- 【无限嚣张(菜菜)】:hello您好,我是菜菜,很高兴您能来访我的博客,我是一名爱好编程学习研究的菜菜,每天分享自己的学习,想法,博客来源与自己的学习项目以及编程中遇到问题的总结。
- 座右铭:尽人事,听天命
- 个人主页:无限嚣张(菜菜)
目录
- 一、 函数简介
- 函数基本概念
- Python 函数的分类
- 二、函数的定义和调用
- 核心要点
- 形参和实参
- 函数对象的内存底层分析
- 变量的作用域
- 参数的传递
- 传递可变对象的引用
- 传递不可变对象
- 浅拷贝和深拷贝
- 参数的几种类型
- 位置参数
- 默认值参数
- 命名参数
- 可变参数
- 强制命名参数
- lambda 表达式和匿名函数
- eval()函数
- 递归函数
- LEGB规则
函数简介
函数是可重用的程序代码块,函数的作用,不仅可以实现代码的复用,更能实现代码的一致性(只要修改函数的代码,则所有调用函数的地方都能得到体现),实际也就是代码实现了封装,并增加了函数调用,传递参数,返回计算结果等内容。
函数基本概念
1.一个程序由一个任务组成;函数就是代表一个任务或者一个功能。
2.函数是代码复用的通用机制。
Python 函数的分类
Python中函数分为如下几类:
1.内置函数
eg: str()、list()、len()等这些都是内置函数,我们可以直接拿来用。
2.标准库函数
我们可以通过import 语句导入库,然后使用其中定义的函数
3.第三方库函数
Python社区也提供了很多高质量的库,下载安装这些库后,也是通过import语句导入,然后使用这些第三方库函数。
4.用户定义函数
用户自己定义函数,显然是开发中适合用户自身需求定义的函数。
函数的定义和调用
核心要点
Python 中,定义函数的语法如下:
def 函数名(参数列表):
““”文档字符串“””(对函数的说明,相当于注释)
函数体/若干语句
文档字符串(函数的注释)一般建议在函数体开始部分附上函数定义说明,这就是“文档字符串”,也有人称为函数的注释,我们通常用三个双引号或者单引号来实现,中间可以加入多行文字来修饰。如何查看函数功能,也就是文档字符串呢?通过help(函数名.__doc__)
要点:
1.我们使用def来定义函数,然后就是一个空格和函数名称:
(1)Python执行def 时,会创建一个函数对象,并绑定函数名变量上。
2.参数列表
(1)圆括号内是形式参数变量(我们也叫做它为形参)列表,有多个参数使用时用逗号隔开。
(2)形式参数不需要声明类型,也不需要指定函数返回值类型。
(3)无参数,也必须保留空的圆括号。
(4)实参列表必须与形参列表一一对应。
3.return返回值
(1)如果函数中包含return语句,则结束函数并返回值;
(2)如果函数中不包含return 语句,则返回None 值。
(3)要返回多个返回值,使用列表,元组,字典,集合,将多个值存起来。
4.一切皆对象,函数也不例外,由下图可知,它的类型为:function,地址为:2504950796904
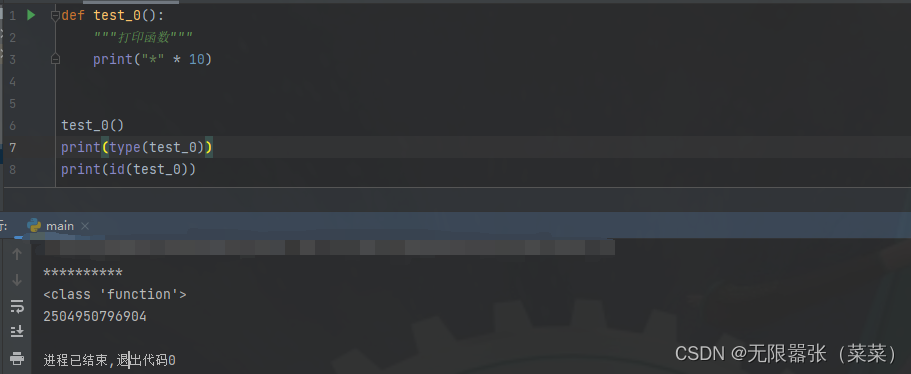
eg:没有参数时定义函数:
def test_0():"""打印函数"""print("*" * 10)test_0()5.调用函数之前,必须先定义函数,即先调用def 创建函数对象
(1)内置函数对象会自动创建
(2)标准库和第三方库函数、通过import导入模块时,会执行模块中的def语句
我们通过实际定义函数来学习函数的定义方式。
形参和实参
形参说的通俗易懂点就是定义函数时所传入的参数,实参就是调用函数时所传入的参数,接下来用一个例子来说明。
eg:定义一个函数,实现三个数字求和运算
解释:其中 a,b,c为函数定义的形参,当做局部变量来使用,出了这个范围将不能使用,d为函数的返回值,在调用时,a1,a2,a3就是我们所输入的实参。
def sum_0(a, b, c):"""实现三个数字的求和运算"""d = a + b + creturn da1 = int(input('请输入第一个数字:'))
a2 = int(input('请输入第二个数字:'))
a3 = int(input('请输入第三个数字:'))
sum_1 = sum_0(a1, a2, a3)
print(f"输出的求和结果为:{sum_1}")
函数对象的内存底层分析
Python中,一切皆对象,实际上,当我们执行所定义的函数后,系统创建了相应的函数对象,我们对上述求和函数进行底层分析。我们调用函数时,我们是调用已经创建好的函数对象,而不需要反复创建。我们测试函数也是对象,eg:
