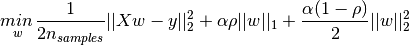正则项
一般地,我们优化 M S E MSE MSE
l m s e = ∑ i ( y i − y ^ i ) 2 n l_{mse}=\frac{\sum_i (y_i-\hat y_i)^2}{n} lmse=n∑i(yi−y^i)2
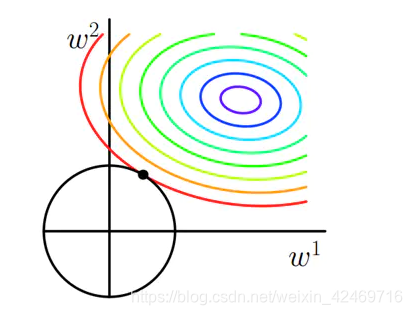
为了使参数尽可能小,加入正则项,防止过拟合,减小方差。L1正则可以更容易得到稀疏项。这一点可以降低参数量举个例子。例如我们的参数只有 w 1 w_1 w1和 w 2 w_2 w2,那么我们的目标是让损失为0,如果损失为0,L1正则对应的是菱形,L2正则对应的是圆, M S E MSE MSE损失函数对应的是偏离原点的椭圆,是关于椭圆的平移变换。
l m s e + ∣ w 1 ∣ + ∣ w 2 ∣ = 0 l_{mse}+|w_1|+|w_2| = 0 lmse+∣w1∣+∣w2∣=0
则
l m s e = − ( ∣ w 1 ∣ + ∣ w 2 ∣ ) l_{mse} = - (|w_1|+|w_2|) lmse=−(∣w1∣+∣w2∣)
− ( ∣ w 1 ∣ + ∣ w 2 ∣ ) - (|w_1|+|w_2|) −(∣w1∣+∣w2∣)表示一个菱形,与 l m s e l_{mse} lmse的交点可以更容易使得 w 1 w_1 w1和 w 2 w_2 w2为0,得到稀疏性。
注:上述这一部分可以参考西瓜书253页
参考资料
https://blog.csdn.net/jinping_shi/article/details/52433975 (感觉讲的不错)