面向:对keras、多层感知器模型、IMDb数据有一定认识
参考教材《TensorFLow+Keras深度学习人工智能应用》
实现工具:jupyter notebook
基本流程
- (1)数据预处理
- (2)建立多层感知器模型
- (3)训练模型
- (4)评估及预测模型
- (5)任意测试一条影评数据
- (6)扩展
- ①使用较大字典提取更多文字
- ②keras使用RNN模型进行Imdb分析
- ③keras使用LSTM模型进行Imdb分析
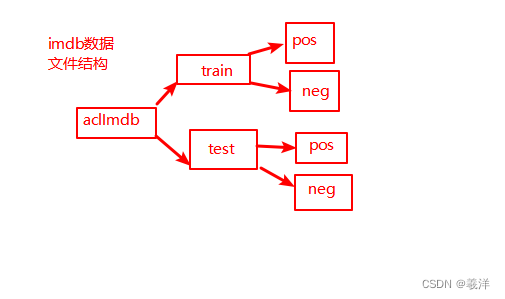
(1)数据预处理
imdb数据集下载地址
下载之后保存到本地文件夹即可
# 导入相关库
from keras.preprocessing import sequence # 后期对数字长度控制的向量
from keras.preprocessing.text import Tokenizer # 字典库 将文字列表转为数字列表
import re
# 定义正则去除文本中的html标签
def re_tags(text):re_tag = re.compile(r'<(^>)+>')return re_tag.sub('',text)
import os
# 读取imdb文件
def readfile(filetype):path = '../data/aclImdb/'# filetype train or testpositive_path = path + filetype + '/pos/'# 定义文件列表filelist =[]# 遍历filetype类型下postive的文件for f in os.listdir(positive_path):filelist += [positive_path + f]negative_path = path + filetype + '/neg/'for f in os.listdir(negative_path):filelist += [negative_path + f]print('read:',filetype,'files',len(filelist))# 前面12500条积极数据 后面12500消极数据all_labels = ([1] * 12500 + [0] * 12500)all_texts = []for fi in filelist:# 读取所有file文件with open(fi,encoding='utf-8') as fileinput:all_texts += [re_tags(' '.join(fileinput.readlines()))]return all_labels,all_texts
# 读取训练数据
y_train,train_text = readfile('train')
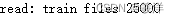
# 读取测试数据
y_test,test_text = readfile('test')

token = Tokenizer(num_words =2000) # 指定字典存储的最大个数 只存储出现次数最多的2000个词
token.fit_on_texts(train_text) # 提取train_text中排名前2000的词
x_train_seq = token.texts_to_sequences(train_text) # 将影评文字转换为数字列表
x_test_seq = token.texts_to_sequences(test_text)
# 数字列表序列化 统一长度为100 不足往前补零 多了切割前面多余的部分
x_train = sequence.pad_sequences(x_train_seq,maxlen=100)
x_test = sequence.pad_sequences(x_test_seq,maxlen=100)
(2)建立多层感知器模型
需要先加入嵌入层将“数字列表“转为”向量列表”
# 导入相关库
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Flatten
from keras.layers.embeddings import Embedding
# 初始化
model = Sequential()
# 嵌入层
# 2000个维度的字典 每个数字列表长度为100 输出维度32维
model.add(Embedding(input_dim=2000,input_length=100,output_dim=32))
model.add(Dropout(0.2))
# 平坦层
model.add(Flatten())
# 隐层
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.35))
# 输出层
model.add(Dense(units=1,activation='sigmoid'))
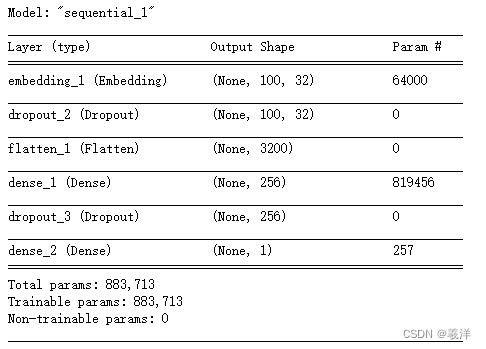
model.summary()
(3)训练模型
import numpy as np
# 将y_train转为numpy类型
y_train = np.array(y_train)# 定义训练方式
# 二分的 交叉熵损失函数 adam优化器 accuracy作为评判标准
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# 开始训练
train_history = model.fit(x_train,y_train,validation_split=0.2,epochs=10,batch_size=100,verbose=2)

(4)评估及预测模型
# 模型评估
# 转为numpy类型
y_test = np.array(y_test)
scores = model.evaluate(x_test,y_test)
scores[1]

# 模型预测 tensorflow2.6以下 可以用 model.predict_classes()一个方法
predict_x = model.predict(x_test)
# 取最大值下标的索引 实际测试predict_x 中只有一个值 返回都是0(最大值下标都是0)
# predict = np.argmax(predict_x,axis=1)
# 转为0 1 在reshape成一维矩阵 转为整数类型
predict = np.round(predict_x).reshape(-1).astype('int32')
# 建立可视化显示预测函数
SentimentDict = {1:'正面的',0:'负面的'}
def display_test_sentiment(i):# 显示原文print(test_text[i])# 显示预测结果print('labels:',SentimentDict[y_test[i]],'predict:',SentimentDict[predict[i]])
display_test_sentiment(1)

display_test_sentiment(12501)

