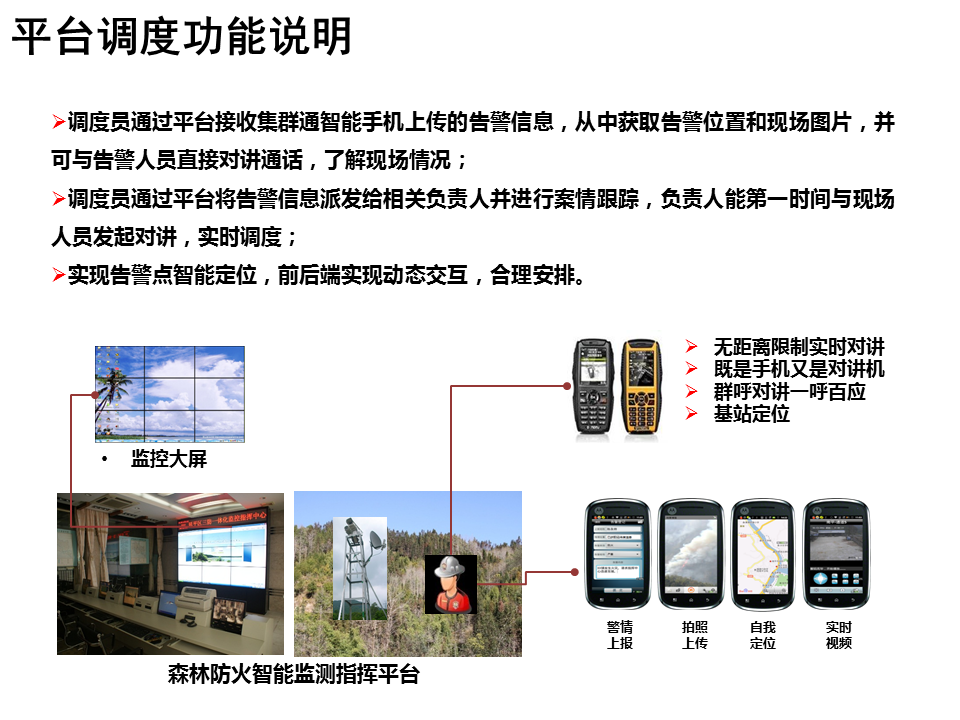
基于随机森林算法的糖尿病数据集回归
- 作者介绍
- 1. 随机森林算法原理
- 1.1决策树与Bagging
- 1.2 随机森林算法
- 2. 实验过程
- 2.1 糖尿病数据集
- 2.2 实验过程
- 2.3 实验结果展示
- 2.4 完整实验代码
作者介绍
李怡格,女,西安工程大学电子信息学院,2021级硕士研究生
研究方向:脑电情绪识别
电子邮件:1719614085@qq.com
孟莉苹,女,西安工程大学电子信息学院,2021级硕士研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:2425613875@qq.com
1. 随机森林算法原理
1.1决策树与Bagging
(一)决策树
决策树算法是一种有监督的机器学习方法。在分类问题中,决策树算法的本质是通过归纳数据中蕴含的分类规则将样本划分为不同的类别。决策树以树状图为基础,按特征对实例进行分类。决策树的结构如图1-1 所示。一个根结点、相当量的内部结点和叶子结点共同构成一棵完整的决策树,其中根结点(三角形)位于树的最顶层,是数据集划分的起点,代表数据的集合点;中间的内部结点(圆圈)属于属性结点,表示对某个属性的判别;叶子结点(正方形)属于类别结点,表示数据的最终决策结果。
决策树的构造是利用递归方法选择最优的特征,并根据选出的特征划分训练数据,其步骤如下:
1)构造根结点。训练样本全都位于根结点;
2)确定最优特征。训练样本需要使用一个最优特征来划分成各个子单元,确保每个子单元具有最佳的分类结果。同时,必须考虑两种情况:如果某个子单元的分类结果满足指标,则构建相应的叶子结点;如果某个子单元尚未有达到指标,则该子单元将继续进行划分;
3)递归地进行训练,直到所有训练样本都得到很好的分类,或者是没有合适的特征。

(二)Bagging 算法
Bagging算法(Bootstrap aggregating,引导聚集算法),又称装袋算法,是机器学习领域的一种团体学习算法。最初由Leo于1996年提出。Bagging算法可与其他分类、回归算法结合,提高其准确率、稳定性的同时,通过降低结果的方差,避免过拟合的发生。Bagging 算法的基本流程如图 1-2 所示。

Bagging 算法采用有放回的方式抽取训练样本,发现样本集中的一些样本可能会重复出现或从未出现。这意味着,即使生成的数据集与原始数据集的大小相同,也可以在生成的特定数据集中排除某些数据点。每个生成的数据集都是不同的,这就是集成模型中产生多样性的方式。计算数据点未被抽样的概率公式为: (1-1/N)^N
其中,N 是原始数据集中的样本数量。根据公式,当 N 足够大时,将有约 36.8%的样本未入选,这些样本被称为袋外(out-of-bag)数据,可作为对泛化性能“袋外估计”的验证集。
1.2 随机森林算法
随机森林(Random Forest,简称 RF)是 Bagging 算法中最具代表性的算法,随机森林在基于决策树的学习器构建 Bagging 集成的基础上,将随机属性选择引入到决策树的训练过程中。具体地说,随机森林中,对于基础决策树的每个结点,它首先从结点的属性集中随机选择一个子集,然后从该子集中选择一个最佳属性进行划分。
随机森林的基本原理是通过对数据集进行采样来生成多个不同的数据子集,并在每个数据子集上训练分类树,最后,结合各分类树的预测结果,以多数表决的原则确定随机森林的预测结果。
随机森林算法的训练过程总结如下:
1)假设训练集大小为 N,在构造每棵树时,随机且有放回地从训练集中的抽取 N个训练样本,作为该树的训练集;
2)假设每个样本的特征维度为 M,随机不重复地选取 m 个特征(m<<M)组成新的特征集来生成一棵决策树,每次树进行分裂时,可依据袋外错误率实现最优m的选择;
3)重复步骤 1)、2)k 次,得到 k 棵决策树;
4)用 k 个决策树形成的随机森林分类器,投票来确定最终分类结果。

