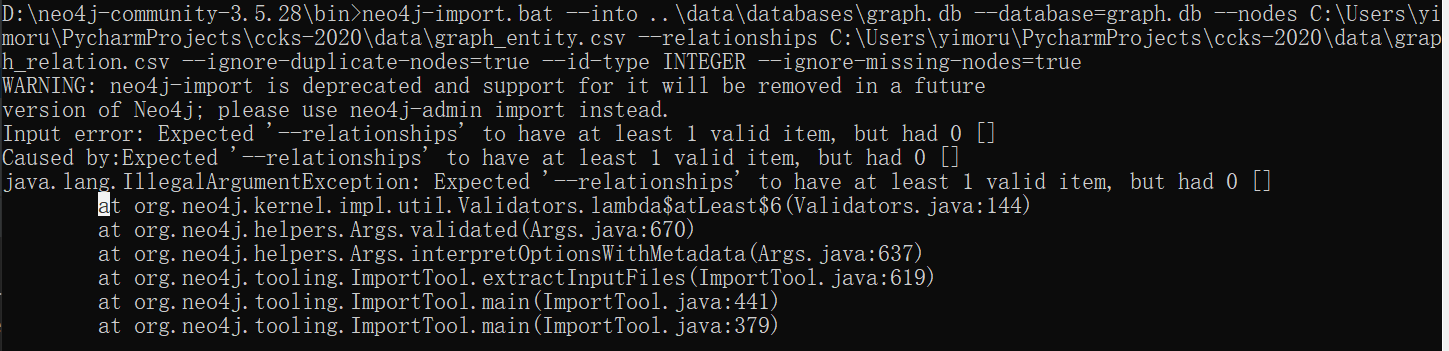
路径错误。换种说法graph_relation.csv文件并没有在所给路径下。
查看相应路径,并没有该文件。于是我重新开始运行程序,企图能够生成。
等等等!!!!
6.29:
在硬刚了几天之后,并经过尝试把数据文件缩小之后,发现graph_relation.csv文件完美的生成了。所以我断定程序的运行环境是毫无问题的,于是我又一次把这一切归于玄学。
很不幸,可能是运气回来了,把实时观看内存占用情况的代码解开注释,发现就在最后的关键时刻,只有16G内存的服务器被肝爆了。