(5)任意测试一条影评数据
# 首先定义文本测试函数
def predict_review(input_text):# 先转数字格式input_seq = token.texts_to_sequences([input_text])# 限定长度pad_input_seq = sequence.pad_sequences(input_seq,maxlen=100)# 进行测试predict_result = np.round(model.predict(pad_input_seq)).reshape(-1).astype('int32')print(SentimentDict[predict_result[0]])
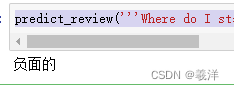
这里找的是《美女与野兽》的一星影评做测试
predict_review('''Where do I start. This adaptation of Disney's 1991 Beauty and the Beast was an utter disappointment. Emma Watson as Belle was extremely unconvincing from the start to the end. She had the same expressions as the actress from Twilight. The animators did a terrible job with the Beast. He looked fake and lifeless. They could have used special makeup to create the beast similar to the Grinch where we get to see Jim Carrey's expressions. The side character animations were poorly executed. Overall I felt the film was rushed as there was lack of compassion and chemistry between the characters. There was a lot of CGI and green screen which could have been replaced by normal acting, because then why make an animated version of an animated film? This is by far the worst remake of an animated classic.''')
九星测试
predict_review('''Very much like the cartoon! The singing was really good ... Emma Watson ... what a star! The acting was great. I was in two minds about seeing this as it's my favorite fairy story and my favorite Disney cartoon. I was in tears at the end, even though I knew the story backwards. Why didn't I give it 10 ... The thing that let it down a little for me was the make up of The Beast, I thought it was a little too scary for the film and the wolves were quite a bit nastier than the cartoon version. Young children may be scared by these things.''')
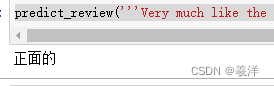
(6)扩展
①使用较大字典提取更多文字
仅展示需要修改的地方
token = Tokenizer(num_words =3800) # 指定字典存储的最大个数 只存储出现次数最多的3800个词
token.fit_on_texts(train_text) # 提取train_text中排名前3800的词
# 数字列表序列化 统一长度为380 不足往前补零 多了切割前面多余的部分
x_train = sequence.pad_sequences(x_train_seq,maxlen=380)
x_test = sequence.pad_sequences(x_test_seq,maxlen=380)
# 初始化
model = Sequential()
# 嵌入层
# 3800个维度的字典 每个数字列表长度为380 输出维度32维
model.add(Embedding(input_dim=3800,input_length=380,output_dim=32))
model.add(Dropout(0.2))
# 平坦层
model.add(Flatten())
# 隐层
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.35))
# 输出层
model.add(Dense(units=1,activation='sigmoid'))
# 首先定义文本测试函数
def predict_review(input_text):# 先转数字格式input_seq = token.texts_to_sequences([input_text])# 限定长度pad_input_seq = sequence.pad_sequences(input_seq,maxlen=380)# 进行测试predict_result = np.round(model.predict(pad_input_seq)).reshape(-1).astype('int32')print(SentimentDict[predict_result[0]])
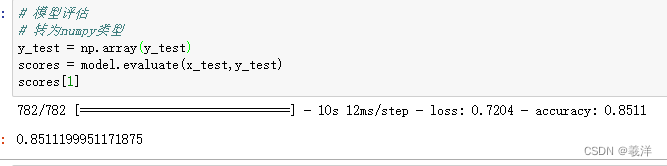
准确率从80%提升到85%
②keras使用RNN模型进行Imdb分析
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Flatten
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import SimpleRNN
# 初始化
model = Sequential()
# 嵌入层
# 3800个维度的字典 每个数字列表长度为380 输出维度32维
model.add(Embedding(input_dim=3800,input_length=380,output_dim=32))
model.add(Dropout(0.2))
# 平坦层
# model.add(Flatten())
# RNN
model.add(SimpleRNN(units=16)) # 16个神经元
# 隐层
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.35))
# 输出层
model.add(Dense(units=1,activation='sigmoid'))
model.summary()

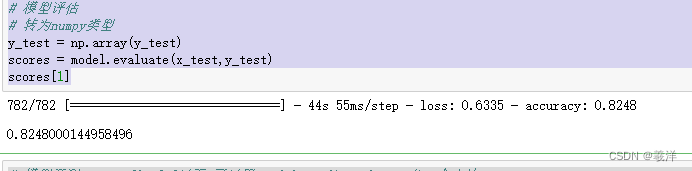
准确率大概在82%左右
③keras使用LSTM模型进行Imdb分析
from keras.models import Sequential
from keras.layers.core import Dense,Dropout,Flatten
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import SimpleRNN,LSTM
# 初始化
model = Sequential()
# 嵌入层
# 3800个维度的字典 每个数字列表长度为380 输出维度32维
model.add(Embedding(input_dim=3800,input_length=380,output_dim=32))
model.add(Dropout(0.2))
# 平坦层
# model.add(Flatten())
# RNN
# model.add(SimpleRNN(units=16)) # 16个神经元
# LSTM
model.add(LSTM(32))
# 隐层
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.2))
# 输出层
model.add(Dense(units=1,activation='sigmoid'))
model.summary()
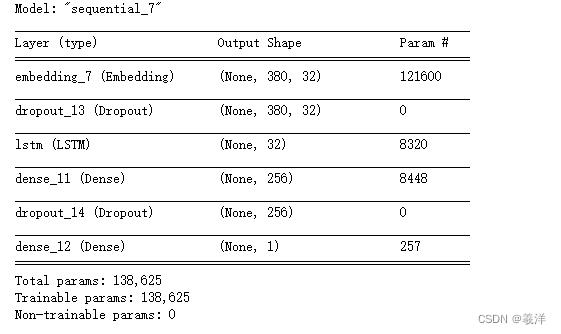

模型评估准确率在85%






