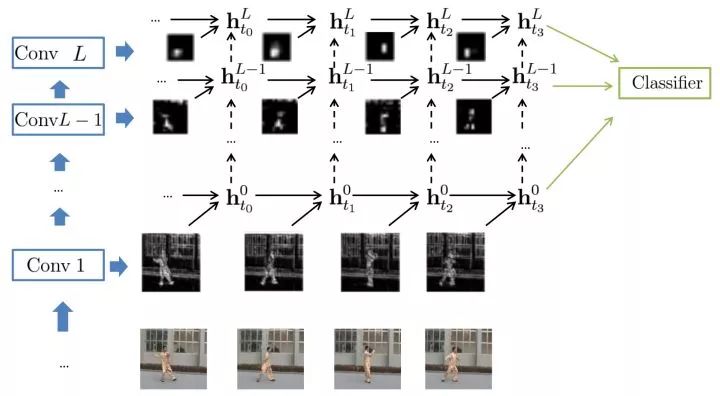
本专栏是计算机视觉方向论文收集积累,时间:2021年3月3日,来源:paper digest
欢迎关注原创公众号 【计算机视觉联盟】,回复 【西瓜书手推笔记】 可获取我的机器学习纯手推笔记!
直达笔记地址:机器学习手推笔记(GitHub地址)
1, TITLE: DeepMerge II: Building Robust Deep Learning Algorithms for Merging Galaxy Identification Across Domains
AUTHORS: A. ?IPRIJANOVI? et. al.
CATEGORY: astro-ph.IM [astro-ph.IM, astro-ph.GA, cs.AI, cs.CV, cs.LG]
HIGHLIGHT: With further development, these techniques will allow astronomers to successfully implement neural network models trained on simulation data to efficiently detect and study astrophysical objects in current and future large-scale astronomical surveys.
2, TITLE: PHASE: PHysically-grounded Abstract Social Events for Machine Social Perception
AUTHORS: Aviv Netanyahu ; Tianmin Shu ; Boris Katz ; Andrei Barbu ; Joshua B. Tenenbaum
CATEGORY: cs.AI [cs.AI, cs.CV, cs.LG, stat.ML]
HIGHLIGHT: In this work, we create a dataset of physically-grounded abstract social events, PHASE, that resemble a wide range of real-life social interactions by including social concepts such as helping another agent.
3, TITLE: Dual Reinforcement-Based Specification Generation for Image De-Rendering
AUTHORS: Ramakanth Pasunuru ; David Rosenberg ; Gideon Mann ; Mohit Bansal
CATEGORY: cs.CL [cs.CL, cs.AI, cs.CV]
HIGHLIGHT: Since these are sequence models, we must choose an ordering of the objects in the graphics programs for likelihood training.
4, TITLE: IdentityDP: Differential Private Identification Protection for Face Images
AUTHORS: Yunqian Wen ; Li Song ; Bo Liu ; Ming Ding ; Rong Xie
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we focus on tackling these challenges to improve face de-identification.
5, TITLE: Comparison of Methods Generalizing Max- and Average-Pooling
AUTHORS: Florentin Bieder ; Robin Sandk�hler ; Philippe C. Cattin
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: In this paper, we compare different pooling methods that generalize both max- and average-pooling.
6, TITLE: AttriMeter: An Attribute-guided Metric Interpreter for Person Re-Identification
AUTHORS: XIAODONG CHEN et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Therefore, we propose an Attribute-guided Metric Interpreter, named AttriMeter, to semantically and quantitatively explain the results of CNN-based ReID models.
7, TITLE: Diffusion Probabilistic Models for 3D Point Cloud Generation
AUTHORS: Shitong Luo ; Wei Hu
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We present a probabilistic model for point cloud generation, which is critical for various 3D vision tasks such as shape completion, upsampling, synthesis and data augmentation.
8, TITLE: Image-to-image Translation Via Hierarchical Style Disentanglement
AUTHORS: XINYANG LI et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue.
