文章目录
- 决策树
- 实现方法
- 测试
- 更好地展示结果
- 调参
- 调整max_depth
- scoring
- 利用GridSearchCV确定最佳max_depth
- min_samples_split
- min_impurity_decrease
- max_features
- 多参数同时选优
- 采用最优参数
- 特征重要性排序
- 随机森林
- 测试
- 调参
- n_estimators
- 调整max_depth
- 调整max_features
- 调整min_samples_leaf
- 调整min_samples_split
- 调整criterion
- 多参数同时选优
- 特征重要性排序
作者:刘梦娇
决策树
决策树是一种有监督的机器学习算法,该方法可以用于解决分类和回归问题。决策树可以简单地理解为达到某一特定结果的一系列决策。包含分类树(classification tree)和回归树(regression tree)。
实现方法
sklearn.tree模块中提供了很多关于决策树的类,tree.DecisionTreeClassifier可实现分类树模型,tree.DecisionTreeRegressor可实现回归树模型。
sklearn.tree.DecisionTreeClassifier(criterion="entropy" #不纯度的计算方法。"entropy"表示使用信息熵,ID3算法,此时sklearn实际计算的是基于信息熵的信息增益(Information Gain);"gini"表示使用基尼系数,CART算法,splitter="best" #控制决策树中的随机选项。“best”表示在分枝时会优先选择重要的特征进行分枝;“random”表示分枝时会更加随机,常用来防止过拟合,max_depth=10 #限制树的最大深度,深度越大,越容易过拟合。,min_samples_split=5 #节点必须包含训练样本的个数。,min_samples_leaf=1 #叶子最少包含样本的个数,min_weight_fraction_leaf=0.0 #基于权重的剪枝参数,如果样本是加权的,则使用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重的总和的一小部分。,max_features=None #限制分枝的特征个数,random_state=None #输入任意数字会让模型稳定下来。加上random_state这个参数后,score就不会总是变化。随机性越大,效果一般越好,因此一般不设置,若追求稳定性可设置成固定值,max_leaf_nodes=None #最大叶子节点数量,在最佳分枝下,以max_leaf_nodes为限制来生长树。默认没有节点数量的限制。,min_impurity_decrease=0.0 #限制信息增益的大小,信息增益小于设定值分枝不会发生,min_impurity_split=None #节点必须含有最小信息增益再划分,class_weight=None #设置样本的权重,当正反样本差别较大时,又需要对少的样本进行精确估计时使用,搭配min_weight_fraction_leaf来剪枝,presort=False #是否预先分配数据以加快拟合中最佳分枝的发现。在大型数据集上使用默认设置决策树时,将这个参数设置为True,可能会延长训练过程,降低训练速度。当使用较小数据集或限制树的深度时,设置这个参数为True,可能会加快训练速度。)测试
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score, confusion_matrix, classification_report
# 导入数据
iris=datasets.load_iris()
X=pd.DataFrame(iris.data,columns=iris.feature_names)
Y=pd.DataFrame(iris.target,columns=['target'])
#分割测试集和训练集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size=0.25,random_state=1)#训练模型
