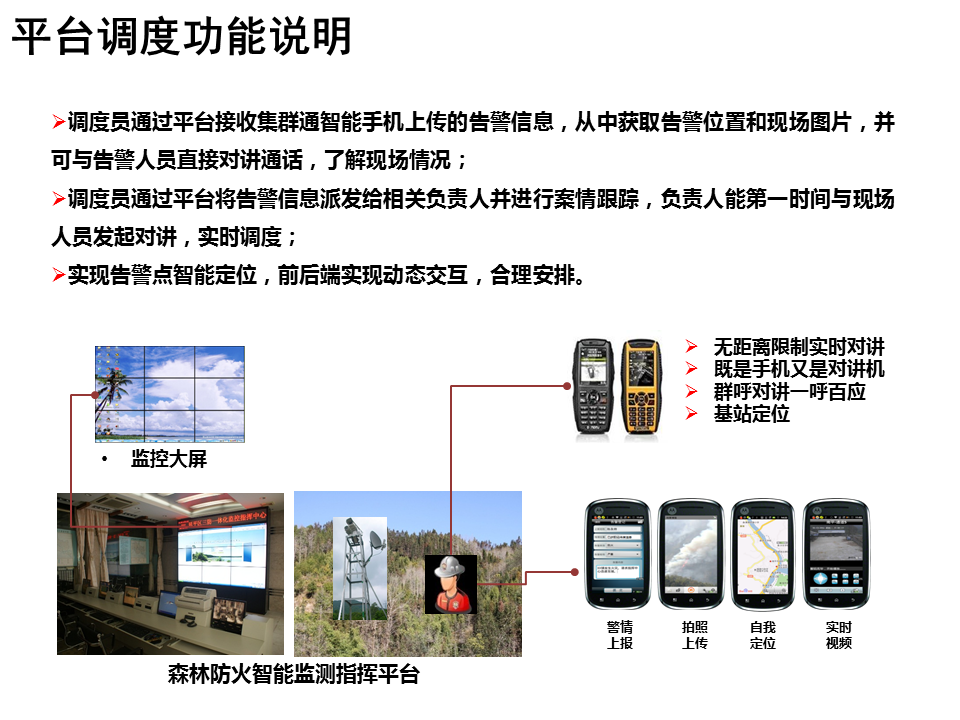
一、决策树
决策树是常见的机器学习中监督学习的方法,可以用来分类和回归。对于数据集,沿着决策树的分支,根据属性值判断属于决策树的哪一枝,最终到达叶节点,得到结果。一棵典型的决策树如下,

图1. 决策树
一棵决策树包括以下部分:
(1)树根:包含全部数据集
(2)树枝:划分标准
(3)中间节点:按照一定标准划分的子集
(4)叶子:最终的结果(包含的子集)
1.1 决策树分类
决策树分类中,最终的叶子为最终划分的分类结果,如根据当天的温度、湿度、风力、大气污染程度等,判断最终是天气好、一般还是差。决策树分支的标准是信息熵的增益最大,信息熵的定义如下:
(1)
其中,为集合
中第
类样本所占的比例,
表示划分前根据数据标签的原始数据集的信息熵,信息熵越大,表示结构越活越;信息熵越小,结构越稳定。假设某一离散属性值
包含
个离散取值,那么根据属性
,可以将
划分为
个不同的子集,每一个子集都可以计算
.
那么根据属性进行划分(分枝)的信息增益(信息熵的下降量)为:
(2)
挑选使得信息增益最大的属性,对决策树进一步分枝。该背后原理如下,根据决策树,使得整棵树的信息熵最低,得到的决策树不确定性最小,最稳定。
参见https://zhuanlan.zhihu.com/p/89607509
1.2 决策树回归
决策树用于回归时,其分枝的标准为最小均方误差。根据数据集的第个特征,设置阈值为
,划分为
和
两个区域,如下:
(3)
使得一个子集内均方误差最小的,那么上式为,
(4)
参见,https://blog.csdn.net/Albert201605/article/details/81865261
二、随机森林
随机森林,顾名思义,是很多树的集合。随机森林的基本单位是决策树,其示意图如下,
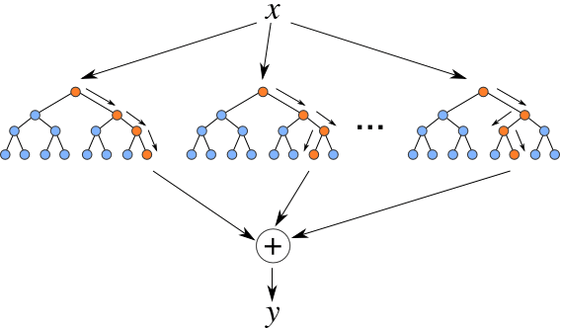
图2. 随机森林
随机森林的步骤如下:
(1)从数据集中有放回的随机抽样 ;
(2)随机抽取特征构建决策树;
(3)将决策树的结果取平均,得到最终结果。
参加,机器学习常用算法——随机森林 - 云+社区 - 腾讯云
三、代码实现
随机森林
利用第三方库,随机森林分类和回归如下,
分类,
from sklearn.ensemble import RandomForestClassifier# x. y为训练数据
model_RF_class = RandomForestClassifier(n_estimators = 100, random_state = 0)
model_RF_class.fit(x, y)
# x_test, y_test为测试数据
y_test = model_RF_class.predict(x_test)回归,
# x. y为训练数据
from sklearn.ensemble import RandomForestRegressor# 随机森林回归器
model_RF_regr = RandomForestRegressor(n_estimators = 100, random_state = 0)
# 拟合数据集
model_RF_regr = model_RF_regr.fit(X, y)
# x_test, y_test为测试数据
y_test = model_RF_regr.predict(x_test)
参见,机器学习算法系列(十八)-随机森林算法(Random Forest Algorithm)_sai_simon的博客-CSDN博客_随机森林算法j
具体参数的含义,见官网,sklearn.ensemble.RandomForestClassifier — scikit-learn 1.1.0 documentation
决策树
from sklearn.tree import DecisionTreeClassifier# x. y为训练数据
model_DT_class = DecisionTreeClassifier()
model_DT_class.fit(x, y)
# x_test, y_test为测试数据
y_test = model_DT_class.predict(x_test)
from sklearn.tree import DecisionTreeRegressor# x. y为训练数据
model_DT_regr = DecisionTreeRegressor(max_depth=1)
model_DT_regr.fit(x, y)
# x_test, y_test为测试数据
y_test = model_DT_regr.predict(x_test)
参见,python代码实现决策树分类_林下月光的博客-CSDN博客_python决策树分类
参见,决策树—回归_禺垣的博客-CSDN博客_决策树回归