如何选择mysql的存储引擎
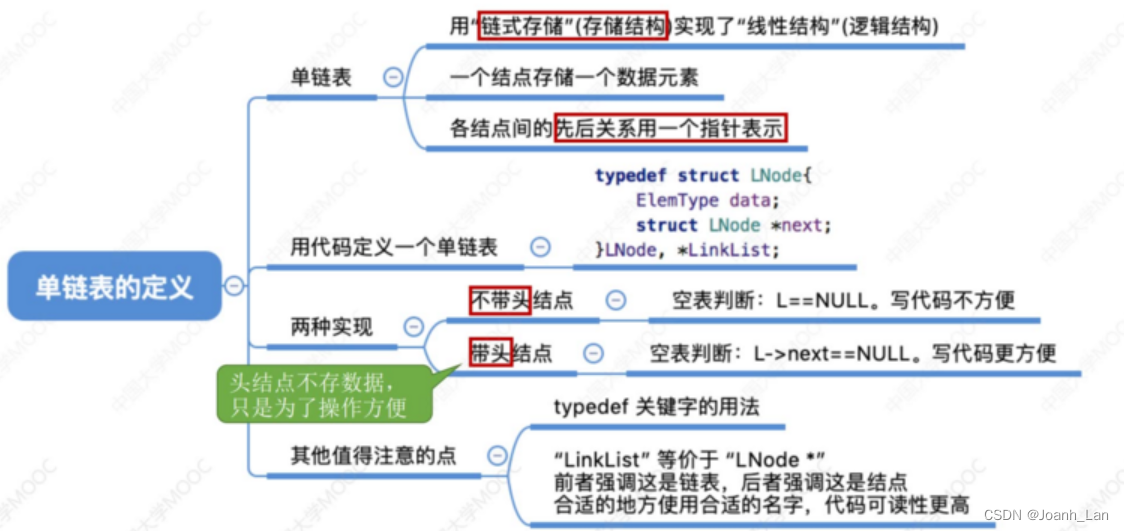
在开发中,我们经常使用的存储引擎 myisam / innodb/ memory存储引擎针对的是表和数据库
事务:MySQL事务主要用于处理操作量大,复杂度高的数据,比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱和文章等,这样,这些数据库操作语句就构成一个事务。
在MySQL中只有使用了innodb的数据库引擎的数据库或者表才支持事务。
事务的基本介绍可以参考文章:MySQL数据库优化技术一_dkjhl的博客-CSDN博客
事务处理可以用来维护数据库的完整性,保证成批的sql语句要么全部执行,要么全部不执行。
事务用来管理insert, update, delete 语句。
MyIsam存储
如果表对事务要求不高,同时是以查询和添加为主的,我们考虑使用myisam存储引擎. ,比如 bbs 中的 发帖表,回复表
INNODB 存储
对事务要求高,保存的数据都是重要数据,我们建议使用INNODB,比如订单表,账号表.
MyISAM 和 INNODB的区别
1. 事务安全: 前者不支持事务,也就不支持回滚(比如在一张表中进行转账的业务,把张三的账户的余额减掉10元,再转账到李四的账户,这种操作就不能使用myisam引擎,因为myisam的特点是有一句话执行成功,而另一句话没有执行成功过。涉及到转账和安全,就要用innodb。)
2. 查询和添加速度: 添加速度mysiam快于innodb,因为前者直接添加在表的最后,不去排序,而innodb在添加的时候要进行事务的安全校验,同时添加的时候要进行适当的排序,所以速度会慢。
3. 支持全文索引: myisam支持全文索引而innodb不支持全文索引。
4. 锁机制: myisam的锁机制是锁在表上,而innodb的锁机制是锁在行上,换言之,innodb的机制更严格,因为事务是针对一条记录而言的,因而他的锁机制,所以innodb更加安全
5. 外键 MyISAM 不支持外键, INNODB支持外键. (在PHP开发中,通常不设置外键,通常是在程序中保证数据的一致,java要使用外键。)
Memory 存储
比如我们数据变化频繁,不需要入库,同时又频繁的查询和修改,我们考虑使用memory, 速度极快. 数据在内存中。如果用不了memory cache 建议用memory存储,效果差不多。
- 尽量使用定点数来存储数值,而不要用浮点数,以此来保证数据的精确性,比如能用decimal,则不要用float
- 如果你的数据库的存储引擎是myisam,请一定记住要定时进行碎片整理,如果不进行碎片整理,会拖垮数据库;一个小的知识点,会解决一个大问题
总结
Myisam引擎用的是最多的,O2O,电商系统,一般用myisam的比较多,关于下订单的用innodb,所以在一个项目里面,这个表的引擎可能有一部分是myisam,一部分是innodb,还有一部分可能是memory
举例
create table test100(id int unsigned ,name varchar(32))engine=myisam;insert into test100 values(1,’aaaaa’);