tree_clf=DecisionTreeClassifier()
tree_clf=tree_clf.fit(Xtrain,Ytrain)
Ypred = tree_clf.predict(Xtest)
train_score=tree_clf.score(Xtrain,Ytrain)
test_score=tree_clf.score(Xtest,Ytest)##导入测试集,由接口score得到模型的得分
print(f'train score: {train_score}, test score: {test_score}')#测试集具体预测情况
confmat = confusion_matrix(y_true=Ytest, y_pred=Ypred)#输出混淆矩阵
print(confmat)# 混淆矩阵并可视化
# 查准率、查全率、F1值
print('precision:%.3f' % precision_score(y_true=Ytest, y_pred=Ypred,average= 'macro'))
print('recall:%.3f' % recall_score(y_true=Ytest, y_pred=Ypred,average= 'macro'))
print('F1:%.3f' % f1_score(y_true=Ytest, y_pred=Ypred,average= 'macro'))
更好地展示结果
from sklearn import tree
import matplotlib.pyplot as plt
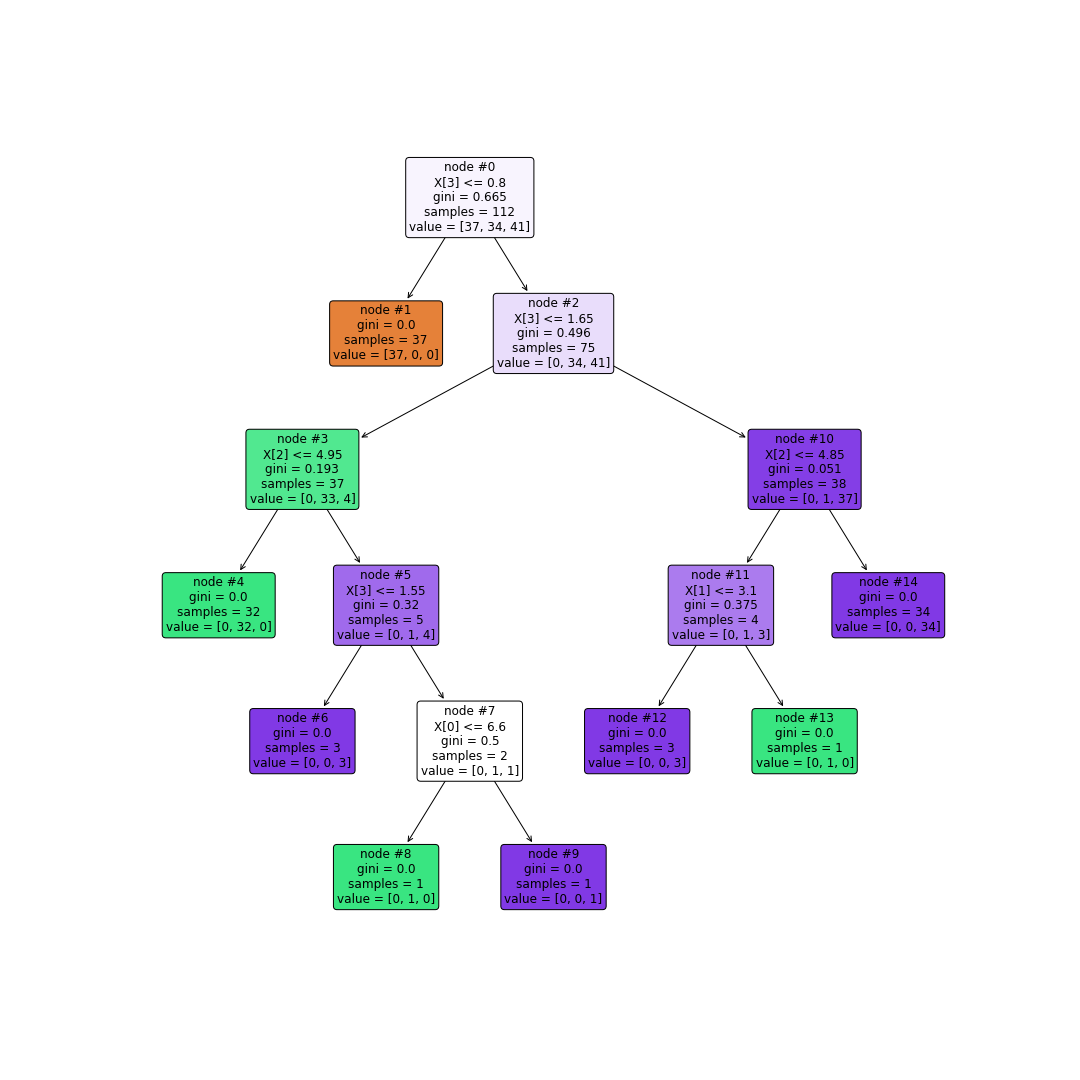
# 对决策树进行美化并保存决策树图片到本地plt.figure(figsize=(15,15)) #设置画布大小(单位为英寸)
tree.plot_tree(tree_clf #训练好的决策树评估器,node_ids=True #显示节点id,filled=True #给节点填充颜色,rounded=True #节点方框变成圆角,fontsize=12 #节点中文本的字体大小)plt.savefig("决策树.png") #保存图片一定要在plt.show()之前
plt.show()
调参
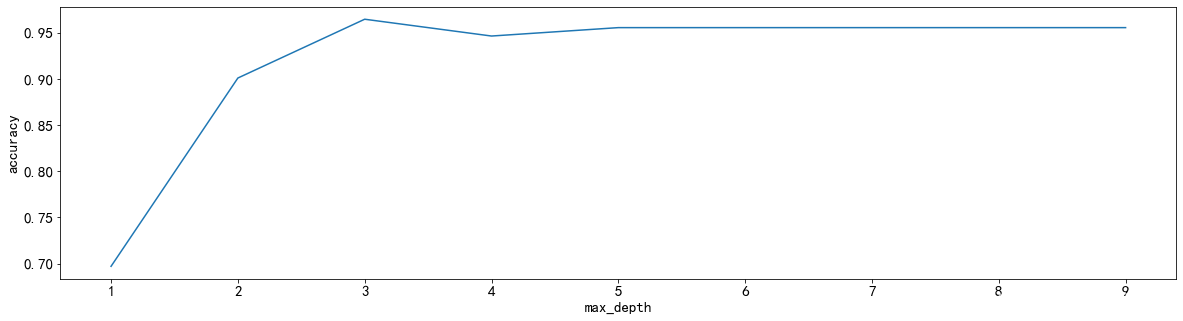
调整max_depth
from sklearn.model_selection import cross_val_score
scorel = []
for i in range(1,10,1):#实例化决策树分类器#随机的模式为1dtc = DecisionTreeClassifier(max_depth=i,random_state=1)#使用交叉验证为我们的模型打分,然后求平均值score = cross_val_score(dtc,Xtrain,Ytrain,cv=10,n_jobs=-1).mean()#将我们的模型的分数追加到我们的结果列表中scorel.append(score)
##将列表中的最大值,也就是最好的打分打印出来
print(max(scorel),([*range(1,10)][scorel.index(max(scorel))]))
plt.figure(figsize=[20,5])
plt.plot(range(1,10,1),scorel)
plt.xlabel('max_depth')
plt.ylabel('accuracy')
plt.show()
scoring
对模型评价的scoring可设置的参数包括:accuracy、average_precision、f1、f1_micro、f1_macro、f1_weighted、f1_samples、neg_log_loss、roc_auc等
F1-score:是统计学中用来衡量二分类模型精确度的一种指标,用于测量不均衡数据的精度。它同时兼顾了分类模型的精确率和召回率。F1-score可以看作是模型精确率和召回率的一种加权平均,它的最大值是1,最小值是0。