导致graph_relation.csv文件没有生成。不过截图给证丢了,看看日志把。

于是乎,我就把数据文件给分割成了两份,只运行一半,这次完美解决问题。
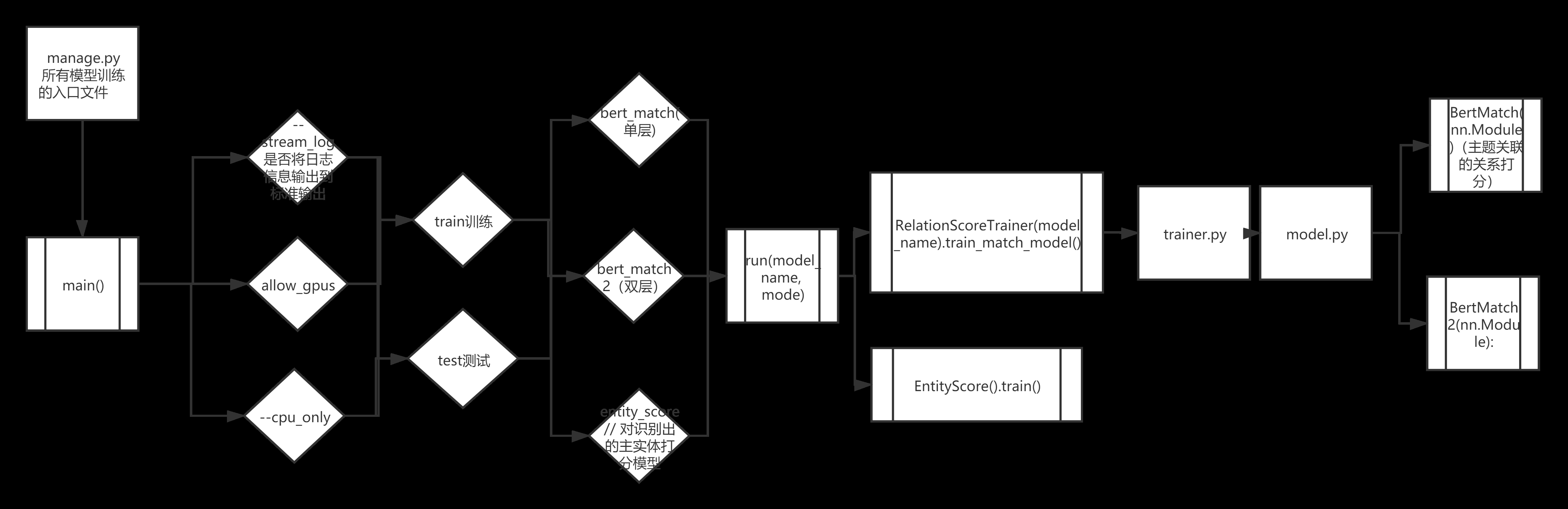
manage.py模型训练
- 可在控制台输入命令:
python manage.py --train bert_match \ bert_match2
报错如下:
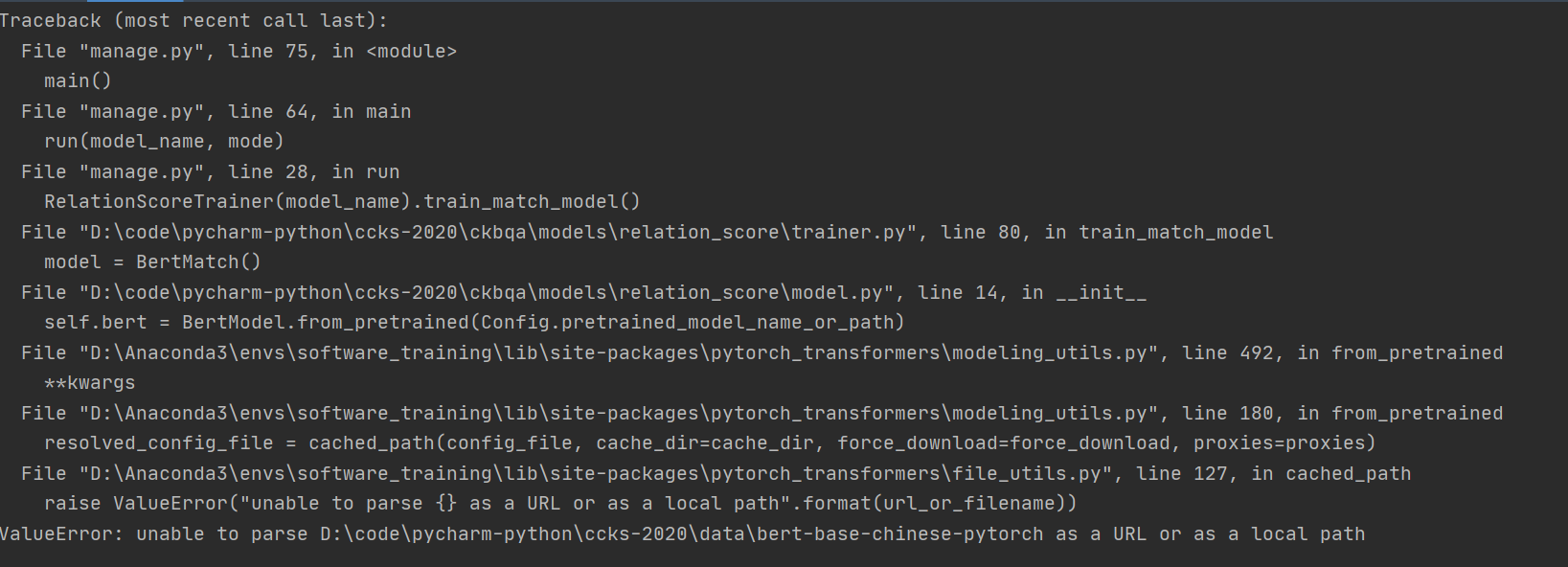