9, TITLE: Auto-Exposure Fusion for Single-Image Shadow Removal
AUTHORS: LAN FU et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This paper proposes a new solution for this task by formulating it as an exposure fusion problem to address the challenges.
10, TITLE: Maximal Function Pooling with Applications
AUTHORS: Wojciech Czaja ; Weilin Li ; Yiran Li ; Mike Pekala
CATEGORY: cs.CV [cs.CV, cs.IT, math.IT]
HIGHLIGHT: Inspired by the Hardy-Littlewood maximal function, we propose a novel pooling strategy which is called maxfun pooling.
11, TITLE: A Structurally Regularized Convolutional Neural Network for Image Classification Using Wavelet-based SubBand Decomposition
AUTHORS: Pavel Sinha ; Ioannis Psaromiligkos ; Zeljko Zilic
CATEGORY: cs.CV [cs.CV, eess.IV]
HIGHLIGHT: We propose a convolutional neural network (CNN) architecture for image classification based on subband decomposition of the image using wavelets.
12, TITLE: Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection
AUTHORS: Chenchen Zhu ; Fangyi Chen ; Uzair Ahmed ; Marios Savvides
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we investigate utilizing this semantic relation together with the visual information and introduce explicit relation reasoning into the learning of novel object detection.
13, TITLE: A Deep Emulator for Secondary Motion of 3D Characters
AUTHORS: Mianlun Zheng ; Yi Zhou ; Duygu Ceylan ; Jernej Barbic
CATEGORY: cs.CV [cs.CV, cs.GR]
HIGHLIGHT: We present a learning-based approach to enhance skinning-based animations of 3D characters with vivid secondary motion effects.
14, TITLE: WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
AUTHORS: Krishna Srinivasan ; Karthik Raman ; Jiecao Chen ; Michael Bendersky ; Marc Najork
CATEGORY: cs.CV [cs.CV, cs.CL, cs.IR]
HIGHLIGHT: In this paper, we introduce the Wikipedia-based Image Text (WIT) Dataset\footnote{\url{https://github.com/google-research-datasets/wit}} to better facilitate multimodal, multilingual learning.
15, TITLE: Network Pruning Via Resource Reallocation
AUTHORS: Yuenan Hou ; Zheng Ma ; Chunxiao Liu ; Zhe Wang ; Chen Change Loy
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we propose a simple yet effective channel pruning technique, termed network Pruning via rEsource rEalLocation (PEEL), to quickly produce a desired slim model with negligible cost.
16, TITLE: Masked Face Recognition: Human Vs. Machine
AUTHORS: NASER DAMER et. al.
CATEGORY: cs.CV [cs.CV, cs.CY]
HIGHLIGHT: This work provides a joint evaluation and in-depth analyses of the face verification performance of human experts in comparison to state-of-the-art automatic face recognition solutions.
17, TITLE: Square Root Bundle Adjustment for Large-Scale Reconstruction
AUTHORS: Nikolaus Demmel ; Christiane Sommer ; Daniel Cremers ; Vladyslav Usenko
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We propose a new formulation for the bundle adjustment problem which relies on nullspace marginalization of landmark variables by QR decomposition.
18, TITLE: Geometry-Guided Street-View Panorama Synthesis from Satellite Imagery
AUTHORS: Yujiao Shi ; Dylan Campbell ; Xin Yu ; Hongdong Li
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This paper presents a new approach for synthesizing a novel street-view panorama given an overhead satellite image.
19, TITLE: HED-UNet: Combined Segmentation and Edge Detection for Monitoring The Antarctic Coastline
AUTHORS: Konrad Heidler ; Lichao Mou ; Celia Baumhoer ; Andreas Dietz ; Xiao Xiang Zhu
CATEGORY: cs.CV [cs.CV, eess.IV]
HIGHLIGHT: To take into account this task duality, we therefore devise a new model to unite these two approaches in a deep learning model.