在多分类问题中,如果要计算模型的F1-score,则有两种计算方式,分别为micro-F1和macro-F1,这两种计算方式在二分类中与F1-score的计算方式一样,所以在二分类问题中,计算micro-F1=macro-F1=F1-score,
micro-F1和macro-F1都是多分类F1-score的两种计算方式;
除了micro-F1和macro-F1,还有weighted-F1,是一个将F1-score乘以该类的比例之后相加的结果,也可以看做是macro-F1的变体吧。
micro-F1:多分类问题,若数据极度不平衡会影响结果;
macro-F1:多分类问题,不受数据不平衡影响,容易受到识别性高(高recall、高precision)的类别影响;
由于我们的问题是多分类问题,我们在这里采用f1_micro或者f1_macro。
scorel = []
for i in range(1,10,1):#实例化决策树分类器#随机的模式为1dtc = DecisionTreeClassifier(max_depth=i,random_state=1)#使用交叉验证为我们的模型打分,然后求平均值score = cross_val_score(dtc,Xtrain,Ytrain,cv=10,scoring='f1_micro',n_jobs=-1).mean()#将我们的模型的分数追加到我们的结果列表中scorel.append(score)
##将列表中的最大值,也就是最好的打分打印出来
print(max(scorel),([*range(1,10)][scorel.index(max(scorel))]))
plt.figure(figsize=[20,5])
plt.plot(range(1,10,1),scorel)
plt.ylabel('f1_micro')
plt.xlabel('max_depth')
plt.show()
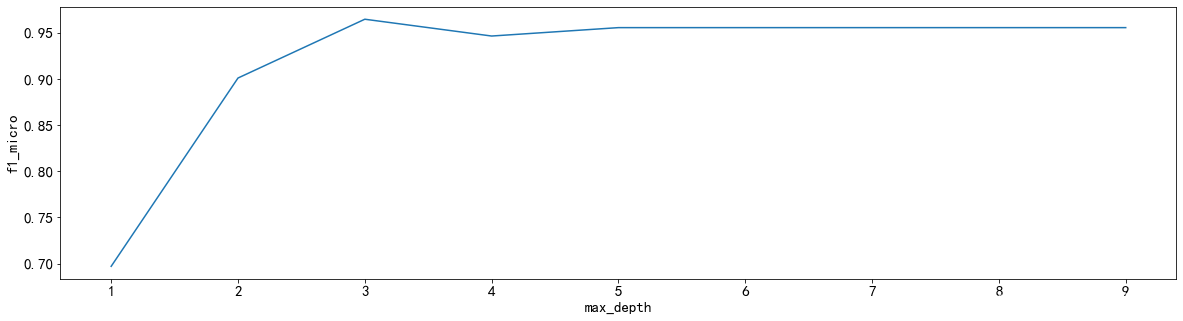
可以发现,改变scoring的评价方式,对max_depth的选择并没有变化。
利用GridSearchCV确定最佳max_depth
param_grid = {'max_depth':np.arange(1, 10, 1)}
# 一般根据数据的大小来进行一个试探,鸢尾花数据很小,所以可以采用1~10,或者1~20这样的试探
dtc = DecisionTreeClassifier(random_state=1)
GS = GridSearchCV(dtc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain)
GS.best_params_
#{'max_depth': 3}
GS.best_score_
#0.9643939393939395
min_samples_split
param_grid = {'min_samples_split':np.arange(2, 30, 1)}
dtc = DecisionTreeClassifier(random_state=1)
GS = GridSearchCV(dtc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain)
GS.best_params_
#{'min_samples_split': 5}
GS.best_score_
#0.9734848484848484
min_impurity_decrease
param_grid = {'min_impurity_decrease':np.arange(0, 20, 0.2)}
dtc = DecisionTreeClassifier(random_state=1)
GS = GridSearchCV(dtc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain)
GS.best_params_
#{'min_impurity_decrease': 0.0}
GS.best_score_
#0.9553030303030303
max_features
param_grid = {'max_features':np.arange(1, 5, 1)}