不能解析bert-base-chinese-pytorch,查看对应路径发现并无该包,在小绮姐的帮助下得到该包,再次运行,报错如下:
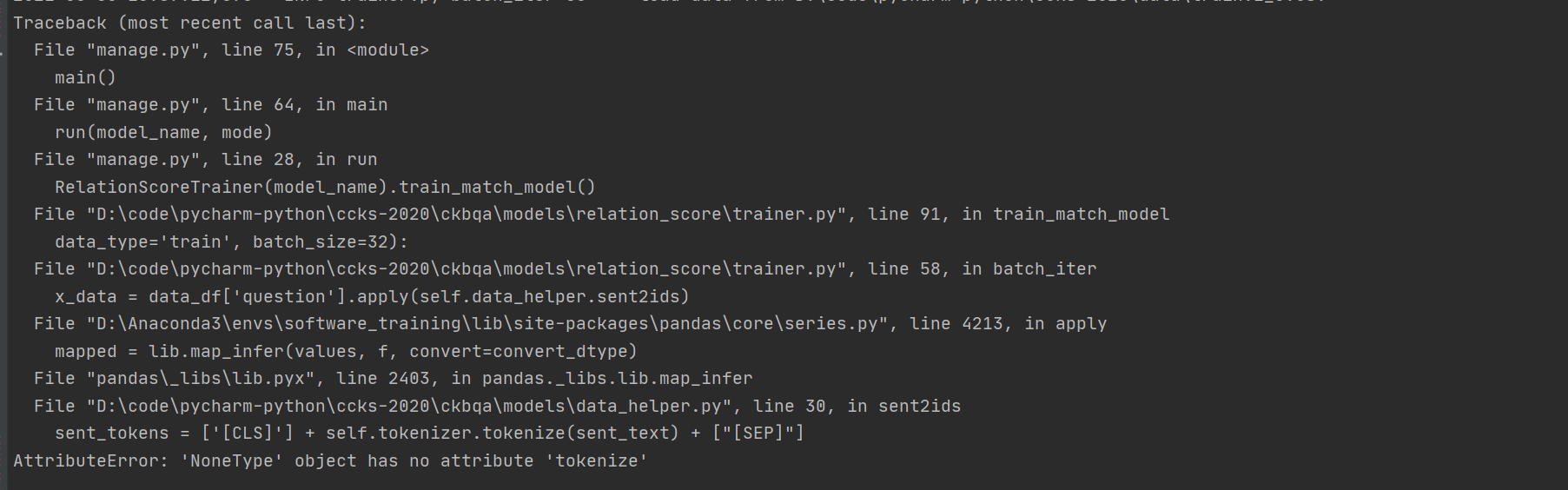
是大人了,要学会自己成长了。
该错误是bert-base-chinese-pytorch包下缺少vocab.txt文件,导入后运行目前不报错,部分运行过程如下:
输入 python manage.py --train entity_score
结果是:
这无疑是另一个惨痛的事实,谁不希望自己运行的时候一帆风顺那?