def test01()print("111111111")c = test01
c()首先程序运行代码时,是从上到下进行执行函数,当执行def 时,在堆里将创建好一个函数对象,这个函数对象,将包含了函数的参数信息,代码信息,然后在栈里边包含了一个函数变量,叫做test01,他的值就是函数对象的地址,当执行c = test01时,我们在堆里找到函数对象,执行里边的代码,每调用一次,找一次,但是吧,我们只创建一次函数对象。
变量的作用域
变量起作用的范围被称为变量的作用域,不同作用域内同名变量之间互不影响,变量分为:全局变量和局部变量。
全局变量:
1.在函数和类定义之外声明的变量。作用域为定义的模块,从定义位置开始直到模块结束。
2.全局变量降低了函数通用性和可读性,应尽量避免全局变量的使用。
3.全局变量一般当做常量使用。
4.函数内要改变全局变量的值,使用global声明一下
局部变量:
1.在函数中(包含形式参数)声明的变量
2.局部变量的引用比全局变量快,优先考虑使用。
3.如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量。
eg:
# 测试全局变量,局部变量def sum_0(a, b, c):m = 4"""实现三个数字的求和运算+4"""d = a + b + c + mreturn da1 = int(input('请输入第一个数字:'))
a2 = int(input('请输入第二个数字:'))
a3 = int(input('请输入第三个数字:'))
sum_1 = sum_0(a1, a2, a3)
print(f"输出的求和结果为:{sum_1}")底层理解:其中 m 就是一个局部变量,只能在sum_0函数中使用,作用域仅限于sum_0这个函数,则不能在函数外中调用,如果要在外边调用,则需用global 声明,而a1,a2,a3则是输入放入全局变量。当调用a1,a2,a3,a4,在栈中定义了a1,a2,a3,a4变量,堆中存的是变量得值,我们在栈中也定义了函数变量sum_0,当函数sum_0被调用时,Python中创建了栈帧,在栈帧里边就可以放局部变量,局部变量m在栈中,4这个值存放在堆中。当调用完时,栈帧就会被删除掉,当我再调用时,我再启动调用。
上式代码也可以写成全局变量形式:
# 测试全局变量,局部变量
m = 4def sum_0(a, b, c):global m"""实现三个数字的求和运算+4"""d = a + b + c + mreturn da1 = int(input('请输入第一个数字:'))
a2 = int(input('请输入第二个数字:'))
a3 = int(input('请输入第三个数字:'))
sum_1 = sum_0(a1, a2, a3)
print(f"输出的求和结果为:{sum_1}")当然在代码的编写中,在有较多代码时,我们必须要知道哪些变量是全局变量,哪些变量是局部变量,我们可以用print(local())和print(globals())来打印局部变量和全局变量。
接下来我们测试一下局部变量和全局变量的效率
局部变量的查询和访问速度都比全局变量要快,优先考虑使用局部变量,尤其在写循环的时候。在特别强调效率的地方,可以通过将全局变量转化为局部变量。
# 测试局部变量和全局变量效率import math
import timedef test01():start = time.time()n = 2k = 5for i in range(10000000):m = math.sqrt(i+n+k)end = time.time()print(f"耗时:{end-start}")n = 2
k = 5
def test02():start = time.time()l = math.sqrtfor i in range(10000000):m = l(i+n+k)end = time.time()print(f"耗时:{end-start}")test01()
test01()
由程序运行可知,局部变量所用时间较短
参数的传递
参数的传递本质就是:从形参到实参的一个赋值过程,Python中“一切皆对象”,所有的赋值操作都是“引用的赋值”。所以,Python中参数的传递都是“引用传递”,不是“值传递”。具体操作时分两类:
1.对“可变对象”进行“写操作”,直接作用于原对象本身。
2.对"不可变对象”进行“写操作”,会产生一个新的对象空间,并用新的值填充这一空间。
可变对象有:
字典、列表、集合、自定义的对象等
不可变对象:
数字、字符串、元组、function等
传递可变对象的引用
传递参数是可变对象(例如:列表、字典、自定义的其他可变对象),实际传递的还是对象的引用。在函数中不创建新的对象拷贝,而是可以直接修改所出传递的对象。
eg:
b = [10, 20, 30]def f(m):print("m:", id(m))m.append(50)f(b)
print("b",id(b))
print(b) 理解:在调用函数时,我们直接将b这个对象直接赋给m,而不会再创建新的对象m,此时在内存中m和b将指向同一个对象。
理解:在调用函数时,我们直接将b这个对象直接赋给m,而不会再创建新的对象m,此时在内存中m和b将指向同一个对象。
传递不可变对象
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),实际传递的还是对象的引用,在赋值操作时,由于不可变对象无法修改,系统会再创建一个对象。
a = 100def f(m):print("m:", id(m))m += 2print("m:", id(m))print(m)f(a)
print("a" ,id(a))
理解:一开始传递进来是a对象的地址,由于a是不可变对象,因此创建新的对象m,显然,通过id值我们已经看到m和a一开始是同一个对象,给m赋值后,m是新的对象。
浅拷贝和深拷贝
为了深入的了解参数传递的底层原理,我们需要理解Python中的浅拷贝和深拷贝。我们可以使用内置函数:copy(浅拷贝)、deepcopy(深拷贝)。
浅拷贝:不拷贝子对象的内容,只拷贝在对象的引用。
深拷贝:会连子对象的内存也拷贝一份,对子对象的修改不会影响源对象。
eg:浅拷贝
import copya = [10, 20, [5, 6]]
b = copy.copy(a)
print("a:", a)
print("b:", b)
b.append(30)
b[2].append(7)
print("浅拷贝............")
print("a:", a)
print("b:", b)
由结果可知 ,a中没有30,而b中有30,只拷贝他自己,这就浅拷贝。而传递不可变对象用到赋值操作,则用的是浅拷贝。
# 传递不可变对象,如果发生拷贝,是浅拷贝a = 10
print("a:", id(a))def test(m):print("m:", id(m))m = 20print(m)print("m:", id(m))test(a)
刚开始,a这个全局变量在栈中,值为10,在堆中,当调用函数test()时,此时也创建一个栈帧,里边有一个局部变量为m,将a的值传入m,他们所指的对象是相同的, 由上图可知,他们的id是相同的,此时有个局部变量m = 20,我们将创建一个新的对象,可知,他们的id是不同的。
eg:深拷贝
# 深拷贝测试import copya = [10, 20, [5, 6]]
b = copy.deepcopy(a)
print("a:", a)
print("b:", b)
b.append(30)
b[2].append(7)
print("浅拷贝............")
print("a:", a)
print("b:", b)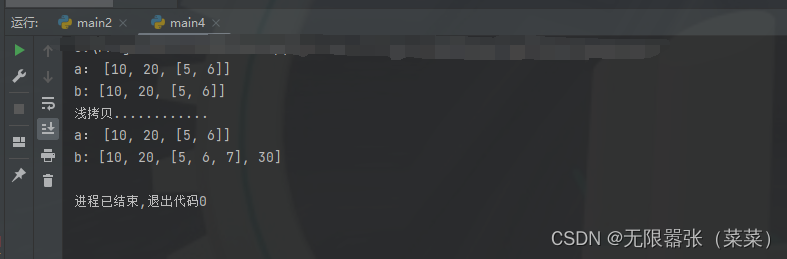
和a是纯属的独立的,把a的多有子对象都拿过来,所以拷贝完以后与a是无关的,因此a的值不会发生变化。
参数的几种类型
位置参数
函数调用时,实参默认按位置顺序传递,需要个数和形参匹配,按位置传递参数,称为位置参数
eg:
# 位置参数示例def f(a, b, c):print(a, b, c)f(1, 2, 3) # 正确
f(1,2) # 错误默认值参数
我们可认为某些参数设置默认值,这样这些参数在传递就是可选的。称为“默认值参数”,默认值参数必须放到位置参数后边。
# 位置参数示例def f(a, b, c=10, d=20):print(a, b, c, d)f(8, 9) # 如果不传,默认C = 10,d=20
f(8, 9, 100) # 如果不传d,默认d=20,a=8,b=9,c=100命名参数
我们也可以按照形参的名称传递参数,称为“命名参数”,也称为关键字参数,根据名字匹配,顺序无所喽。
# 位置参数示例def f(a, b, c):print(a, b, c)f(8, 9, 10)
f(c=10, b=9, a=8)可变参数
可变参数指的是“可变数量的参数”,分两种情况
1.*param(一个星号),将多个参数收集到一个“元组”对象。
2.**param(两个星号),将多个参数收集到一个“字典”对象中。