insert into test100 values(2,’bbbb’);
insert into test100 values(3,’ccccc’);insert into test100 select id,name from test100;
这种做法就是主从复制,数据将在当前数量的基础上进行成倍的增长
delete from test100 where id=3;
假设这个时候删除了3分之一的数据,但是表的数据量没有变化,这个时候刚开始可能没有影响,但是当运行了几年之后,就会容易出现拖垮表的现象。
我们应该定时对myisam进行整理
optimize table test100;
mysql_query(“optimize tables $表名”);
数据库的备份
- 手动备份数据库(表的)方法
cmd控制台:
mysqldump –u root –proot 数据库 [表名1 表名2..] > 文件路径
比如: 把temp数据库备份到 d:\temp.bak
mysqldump –u root –proot temp > d:\temp.bak 这里面有400万的数据慎用
如果你希望备份是,数据库的某几张表
mysqldump –u root –prot temp dept > d:\temp.dept.bak
这个文件名是随意的,后缀名也是随意的。
如何使用备份文件恢复我们的数据.
mysql控制台
source d:\temp.dept.bak
- 使用定时器来自定完成
把备份数据库的指令,写入到 bat文件, 然后通过任务管理器去定时调用 bat文件.
mytask.bat 内容是:
C:\myenv\mysql5.5.27\bin\mysqldump -u root -proot temp dept > d:\temp.dept.bak
☞ 如果你的mysqldump.exe文件路径有空格,则一定要使用 “” 包括.
把mytask.bat 做成一个任务,并定时调用在 2:00 调用一次
步骤 任务计划->增加一个任务,选中你的mytask.bat文件 ,最后配置:

现在问题是,每次都是覆盖原来的备份文件,不利用我们分时间段进行备份, 我们可以这样处理; 示意图:
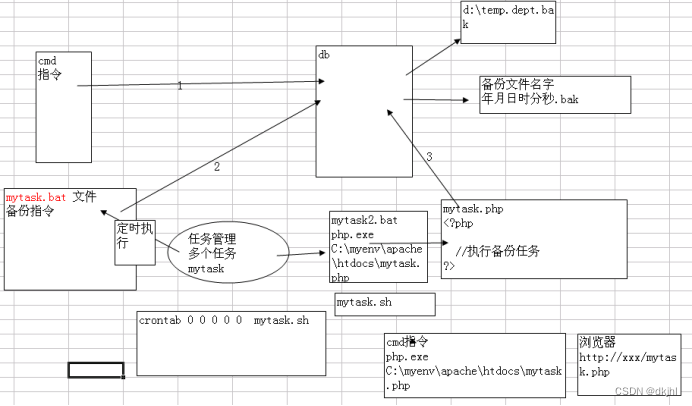
代码是:
mytask2.bat 内容:
C:\myenv\php-5.3.5\php.exe C:\myenv\apache\htdocs\mytask.php
mytask.php代码:
<?php//定时备份我们的数据库文件date_default_timezone_set('PRC');$bakfilename=date("YmdHis",time());$command="C:\myenv\mysql5.5.27\bin\mysqldump -u root -proot temp dept > d:\\{$bakfilename}";exec($command);分表技术
分表技术有
水平分割和垂直分割
当一张越来越大时候,即使添加索引还慢的话,我们可以使用分表
以qq用户表来具体的说明一下分表的操作.