dtc = DecisionTreeClassifier(random_state=1)
GS = GridSearchCV(dtc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain)
GS.best_params_
#{'max_features': 4}
GS.best_score_
#0.9553030303030303
多参数同时选优
param_grid = {'max_depth':np.arange(1, 10, 1),'min_samples_split':np.arange(2, 30, 1),'min_impurity_decrease':np.arange(0, 20, 0.2),'max_features':np.arange(1, 5, 1)}
dtc = DecisionTreeClassifier(random_state=1)
GS = GridSearchCV(dtc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain)
GS.best_params_
#{'max_depth': 4,#'max_features': 4,#'min_impurity_decrease': 0.0,#'min_samples_split': 5}GS.best_score_
# 0.9734848484848484
采用最优参数
clf = DecisionTreeClassifier(max_depth=4,min_samples_split=5,min_impurity_decrease=0,max_features=4,random_state=1)
tree_clf=clf.fit(Xtrain,Ytrain)## 用决策树模型拟合构造的数据集
Ypred = clf.predict(Xtest)
train_score=clf.score(Xtrain,Ytrain)##导入训练集,由接口score得到模型的得分
test_score=clf.score(Xtest,Ytest)##导入测试集,由接口score得到模型的得分
print(train_score,test_score)confmat = confusion_matrix(y_true=Ytest, y_pred=Ypred)#输出混淆矩阵
print(confmat)# 混淆矩阵并可视化
# 查准率、查全率、F1值
print('precision:%.3f' % precision_score(y_true=Ytest, y_pred=Ypred,average= 'macro'))
print('recall:%.3f' % recall_score(y_true=Ytest, y_pred=Ypred,average= 'macro'))
print('F1:%.3f' % f1_score(y_true=Ytest, y_pred=Ypred,average= 'macro'))

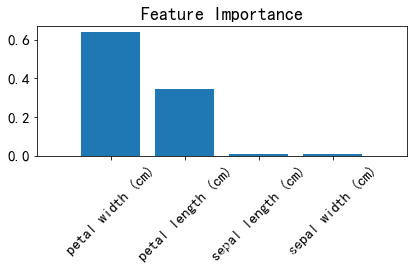
特征重要性排序
importances = clf.feature_importances_
indices = np.argsort(importances)[::-1]
feat_labels = Xtrain.columns
plt.title('Feature Importance')
plt.bar(range(Xtrain.shape[1]), importances[indices], align='center')
plt.xticks(range(Xtrain.shape[1]), feat_labels[indices], rotation=45)
plt.xlim([-1, Xtrain.shape[1]])
plt.tight_layout()
plt.show()
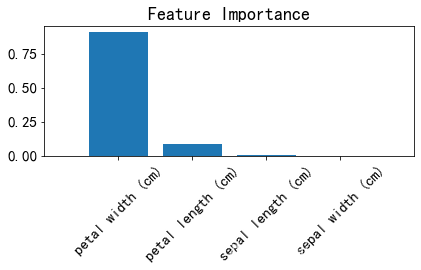
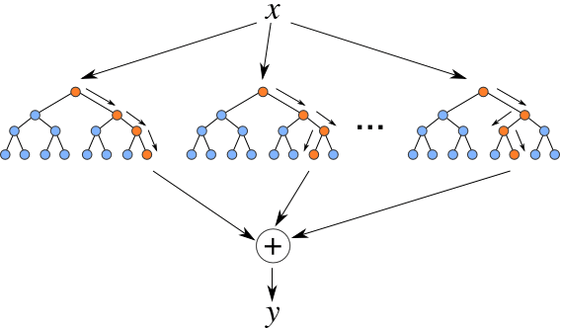
随机森林
