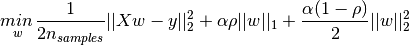L1 Loss(也称为Mean Absolute Error)是深度学习中常用的一种损失函数,用于衡量模型预测结果与真实标签之间的平均绝对误差。具体来说,对于一个大小为N的样本集合,L1 Loss定义如下:
L 1 ( y , y ^ ) = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ L_{ 1 }(y, \hat{y}) = \frac{1}{N} \sum_{i=1}^{N}|y_i - \hat{y}_i| L1(y,y^)=N1∑i=1N∣yi−y^i∣
其中, y i y_i yi表示样本i的真实标签(ground truth), y ^ i \hat{y}_i y^i表示模型对于样本i的预测标签。将每个样本的绝对误差取平均值,得到L1 Loss。
与L2 Loss(也称为Mean Squared Error)相比,L1 Loss更加鲁棒,对于异常值(outliers)的容忍性更高。因此,在某些需要考虑异常值的任务中,例如目标检测、人脸识别等领域,L1 Loss被广泛应用。