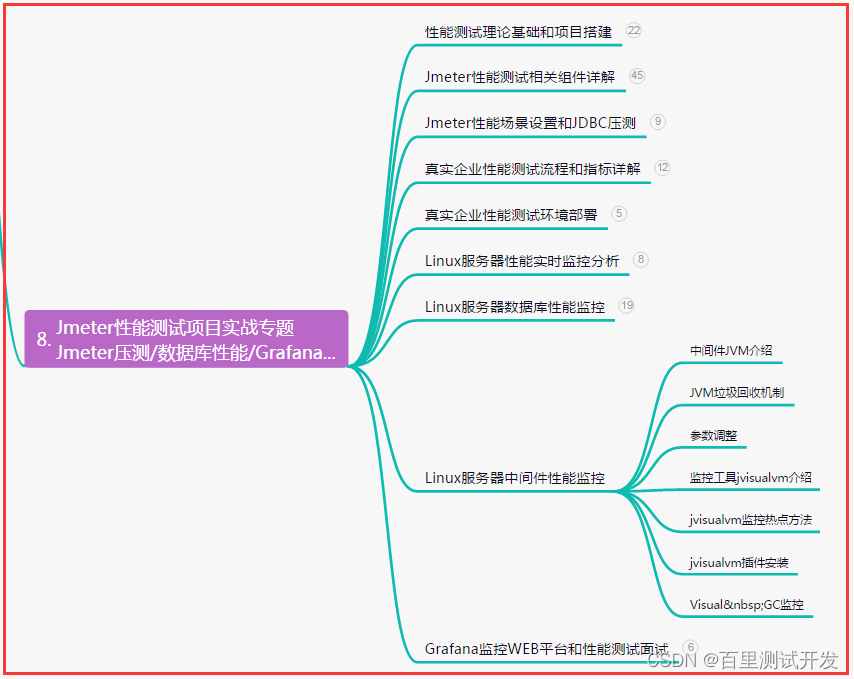
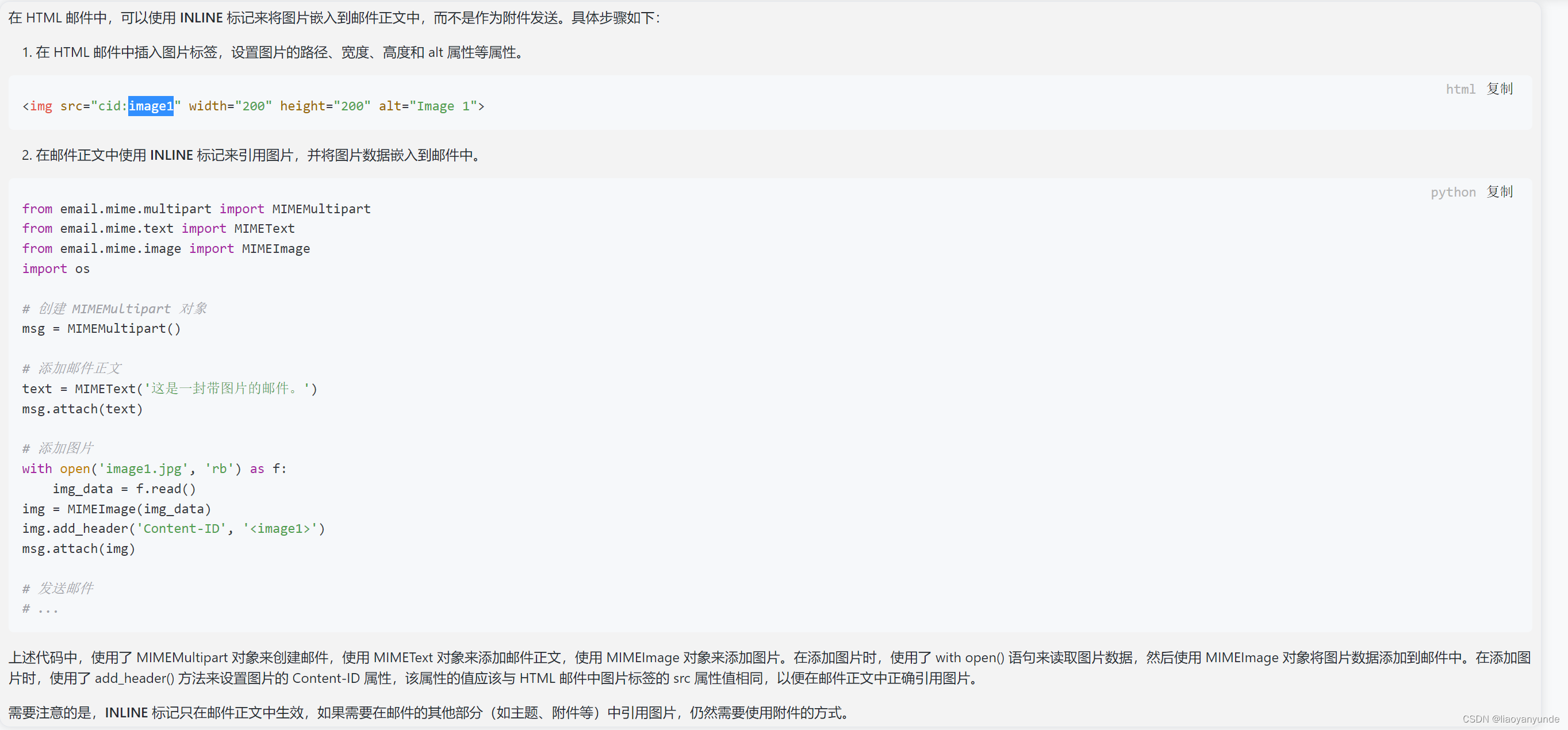
本专栏是计算机视觉方向论文收集积累,时间:2021年7月13日,来源:paper digest
欢迎关注原创公众号 【计算机视觉联盟】,回复 【西瓜书手推笔记】 可获取我的机器学习纯手推笔记!