20, TITLE: All at Once Network Quantization Via Collaborative Knowledge Transfer
AUTHORS: XIMENG SUN et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we develop a novel collaborative knowledge transfer approach for efficiently training the all-at-once quantization network.
21, TITLE: Inter-class Discrepancy Alignment for Face Recognition
AUTHORS: JIAHENG LIU et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this study, we make a key observation that the local con-text represented by the similarities between the instance and its inter-class neighbors1plays an important role forFR.
22, TITLE: Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
AUTHORS: HONGGU LIU et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection.
23, TITLE: Exploring Complementary Strengths of Invariant and Equivariant Representations for Few-Shot Learning
AUTHORS: Mamshad Nayeem Rizve ; Salman Khan ; Fahad Shahbaz Khan ; Mubarak Shah
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: In this work, we build on this insight and propose a novel training mechanism that simultaneously enforces equivariance and invariance to a general set of geometric transformations.
24, TITLE: Brain-inspired Algorithms for Processing of Visual Data
AUTHORS: Nicola Strisciuglio
CATEGORY: cs.CV [cs.CV, eess.IV]
HIGHLIGHT: In this paper, we review approaches for image processing and computer vision, the design of which is based on neuro-scientific findings about the functions of some neurons in the visual cortex.
25, TITLE: Using CNNs to Identify The Origin of Finger Vein Image
AUTHORS: Babak Maser ; Andreas Uhl
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We study the finger vein (FV) sensor model identification task using a deep learning approach.
26, TITLE: On The Generalisation Capabilities of Fisher Vector Based Face Presentation Attack Detection
AUTHORS: L�zaro J. Gonz�lez-Soler ; Marta Gomez-Barrero ; Christoph Busch
CATEGORY: cs.CV [cs.CV, cs.IT, cs.LG, math.IT]
HIGHLIGHT: In this work, we use a new feature space based on Fisher Vectors, computed from compact Binarised Statistical Image Features histograms, which allow discovering semantic feature subsets from known samples in order to enhance the detection of unknown attacks.
27, TITLE: Interpretable Hyperspectral AI: When Non-Convex Modeling Meets Hyperspectral Remote Sensing
AUTHORS: DANFENG HONG et. al.
CATEGORY: cs.CV [cs.CV, cs.AI, eess.IV]
HIGHLIGHT: For this reason, it is, therefore, urgent to develop more intelligent and automatic approaches for various HS RS applications.
28, TITLE: Depth from Camera Motion and Object Detection
AUTHORS: Brent A. Griffin ; Jason J. Corso
CATEGORY: cs.CV [cs.CV, cs.RO]
HIGHLIGHT: This paper addresses the problem of learning to estimate the depth of detected objects given some measurement of camera motion (e.g., from robot kinematics or vehicle odometry).
29, TITLE: A Novel CNN-LSTM-based Approach to Predict Urban Expansion
AUTHORS: Wadii Boulila ; Hamza Ghandorh ; Mehshan Ahmed Khan ; Fawad Ahmed ; Jawad Ahmad
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: Building upon previous work, we propose a novel two-step approach based on semantic image segmentation in order to predict urban expansion.
30, TITLE: Image/Video Deep Anomaly Detection: A Survey
AUTHORS: Bahram Mohammadi ; Mahmood Fathy ; Mohammad Sabokrou
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Hereupon, in this survey we intend to conduct an in-depth investigation into the images/videos deep learning based AD methods.
31, TITLE: Exploiting Latent Representation of Sparse Semantic Layers for Improved Short-term Motion Prediction with Capsule Networks
AUTHORS: Albert Dulian ; John C. Murray
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: We train and evaluate our model on publicly available dataset nuTonomy scenes and compare it to recently published methods.
32, TITLE: Contextually Guided Convolutional Neural Networks for Learning Most Transferable Representations
AUTHORS: Olcay Kursun ; Semih Dinc ; Oleg V. Favorov
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: Implementing such local contextual guidance principles in a single-layer CNN architecture, we propose an efficient algorithm for developing broad-purpose representations (i.e., representations transferable to new tasks without additional training) in shallow CNNs trained on limited-size datasets.
