【生信笔记】R语言easier包预测免疫治疗响应
这个包发表于2021年,以患者的RNA序列数据作为输入,来预测免疫治疗的结果。文章的DOI是:doi: 10.1016/j.patter.2021.100293.
用户手册在:http://127.0.0.1:27097/library/easier/doc/easier_user_manual.html
输入的表达矩阵要求是RNA-Seq数据,原始的Counts数据和TPM数据都可以。
easier包主要包括以下几个功能:
一、计算免疫反应的特征(Compute hallmarks of immune response)
compute_scores_immune_response函数能够对多个不同的免疫特征进行打分,主要包括:
函数里的selected_scores参数可以选择输出哪些Hallmarks。比如我们指定2个Hallmarks进行计算:
> immune_response_scores <- compute_scores_immune_response(RNA_tpm = tpm)
结果是一个dataframe,行是样本,列是分数。
> head(immune_response_scores)CYT TLS IFNy Ayers_expIS
TCGA-05-4244-01A 6.804592 8.771665 5.044553 4.562678
TCGA-05-4250-01A 43.445152 8.315098 7.135774 6.035539
TCGA-05-4382-01A 11.721161 19.004632 6.411094 5.380301
TCGA-05-4384-01A 10.612710 17.434152 4.950731 4.482248
TCGA-05-4389-01A 35.632111 16.462322 7.097995 6.227765
TCGA-05-4390-01A 4.065595 4.934187 4.510498 3.948847
二、对TME定量描述的计算
这里主要是为后面计算免疫治疗响应准备数据,分以下几个部分。
(一)细胞成分
比CIBERSORT简单一些,不需要读入LM22的文件,但是相应的只有9个类别。
> str(cell_fractions)
'data.frame': 486 obs. of 11 variables:$ B : num 0.00607 0.01211 0.02209 0.00391 0.01051 ...$ M1 : num 0.2832 0.1664 0.1915 0.1058 0.0712 ...$ M2 : num 0.0561 0.037 0.0834 0.1553 0.0607 ...$ Monocyte : num 0 0 0 0 0 ...$ Neutrophil: num 0.0543 0.0468 0.0118 0.033 0.1042 ...$ NK : num 0.00814 0 0.00452 0.00526 0.002 ...$ CD4 T : num 0.0436 0.0595 0.0353 0.0356 0.0369 ...$ CD8+ T : num 0.00919 0.03629 0.00194 0.00504 0.03537 ...$ Treg : num 0.0436 0.0221 0.0353 0.0229 0.0369 ...$ DC : num 0 0 0 0 0 ...$ Other : num 0.539 0.642 0.649 0.656 0.679 ...
(二)通路活性方面
主要是评估14条信号通路的活性,包括Androgen、EGFR、Estrogen、Hypoxia、JAK-STAT、MAPK、NFkB、p53、PI3K、TGFb、TNFa、Trail、VEGF、WNT的活性。注意这一步只能输入Counts。
> pathway_activities <- compute_pathway_activity(RNA_counts = , remove_sig_genes_immune_response = TRUE)
> str(pathway_activities)
'data.frame': 486 obs. of 14 variables:$ Androgen: num 3765 3789 3613 3869 3695 ...$ EGFR : num 53.65 210.41 9.37 -82.37 -20.52 ...$ Estrogen: num 2399 2439 2357 2425 2333 ...$ Hypoxia : num 7787 7853 8095 7170 7132 ...$ JAK-STAT: num 6883 7086 6912 6595 7129 ...$ MAPK : num 1441 1662 1357 1294 1313 ...$ NFkB : num 6823 6829 7326 6383 6561 ...$ p53 : num 4677 4646 4592 4871 4845 ...$ PI3K : num -3602 -3513 -3465 -3635 -3571 ...$ TGFb : num 3038 3224 3419 3096 2969 ...$ TNFa : num 7198 7124 7564 6556 6708 ...$ Trail : num 118 120 135 100 142 ...$ VEGF : num -417 -508 -503 -564 -488 ...$ WNT : num 630 647 698 656 697 ...