随机森林算法用多棵(随机生成的)决策树来生成最后的输出结果。sklearn.ensemble模块中的RandomForestClassifier可以实现随机森林。
RandomForestClassifier(n_estimators=100, 随机森林中决策树的个数,默认为 100。若n_estimators太小容易欠拟合,太大不能显著的提升模型。criterion='gini', 随机森林中决策树的算法,可选的有两种:gini:基尼系数,也就是CART算法,为默认值。entropy:信息熵,也就是ID3算法。max_depth=None, 决策树的最大深度。决策树最大深度。若等于None,表示决策树在构建最优模型的时候不会限制子树的深度。如果模型样本量多,特征也多的情况下,推荐限制最大深度;若样本量少或者特征少,则不限制最大深度。min_samples_split=2, 节点可分的最小样本数,默认值是2。min_samples_leaf=1, 叶子节点含有的最少样本。若叶子节点样本数小于min_samples_leaf,则对该叶子节点和兄弟叶子节点进行剪枝,只留下该叶子节点的父节点。默认值是1。min_weight_fraction_leaf=0.0, 叶节点上所需的总权重的最小加权分数。当没有提供sample_weight时,样本具有相等的权值。max_features='auto', 构建决策树最优模型时考虑的最大特征数。默认是auto,表示最大特征数是N的平方根max_leaf_nodes=None, 最大叶子节点数。int设置节点数,None表示对叶子节点数没有限制。min_impurity_decrease=0.0, 节点划分的最小不纯度。假设不纯度用信息增益表示,若某节点划分时的信息增益大于等于min_impurity_decrease,那么该节点还可以再划分;反之,则不能划分。min_impurity_split=None, 提前停止的阈值。如果一个节点的不纯度高于阈值,则该节点将拆分,否则,它是一个叶子。bootstrap=True, 是否对样本集进行有放回抽样来构建树,True表示是,默认值Trueoob_score=False, 是否采用袋外样本来评估模型的好坏,True代表是,默认值False,袋外样本误差是测试数据集误差的无偏估计,所以推荐设置True。n_jobs=None, 并行计算数。默认是Nonerandom_state=None, 控制bootstrap的随机性以及选择样本的随机性。verbose=0, 在拟合和预测时控制详细程度。默认是0。warm_start=False, 不常用class_weight=None, 每个类的权重,可以用字典的形式传入{class_label: weight}。ccp_alpha=0.0, 将选择成本复杂度最大且小于ccp_alpha的子树。默认情况下,不执行修剪。max_samples=None,如果为None(默认),则抽取X.shape[0]样本。如果为int,则抽取max_samples样本。如果为float,则抽取max_samples*X.shape[0]个样本。因此,max_samples应该在(0,1)中。是0.22版中的新功能。)
测试
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
#sklearn.ensemble库,支持众多集成学习算法和模型
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
from sklearn.metrics import precision_score, recall_score, f1_score, confusion_matrix, classification_reportfrom sklearn import datasets
iris=datasets.load_iris()
X=pd.DataFrame(iris.data,columns=iris.feature_names)
Y=pd.DataFrame(iris.target,columns=['target'])
