目录
- 前言
- 一 到 三
- 四. 滑动窗口
- 五. 流量控制
- 六. 拥塞控制
- 七. 延时应答
- 八. 捎带应答
- 九. 面向字节流
- 十. 异常处理
- 总结
前言
TCP协议是传输层的重点协议, 负责将数据从发送端传输到接收端.
TCP协议是传输控制协议, 顾名思义也就是对数据的传输进行控制的协议.
TCP 协议有很多, 我们今天就介绍其最重要的十个核心机制, 即 :
- 确认应答
- 超时重传
- 连接管理
- 滑动窗口
- 流量控制
- 拥塞控制
- 延迟应答
- 捎带应答
- 面向字节流
- 异常处理
一 到 三
确认应答及超时重传(保证TCP的可靠性)
连接管理(三次握手及四次挥手)
下面就详细讲解其它七点特性.
四. 滑动窗口
相比于 UDP 来说 TCP 的效率是很低的, 使用 TCP 最重要的还是为了保证可靠性, 在可靠性的基础上再来尽可能高的提高效率, 当然再怎么提高都不如 UDP, 这只是尽可能的止损. (提高可靠性, 往往要损失效率, 所谓鱼和熊掌不可兼得)
什么是滑动窗口呢 ? 滑动窗口又是如何提高效率的呢 ?
首先, 我们回到两台主机间的数据传输, 我们知道 TCP 因为要保证数据的可靠性, 因此在数据接收方在接收到数据后, 就会发送一个 ack 报文, 来告知发送方已接收到数据请发下一条数据, 具体场景如下:

观察上图, 我们发现这些数据都是一条一条发送, 发送完了一条还得对方回应再发送, 我们是不是可以对其进行优化, 使得等待时间变短. 滑动窗口就是通过减少等待时间, 来增大传输效率的.
具体场景如下:

可以看到, 滑动窗口是通过批量发送数据来达到减少等待时间的目的.
这里是批量发送四个数据, 再统一等待 ack, 每次收到一个 ack 就发下一条, 用一份等待时间等待多个ack, 这样总的等待时间变短了, 总体效率也就提高了.
批量传输为啥要叫滑动窗口呢 ?
批量传输不是无限传输, 它是发送一定的数据然后等待 ack, 每等到一个 ack 就立即再传输一个数据, 这样总的等待数量就不变, 我们把批量等待数据的大小就叫做窗口大小, 场景如下:
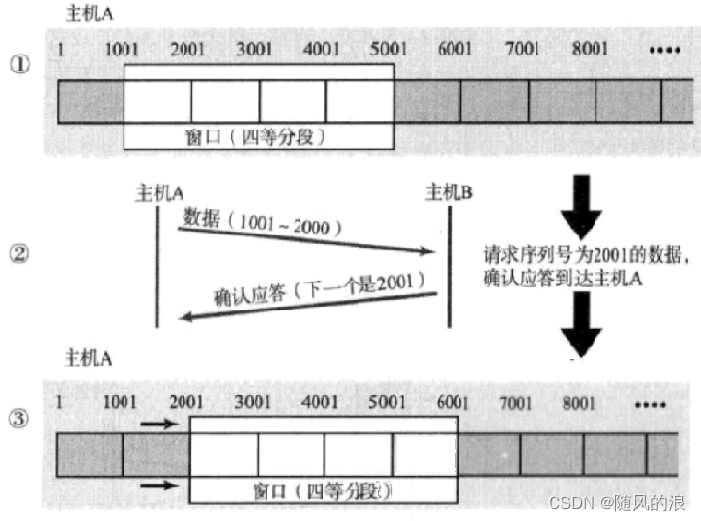
电脑的传输处理数据能力是非常快的, 因此这个窗口就像一直处在滑动状态.
那如果在批量传输过程中出现丢包情况怎么办 ?
这里我们可以分两种情况, 一种是数据报抵达但 ack 丢了, 另一种是数据报丢了.
情况一 : ack丢了.