(三)转录因子活性
能够对118个转录因子的活性进行评估
> tf_activities <- compute_TF_activity(RNA_tpm = tpm)
> str(tf_activities)
'data.frame': 486 obs. of 118 variables:$ AR : num -0.709 1.233 -2.683 -1.041 -1.452 ...$ ARNTL : num 2.389 0.821 1.489 -0.25 0.22 ...$ ATF1 : num 1.191 2.22 1.093 -0.459 0.268 ...$ ATF2 : num 0.201 2.197 0.425 0.823 -0.4 ...$ ATF4 : num 0.727 1.965 0.259 -0.992 -0.409 ...$ ATF6 : num 0.825 0.341 2.062 0.326 1.216 ...$ BACH1 : num 1.216 0.497 0.338 1.645 2.544 ...$ CDX2 : num -1.3392 -0.5584 -0.8671 -0.8286 0.0699 ...$ CEBPA : num 1.775 2.059 1.663 0.097 1.424 ...$ CEBPB : num 1.084 0.993 0.781 0.482 1.155 ...$ CEBPD : num 0.4532 -0.0117 0.3975 0.5953 0.5444 ...
表格很长,这里就不全部展示了。
(四)配体-受体权重与细胞间相互作用
手册的描述:使用衍生的癌症特异性细胞间网络,可以对867个配体-受体的权重进行量化。使用配体-受体权重作为输入,可以得出169个细胞-细胞相互作用分数。结果跟上面的类似,这里也不展示了。
总结一下,这一步我们获得了cell_fractions、pathway_activities、tf_activities、lrpair_weights、ccpair_scores一共5个变量,接下来这5个变量要全部(或部分)输入到一个函数里来预测免疫治疗的响应。
三、获取患者对免疫反应的预测
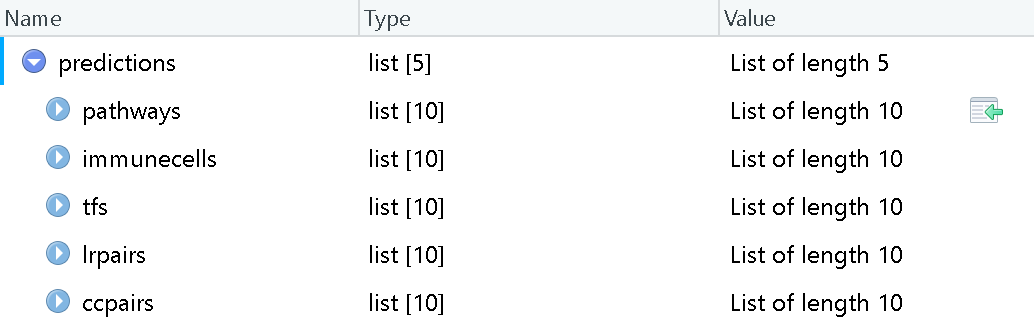
> predictions <- predict_immune_response(pathways = pathway_activities,immunecells = cell_fractions,tfs = tf_activities,lrpairs = lrpair_weights,ccpairs = ccpair_scores,cancer_type = cancer_type, verbose = TRUE)
这个函数的输入包括5个内容,都是上面计算得出来的结果。另外还需要指定癌种,主要包括:膀胱尿路上皮癌(BLCA)、BRCA浸润癌(BRCA)、宫颈癌和宫颈癌(CESC)、结直肠癌(CRC)、多形性胶质母细胞瘤(GBM)、头颈部鳞状细胞癌(HNSC)、肾透明细胞癌(KIRC)、肾肾乳头状细胞癌(KIRP)、肝细胞癌(LIHC)、肺腺癌(LUAD),肺鳞状细胞癌(LUSC)、非小细胞肺癌(NSCLC[LUAD+LUSC])、卵巢浆液性囊腺癌(OV)、胰腺癌(PAAD)、前列腺癌(PRAD)、皮肤黑色素瘤(SKCM)、胃腺癌(STAD)、甲状腺癌(THCA)、子宫内膜体癌(UCEC)。
这一步得到的结果predictions是一个list,需要进一步处理才能得到最终的预测结果。
四、得到ICB治疗的预测结果
通过函数retrieve_easier_score可以对上面的list进行处理得到easier预测的免疫治疗响应评分。如果有TMB信息还可以联合TMB信息进行评估。
> easier_derived_scores <- retrieve_easier_score(predictions_immune_response = predictions,TMB_values = TMB,easier_with_TMB = c("weighted_average", "penalized_score"),weight_penalty = 0.5)
得到的结果是一个dataframe,里面存着不同方法得到的免疫治疗响应的评分。其中easier_score是不纳入TMB信息的得分。
> str(easier_derived_scores)
'data.frame': 482 obs. of 3 variables:$ easier_score: num -0.356 0.135 0.162 -0.552 0.348 ...$ w_avg_score : num 0.229 0.268 0.395 0.213 0.285 ...$ pen_score : num -0.356 0.135 0.662 -0.552 0.348 ...