直达笔记地址:机器学习手推笔记(GitHub地址)
1, TITLE: Anatomy-Constrained Contrastive Learning for Synthetic Segmentation Without Ground-truth
AUTHORS: Bo Zhou ; Chi Liu ; James S. Duncan
CATEGORY: cs.CV [cs.CV, cs.AI, eess.IV]
HIGHLIGHT: In this work, we developed an anatomy-constrained contrastive synthetic segmentation network (AccSeg-Net) to train a segmentation network for a target imaging modality without using its ground truth.
2, TITLE: Anatomy of Domain Shift Impact on U-Net Layers in MRI Segmentation
AUTHORS: Ivan Zakazov ; Boris Shirokikh ; Alexey Chernyavskiy ; Mikhail Belyaev
CATEGORY: cs.CV [cs.CV, cs.LG, eess.IV]
HIGHLIGHT: To this end, we propose SpotTUnet - a CNN architecture that automatically chooses the layers which should be optimally fine-tuned.
3, TITLE: Partial Video Domain Adaptation with Partial Adversarial Temporal Attentive Network
AUTHORS: YUECONG XU et. al.
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: In this paper, we propose a novel Partial Adversarial Temporal Attentive Network (PATAN) to address the PVDA problem by utilizing both spatial and temporal features for filtering source-only classes. We further introduce new benchmarks to facilitate research on PVDA problems, covering a wide range of PVDA scenarios.
4, TITLE: Aligning Correlation Information for Domain Adaptation in Action Recognition
AUTHORS: YUECONG XU et. al.
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: Therefore we propose a novel Adversarial Correlation Adaptation Network (ACAN) to align action videos by aligning pixel correlations. We, therefore, introduce a novel HMDB-ARID dataset with a larger domain shift caused by a larger statistical difference between domains.
5, TITLE: A Spatial Guided Self-supervised Clustering Network for Medical Image Segmentation
AUTHORS: Euijoon Ahn ; Dagan Feng ; Jinman Kim
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Hence, we propose a new spatial guided self-supervised clustering network (SGSCN) for medical image segmentation, where we introduce multiple loss functions designed to aid in grouping image pixels that are spatially connected and have similar feature representations.
6, TITLE: BEV-MODNet: Monocular Camera Based Bird's Eye View Moving Object Detection for Autonomous Driving
AUTHORS: Hazem Rashed ; Mariam Essam ; Maha Mohamed ; Ahmad El Sallab ; Senthil Yogamani
CATEGORY: cs.CV [cs.CV, cs.RO]
HIGHLIGHT: In this work, we explore end-to-end Moving Object Detection (MOD) on the BEV map directly using monocular images as input. To the best of our knowledge, such a dataset does not exist and we create an extended KITTI-raw dataset consisting of 12.9k images with annotations of moving object masks in BEV space for five classes.
7, TITLE: Deep Fiber Clustering: Anatomically Informed Unsupervised Deep Learning for Fast and Effective White Matter Parcellation
AUTHORS: YUQIAN CHEN et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We propose a novel WMFC framework based on unsupervised deep learning.
8, TITLE: Geographical Knowledge-driven Representation Learning for Remote Sensing Images
AUTHORS: Wenyuan Li ; Keyan Chen ; Hao Chen ; Zhenwei Shi
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: To fully utilize the remaining unlabeled images, we propose a Geographical Knowledge-driven Representation learning method for remote sensing images (GeoKR), improving network performance and reduce the demand for annotated data.
9, TITLE: Learn from Anywhere: Rethinking Generalized Zero-Shot Learning with Limited Supervision
AUTHORS: Gaurav Bhatt ; Shivam Chandok ; Vineeth N Balasubramanian
CATEGORY: cs.CV [cs.CV, cs.AI, cs.LG]
HIGHLIGHT: In this work, we present a practical setting of inductive zero and few-shot learning, where unlabeled images from other out-of-data classes, that do not belong to seen or unseen categories, can be used to improve generalization in any-shot learning.
10, TITLE: Few-Shot Domain Adaptation with Polymorphic Transformers
AUTHORS: SHAOHUA LI et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we propose a Polymorphic Transformer (Polyformer), which can be incorporated into any DNN backbones for few-shot domain adaptation.
11, TITLE: Prediction Surface Uncertainty Quantification in Object Detection Models for Autonomous Driving
AUTHORS: Ferhat Ozgur Catak ; Tao Yue ; Shaukat Ali
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: Hence, we propose a novel method called PURE (Prediction sURface uncErtainty) for measuring prediction uncertainty of such regression models.
12, TITLE: CSL-YOLO: A New Lightweight Object Detection System for Edge Computing
AUTHORS: Yu-Ming Zhang ; Chun-Chieh Lee ; Jun-Wei Hsieh ; Kuo-Chin Fan
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This paper proposes a new lightweight Convolution method Cross-Stage Lightweight (CSL) Module, to generate redundant features from cheap operations.
13, TITLE: Not End-to-End: Explore Multi-Stage Architecture for Online Surgical Phase Recognition
AUTHORS: Fangqiu Yi ; Tingting Jiang
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: To address the problem, we propose a new non end-to-end training strategy and explore different designs of multi-stage architecture for surgical phase recognition task.
14, TITLE: Detection of Plant Leaf Disease Directly in The JPEG Compressed Domain Using Transfer Learning Technique
AUTHORS: Atul Sharma ; Bulla Rajesh ; Mohammed Javed
CATEGORY: cs.CV [cs.CV, cs.LG, eess.IV]
HIGHLIGHT: In this research paper, plant leaf disease detection employing transfer learning is explored in the JPEG compressed domain.
15, TITLE: Lifelong Twin Generative Adversarial Networks
AUTHORS: Fei Ye ; Adrian G. Bors
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: In this paper, we propose a new continuously learning generative model, called the Lifelong Twin Generative Adversarial Networks (LT-GANs).