图中的 ack 丢了一半多了, 丢包率相当高了, 这种情况有啥影响吗 ?
其实即是丢了这么多 ack, 对可靠性也没任何影响.
我们知道返回的 ack 中有确认序号, 确认序号的含义就是该序号之前的数据已经收到了.
注意 : 后一个 ack 能够涵盖前一个 ack 的意思, 举个例子 :
我们看图中返回的确认序号 1001 丢了, 但 2001 到了, 这个时候接收方收到 2001 之前的数据, 发送方即使没收到 1001, 根据 2001 也知道前面的数据都收到了, 接着就是发下面的数据了.
那如果最后一条数据丢了呢 ?
很简单, 超时重传.(发送方不知道是ack丢了还是数据包丢了)
情况二 : 数据包直接丢了
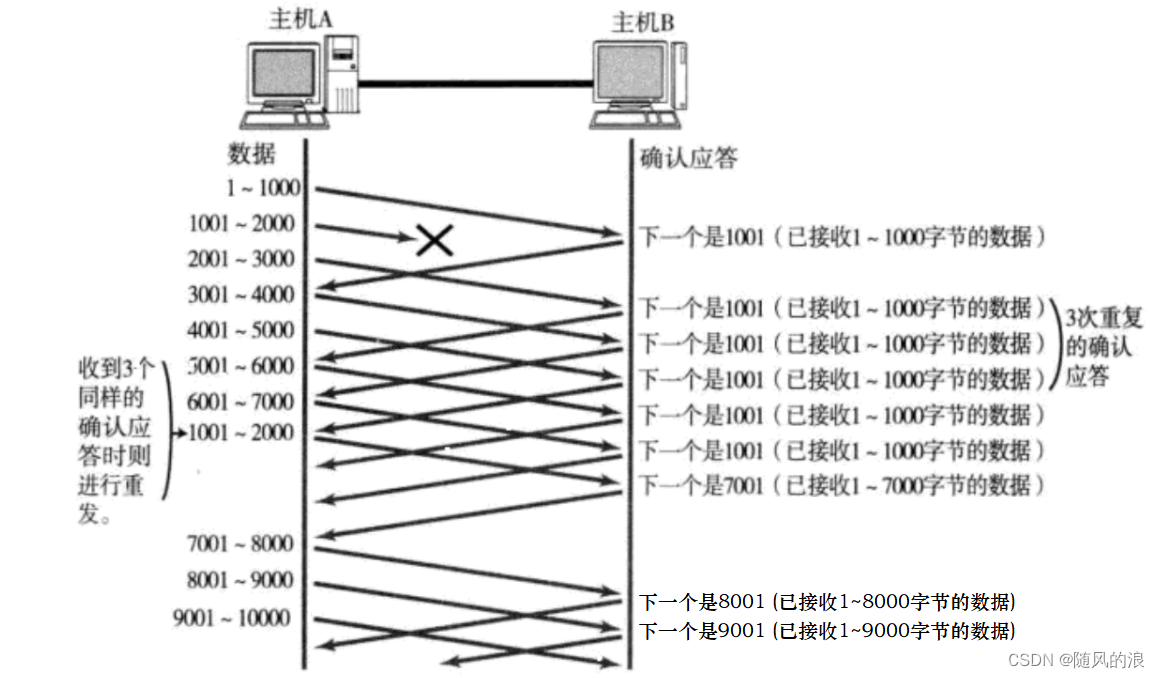
上图中 1001-2000 的数据包丢了, 接收方接收到的数据, 是按照序号在缓冲区进行排列的, 如下 :
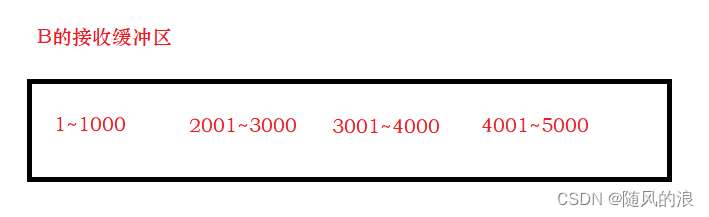
B接收到 2001-3000, 3001-4000, 4001-5000 时就会发现少了 1001-2000 的数据, 这个时候返回的确认序号就是 1001, 即向A索要 1001 开始的数据, 如果A一直不发送, 那 B 会一直索要, 当 B 发送了三个重复确认序号时, A 就会发现事情不简单, 就会重新发送 1001-2000 的数据, 当 B 接收到后, 就不是发送 2001 的确认序号了, 而是索要接下来未发送的数据, 也就是 5001.