33, TITLE: When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework
AUTHORS: Zhizhong Huang ; Junping Zhang ; Hongming Shan
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Therefore, this paper proposes a unified, multi-task framework to jointly handle these two tasks, termed \methodname, which can learn age-invariant identity-related representation while achieving pleasing face synthesis. In addition, we collect and release a large cross-age face dataset with age and gender annotations to advance the development of the AIFR and FAS.
34, TITLE: Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition
AUTHORS: Stephen Hausler ; Sourav Garg ; Ming Xu ; Michael Milford ; Tobias Fischer
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This paper introduces Patch-NetVLAD, which provides a novel formulation for combining the advantages of both local and global descriptor methods by deriving patch-level features from NetVLAD residuals.
35, TITLE: There Is More Than Meets The Eye: Self-Supervised Multi-Object Detection and Tracking with Sound By Distilling Multimodal Knowledge
AUTHORS: Francisco Rivera Valverde ; Juana Valeria Hurtado ; Abhinav Valada
CATEGORY: cs.CV [cs.CV, cs.LG, cs.RO]
HIGHLIGHT: In this work, we present the novel self-supervised MM-DistillNet framework consisting of multiple teachers that leverage diverse modalities including RGB, depth and thermal images, to simultaneously exploit complementary cues and distill knowledge into a single audio student network. We introduce a large-scale multimodal dataset with over 113,000 time-synchronized frames of RGB, depth, thermal, and audio modalities.
36, TITLE: A Comprehensive Study on Face Recognition Biases Beyond Demographics
AUTHORS: PHILIPP TERH�RST et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Therefore, in this work, we analyse FR bias over a wide range of attributes.
37, TITLE: Hierarchical and Partially Observable Goal-driven Policy Learning with Goals Relational Graph
AUTHORS: Xin Ye ; Yezhou Yang
CATEGORY: cs.CV [cs.CV, cs.RO]
HIGHLIGHT: We present a novel two-layer hierarchical reinforcement learning approach equipped with a Goals Relational Graph (GRG) for tackling the partially observable goal-driven task, such as goal-driven visual navigation.
38, TITLE: Simulation-to-Real Domain Adaptation with Teacher-student Learning for Endoscopic Instrument Segmentation
AUTHORS: Manish Sahu ; Anirban Mukhopadhyay ; Stefan Zachow
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: Methods: We introduce a teacher-student learning approach that learns jointly from annotated simulation data and unlabeled real data to tackle the erroneous learning problem of the current consistency-based unsupervised domain adaptation framework.
39, TITLE: Brain Programming Is Immune to Adversarial Attacks: Towards Accurate and Robust Image Classification Using Symbolic Learning
AUTHORS: Gerardo Ibarra-Vazquez ; Gustavo Olague ; Mariana Chan-Ley ; Cesar Puente ; Carlos Soubervielle-Montalvo
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we perform a comparative study of the effects of AA on the complex problem of art media categorization, which involves a sophisticated analysis of features to classify a fine collection of artworks.
40, TITLE: A Survey of Deep Learning Techniques for Weed Detection from Images
AUTHORS: A S M Mahmudul Hasan ; Ferdous Sohel ; Dean Diepeveen ; Hamid Laga ; Michael G. K. Jones
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: In this paper, we review existing deep learning-based weed detection and classification techniques.
41, TITLE: A Pose-only Solution to Visual Reconstruction and Navigation
AUTHORS: Qi Cai ; Lilian Zhang ; Yuanxin Wu ; Wenxian Yu ; Dewen Hu
CATEGORY: cs.CV [cs.CV, cs.RO]
HIGHLIGHT: A Pose-only Solution to Visual Reconstruction and Navigation
42, TITLE: Multiclass Burn Wound Image Classification Using Deep Convolutional Neural Networks
AUTHORS: Behrouz Rostami ; Jeffrey Niezgoda ; Sandeep Gopalakrishnan ; Zeyun Yu
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this study, we use a deep learning-based method to classify burn wound images into two or three different categories based on the wound conditions.