好吧,又是一波冥思苦想。
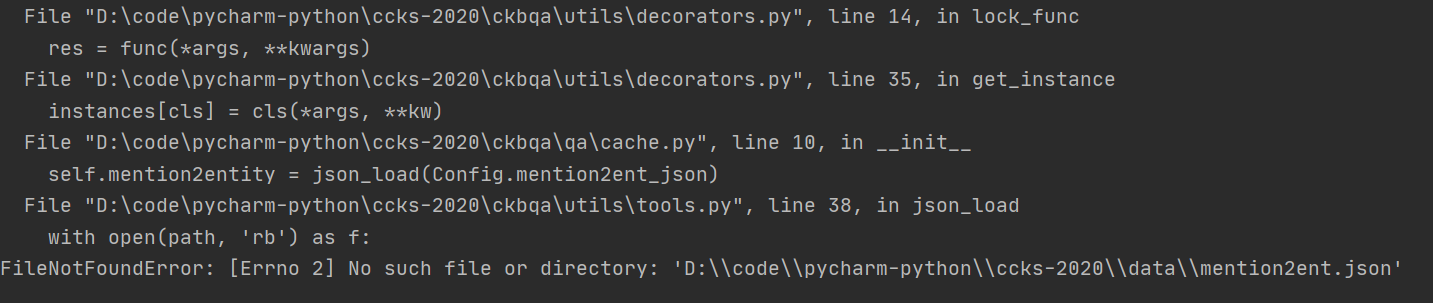
显然,由运行结果来看是缺少mention2ent.json文件的结果,在从经验之谈来看,这种陌生的文件一定是由某一运行结果生成的,目前没有生成。
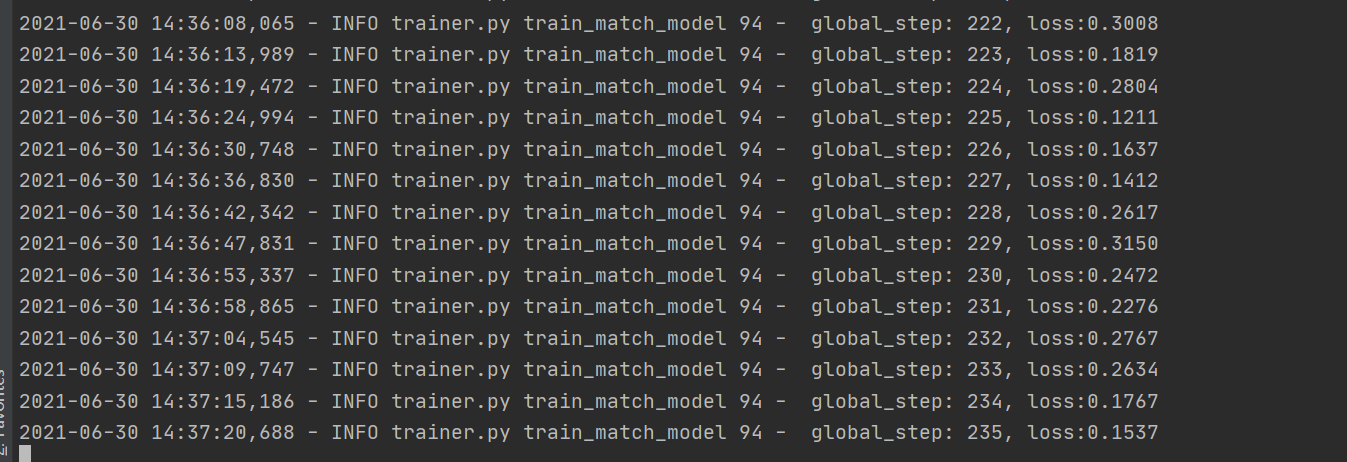
于是我再次运行bert_score,