注意 : 上述重传过程没有任何冗余操作, 丢了的数据才会进行重传, 整体速度比较快, 又叫快速重传.
滑动窗口及快速重传是在批量传输大量数据时才会采用的措施, 当数据量少, 且比较低频时, 就不会这样搞了, 此时依靠确认应答及超时重传.
五. 流量控制
为啥要流量控制呢 ?
上面讲了滑动窗口, 批量发送, 窗口越大, 批量发送的数据就越多, 传输的效率也就越大了.
但滑动窗口大小可不是无限大的, 得保证可靠传输, 如果一次性发的数据包太多了, 瞬间就会将接收方的数据接收缓冲区给冲满, 接下来继续发送就会丢失数据包, 得不偿失.
通过流量控制, 本质上就是让接收方来限制发送方的发送速度.
它是如何控制的呢 ?
其实在 TCP 报文中, 携带了 “窗口大小” 这样的字段, 如下 :
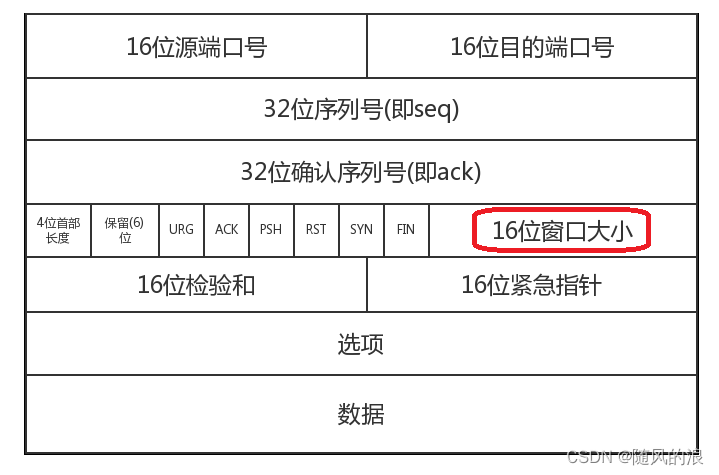
当 ack 为 1 时, 此时窗口大小字段就会生效, 这里的值只是建议发送方发送的窗口大小.
那接收方是如何计算窗口大小的呢?
接收方直接拿缓冲区剩余空间作为窗口大小.

① : 当 B 收到数据时, 根据缓冲区大小计算窗口大小, 并写入 ack 中.
② : A 收到窗口大小后, 批量发送适量的数据.
③ : B 每次收到数据时, 都会计算一次窗口大小, 并写入 ack 中.
④ : A 收到窗口大小为 0 的 ack 后, 就不再发送剩下的数据包了, 而是每隔一段时间发一个窗口探测报文, 如果探测到了窗口大小不为零, 则说明有空间了, 可以继续发送.
⑤ : B 腾出空间了, 将窗口大小写入 ack 中, 并索要接下来的数据.
应用程序从 socket 读数据, 就是在消费缓冲区里的数据, 读完就腾出空间了.
注意 : 上述过程是将返回的窗口大小作为实际窗口大小, 实践中可能会有出入.
窗口大小 = 流量控制 + 拥塞控制
六. 拥塞控制
为啥说滑动窗口大小取决于流量控制和拥塞控制呢 ?
如果说流量控制衡量了接收方的接收能力, 那么拥塞控制就是衡量传输路径的数据处理能力.
两个主机间进行交互, 并不是直接点对点进行交互的, 而是通过很多中间节点来实现数据传输.
场景如下 :
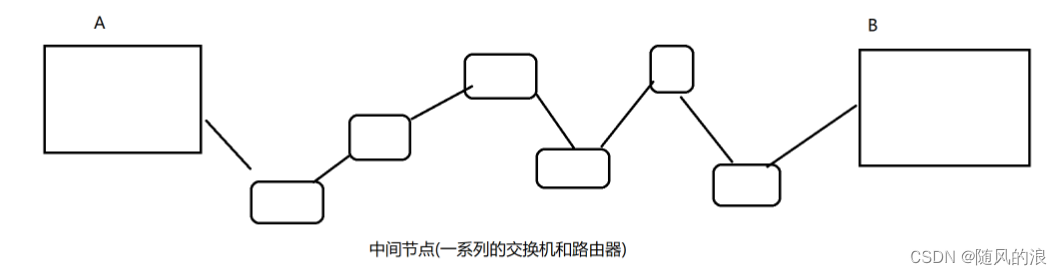
如果在数据传输过程中, 有一台设备处于瓶颈状态, 都会对整体传输数率产生明显影响.(短板效应)
拥塞控制就是衡量中间节点的传输能力, 它是通过实验的方式来找到一个合适的发送速率.
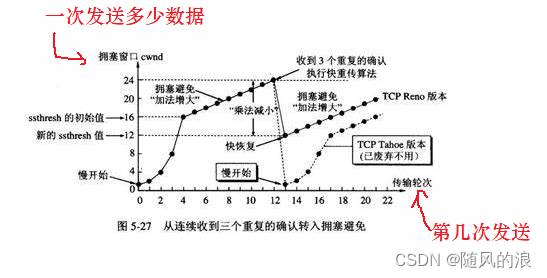
刚开始的时候, 按照一个小速率发送, 如果不丢包就提高速率(窗口大小), 如果出现丢包, 则把速率再调小.
可以看到在拥塞窗口达到一定值(阈值)之前, 是按指数级增长, 之后就是线性增长, 避免一下超出上限很多, 可以慢慢接近传输上限. 当增长到一定程度时, 出现丢包情况, 则认为已经达到当前路径的传输上限了. 这时就开始下一轮的测试, 但是这次的阈值比前一次小了, 以期望达到更准确的传输上限.
七. 延时应答
延时应答是为了提高 TCP 的传输效率.
延时应答是啥意思呢 ?
就是返回的 ack 不是立即发送, 而是等待一会儿, 再发送.
为啥延时应答可以提高传输效率呢 ?
我们知道 TCP 中决定传输效率的关键元素就是窗口大小.
窗口大小又取决于 流量控制及拥塞控制.
而流量控制的关键又是接收方的接收缓冲区的剩余空间大小, 延时应答就是通过这点来提高传输效率的. (当然不是扩大缓冲区)
具体原理如下 :