43, TITLE: Part2Whole: Iteratively Enrich Detail for Cross-Modal Retrieval with Partial Query
AUTHORS: GUANYU CAI et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we introduce the partial-query problem and extensively analyze its influence on text-based image retrieval.
44, TITLE: Few-shot Open-set Recognition By Transformation Consistency
AUTHORS: Minki Jeong ; Seokeon Choi ; Changick Kim
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we attack a few-shot open-set recognition (FSOSR) problem, which is a combination of few-shot learning (FSL) and open-set recognition (OSR).
45, TITLE: TransTailor: Pruning The Pre-trained Model for Improved Transfer Learning
AUTHORS: Bingyan Liu ; Yifeng Cai ; Yao Guo ; Xiangqun Chen
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: To this end, we propose TransTailor, targeting at pruning the pre-trained model for improved transfer learning.
46, TITLE: Fixing Data Augmentation to Improve Adversarial Robustness
AUTHORS: SYLVESTRE-ALVISE REBUFFI et. al.
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: In this paper, we focus on both heuristics-driven and data-driven augmentations as a means to reduce robust overfitting.
47, TITLE: An Interpretable Multiple-Instance Approach for The Detection of Referable Diabetic Retinopathy from Fundus Images
AUTHORS: Alexandros Papadopoulos ; Fotis Topouzis ; Anastasios Delopoulos
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we propose a machine learning system for the detection of referable DR in fundus images that is based on the paradigm of multiple-instance learning.
48, TITLE: Scalable Scene Flow from Point Clouds in The Real World
AUTHORS: Philipp Jund ; Chris Sweeney ; Nichola Abdo ; Zhifeng Chen ; Jonathon Shlens
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: In this work, we introduce a new large scale benchmark for scene flow based on the Waymo Open Dataset.
49, TITLE: Exploring The High Dimensional Geometry of HSI Features
AUTHORS: Wojciech Czaja ; Ilya Kavalerov ; Weilin Li
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We explore feature space geometries induced by the 3-D Fourier scattering transform and deep neural network with extended attribute profiles on four standard hyperspectral images.
50, TITLE: Real Masks and Fake Faces: On The Masked Face Presentation Attack Detection
AUTHORS: Meiling Fang ; Naser Damer ; Florian Kirchbuchner ; Arjan Kuijper
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Therefore, we present novel attacks with real masks placed on presentations and attacks with subjects wearing masks to reflect the current real-world situation.
51, TITLE: Coarse-Fine Networks for Temporal Activity Detection in Videos
AUTHORS: Kumara Kahatapitiya ; Michael S. Ryoo
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we introduce 'Coarse-Fine Networks', a two-stream architecture which benefits from different abstractions of temporal resolution to learn better video representations for long-term motion.
52, TITLE: Context Decoupling Augmentation for Weakly Supervised Semantic Segmentation
AUTHORS: Yukun Su ; Ruizhou Sun ; Guosheng Lin ; Qingyao Wu
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: To this end, we present a Context Decoupling Augmentation (CDA) method, to change the inherent context in which the objects appear and thus drive the network to remove the dependence between object instances and contextual information.
53, TITLE: Predicting Video with VQVAE
AUTHORS: Jacob Walker ; Ali Razavi ; A�ron van den Oord
CATEGORY: cs.CV [cs.CV, cs.LG, I.2.6; I.2.10]
HIGHLIGHT: In this paper we propose a novel approach to this problem with Vector Quantized Variational AutoEncoders (VQ-VAE).
54, TITLE: Unmasking Face Embeddings By Self-restrained Triplet Loss for Accurate Masked Face Recognition
AUTHORS: Fadi Boutros ; Naser Damer ; Florian Kirchbuchner ; Arjan Kuijper
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we presented a solution to improve the masked face recognition performance.