16, TITLE: A Weakly-Supervised Depth Estimation Network Using Attention Mechanism
AUTHORS: Fang Gao ; Jiabao Wang ; Jun Yu ; Yaoxiong Wang ; Feng Shuang
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: A weakly-supervised framework based on attention nested U-net (ANU) named as ANUW is introduced in this paper for cases with wrong labels.
17, TITLE: DDCNet: Deep Dilated Convolutional Neural Network for Dense Prediction
AUTHORS: Ali Salehi ; Madhusudhanan Balasubramanian
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we present a systemic approach to design network architectures that can provide a larger receptive field while maintaining a higher spatial feature resolution.
18, TITLE: Bayesian Convolutional Neural Networks for Seven Basic Facial Expression Classifications
AUTHORS: Wei Gong ; Hailan Huang
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Based on the traditional Bayesian neural network framework, the ResNet-18_BNN network constructed in this paper has been improved in the following three aspects: (1) A new objective function is proposed, which is composed of the KL loss of uncertain parameters and the intersection of specific parameters.
19, TITLE: Consensual Collaborative Training And Knowledge Distillation Based Facial Expression Recognition Under Noisy Annotations
AUTHORS: Darshan Gera ; S. Balasubramanian
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This work proposes an effective training strategy in the presence of noisy labels, called as Consensual Collaborative Training (CCT) framework.
20, TITLE: Learning 3D Dense Correspondence Via Canonical Point Autoencoder
AUTHORS: An-Chieh Cheng ; Xueting Li ; Min Sun ; Ming-Hsuan Yang ; Sifei Liu
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We propose a canonical point autoencoder (CPAE) that predicts dense correspondences between 3D shapes of the same category.
21, TITLE: Resilience of Autonomous Vehicle Object Category Detection to Universal Adversarial Perturbations
AUTHORS: Mohammad Nayeem Teli ; Seungwon Oh
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we bring a fresh perspective on those procedures by evaluating the impact of universal perturbations on object detection at a class-level.
22, TITLE: Local-to-Global Self-Attention in Vision Transformers
AUTHORS: Jinpeng Li ; Yichao Yan ; Shengcai Liao ; Xiaokang Yang ; Ling Shao
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we design a multi-path structure of the Transformer, which enables local-to-global reasoning at multiple granularities in each stage.
23, TITLE: Multi-view Image-based Hand Geometry Refinement Using Differentiable Monte Carlo Ray Tracing
AUTHORS: Giorgos Karvounas ; Nikolaos Kyriazis ; Iason Oikonomidis ; Aggeliki Tsoli ; Antonis A. Argyros
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We find that there is still room for improvement in both fronts, and even beyond.
24, TITLE: Hierarchical Self-Supervised Learning for Medical Image Segmentation Based on Multi-Domain Data Aggregation
AUTHORS: HAO ZHENG et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we propose Hierarchical Self-Supervised Learning (HSSL), a new self-supervised framework that boosts medical image segmentation by making good use of unannotated data.
25, TITLE: Context-aware Virtual Adversarial Training for Anatomically-plausible Segmentation
AUTHORS: PING WANG et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: To solve this problem, we present a Context-aware Virtual Adversarial Training (CaVAT) method for generating anatomically plausible segmentation.
26, TITLE: Anomaly Detection in Residential Video Surveillance on Edge Devices in IoT Framework
AUTHORS: Mayur R. Parate ; Kishor M. Bhurchandi ; Ashwin G. Kothari
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: Therefore, we propose anomaly detection for intelligent surveillance using CPU-only edge devices.
27, TITLE: 1st Place Solution for ICDAR 2021 Competition on Mathematical Formula Detection
AUTHORS: YUXIANG ZHONG et. al.
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: In this technical report, we present our 1st place solution for the ICDAR 2021 competition on mathematical formula detection (MFD).
28, TITLE: Scaled-Time-Attention Robust Edge Network
AUTHORS: RICHARD LAU et. al.
CATEGORY: cs.CV [cs.CV, 68T05]
HIGHLIGHT: This paper describes a systematic approach towards building a new family of neural networks based on a delay-loop version of a reservoir neural network.
29, TITLE: Let's Play for Action: Recognizing Activities of Daily Living By Learning from Life Simulation Video Games
AUTHORS: ALINA ROITBERG et. al.
CATEGORY: cs.CV [cs.CV, cs.AI, cs.MM, cs.RO]
HIGHLIGHT: In this work, we explore the concept of constructing training examples for ADL recognition by playing life simulation video games and introduce the SIMS4ACTION dataset created with the popular commercial game THE SIMS 4.
30, TITLE: Interpretable Mammographic Image Classification Using Cased-Based Reasoning and Deep Learning
AUTHORS: ALINA JADE BARNETT et. al.
CATEGORY: cs.CV [cs.CV, cs.LG, I.2.6; I.4.9; I.2.10]
HIGHLIGHT: In this work, we present a novel interpretable neural network algorithm that uses case-based reasoning for mammography.
31, TITLE: Structured Latent Embeddings for Recognizing Unseen Classes in Unseen Domains
AUTHORS: SHIVAM CHANDHOK et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we propose a novel approach that learns domain-agnostic structured latent embeddings by projecting images from different domains as well as class-specific semantic text-based representations to a common latent space.
32, TITLE: Few-shot Learning with Global Relatedness Decoupled-Distillation
AUTHORS: YUAN ZHOU et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: To overcome these problems, we propose a new Global Relatedness Decoupled-Distillation (GRDD) method using the global category knowledge and the Relatedness Decoupled-Distillation (RDD) strategy.
33, TITLE: Interpretable Deep Feature Propagation for Early Action Recognition
AUTHORS: He Zhao ; Richard P. Wildes
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this study, we address action prediction by investigating how action patterns evolve over time in a spatial feature space.