这里TMB有两种纳入的方法,一种是加权,一种是惩罚得分,可以两个都算出来看看。另外,输入的TMB必须为一个Named_num。否则会报错。
除了上面这个函数,还可以通过函数assess_immune_response进行处理。
> output_eval_with_resp <- assess_immune_response(predictions_immune_response = predictions,patient_response = patient_ICBresponse,RNA_tpm = RNA_tpm,TMB_values = TMB,easier_with_TMB = "weighted_average",weight_penalty = 0.5)
这个函数的参数patient_response是由用户提供的每个患者的治疗信息,整理成两个因子的字符向量输入(Non-responders = NR, Responders = R),如果没有治疗信息的话可以直接把这个参数删掉。
这个函数会输出一个list,里面存着几个图。
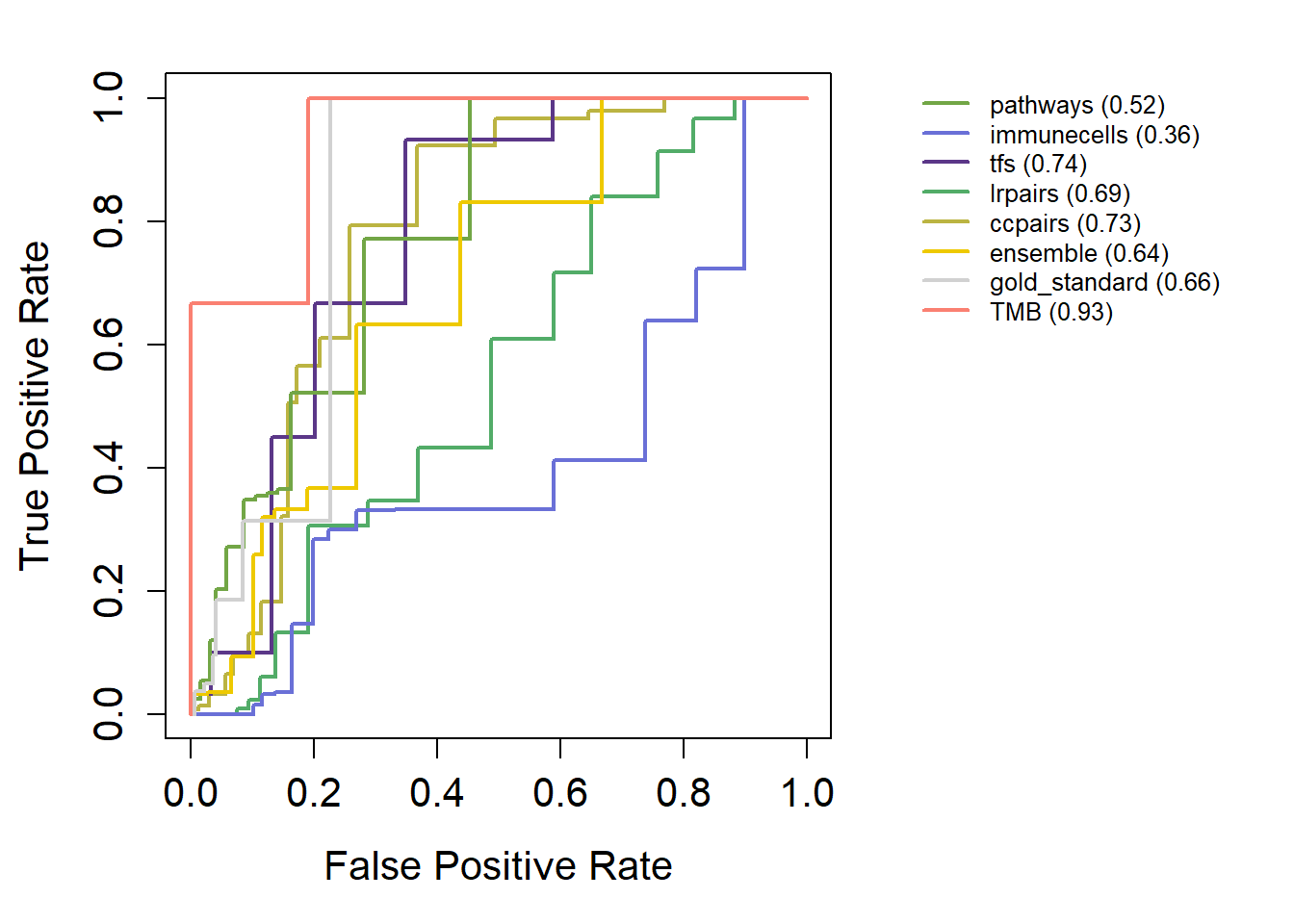