比如当有5亿的数据量在一张表的时候,传统做法就是直接去查,这时候根本没有效率,若是考虑到将整张表导入到内存中去,但是也是不行的,这个表太大了,memory cache默认才64M,所以最后一种有效可行的做法就是进行分表。
水平分割:
表的结构不发生变化,表的结构也就是里面大表里面长的什么样,分出来的表也就是什么样。
思路如下:
首先我创建三张表 user0 / user1 /user2 , 然后我再创建 uuid表,该表的作用就是提供自增的id,
走代码:
create table user0(
id int unsigned primary key ,
name varchar(32) not null default '',
pwd varchar(32) not null default '')
engine=myisam charset utf8;create table user1(
id int unsigned primary key ,
name varchar(32) not null default '',
pwd varchar(32) not null default '')
engine=myisam charset utf8;create table user2(
id int unsigned primary key ,
name varchar(32) not null default '',
pwd varchar(32) not null default '')
engine=myisam charset utf8;create table uuid(
id int unsigned primary key auto_increment)engine=myisam charset utf8;编写addUser.php:
<?php//注册一个用户$con=mysql_connect("localhost","root","root");if(!$con){die("连接失败!");}mysql_select_db("temp",$con);$name=$_GET['name'];$pwd=$_GET['pwd'];//这时我们先获取用户id,id是从uuid表获取$sql="insert into uuid values(null)";if(mysql_query($sql,$con)){$id=mysql_insert_id();}//计算表名,就是,你应该把这个用户放入到哪个表$talname='user'.$id%3;$sql="insert into {$talname} values ($id,'$name','$pwd')";if(mysql_query($sql,$con)){echo '添加用户到 '.$talname.'ok';}mysql_close($con);//
<?php//注册一个用户$con=mysql_connect("localhost","root","root");if(!$con){die("连接失败!");}mysql_select_db("temp",$con);$id=intval($_GET['id']);//计算表名$tabname='user'.$id%3;$sql="select pwd from {$tabname} where id=$id";$res=mysql_query($sql,$con);if($row=mysql_fetch_assoc($res)){echo "在{$tabname}. 中发现 id号为 {$id}";}//.....思考:
如果我们做的是一个平安保险公司的一个订单(8999999999000000条)查询功能该如何处理海量表? ->按时间
1.分表的标准是依赖业务逻辑(时间/地区/....)
2.安装字符不同. a-z
3.我们给用户提供的查询界面一定是有条件,不能让用户进行大范围.(世界),如果需要的可以根据不同的规则,对应多套分表.
4.检索时候,带分页条件,减少返回的数据.
5.项目中,灵活的根据需求来考虑.
垂直分割
示意图:
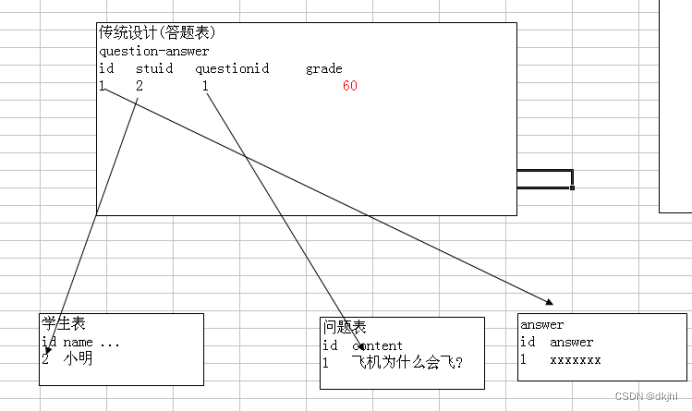
一句话: 如果一张表某个字段,信息量大,但是我们很少查询,则可以考虑把这些字段,单独的放入到一张表中,这种方式称为垂直分割.