34, TITLE: Scenes and Surroundings: Scene Graph Generation Using Relation Transformer
AUTHORS: Rajat Koner ; Poulami Sinhamahapatra ; Volker Tresp
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This work proposes a novel local-context aware architecture named relation transformer, which exploits complex global objects to object and object to edge (relation) interactions.
35, TITLE: AxonEM Dataset: 3D Axon Instance Segmentation of Brain Cortical Regions
AUTHORS: DONGLAI WEI et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: To address this, we introduce the AxonEM dataset, which consists of two 30x30x30 um^3 EM image volumes from the human and mouse cortex, respectively. We publicly release our code and data at https://connectomics-bazaar.github.io/proj/AxonEM/index.html to foster the development of advanced methods.
36, TITLE: Out of Distribution Detection and Adversarial Attacks on Deep Neural Networks for Robust Medical Image Analysis
AUTHORS: Anisie Uwimana1 ; Ransalu Senanayake
CATEGORY: cs.CV [cs.CV, cs.LG, eess.IV]
HIGHLIGHT: In this work, we experimentally evaluate the robustness of a Mahalanobis distance-based confidence score, a simple yet effective method for detecting abnormal input samples, in classifying malaria parasitized cells and uninfected cells.
37, TITLE: Human-like Relational Models for Activity Recognition in Video
AUTHORS: Joseph Chrol-Cannon ; Andrew Gilbert ; Ranko Lazic ; Adithya Madhusoodanan ; Frank Guerin
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Therefore we propose a more human-like approach to activity recognition, which interprets a video in sequential temporal phases and extracts specific relationships among objects and hands in those phases.
38, TITLE: Real-Time Super-Resolution System of 4K-Video Based on Deep Learning
AUTHORS: Yanpeng Cao ; Chengcheng Wang ; Changjun Song ; He Li ; Yongming Tang
CATEGORY: cs.CV [cs.CV, cs.AI, eess.IV]
HIGHLIGHT: Besides, we implement the batch normalization computation fusion, convolutional acceleration algorithm and other neural network acceleration techniques on the actual hardware platform to optimize the inference process of EGVSR network.
39, TITLE: End-to-end Multi-modal Video Temporal Grounding
AUTHORS: Yi-Wen Chen ; Yi-Hsuan Tsai ; Ming-Hsuan Yang
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Different from most existing methods that only consider RGB images as visual features, we propose a multi-modal framework to extract complementary information from videos.
40, TITLE: TTAN: Two-Stage Temporal Alignment Network for Few-shot Action Recognition
AUTHORS: SHUYUAN LI et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we arrest this problem from two distinct aspects -- action duration misalignment and motion evolution misalignment.
41, TITLE: Split, Embed and Merge: An Accurate Table Structure Recognizer
AUTHORS: Zhenrong Zhang ; Jianshu Zhang ; Jun Du
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we introduce Split, Embed and Merge (SEM), an accurate table structure recognizer.
42, TITLE: Delta Sampling R-BERT for Limited Data and Low-light Action Recognition
AUTHORS: Sanchit Hira ; Ritwik Das ; Abhinav Modi ; Daniil Pakhomov
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We present an approach to perform supervised action recognition in the dark.
43, TITLE: Training Deep Cross-modality Conversion Models with A Small Amount of Data and Its Application to MVCT to KVCT Conversion
AUTHORS: SHO OZAKI et. al.
CATEGORY: cs.CV [cs.CV, physics.med-ph]
HIGHLIGHT: Therefore, we performed CT modality conversion based on deep learning requiring only a small number of unsupervised images.
44, TITLE: SynLiDAR: Learning From Synthetic LiDAR Sequential Point Cloud for Semantic Segmentation
AUTHORS: Aoran Xiao ; Jiaxing Huang ; Dayan Guan ; Fangneng Zhan ; Shijian Lu
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We address this issue by collecting SynLiDAR, a synthetic LiDAR point cloud dataset that contains large-scale point-wise annotated point cloud with accurate geometric shapes and comprehensive semantic classes, and designing PCT-Net, a point cloud translation network that aims to narrow down the gap with real-world point cloud data.
45, TITLE: Industry and Academic Research in Computer Vision
AUTHORS: Iuliia Kotseruba
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This work aims to study the dynamic between research in the industry and academia in computer vision.
46, TITLE: LiveView: Dynamic Target-Centered MPI for View Synthesis
AUTHORS: SUSHOBHAN GHOSH et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: We propose LiveView - a novel MPI generation and rendering technique that produces high-quality view synthesis in real-time.
47, TITLE: Review of Video Predictive Understanding: Early ActionRecognition and Future Action Prediction
AUTHORS: He Zhao ; Richard P. Wildes
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this survey, we start by introducing the major sub-areas of the broad area of video predictive understanding, which recently have received intensive attention and proven to have practical value.
48, TITLE: Modeling Explicit Concerning States for Reinforcement Learning in Visual Dialogue
AUTHORS: ZIPENG XU et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we propose Explicit Concerning States (ECS) to represent what visual contents are concerned at each round and what have been concerned throughout the Visual Dialogue.
49, TITLE: AutoFB: Automating Fetal Biometry Estimation from Standard Ultrasound Planes
AUTHORS: SOPHIA BANO et. al.
CATEGORY: cs.CV [cs.CV, cs.LG, eess.IV]
HIGHLIGHT: In this paper, we present a unified automated framework for estimating all measurements needed for the fetal weight assessment.
50, TITLE: ICDAR 2021 Competition on Integrated Circuit Text Spotting and Aesthetic Assessment
AUTHORS: CHUN CHET NG et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: Details of the competition and submission results are presented in this report.
51, TITLE: Spatial and Temporal Networks for Facial Expression Recognition in The Wild Videos
AUTHORS: Shuyi Mao ; Xinqi Fan ; Xiaojiang Peng
CATEGORY: cs.CV [cs.CV, eess.IV]
HIGHLIGHT: The paper describes our proposed methodology for the seven basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2021.