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size=0.25,random_state=1)clf=RandomForestClassifier(random_state=1)
#使用.values.ravel()原因>>>>>>>>>>数据转换警告:当需要一维数组时,传递了列向量y。请将Y的形状更改为(n_samples,),例如使用ravel()。
tree_clf=clf.fit(Xtrain,Ytrain.values.ravel())## 用决策树模型拟合构造的数据集
Ypred = clf.predict(Xtest)
train_score=clf.score(Xtrain,Ytrain.values.ravel())##导入训练集,由接口score得到模型的得分
test_score=clf.score(Xtest,Ytest.values.ravel())##导入测试集,由接口score得到模型的得分
print(train_score,test_score)
########测试集具体预测情况
confmat = confusion_matrix(y_true=Ytest.values.ravel(), y_pred=Ypred)#输出混淆矩阵
print(confmat)# 混淆矩阵并可视化
# 查准率、查全率、F1值
print('precision:%.3f' % precision_score(y_true=Ytest.values.ravel(), y_pred=Ypred,average= 'macro'))
print('recall:%.3f' % recall_score(y_true=Ytest.values.ravel(), y_pred=Ypred,average= 'macro'))
print('F1:%.3f' % f1_score(y_true=Ytest.values.ravel(), y_pred=Ypred,average= 'macro'))

调参
n_estimators
调优随机森林的主要参数是n_estimators参数。一般来说,森林中的树越多,泛化性能越好,但它会减慢拟合和预测的时间。
随机森林调整的第一步:无论如何先来调n_estimators,以10为分隔点
#我们n_estimators对于模型准确率的影响是十分大的,所以需要多次调整
#这一步我们只要目的是在绘制n_estimators的学习曲线。
#这里当然也可以使用GridSearch网格搜索,但是只有学习曲线才能看见趋势
scorel = []
for i in range(0,200,10):#实例化随机森林分类器#让n_estimator,也就是树的数量不断增长#然后动用全部的计算资源去计算#随机的模式为1rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1,#表示使用CPU所有的线程数进行运算,起到并行加速的作用random_state=1)#使用交叉验证为我们的模型打分,然后求平均值score = cross_val_score(rfc,Xtrain,Ytrain.values.ravel(),cv=10,n_jobs=-1).mean()#将我们的模型的分数追加到我们的结果列表中scorel.append(score)
#将列表中的最大值,也就是最好的打分打印出来
#并且打印其运行时n_estimators所设置的参数,也就是树的数量
print(max(scorel),(scorel.index(max(scorel))*10)+1)
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.xlabel('n_estimators')
plt.ylabel('accuracy')
plt.show()
#我们第一步的学习曲线只是给我们确定一个大致的范围
#现在我们知道我们的n_estimators在大概在10的范围左右将会有一个峰值
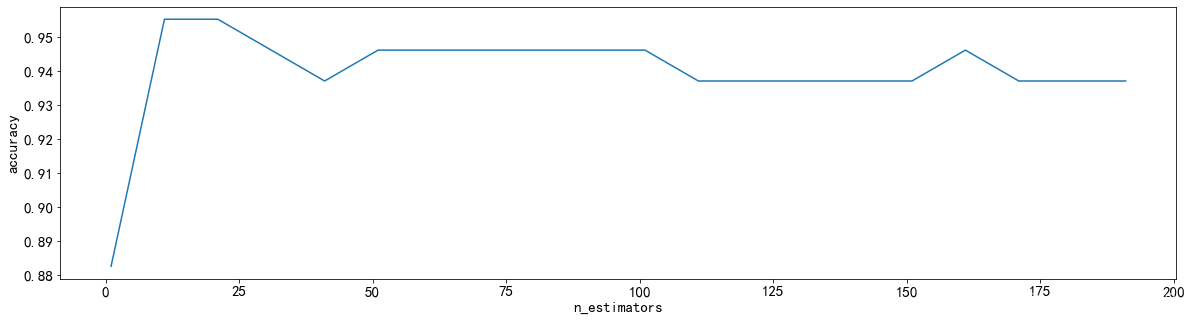