Tinyint占用一个字节,但是我们经常看到tinyint(3),这个代表的是0填充,tinyint存放一个字节,如果是有符号的话,存放的数值的范围是-128到+127,如果全部是无符号的,那么可以存放的数值范围是255
例子:
create table test1 (id tinyint(1) primary key , name varchar(12));Create table test2(id tinyint(3) zerofill, id2 tinyint(4) zerofill);如果一个项目bigint不能表示的时候,只能用varchar来存储了,varchar能存的数据可以用一个位数来表示。拿过来之后,放在内存中,进行分阶段读取计算,读取到一定大的数据量就进行计算,计算过后,再取第二部分的数据进行计算。好比一个数组非常大,比如人口普及根据身份证号排序,这时候要用合并排序法,先取一部分读到内存中去,排好序后排出去,再读另外一部分,再排好再排出去。
Mysql的最大并发性,MySQL是一个中型数据库,最大并发数一般在2000左右就卡住了,这时候就要做服务器集群,2000左右的并发配合上页面静态化,支撑上10w是没有问题的,运用静态化+缓存技术,支撑10w问题不大,这时候一个数据库就不够用了,往往需要数据库的读写分离集群等。
关于缓存大小的设置
Query_cache_size=15M,查询缓存大小
最终要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数条的很大
Innodb_additional_mem_pool_size = 64M;
Innodb_buffen_pool_size = 1G;
对于myisan,需要调整key_buffen_size
当然调整参数还是要看状态,用show status 语句可以看到当前状态,以决定调整哪些参数。
读写分离的思想:如果数据库压力很大,一台机器支撑不了,那么可以用MySQL赋值实现多态机器同步,将数据库压力分散。
核心思想:并发数太大,分表,缓存都用到了,所以还是要进行数据库的读写分离。分表结解决只能数据库本身快速的完成。这里不再赘述,可以参考读写分离的文章:
spring完美实现读写分离+mysql实现主从复制_spring数据库主从复制_dkjhl的博客-CSDN博客
windows下实现mysql5.6读写分离、主从复制和一主多从_mysql在windows环境做读写分离_dkjhl的博客-CSDN博客
这里以java作为开发语言描述一下读写分离的内部原理
Java 处理模块与数据库之间有一个负载均衡器,判断你的java处理模块执行的是dml语句还是select语句,如果是select语句就会走另外的数据库slave数据库,这样的数据库可以有多台,而dml语句就会走主服务器master;
那么负载均衡器是如何判断select语句发送给哪一个slave服务器呢,这时候负载均衡器的作用就显示出来了,他这时候会每隔一定时间,应用轮询技术去轮询这些slave服务器,负载均衡器中有一张内置的轮询表,在内存里面跑,这张表就会记录这些从服务器的ip,状态,以及地址,当每隔一定时间去轮询一下,就会去查看这些从服务器的状态,并且将这些状态记录下来,比如slave1目前的负载是20%,(负载是内存和CPU综合考量的一个值),slave2目前的负载是80%,slave3是50%,则内置的轮询表中记录的状态就是当前这些负载值,根据这个状态值所记录的负载值进行判断,发现slave1相对空闲,让slave1去执行这个select语句。
但是这里面最难的就是如何将主服务器中的dml语句所进行后的操作同步到slave服务器上,这里面就会有很多同步的机制,MySQL也有提供,比如MySQL proxy,现在也有成型的技术,比如新浪的amoeba,通过配置文件进行配置完成,复制给slave需要通过配置文件,主要的实现思路,将dml语句执行的操作用一个日志文件记录下来,记录下来之后,通过日志文件,每隔一段时间将日志执行到slave服务器中去,也就是同步,比如隔离30秒或者1分钟。
增量备份
问题的提出:
公司的产品是在window平台下的,使用window下的MySQL5,那么MySQL5在window下是如何实现增量备份的,数据库的存储引擎myisam和innodb都有用,数据量一般每天视业务情况全备约在10G到30G之间,压缩后一般几百兆到1,2个G,这类数据库大约有几十个点,也就是说每天我的部门面的是压缩后至少20到40 G的全备份文件。
如果可以做增量备份,那么我将在每隔业务点设定每周一次全备,然后每天增量备份,每天把数据转存到异地的中心备份磁带机上,这样可以收集到所有因为诶点的所有备份,而目前我们使用的是全备,数据量太大,使用以上的方案每天至少有20到40G的数据要通过网络复制到异地,不现实,怎么解决。
增量备份的定义:
MySQL数据库会以二进制的形式,自动把用户对MySQL数据库的操作,记录到文件,当用户希望回复的时候可以使用备份文件,进行恢复。只会记录当天的记录
增量备份会记录(dml语句,创建表的语句,不会记录select语句)
记录的内容有(a操作语句本身,b操作的时间,c操作的位置position)
用户可以根据b和c来进行恢复
步骤:
(1 配置my.ini文件或者my.cof,启用二进制备份,定位mysqld,在port=3306下添加一行代码log-bin=d:/binlog/mylog,文件的磁盘位置和命名随意,这个时候要现在d盘下新建一个binlog的文件夹,这样重启才不会报错。
(2 重新启动MySQL可以得到第一个备份文件
(3 分别是d;/binlog/coollog.index 索引文件,有哪些增量备份文件
(4 和d;/binlog/coollog.000001 存放用户对数据库操作的文件
查看增量备份文件:cmd>进到mysqlbinlog mysqlbinlog d:/binlog/coollog.000001
步骤:
1、配置my.ini文件或者my.conf,启用二进制备份[mysqld]
#The TCP/IP Port the MySQL Server will listen on port=3307
#这里指定把备份文件放在哪个目录下
Log-bin=D:/binlog/coolfxl
2、重启mysql得到文件
cmd 控制台可以这样控制MySQL的启动与关闭
进入cmd ,输入net stop MySQL //停止 输入net start MySQL //重启
D:/binlog/mylog/coolfxl.index 索引文件,有哪些增量备份文件
D:/binlog/mylog/coolfxl.000001 存放用户对数据库操作的文件
可以用MySQL/bin/MySQLbinlog程序来查看 备份文件的内容
进入到cmd控制台
Cmd>mysqlbinlog 备份文件路径(绝对路径)
比如:mysqlbinlog d:\binlog\coolfxl.000001


增量备份的恢复:
利用增量备份恢复数据库文件:打开cmd控制台,进入到MySQL的安装目录:bin级目录下,比如:C:\Program Files\MySQL Server 5.5\bin>mysqlbinlog –stop-position=”21114”
利用时间点恢复:
//到下面这个时间点结束
Mysqlbinlog --stop-datetime=”2017-07-07 00:54:55” D:/binlog/coolfxl.000001 | mysql –uroot –p
//从下面这个时间点开始到最后
Mysqlbinlog --start-datetime=”2017-07-07 00:54:55” D:/binlog/coolfxl.000001 | mysql –uroot –p
时间之间可以测试
利用位置恢复:
在test.000001文件开始的地方恢复到à21114
Mysqlbinlog –stop-position=”21114” D:/binlog/coolfxl.000001 | mysql –uroot –p
//在coolfxl.000001文件2111-à最后
Mysqlbinlog –start-position=”2111” D:/binlog/coolfxl.000001 | mysql –uroot -p
//在coolfxl.000001文件751-->1195之间
Mysqlbinlog –start-position=”751” –stop-position=”1195” D:/binlog/coolfxl.000001 | mysql –uroot –p
到此备份就差不多了,当然为了更加安全的操作,可以写一段代码,将备份文件通过一个ftp操作上传到一个更加安全的服务器中去,对备份文件进行备份。将来这个备份文件越来越大的情况下又该如何处理:可以启动一个清日志的命令,清除日志。
MySQL日志的应用
mysgl有4种不同的日志,分别是
二进制日志,查询日志,慢查询日志和错误日志
这些日记记录着数据库工作的方方面面,可以帮我们了解数据库的不同方面的踪迹,下面先介绍二进制日志的作用和使用方法,并利用二进制日志对数据库进行各种维护和优化,其他日志也会在后面陆续会做详细的介绍。
二进制日志 (bin-log日志)在之前的文章介绍mysql主从配置的blog中,已经提过bin-log日志的作用和使用,bin-log日志记录了所有的DDL和DML的语句,但不包括查询的语句,语句以事件的方式保存,描述了数据的更改过程,此日志对发生灾难时数据恢复起到了极为重要的作用。
如何开启bin-log
mysql默认是没有开发bin-log日志,首先我们需要开启bin-log日志,在my.cnf中修改
[mysqld]
log-bin=/usr/share/mysql/log/mysql-bin.log
指定了bin-log日志的路径,开启日志后需要mysqladmin fush log才生效,重启后我们发现在刚才设定的路径新增了l0g文件,这就是我们需要的二进制日志
由于日志是以二进制方式存储的,不能直接读取,需要使用mysql自带的mysqlbinlog工具来进行查看,语法如下:
#mysqlbinlog mysgl-bin.000002
如何使用bin-log
现在我们尝试向test1表插入数据
mysql> insert into test1 (al,a2) alues! test1 , test2 );
然后使用mysqlbinlog工具进行日志查看
#mysqlbinlog mysql-bin.000002 -d test
......
insert into test1 (al,a2) alues! test1 , test2 )
......