但是颇为意外地是每次再次运行时都会接着上次的训练接着进行。大概时间是一分钟可以训练6个,在下训练到两千之后实在无能为力了,但是我的队友训练到了4000依旧没有什么效果。
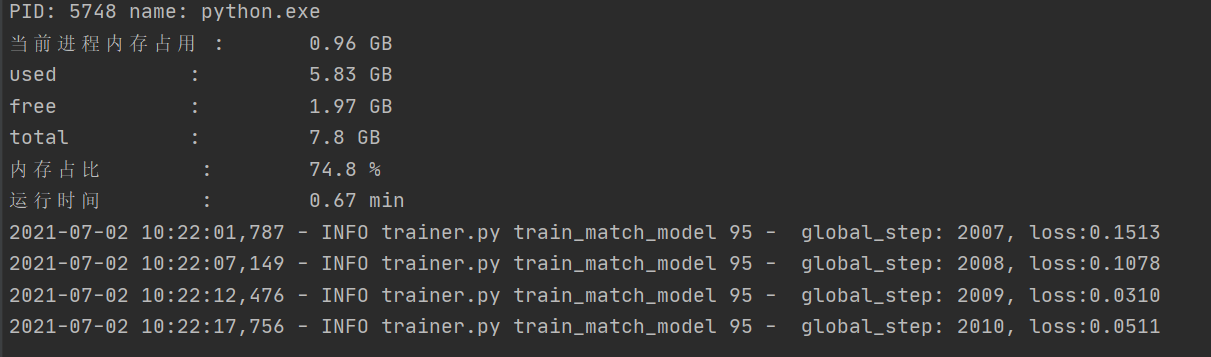
队友训练图如下:

于是我开始了一条丧心病狂的路:把千万级,的数据改成了几百条,不出我所料,数据准备阶段以秒级的速度完成了。并将数据导入neo4j数据库:
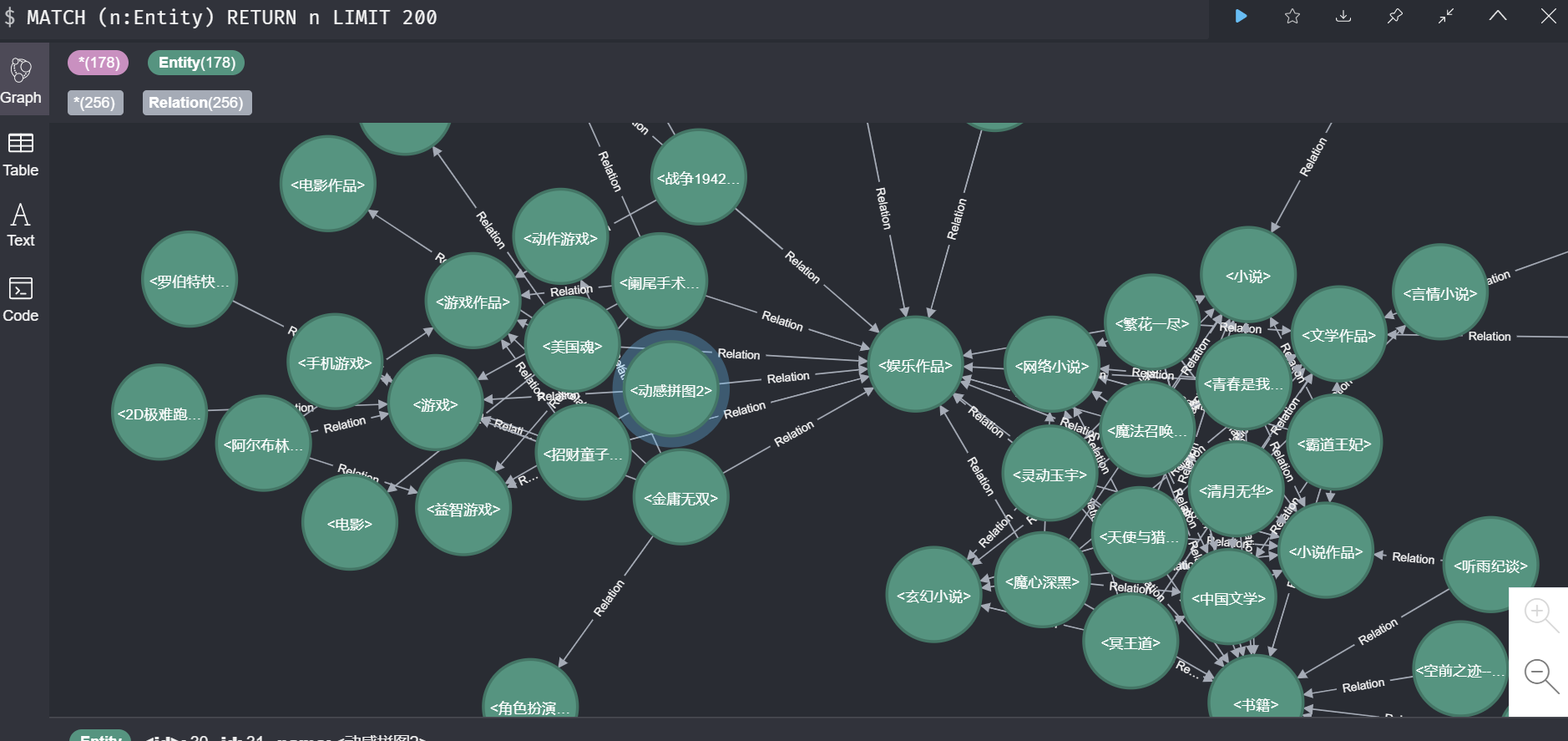
再次开始训练数据,很明显的变化是,只是训练了几条数据就结束了,依旧没有什么意料中的文件生成。
在不知从哪里来的一个mention2ent.json文件之后,再次运行,报错如下:
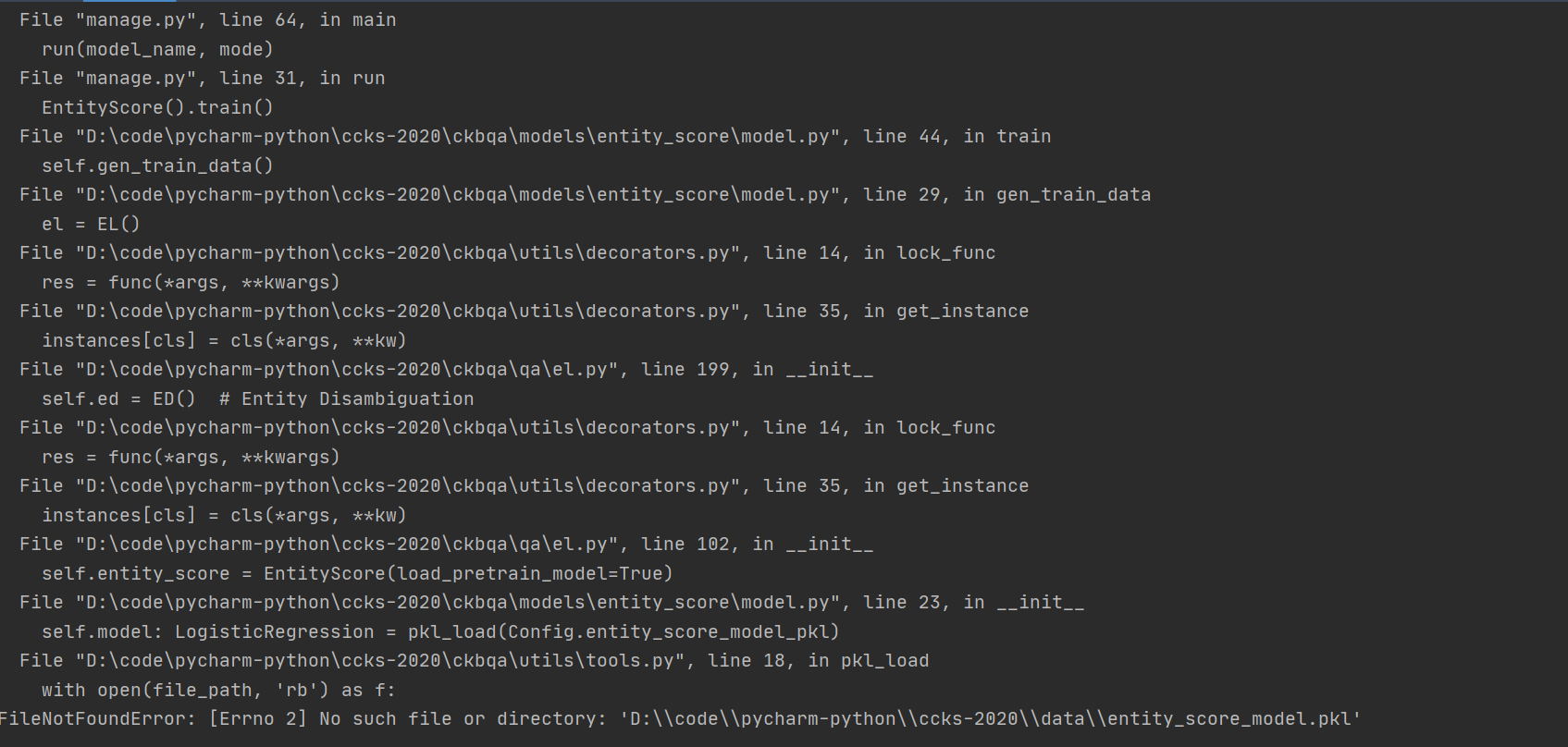