55, TITLE: Transportation Density Reduction Caused By City Lockdowns Across The World During The COVID-19 Epidemic: From The View of High-resolution Remote Sensing Imagery
AUTHORS: CHEN WU et. al.
CATEGORY: cs.CV [cs.CV, eess.IV]
HIGHLIGHT: A novel vehicle detection model combining unsupervised vehicle candidate extraction and deep learning identification was specifically proposed for the images with the resolution of 0.5m.
56, TITLE: Mixture of Volumetric Primitives for Efficient Neural Rendering
AUTHORS: STEPHEN LOMBARDI et. al.
CATEGORY: cs.GR [cs.GR, cs.CV]
HIGHLIGHT: We present Mixture of Volumetric Primitives (MVP), a representation for rendering dynamic 3D content that combines the completeness of volumetric representations with the efficiency of primitive-based rendering, e.g., point-based or mesh-based methods.
57, TITLE: SME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network
AUTHORS: FANGXIN LIU et. al.
CATEGORY: cs.AR [cs.AR, cs.CV, cs.LG]
HIGHLIGHT: As the countermeasure, we developed a novel ReRAM-based DNN accelerator, named Sparse-Multiplication-Engine (SME), based on a hardware and software co-design framework.
58, TITLE: Performance Variability in Zero-Shot Classification
AUTHORS: Mat�as Molina ; Jorge S�nchez
CATEGORY: cs.LG [cs.LG, cs.CV]
HIGHLIGHT: In this work we show experimentally that ZSC performance exhibits strong variability under changing training setups.
59, TITLE: A Survey On Universal Adversarial Attack
AUTHORS: CHAONING ZHANG et. al.
CATEGORY: cs.LG [cs.LG, cs.CV]
HIGHLIGHT: With the focus on UAP against deep classifiers, this survey summarizes the recent progress on universal adversarial attacks, discussing the challenges from both the attack and defense sides, as well as the reason for the existence of UAP.
60, TITLE: Learning with Hyperspherical Uniformity
AUTHORS: WEIYANG LIU et. al.
CATEGORY: cs.LG [cs.LG, cs.CV]
HIGHLIGHT: We consider several geometrically distinct ways to achieve hyperspherical uniformity.
61, TITLE: A HINT from Arithmetic: On Systematic Generalization of Perception, Syntax, and Semantics
AUTHORS: QING LI et. al.
CATEGORY: cs.LG [cs.LG, cs.AI, cs.CV]
HIGHLIGHT: Inspired by humans' remarkable ability to master arithmetic and generalize to unseen problems, we present a new dataset, HINT, to study machines' capability of learning generalizable concepts at three different levels: perception, syntax, and semantics.
62, TITLE: Adversarial Examples for Unsupervised Machine Learning Models
AUTHORS: Chia-Yi Hsu ; Pin-Yu Chen ; Songtao Lu ; Sijia Lu ; Chia-Mu Yu
CATEGORY: cs.LG [cs.LG, cs.CV]
HIGHLIGHT: In this paper, we propose a framework of generating adversarial examples for unsupervised models and demonstrate novel applications to data augmentation.
63, TITLE: Avoiding Degeneracy for Monocular Visual SLAM with Point and Line Features
AUTHORS: Hyunjun Lim ; Yeeun Kim ; Kwangik Jung ; Sumin Hu ; Hyun Myung
CATEGORY: cs.RO [cs.RO, cs.CV]
HIGHLIGHT: In this paper, a degeneracy avoidance method for a point and line based visual SLAM algorithm is proposed.
64, TITLE: Geometry-Based Grasping of Vine Tomatoes
AUTHORS: Taeke de Haan ; Padmaja Kulkarni ; Robert Babuska
CATEGORY: cs.RO [cs.RO, cs.CV]
HIGHLIGHT: We propose a geometry-based grasping method for vine tomatoes.
65, TITLE: Test Automation with Grad-CAM Heatmaps -- A Future Pipe Segment in MLOps for Vision AI?