我们第一步的学习曲线只是给我们确定一个大致的范围,根据上面的显示最优点在10附近,进一步细化学习曲线。 即现在我们知道我们的n_estimators在大概10的范围左右将会有一个峰值
scorel = []
#由于我们上面得知的最好的n_estimators大概在10左右,所以我们可以探索5-15之间有没有更好的结果
for i in range(5,15):rfc = RandomForestClassifier(n_estimators=i,n_jobs=-1,random_state=1)score = cross_val_score(rfc,Xtrain,Ytrain.values.ravel(),cv=10,n_jobs=-1).mean()scorel.append(score)
#打印出最大的打分和在5到15中,分数最高的时候所对应的索引
print(max(scorel),([*range(5,15)][scorel.index(max(scorel))]))
plt.figure(figsize=[20,5])
plt.xlabel('n_estimators')
plt.ylabel('accuracy')
plt.plot(range(5,15),scorel)
plt.show()
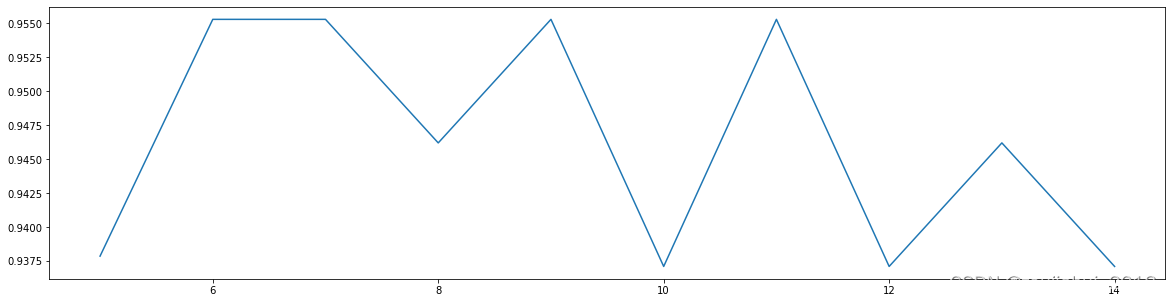
调整max_depth
param_grid = {'max_depth':np.arange(1, 10, 1)}
# 一般根据数据的大小来进行一个试探,鸢尾花数据很小,所以可以采用1~10,或者1~20这样的试探
rfc = RandomForestClassifier(n_estimators=6,n_jobs=-1,random_state=1)
GS = GridSearchCV(rfc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain.values.ravel())

调整max_features
param_grid = {'max_features':np.arange(2,5,1)}
rfc = RandomForestClassifier(n_estimators=6,max_depth=5,n_jobs=-1,random_state=1)
GS = GridSearchCV(rfc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain.values.ravel())

调整min_samples_leaf
param_grid={'min_samples_leaf':np.arange(1,1+10,1)}
#对于min_samples_split和min_samples_leaf,一般是从他们的最小值开始向上增加10或20
#面对高维度高样本量数据,如果不放心,也可以直接+50,对于大型数据,可能需要200~300的范围
#如果调整的时候发现准确率无论如何都上不来,那可以放心大胆调一个很大的数据,大力限制模型的复杂度
rfc = RandomForestClassifier(n_estimators=6,max_depth=5,max_features=2,n_jobs=-1,random_state=1)
GS = GridSearchCV(rfc,param_grid,cv=10,n_jobs=-1,)
GS.fit(Xtrain,Ytrain.values.ravel())

调整min_samples_split
param_grid={'min_samples_split':np.arange(2, 2+20, 1)}
rfc = RandomForestClassifier(n_estimators=6,max_depth=5,max_features=2,min_samples_leaf=1,n_jobs=-1,random_state=1)
GS = GridSearchCV(rfc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain.values.ravel())

调整criterion
param_grid = {'criterion':['gini', 'entropy']}