eg1:将 8 9 传入到 a, b 中,后边可以有好多参数,都是给了元组c
# 位置参数示例def f(a, b, *c):print(a, b, c)f(8, 9, 10, 20, 30, 40)
eg2:将 8 9 传入到 a, b 中,后边可以有好多参数,"name":"yy1","age":18,给了字典c
# 位置参数示例def f(a, b, **c):print(a, b, c)f(8, 9, name="yyq", age = 18)强制命名参数
在带星号“可变参数”后面增加新的参数,必须是“强制命名参数”,因为前边有星号,不知道长度,所以必须得强制命名参数。
def f(*a, b, c):print(a, b, c)f(1, 2, 3, b = 8, c = 9)lambda 表达式和匿名函数
lambda 表达式可以用来声明匿名函数。lambda函数是一种简单的、在同一行中定义函数的方法。lambda 函数实际生成了一个函数对象。lambda表达式只允许一个表达式,不能包含复杂语句,该表达式的计算结果就是函数的返回值
lambda表达式的基本语法如下:
lambda arg1,arg2,arg3......:<表达式>
eg:
f = lambda a, b, c:a + b + cprint(f)
print(f(1,2,3))eval()函数
功能:将字符串str当成有效的表达式来求值并返回计算结果
语法:eval(source[,globals[,locals]])
参数:
source:一个Python表达式或函数compile()返回的代码对象
globals:可选,必须是dictionary
locals:可选,任意映射对象
s = "print('abcded')"
eval(s)
a = 10
b = 20
c = eval("a+b")
print(c)dict1 = dict(a=100,b=200)
d = eval("a+b",dict1)
print(d)为什么加eval呢?有了eval 我们的代码可以从外部传进来,这样我们的程序就会很灵活,当然我们也可以出入字典,映射对象。
递归函数
递归函数很常用,它是指,自己调用自己的函数,在函数体内部直接或者间接的自己调用自己。递归类似于大家中学数学的“数学归纳法”,每个递归必须包含两部分:、
①:终止条件
表示递归什么时候结束,一般用于返回值,不再调用自己。
②:递归步骤
把第n步值和第n-1步相关联
递归函数由于会创建大量的函数对象,过量的消耗内存和运算能力,在处理数据时,谨慎使用。
eg:实现数字的阶乘
# 实现函数阶乘def faction(n):if n == 0:return 1else:k = n * faction(n - 1)return kfor i in range(10):print(f"{i}的阶乘为:", faction(i))

嵌套函数:
在函数内部定义的函数
eg:
def f1():print("f1 running>>>>>>>>")def f2():print("f2 running>>>>>>")f2()f1()
一般在什么情况下使用嵌套函数?
1.封装,数据隐藏
外部无法访问嵌套函数
2.贯彻DRY原则
嵌套函数,可以让我们在函数内部避免代码重复
3.闭包
nonlocal关键字
nonlocal 用来声明外层局部变量
外部函数有个变量,我想在内部函数中使用外部函数变量,我们就用nonlocal来声明。
eg:如果不加nonlocal来声明变量 b,内部函数将无法修改其值
# 测试 nonlocal global 关键字用法def outer():b =10def inter():nonlocal bprint("inter:",b)b=20inter()print("outer:", b)outer()
global 用来声明全局变量
LEGB规则
Python 在查找“名称”时,是按照LEGB规则查找的:Local-->Enclosed-->Global-->Built in。
local 指的是函数或者类的方法内部
Enclosed 指的是嵌套函数
Global 指的是模块中的嵌套函数
Built in 指的是Python为自己保留的特殊名称
如果某个name映射在局部(local)命名空间中没找到,接下来会在必包作用域(enclosed)进行搜索,如果必包作用域也没有找到,Python就会在全局(global)命名空间中进行查找,最后会在(built - in)命名空间搜索,如果还没有找到,就会产生NameError。