AUTHORS: MARKUS BORG et. al.
CATEGORY: cs.SE [cs.SE, cs.CV]
HIGHLIGHT: In this paper, we demonstrate how Grad-CAM heatmaps can be used to increase the explainability of an image recognition model trained for a pedestrian underpass.
66, TITLE: Solving Inverse Problems By Joint Posterior Maximization with Autoencoding Prior
AUTHORS: Mario Gonz�lez ; Andr�s Almansa ; Pauline Tan
CATEGORY: stat.ML [stat.ML, cs.CV, cs.LG, eess.IV, math.OC]
HIGHLIGHT: In this work we address the problem of solving ill-posed inverse problems in imaging where the prior is a variational autoencoder (VAE).
67, TITLE: Have We Learned to Explain?: How Interpretability Methods Can Learn to Encode Predictions in Their Interpretations
AUTHORS: Neil Jethani ; Mukund Sudarshan ; Yindalon Aphinyanaphongs ; Rajesh Ranganath
CATEGORY: stat.ML [stat.ML, cs.AI, cs.CV, cs.LG]
HIGHLIGHT: We introduce EVAL-X as a method to quantitatively evaluate interpretations and REAL-X as an amortized explanation method, which learn a predictor model that approximates the true data generating distribution given any subset of the input.
68, TITLE: Super-resolving Compressed Images Via Parallel and Series Integration of Artifact Reduction and Resolution Enhancement
AUTHORS: Hongming Luo ; Fei Zhou ; Guangsen Liao ; Guoping Qiu
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this paper, we propose a novel compressed image super resolution (CISR) framework based on parallel and series integration of artifact removal and resolution enhancement.
69, TITLE: Robust 3D U-Net Segmentation of Macular Holes
AUTHORS: JONATHAN FRAWLEY et. al.
CATEGORY: eess.IV [eess.IV, cs.CV, cs.LG]
HIGHLIGHT: We use the 3D U-Net architecture as a basis and experiment with a number of design variants.
70, TITLE: Efficient Deep Image Denoising Via Class Specific Convolution
AUTHORS: LU XU et. al.
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this paper, we propose an efficient deep neural network for image denoising based on pixel-wise classification.
71, TITLE: Medical Imaging and Machine Learning
AUTHORS: Rohan Shad ; John P. Cunningham ; Euan A. Ashley ; Curtis P. Langlotz ; William Hiesinger
CATEGORY: eess.IV [eess.IV, cs.CV, cs.LG]
HIGHLIGHT: In this perspective paper we explore challenges unique to high dimensional clinical imaging data, in addition to highlighting some of the technical and ethical considerations in developing high-dimensional, multi-modality, machine learning systems for clinical decision support.
72, TITLE: Feature-Align Network and Knowledge Distillation for Efficient Denoising
AUTHORS: LUCAS D. YOUNG et. al.
CATEGORY: eess.IV [eess.IV, cs.CV, cs.LG, 94A08 (Primary) 68T07, 65D19 (Secondary), I.4.5; I.2.6]
HIGHLIGHT: Here, we propose a novel network for efficient RAW denoising on mobile devices.
73, TITLE: A Practical Framework for ROI Detection in Medical Images -- A Case Study for Hip Detection in Anteroposterior Pelvic Radiographs
AUTHORS: Feng-Yu Liu ; Chih-Chi Chen ; Shann-Ching Chen ; Chien-Hung Liao
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: Thus, we proposed a practical framework of ROIs detection in medical images, with a case study for hip detection in anteroposterior (AP) pelvic radiographs.
74, TITLE: MetaSCI: Scalable and Adaptive Reconstruction for Video Compressive Sensing
AUTHORS: Zhengjue Wang ; Hao Zhang ; Ziheng Cheng ; Bo Chen ; Xin Yuan
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: We address these challenges by developing a Meta Modulated Convolutional Network for SCI reconstruction, dubbed MetaSCI.