rfc = RandomForestClassifier(n_estimators=6,max_depth=5,max_features=2,min_samples_leaf=1,min_samples_split=2,n_jobs=-1,random_state=1)
GS = GridSearchCV(rfc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain.values.ravel())

多参数同时选优
param_grid = {'max_depth':np.arange(1, 10, 1),'max_features':np.arange(2,5,1),'min_samples_leaf':np.arange(1,1+10,1),'min_samples_split':np.arange(2, 2+20, 1),'criterion':['gini', 'entropy']}
rfc = RandomForestClassifier(n_estimators=6,n_jobs=-1,random_state=1)
GS = GridSearchCV(rfc,param_grid,cv=10,n_jobs=-1)
GS.fit(Xtrain,Ytrain.values.ravel())

clf = RandomForestClassifier(n_estimators=6,criterion='entropy',max_depth=3,max_features=3,min_samples_leaf=3,min_samples_split=2,n_jobs=-1,random_state=1)
tree_clf=clf.fit(Xtrain,Ytrain.values.ravel())## 用决策树模型拟合构造的数据集
Ypred = clf.predict(Xtest)
train_score=clf.score(Xtrain,Ytrain.values.ravel())##导入训练集,由接口score得到模型的得分
test_score=clf.score(Xtest,Ytest.values.ravel())##导入测试集,由接口score得到模型的得分
print(train_score,test_score)
########集具体预测情况
confmat = confusion_matrix(y_true=Ytest.values.ravel(), y_pred=Ypred)#输出混淆矩阵
print(confmat)# 混淆矩阵并可视化
# 查准率、查全率、F1值
print('precision:%.3f' % precision_score(y_true=Ytest.values.ravel(), y_pred=Ypred,average= 'macro'))
print('recall:%.3f' % recall_score(y_true=Ytest.values.ravel(), y_pred=Ypred,average= 'macro'))
print('F1:%.3f' % f1_score(y_true=Ytest.values.ravel(), y_pred=Ypred,average= 'macro'))

特征重要性排序
importances = clf.feature_importances_
indices = np.argsort(importances)[::-1] # 取反后是从大到小
feat_labels = Xtrain.columns
plt.title('Feature Importance')
plt.bar(range(Xtrain.shape[1]), importances[indices], align='center')
plt.xticks(range(Xtrain.shape[1]), feat_labels[indices], rotation=45)
plt.xlim([-1, Xtrain.shape[1]])
plt.tight_layout()
plt.show()