52, TITLE: Locality Relationship Constrained Multi-view Clustering Framework
AUTHORS: Xiangzhu Meng ; Wei Wei ; Wenzhe Liu
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: To solve these issues, we propose a novel multi-view learning method with locality relationship constraint to explore the problem of multi-view clustering, called Locality Relationship Constrained Multi-view Clustering Framework (LRC-MCF).
53, TITLE: End-to-end Trainable Deep Neural Network for Robotic Grasp Detection and Semantic Segmentation from RGB
AUTHORS: Stefan Ainetter ; Friedrich Fraundorfer
CATEGORY: cs.CV [cs.CV, cs.RO]
HIGHLIGHT: In this work, we introduce a novel, end-to-end trainable CNN-based architecture to deliver high quality results for grasp detection suitable for a parallel-plate gripper, and semantic segmentation.
54, TITLE: A Cloud-Edge-Terminal Collaborative System for Temperature Measurement in COVID-19 Prevention
AUTHORS: ZHEYI MA et. al.
CATEGORY: cs.CV [cs.CV, cs.HC, eess.SP]
HIGHLIGHT: In this paper, to realize safe and accurate temperature measurement even when a person's face is partially obscured, we propose a cloud-edge-terminal collaborative system with a lightweight infrared temperature measurement model.
55, TITLE: Learned Super Resolution Ultrasound for Improved Breast Lesion Characterization
AUTHORS: OR BAR-SHIRA et. al.
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: In this work we use a deep neural network architecture that makes effective use of signal structure to address these challenges.
56, TITLE: CFTrack: Center-based Radar and Camera Fusion for 3D Multi-Object Tracking
AUTHORS: Ramin Nabati ; Landon Harris ; Hairong Qi
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we propose an end-to-end network for joint object detection and tracking based on radar and camera sensor fusion.
57, TITLE: SE-PSNet: Silhouette-based Enhancement Feature for Panoptic Segmentation Network
AUTHORS: Shuo-En Chang ; Yi-Cheng Yang ; En-Ting Lin ; Pei-Yung Hsiao ; Li-Chen Fu
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: In this work, we propose a solution to tackle the panoptic segmentation task.
58, TITLE: Visual-Tactile Cross-Modal Data Generation Using Residue-Fusion GAN with Feature-Matching and Perceptual Losses
AUTHORS: Shaoyu Cai ; Kening Zhu ; Yuki Ban ; Takuji Narumi
CATEGORY: cs.CV [cs.CV, cs.AI, cs.RO]
HIGHLIGHT: In this paper, we propose a deep-learning-based approach for cross-modal visual-tactile data generation by leveraging the framework of the generative adversarial networks (GANs).
59, TITLE: GiT: Graph Interactive Transformer for Vehicle Re-identification
AUTHORS: Fei Shen ; Yi Xie ; Jianqing Zhu ; Xiaobin Zhu ; Huanqiang Zeng
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this paper, we propose a graph interactive transformer (GiT) for vehicle re-identification.
60, TITLE: Early Warning of Pedestrians and Cyclists
AUTHORS: Joerg Christian Wolf
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: This paper describes an early pedestrian warning demonstration system.
61, TITLE: TransClaw U-Net: Claw U-Net with Transformers for Medical Image Segmentation
AUTHORS: Yao Chang ; Hu Menghan ; Zhai Guangtao ; Zhang Xiao-Ping
CATEGORY: cs.CV [cs.CV, cs.AI, cs.LG, eess.IV]
HIGHLIGHT: Hence, we propose a TransClaw U-Net network structure, which combines the convolution operation with the transformer operation in the encoding part.
62, TITLE: Cumulative Assessment for Urban 3D Modeling
AUTHORS: SHEA HAGSTROM et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: In this work, we present a cumulative assessment metric that succinctly captures error contributions from each of these components.
63, TITLE: Similarity Guided Deep Face Image Retrieval
AUTHORS: Young Kyun Jang ; Nam Ik Cho
CATEGORY: cs.CV [cs.CV, cs.IR]
HIGHLIGHT: In this paper, we attempt to improve the face image retrieval quality by proposing a Similarity Guided Hashing (SGH) method, which gently considers self and pairwise-similarity simultaneously.
64, TITLE: Towards Accurate Localization By Instance Search
AUTHORS: Yi-Geng Hong ; Hui-Chu Xiao ; Wan-Lei Zhao
CATEGORY: cs.CV [cs.CV, cs.IR]
HIGHLIGHT: In this paper, a self-paced learning framework is proposed to achieve accurate object localization on the rank list returned by instance search.
65, TITLE: Zero-Shot Compositional Concept Learning
AUTHORS: Guangyue Xu ; Parisa Kordjamshidi ; Joyce Y. Chai
CATEGORY: cs.CV [cs.CV, cs.CL]
HIGHLIGHT: In this paper, we study the problem of recognizing compositional attribute-object concepts within the zero-shot learning (ZSL) framework.
66, TITLE: Optimal Triangulation Method Is Not Really Optimal
AUTHORS: Seyed-Mahdi Nasiri ; Reshad Hosseini ; Hadi Moradi
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: For solving this problem, it is the common practice to use so-called optimal triangulation method, which we call the L2 method in this paper.
67, TITLE: Diverse Video Generation Using A Gaussian Process Trigger
AUTHORS: Gaurav Shrivastava ; Abhinav Shrivastava
CATEGORY: cs.CV [cs.CV, cs.AI, cs.LG, cs.RO]
HIGHLIGHT: Instead, we propose to explicitly model the multi-modality in the future outcomes and leverage it to sample diverse futures.
68, TITLE: Self-Supervised Generative Adversarial Network for Depth Estimation in Laparoscopic Images
AUTHORS: BAORU HUANG et. al.