如果提供了patient_response的话,会输出一个ROC曲线和一个AUC的barplot。
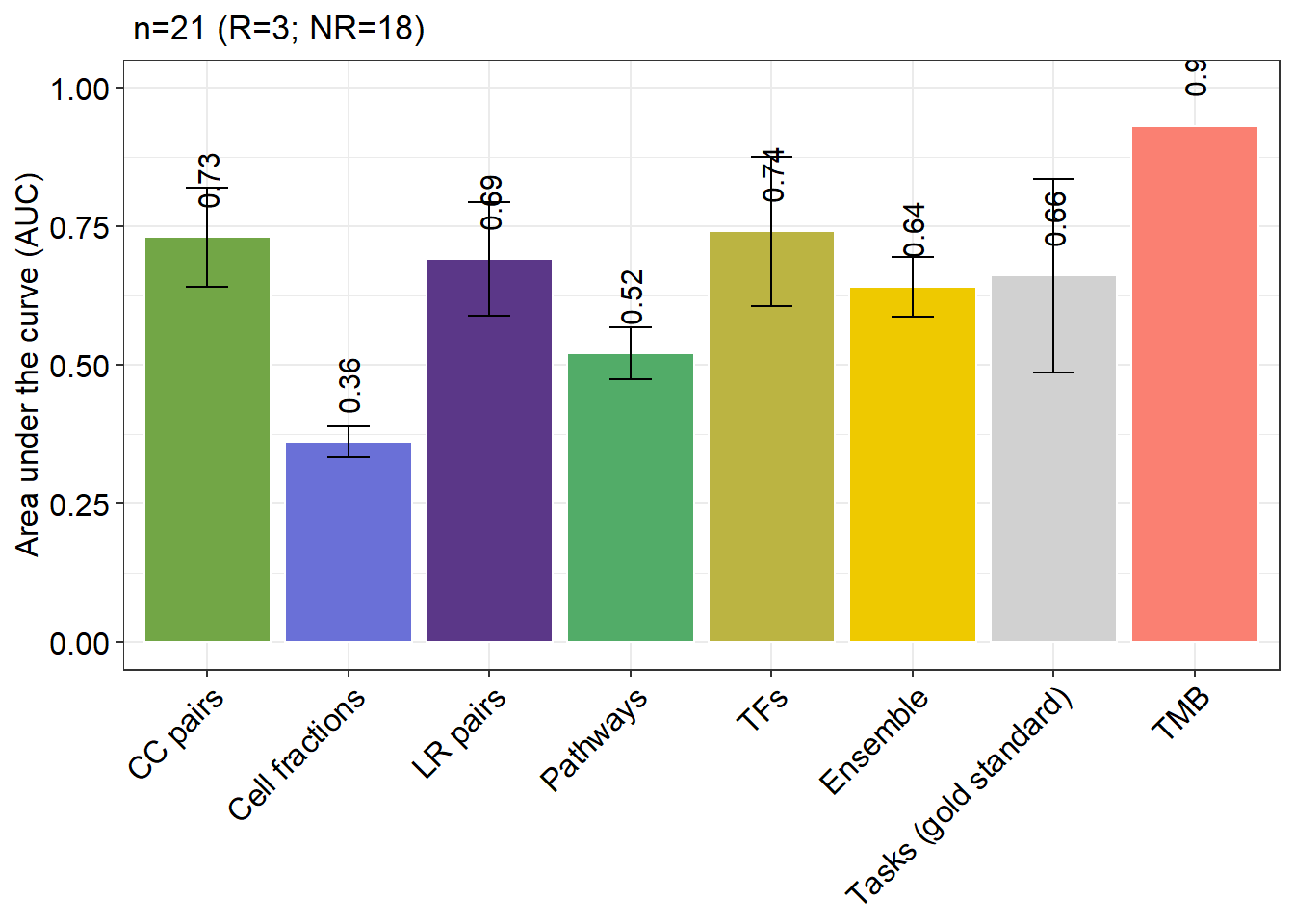
如果同时还提供了TMB的话,将返回一个散点图,显示综合方法、easier score和TMB的AUC值。
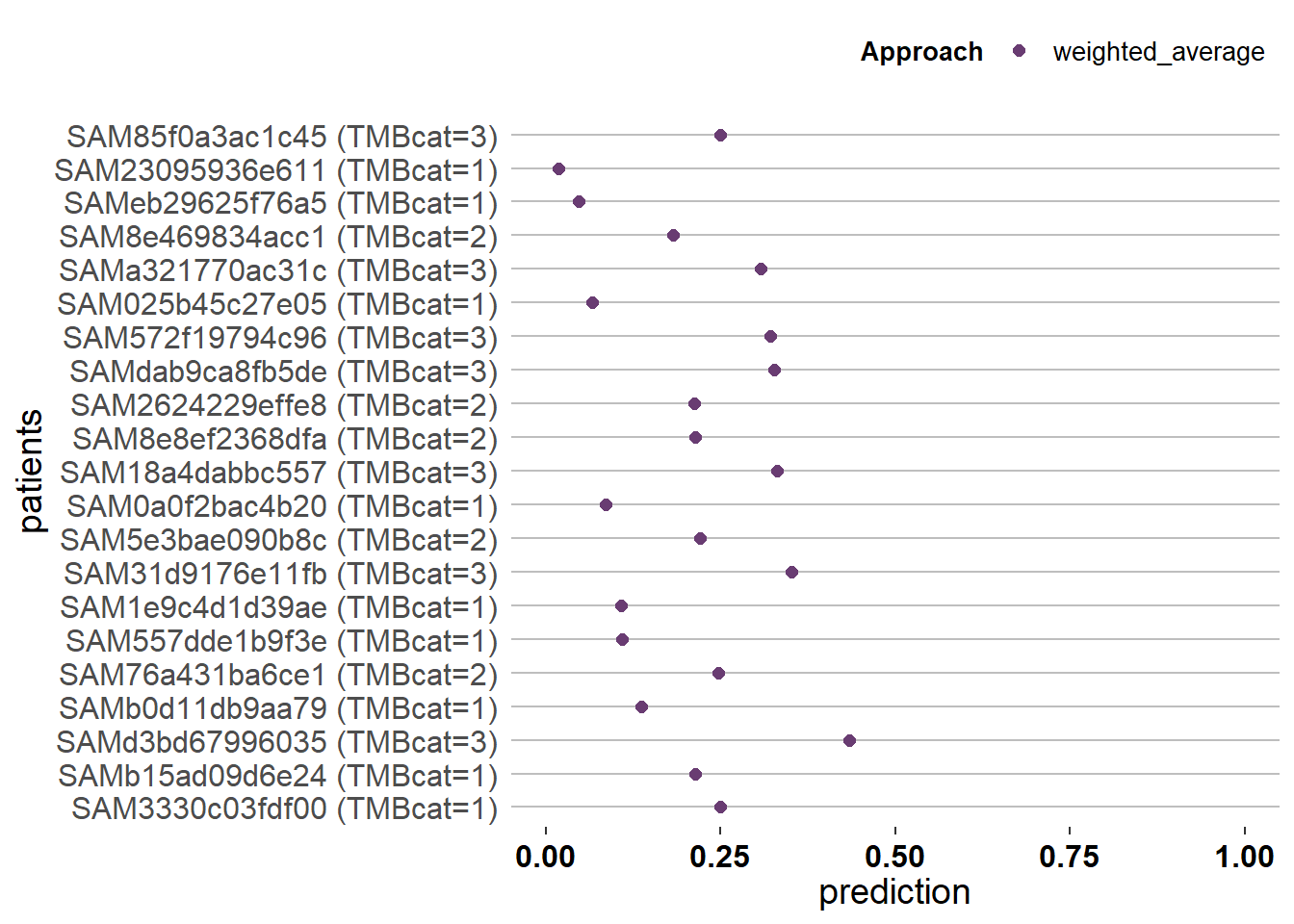
如果没有patient_response的话,将返回一个点图,代表每个患者的综合得分,同时还有一个箱线图。
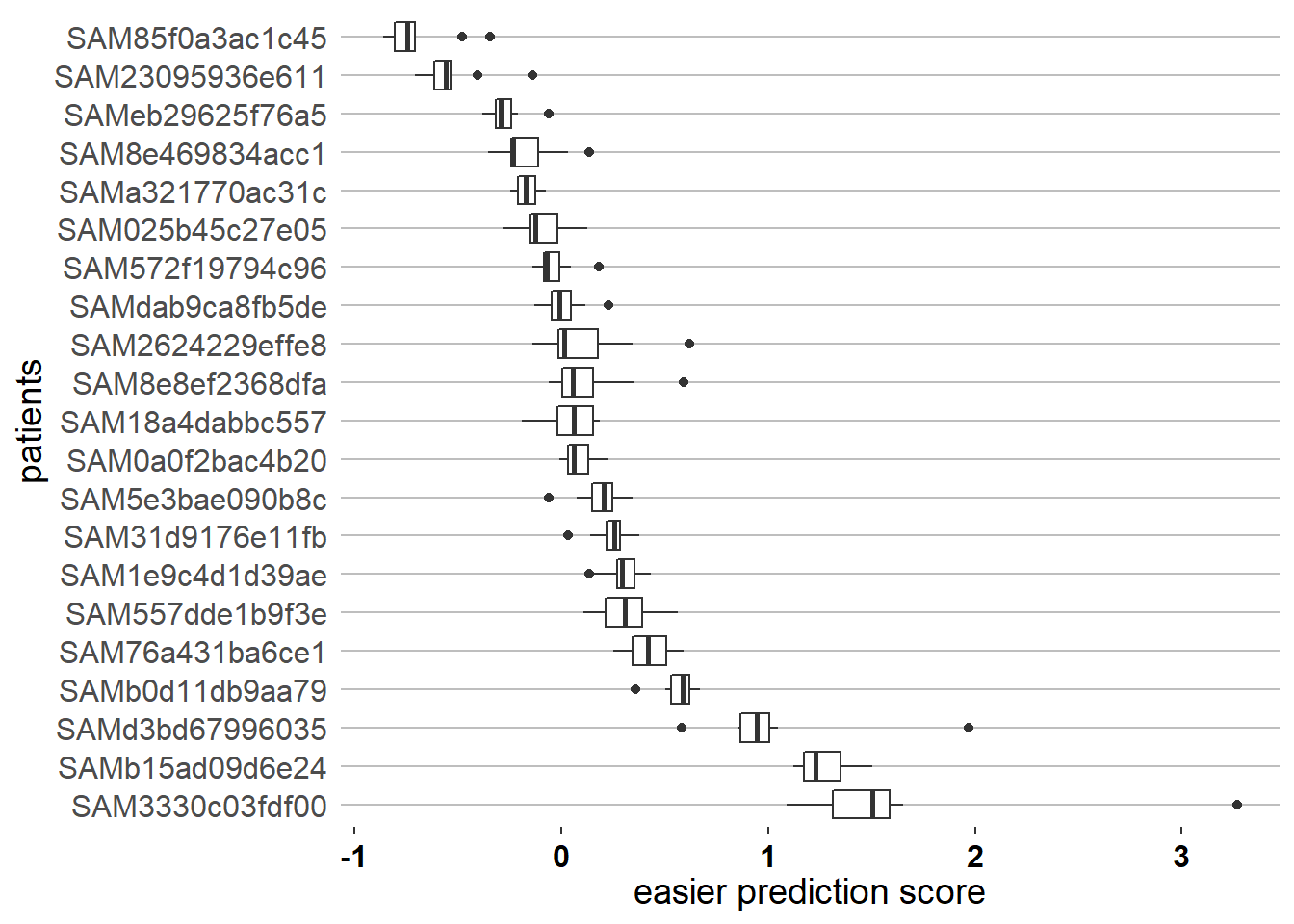
之后就可以用这个easier prediction score去做各种各样的分析啦!
ient_response的话,将返回一个点图,代表每个患者的综合得分,同时还有一个箱线图。
[外链图片转存中…(img-YSw4sICp-1650789699131)]
[外链图片转存中…(img-SzY7Szy4-1650789699132)]
之后就可以用这个easier prediction score去做各种各样的分析啦!
以上是个人对easier包的简单探索,欢迎大家批评指正、多多交流!