如图1-3表示随机森林的建模过程。从上面的描述可以看出,随机森林的随机性主要表现在每棵树训练样本和每个结点分裂属性的随机性。随机森林主要的优点是:对于多种数据,它可以产生性能良好的高精度分类器;在建造森林时,泛化误差使用的是无偏估计,模型的泛化能力较强;通常随机森林的构造不需要对其进行剪枝也可以达到很好的效果。
2. 实验过程
2.1 糖尿病数据集
本实验使用的糖尿病数据集为sklearn中的diabetes数据集。此数据集中共442个样本,每个样本有十个特征,分别是 [‘age’, ‘sex’, ‘bmi’, ‘bp’, ‘s1’, ‘s2’, ‘s3’, ‘s4’, ‘s5’, ‘s6’],对应年龄、性别、体质指数、平均血压、S1~S6为一年后疾病级数指标。Targets为一年后患疾病的定量指标,值在25到346之间。

2.2 实验过程
a. 导入实验需要用的一些模块
import matplotlib.pyplot as plt #导入绘图工具
import numpy as np #导入numpy数据库
from sklearn.metrics import r2_score #使用拟合优度r2_score对实验结果进行评估
from sklearn.model_selection import train_test_split #划分数据集
from sklearn.ensemble import RandomForestRegressor #导入随机森林训练模型
from sklearn.datasets import load_diabetes #导入糖尿病数据集b. 读取糖尿病数据集并进行数据划分
考虑到测试集的数据越小对模型泛化误差的估计会越不准确,因此将数据集以测试集:训练集=4:6的比例进行划分。
#数据格式
data=load_diabetes()
X =data.data #数据
y=data.target #结果#划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
#测试集与训练集的比例为4:6 如果测试集的数据越小,对模型的泛化误差的估计将会越不准确
n = np.arange(0, X_test.shape[0], 1)
print('shape of X_test{}'.format(n.shape))#显示特征与目标的形状
print('shape of X_test{}'.format(X_test.shape))#显示特征与目标的形状
print('shape of y_test{}'.format(y_test.shape))#显示特征与目标的形状
c. 导入随机森林训练模型
#随机森林训练模型
regressor = RandomForestRegressor(n_estimators=100, max_depth=3, random_state=0)
#随机森林回归,并使用100个决策树,深度为3
#这里的random_state就是为了保证程序每次运行都分割一样的训练集和测试集
regressor.fit(X_train, y_train) # 拟合模型
result = regressor.predict(X_test)
print('score:{}'.format(r2_score(y_test,result)))#显示训练结果与测试结果的拟合优度
d .绘制拟合曲线
#画出拟合曲线
plt.figure(figsize=(8, 5))#设置图片格式
plt.plot(n , result, c='r', label='prediction', lw=2) # 画出拟合曲线
plt.plot(n , y_test, c='b', label='true', lw=2) # 画出拟合曲线
plt.axis('tight') #使x轴与y轴限制在有数据的区域
plt.title("RandomForestRegressor" )
plt.show()
2.3 实验结果展示

如上图所示,score表示特征模型对特征样本预测的好坏,即确定系数。这个值越接近1说明预测结果越好。
根据预测值和真实值的对比图,可知score约为0.422,说明预测与真实之间的相关度为0.422。
2.4 完整实验代码
import matplotlib.pyplot as plt #导入绘图工具
import numpy as np #导入numpy数据库
from sklearn.metrics import r2_score #使用拟合优度r2_score对实验结果进行评估
from sklearn.model_selection import train_test_split #划分数据集
from sklearn.ensemble import RandomForestRegressor #导入随机森林训练模型
from sklearn.datasets import load_diabetes #导入糖尿病数据集#数据格式
data=load_diabetes()
X =data.data #数据
y=data.target #结果#划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
#测试集与训练集的比例为4:6 如果测试集的数据越小,对模型的泛化误差的估计将会越不准确
n = np.arange(0, X_test.shape[0], 1)
print('shape of X_test{}'.format(n.shape))#显示特征与目标的形状
print('shape of X_test{}'.format(X_test.shape))#显示特征与目标的形状
print('shape of y_test{}'.format(y_test.shape))#显示特征与目标的形状#随机森林训练模型
regressor = RandomForestRegressor(n_estimators=100, max_depth=3, random_state=0)
#随机森林回归,并使用100个决策树,深度为3
#这里的random_state就是为了保证程序每次运行都分割一样的训练集和测试集
regressor.fit(X_train, y_train) # 拟合模型
result = regressor.predict(X_test)
print('score:{}'.format(r2_score(y_test,result)))#显示训练结果与测试结果的拟合优度#画出拟合曲线
plt.figure(figsize=(8, 5))#设置图片格式
plt.plot(n , result, c='r', label='prediction', lw=2) # 画出拟合曲线
plt.plot(n , y_test, c='b', label='true', lw=2) # 画出拟合曲线
plt.axis('tight') #使x轴与y轴限制在有数据的区域
plt.title("RandomForestRegressor" )
plt.show()