清理方式
如果每天都会生成大量的二进制日志,这些日志长时间不清理的话,将会对碰盘空间带来很大的浪费,所以定期清理日志是DBA维护mysql的一个重要工作
方式一:RESET MASTER
在上面查看日志存放的文件夹中,二进制日志命名的格式是以mysql-bin,","代表日志的序号,序号是递增的,其中还有mysql-binindex是日志的索引文件记录了日志的最大序号我们执行RESET MASTER命名删除全部部日志

可以看到,以前的日志全部被清空,新的日志从00001开始
方式二:PURGE MASTER LOGS TO & PURGE MASTER LOGS BEFORE
执行PURGE MASTER LOGS TO 'mysql-bin,******' 命令,是将******编号之前的所有日志进行删除
执行PURGE MASTER LOGS BEFORE yyyy-mm-dd hh:mm:ss命令,是将在'yyyy-mm-dd hh:mm:ss' 时间之前的所有日志进行删除
方式三:EXPIRE LOGS DAYS
此参数是设置日志的过期天数,过期的日志将会被自动删除,这有利于减少我们管理日志的工作量,需要修改my.cnf

这里我们设定保存日志为3天,3天之后过期的日志将被自动删除
bin-log恢复
bin-log是记录着mysg所有事件的操作,当mysl发生灾难性错误时,可以通过bin-log做完整恢复,
基于时间点的恢复,和基于位置的恢复上面已经论述过,这里再巩固一下
完整恢复
假定我们每天凌晨2点都会使用mysql dump备份数据库,但在第二天早上9点由于数据库出现了故障,数据无法访问,需要恢复数据,先使用昨天凌晨备份的文件进行恢复到凌晨2点的状态,在使用mysql binlog恢复自mysql dump备份以来的binlog
mysgl localhost mysgl-bin.000001mysgl -uroot -p
这样数据库就可以完全的恢复到崩溃前的完全状态
基于时间点的恢复
由于误操作,比如说删除了一张表,这时使用上面讲的完全恢复是没有用的,因为日志里面还存在误操作的语句,,我们需要的是恢复到误操作前的状态,然后跳过误操作的语句,再恢复后面操作的语句,假定我们除了一张表的误操作发生在10:00这个时间点,我们可以使用下面的语句用备份和binlog将数据恢复到故障前
mysqlbinlog --stop-date='2010-09-04 9:59:59' /var/log/mysgl-bin.000001 1 mysql -uroot -p
然后跳过误操作的时间点,继续执行后面的binlog
mysglbinlog --start-date='2010-09-04 10:01:00' /var/log/mysgl-bin.000001 mysg -uroot -p
其中--stop-date=‘2010-09-04 9:59:59’和--start-date='2010-09-04 10:01:00’ 其中的时间是误操作的时间点,当然了,这个时间点需要自己计算的,而且这个时间点还可以涉及到的不只是误操作,还可以有正确的操作也被跳过去了。
基子位置恢复
由于上面提到的,使用基于时间点的恢复可能出现,在一个时间点里面可能存在误操作和其他正确的操作,所以我们需要一种更为精确的恢复方式使用mysql binlog查看二进制,可看到
其中drop tables test1这个误操作的end _og_pos为8879917,记下这个id,得出它前后操作的id分别为8879916,8879918我们将进行位置恢复操作
mysqlbinlog --stop-position='8879916' /var/og/mysgl-bin.000001 mysql -uroot -p
mysqlbinlog --start-position='8879918' /var/log/mysal-bin.0000011 mysgl -uroot -p
第一行是恢复到停止位置位置的所以事务,第二性是恢复从给定的起始位置知道二进制日志结束所有事物。
最后:如何在工作总将全备份和增量备份配合使用
方案:
每周一做一个全备份,就是mysqldump那个指令,启用增量备份,把过期时间设为>=7,这样就比较安全了,文件名称要变化,增量备份不需要定时任务,dml语句对数据库造成的压力不是很大,select不会被记录。如果出现数据库奔溃,分析是库还是表,然后根据时间和位置进行恢复。