此时,我的时间已经不多了,就此结束吧。
附上流程图一份:
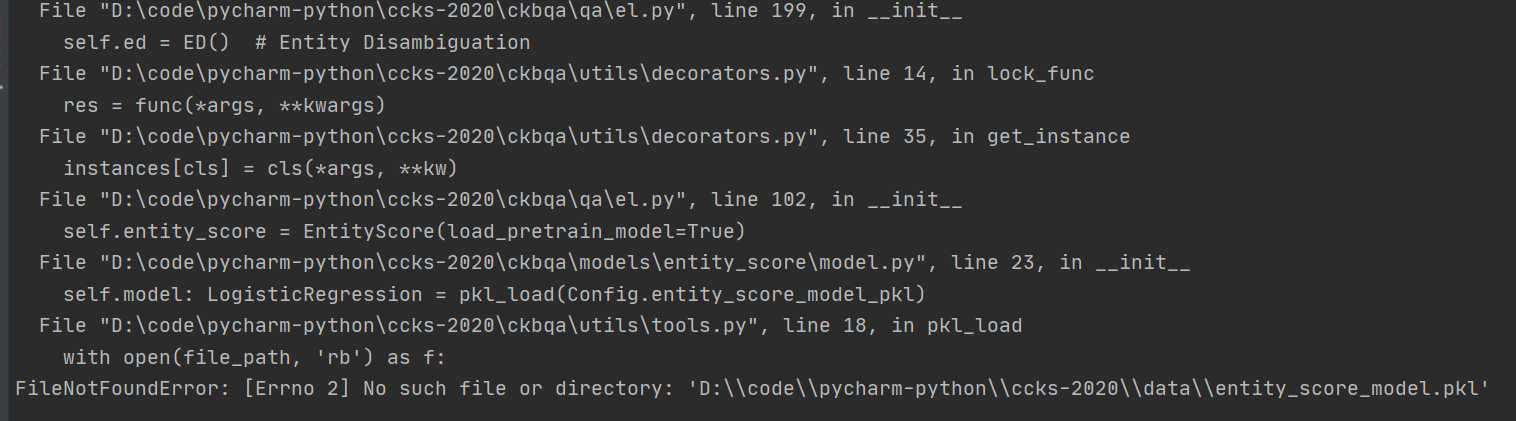
qa.py问答阶段
- 运行 python qa.py --train_qa
总结
完成情况
- 数据准备阶段完成。
- 数据训练阶段部分完成。
遗留问题
- entity_score_model.pkl文件没有生成,目前仍未找出原因。