CATEGORY: cs.CV [cs.CV]
HIGHLIGHT: To overcome this limitation, we propose SADepth, a new self-supervised depth estimation method based on Generative Adversarial Networks.
69, TITLE: Efficient Real-Time Image Recognition Using Collaborative Swarm of UAVs and Convolutional Networks
AUTHORS: Marwan Dhuheir ; Emna Baccour ; Aiman Erbad ; Sinan Sabeeh ; Mounir Hamdi
CATEGORY: cs.CV [cs.CV, cs.DC]
HIGHLIGHT: In this work, we present a strategy aiming at distributing inference requests to a swarm of resource-constrained UAVs that classifies captured images on-board and finds the minimum decision-making latency.
70, TITLE: A Projector-Camera System Using Hybrid Pixels with Projection and Capturing Capabilities
AUTHORS: Kenta Yamamoto ; Daisuke Iwai ; Kosuke Sato
CATEGORY: cs.CV [cs.CV, cs.GR]
HIGHLIGHT: We propose a novel projector-camera system (ProCams) in which each pixel has both projection and capturing capabilities.
71, TITLE: One Map Does Not Fit All: Evaluating Saliency Map Explanation on Multi-Modal Medical Images
AUTHORS: Weina Jin ; Xiaoxiao Li ; Ghassan Hamarneh
CATEGORY: cs.CV [cs.CV, cs.LG]
HIGHLIGHT: To tackle this clinically important but technically ignored problem, we propose the MSFI (Modality-Specific Feature Importance) metric to examine whether saliency maps can highlight modality-specific important features.
72, TITLE: Semi-Supervised Object Detection with Adaptive Class-Rebalancing Self-Training
AUTHORS: Fangyuan Zhang ; Tianxiang Pan ; Bin Wang
CATEGORY: cs.CV [cs.CV, cs.AI]
HIGHLIGHT: Therefore, we propose a novel two-stage filtering algorithm to generate accurate pseudo-labels.
73, TITLE: Blending Pruning Criteria for Convolutional Neural Networks
AUTHORS: Wei He ; Zhongzhan Huang ; Mingfu Liang ; Senwei Liang ; Haizhao Yang
CATEGORY: cs.CV [cs.CV, cs.AI, cs.LG]
HIGHLIGHT: From this motivation, we propose a novel framework to integrate the existing filter pruning criteria by exploring the criteria diversity.
74, TITLE: Zero-Shot Scene Graph Relation Prediction Through Commonsense Knowledge Integration
AUTHORS: Xuan Kan ; Hejie Cui ; Carl Yang
CATEGORY: cs.CV [cs.CV, cs.LG, I.4.8; I.2.4; I.2.6]
HIGHLIGHT: In this work, we stress that such incapability is due to the lack of commonsense reasoning,i.e., the ability to associate similar entities and infer similar relations based on general understanding of the world.
75, TITLE: Non-linear Visual Knowledge Discovery with Elliptic Paired Coordinates
AUTHORS: Rose McDonald ; Boris Kovalerchuk
CATEGORY: cs.LG [cs.LG, cs.CV, cs.GR]
HIGHLIGHT: An interactive software system EllipseVis, which is developed in this work, processes high-dimensional datasets, creates EPC visualizations, and produces predictive classification models by discovering dominance rules in EPC.
76, TITLE: Identifying Layers Susceptible to Adversarial Attacks
AUTHORS: Shoaib Ahmed Siddiqui ; Thomas Breuel
CATEGORY: cs.LG [cs.LG, cs.AI, cs.CV]
HIGHLIGHT: We test this question by large-scale non-linear dimensionality reduction and density modeling on distributions of feature vectors in hidden layers and find that the feature distributions between non-adversarial and adversarial samples differ substantially.
77, TITLE: Automated Graph Learning Via Population Based Self-Tuning GCN
AUTHORS: Ronghang Zhu ; Zhiqiang Tao ; Yaliang Li ; Sheng Li
CATEGORY: cs.LG [cs.LG, cs.CV]
HIGHLIGHT: In this paper, we aim to automate the training of GCN models through hyperparameter optimization.
78, TITLE: A Topological-Framework to Improve Analysis of Machine Learning Model Performance
AUTHORS: HENRY KVINGE et. al.
CATEGORY: cs.LG [cs.LG, cs.CV, math.GN]
HIGHLIGHT: In this paper we propose a topological framework for evaluating machine learning models in which a dataset is treated as a "space" on which a model operates.
79, TITLE: Lifelong Teacher-Student Network Learning
AUTHORS: Fei Ye ; Adrian G. Bors
CATEGORY: cs.LG [cs.LG, cs.AI, cs.CV]
HIGHLIGHT: We propose a novel lifelong learning methodology by employing a Teacher-Student network framework.
80, TITLE: Lifelong Mixture of Variational Autoencoders
AUTHORS: Fei Ye ; Adrian G. Bors
CATEGORY: cs.LG [cs.LG, cs.AI, cs.CV]
HIGHLIGHT: In this paper, we propose an end-to-end lifelong learning mixture of experts.
81, TITLE: Source-Free Adaptation to Measurement Shift Via Bottom-Up Feature Restoration
AUTHORS: Cian Eastwood ; Ian Mason ; Christopher K. I. Williams ; Bernhard Sch�lkopf
CATEGORY: cs.LG [cs.LG, cs.AI, cs.CV, stat.ML]
HIGHLIGHT: We address these issues for a particularly pervasive type of domain shift called measurement shift, characterized by a change in measurement system (e.g. a change in sensor or lighting).
82, TITLE: Hierarchical Neural Dynamic Policies
AUTHORS: Shikhar Bahl ; Abhinav Gupta ; Deepak Pathak
CATEGORY: cs.LG [cs.LG, cs.AI, cs.CV, cs.RO, cs.SY, eess.SY]
HIGHLIGHT: In this paper, we address this dichotomy by leveraging embedding the structure of dynamical systems in a hierarchical deep policy learning framework, called Hierarchical Neural Dynamical Policies (H-NDPs).
83, TITLE: Semi-Supervised Learning with Multi-Head Co-Training
AUTHORS: Mingcai Chen ; Yuntao Du ; Yi Zhang ; Shuwei Qian ; Chongjun Wang
CATEGORY: cs.LG [cs.LG, cs.CV]
HIGHLIGHT: In this paper, we present a simple and efficient co-training algorithm, named Multi-Head Co-Training, for semi-supervised image classification.
84, TITLE: Fine-Grained AutoAugmentation for Multi-label Classification
AUTHORS: YA WANG et. al.
CATEGORY: cs.LG [cs.LG, cs.CV]
HIGHLIGHT: To tackle this problem, we propose a novel Label-Based AutoAugmentation (LB-Aug) method for multi-label scenarios, where augmentation policies are generated with respect to labels by an augmentation-policy network.
85, TITLE: Prb-GAN: A Probabilistic Framework for GAN Modelling
AUTHORS: Blessen George ; Vinod K. Kurmi ; Vinay P. Namboodiri
CATEGORY: cs.LG [cs.LG, cs.CV, stat.ML]
HIGHLIGHT: We present Prb-GANs, a new variation that uses dropout to create a distribution over the network parameters with the posterior learnt using variational inference.
86, TITLE: BrainNNExplainer: An Interpretable Graph Neural Network Framework for Brain Network Based Disease Analysis
AUTHORS: HEJIE CUI et. al.
CATEGORY: cs.LG [cs.LG, cs.CV, eess.IV, q-bio.NC, 68T07, 68T45, 68T20, I.2.6; I.2.10; J.3]
HIGHLIGHT: To bridge this gap, we propose BrainNNExplainer, an interpretable GNN framework for brain network analysis.
87, TITLE: InfoVAEGAN : Learning Joint Interpretable Representations By Information Maximization and Maximum Likelihood
AUTHORS: Fei Ye ; Adrian G. Bors
CATEGORY: cs.LG [cs.LG, cs.AI, cs.CV]
HIGHLIGHT: In this paper, we propose a novel representation learning algorithm which combines the inference abilities of Variational Autoencoders (VAE) with the generalization capability of Generative Adversarial Networks (GAN).
88, TITLE: Remote Blood Oxygen Estimation From Videos Using Neural Networks
AUTHORS: Joshua Mathew ; Xin Tian ; Min Wu ; Chau-Wai Wong
CATEGORY: cs.LG [cs.LG, cs.CV, eess.IV]
HIGHLIGHT: In this paper, we propose the first convolutional neural network based noncontact SpO$_2$ estimation scheme using smartphone cameras.
89, TITLE: DualVGR: A Dual-Visual Graph Reasoning Unit for Video Question Answering
AUTHORS: Jianyu Wang ; Bing-Kun Bao ; Changsheng Xu
CATEGORY: cs.MM [cs.MM, cs.AI, cs.CV]
HIGHLIGHT: Based on these observations, we propose a Dual-Visual Graph Reasoning Unit (DualVGR) which reasons over videos in an end-to-end fashion.
90, TITLE: SynPick: A Dataset for Dynamic Bin Picking Scene Understanding
AUTHORS: Arul Selvam Periyasamy ; Max Schwarz ; Sven Behnke
CATEGORY: cs.RO [cs.RO, cs.CV]
HIGHLIGHT: We present SynPick, a synthetic dataset for dynamic scene understanding in bin-picking scenarios.
91, TITLE: A Persistent Spatial Semantic Representation for High-level Natural Language Instruction Execution
AUTHORS: Valts Blukis ; Chris Paxton ; Dieter Fox ; Animesh Garg ; Yoav Artzi
CATEGORY: cs.RO [cs.RO, cs.AI, cs.CL, cs.CV, cs.LG]
HIGHLIGHT: We propose a persistent spatial semantic representation method, and show how it enables building an agent that performs hierarchical reasoning to effectively execute long-term tasks.
92, TITLE: Feature-based Event Stereo Visual Odometry
AUTHORS: Antea Hadviger ; Igor Cvi?i? ; Ivan Markovi? ; Sacha Vra?i? ; Ivan Petrovi?
CATEGORY: cs.RO [cs.RO, cs.CV]
HIGHLIGHT: In this paper, we propose a novel stereo visual odometry method for event cameras based on feature detection and matching with careful feature management, while pose estimation is done by reprojection error minimization.
93, TITLE: Deep Geometric Distillation Network for Compressive Sensing MRI
AUTHORS: Xiaohong Fan ; Yin Yang ; Jianping Zhang
CATEGORY: eess.IV [eess.IV, cs.CV, 68T05, 68T20, 68T09, 68W25, F.2.2; I.2.7]
HIGHLIGHT: In this work, we propose a novel deep geometric distillation network which combines the merits of model-based and deep learning-based CS-MRI methods, it can be theoretically guaranteed to improve geometric texture details of a linear reconstruction.
94, TITLE: TeliNet, A Simple and Shallow Convolution Neural Network (CNN) to Classify CT Scans of COVID-19 Patients
AUTHORS: Mohammad Nayeem Teli
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this research we present a simple and shallow Convolutional Neural Network based approach, TeliNet, to classify CT-scan images of COVID-19 patients.
95, TITLE: TransAttUnet: Multi-level Attention-guided U-Net with Transformer for Medical Image Segmentation
AUTHORS: Bingzhi Chen ; Yishu Liu ; Zheng Zhang ; Guangming Lu ; David Zhang
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: To overcome the above challenges, this paper proposes a novel Transformer based medical image semantic segmentation framework called TransAttUnet, in which the multi-level guided attention and multi-scale skip connection are jointly designed to effectively enhance the functionality and flexibility of traditional U-shaped architecture.
96, TITLE: COVID Detection in Chest CTs: Improving The Baseline on COV19-CT-DB
AUTHORS: Radu Miron ; Cosmin Moisii ; Sergiu Dinu ; Mihaela Breaban
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: The paper presents a comparative analysis of three distinct approaches based on deep learning for COVID-19 detection in chest CTs.
97, TITLE: BSDA-Net: A Boundary Shape and Distance Aware Joint Learning Framework for Segmenting and Classifying OCTA Images
AUTHORS: LI LIN et. al.
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this paper, we propose a novel multi-level boundary shape and distance aware joint learning framework, named BSDA-Net, for FAZ segmentation and diagnostic classification from OCTA images.
98, TITLE: U-Net with Hierarchical Bottleneck Attention for Landmark Detection in Fundus Images of The Degenerated Retina
AUTHORS: Shuyun Tang ; Ziming Qi ; Jacob Granley ; Michael Beyeler
CATEGORY: eess.IV [eess.IV, cs.CV, cs.LG]
HIGHLIGHT: Here we propose HBA-U-Net: a U-Net backbone enriched with hierarchical bottleneck attention.
99, TITLE: Weaving Attention U-net: A Novel Hybrid CNN and Attention-based Method for Organs-at-risk Segmentation in Head and Neck CT Images
AUTHORS: Zhuangzhuang Zhang ; Tianyu Zhao ; Hiram Gay ; Weixiong Zhang ; Baozhou Sun
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: We aim to develop a novel hybrid deep learning approach, combining convolutional neural networks (CNNs) and the self-attention mechanism, for rapid and accurate multi-organ segmentation on head and neck computed tomography (CT) images.
100, TITLE: MoDIR: Motion-Compensated Training for Deep Image Reconstruction Without Ground Truth
AUTHORS: WEIJIE GAN et. al.
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: This paper addresses this issue by proposing a novel motion-compensated deep image reconstruction (MoDIR) method that can use information from several unregistered and noisy measurements for training.
101, TITLE: Details Preserving Deep Collaborative Filtering-Based Method for Image Denoising
AUTHORS: Basit O. Alawode ; Mudassir Masood ; Tarig Ballal ; Tareq Al-Naffouri
CATEGORY: eess.IV [eess.IV, cs.CV, cs.LG]
HIGHLIGHT: In this paper, we propose an algorithm to address this shortcoming.
102, TITLE: R3L: Connecting Deep Reinforcement Learning to Recurrent Neural Networks for Image Denoising Via Residual Recovery
AUTHORS: Rongkai Zhang ; Jiang Zhu ; Zhiyuan Zha ; Justin Dauwels ; Bihan Wen
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this work, we propose a novel image denoising scheme via Residual Recovery using Reinforcement Learning, dubbed R3L.
103, TITLE: Visual Transformer with Statistical Test for COVID-19 Classification
AUTHORS: Chih-Chung Hsu ; Guan-Lin Chen ; Mei-Hsuan Wu
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: We simultaneously propose 2-D and 3-D models to predict the COVID-19 of CT scan to tickle this issue.
104, TITLE: EndoUDA: A Modality Independent Segmentation Approach for Endoscopy Imaging
AUTHORS: Numan Celik ; Sharib Ali ; Soumya Gupta ; Barbara Braden ; Jens Rittscher
CATEGORY: eess.IV [eess.IV, cs.CV, cs.LG]
HIGHLIGHT: In this context, we propose a novel UDA-based segmentation method that couples the variational autoencoder and U-Net with a common EfficientNet-B4 backbone, and uses a joint loss for latent-space optimization for target samples.
105, TITLE: The Power of Proxy Data and Proxy Networks for Hyper-Parameter Optimization in Medical Image Segmentation
AUTHORS: VISHWESH NATH et. al.
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this work, we focus on accelerating the estimation of hyper-parameters by proposing two novel methodologies: proxy data and proxy networks.
106, TITLE: NeoUNet: Towards Accurate Colon Polyp Segmentation and Neoplasm Detection
AUTHORS: PHAN NGOC LAN et. al.
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this work, we propose a fine-grained formulation for the polyp segmentation problem.
107, TITLE: Synthesizing Multi-Tracer PET Images for Alzheimer's Disease Patients Using A 3D Unified Anatomy-aware Cyclic Adversarial Network
AUTHORS: BO ZHOU et. al.
CATEGORY: eess.IV [eess.IV, cs.AI, cs.CV]
HIGHLIGHT: To tackle these issues, we propose a 3D unified anatomy-aware cyclic adversarial network (UCAN) for translating multi-tracer PET volumes with one unified generative model, where MR with anatomical information is incorporated.
108, TITLE: Deep-learning-based Hyperspectral Imaging Through A RGB Camera
AUTHORS: XINYU GAO et. al.
CATEGORY: eess.IV [eess.IV, cs.CV]
HIGHLIGHT: In this study, we focused on the influence of the RGB camera spectral sensitivity (CSS) on the HSI.
109, TITLE: Effect of Input Size on The Classification of Lung Nodules Using Convolutional Neural Networks
AUTHORS: Gorkem Polat ; Yesim Dogrusoz Serinagaoglu ; Ugur Halici
CATEGORY: eess.IV [eess.IV, cs.CV, cs.LG]
HIGHLIGHT: In this study, we proposed a framework that analyzes CT lung screenings using convolutional neural networks (CNNs) to reduce false positives.
110, TITLE: EGHWT: The Extended Generalized Haar-Walsh Transform
AUTHORS: Naoki Saito ; Yiqun Shao
CATEGORY: eess.SP [eess.SP, cs.CV, cs.IT, cs.NA, math.CO, math.IT, math.NA]
HIGHLIGHT: We propose the extended Generalized Haar-Walsh Transform (eGHWT), which is a generalization of the adapted time-frequency tilings of Thiele and Villemoes (1996).