当接收方接收到一个数据时, 就会返回一个 ack, 这个 ack 中就包含了窗口大小, 假设为 n.
同时应用程序也在消费缓冲区的数据, 也就是说缓冲区的大小在时刻变化, 这个时候如果稍等片刻再返回 ack, 此时 ack 中的窗口大小大概率比 n 大.
(数据交互都要进行封装和分用, 此时减少发送频率还提高了窗口大小, 无疑提高了传输效率)
总结 :
延时应答就是通过延时发送 ack, 来让应用程序多消费点数据, 达到增大窗口的效果, 此时就发送方的发送效率就得到提高.(同时也满足让接收方处理的过来)
八. 捎带应答
捎带应答是基于延时应答来实现的.
客户端服务器间的通信模型通常是 “一问一答” 的.
客户端服务器间的通信模型:
- 一问一答 : 绝大部分服务器都采用这种方式.
- 多问一答 : 上传文件.
- 一问多答 : 下载文件.
- 多问多答 : 游戏串流.
像前面学的 TCP 四次挥手 : (链接 : 三次握手及四次挥手)

服务器收到客户端发出的断开请求 fin 后, 由系统内核立即返回一个 ack, 然后服务器执行到 close 方法也发送一个 fin.
服务器发送的 ack 及 fin 本来时机是不同的, 但由于延时应答, 此时 ack 就可能和 fin 合成一个数据报, 提高了传输效率. (数据交互都是要进行封装和分用的, 减少交互次数就可以提高效率)
九. 面向字节流
面向字节流可以让我们读写数据时依据需求来读写.
比如 :
写100个字节数据时,可以调用一次write写100个字节,也可以调用100次write,每次写一个字节;
读100个字节数据时,也完全不需要考虑写的时候是怎么写的,既可以一次read 100个字节,也可以一次read一个字节,重复100次;
这也随之引来一个问题 ----“粘包问题”.
什么是粘包问题呢 ?
假设以下场景 :

主机A 与 主机B对话, 其中它们的缓冲区如下 :

站在传输层的角度来看, TCP 是一个报文一个报文发送过来的, 按照序号排好序放在缓冲区的.
但在应用层角度来看, 缓冲区中只是一串连续的字符, 没有规律.
回到上图, 如果仅看缓冲区, 我们是否可以分出一句话呢 ?
以 B 的缓冲区来看, 可以明显看出每句话都以 “兄弟” 开头, 也就不难分辨每一句话了.
但 A 的缓冲区不同, 它是毫无规律的, 我们区分不出来一句话哪里到哪里.
这就是 “粘包问题”.
简单来说, 粘包问题就是 当 A 给 B 发送多个应用层数据报后, 这些数据都在 B 的缓冲区中排好序, 紧紧挨着, 此时 B 的应用程序在读数据的时候, 就难区分从哪里到哪里是一个完整的应用层数据报, 就很容易读错(读出半个包 / 一个半包…)
如何解决粘包问题呢 ?
对于定长的包,保证每次都按固定大小读取即可;
对于变长的包,可以在包头的位置,约定一个包总长度的字段,从而就知道了包的结束位置;
对于变长的包,还可以在包和包之间使用明确的分隔符(应用层协议,是程序猿自己来定的,只要保证分隔符不和正文冲突即可);
通常我们是自定义分隔符来解决问题.
ps : 那 UDP 协议会有这种问题吗 ?
对于UDP,数据进入缓冲区后,UDP的报文长度仍然在。同时,UDP是一个一个把数据交给应用层的。就有很明确的数据边界。
站在应用层的角度,使用UDP的时候,要么收到完整的UDP报文,要么不收, 不会出现 “半个” 的情况。
十. 异常处理
这里异常分四种情况 :
- 进程关闭 / 进程崩溃
- 主机关机 (正常流程关机)
- 主机掉电 (直接拔电源, 不考虑笔记本)
- 网线断开
1.进程关闭 / 进程崩溃
虽然进程没了, 但 socket 是文件, 进程结束会释放资源描述符, 仍然可以进行四次挥手.
2.主机关机
会先杀死所有的用户进程, 然后关机.
杀死进程就会触发四次挥手, 可能它还没挥完手就关机了, 比如 :
我这边发送 fin, 对方回了个 ack, 这时我电脑已经关了, 我收不到 ack 了, 对方发完 ack 后, 又发了 fin, 结果发现我这边没响应, 此时对端就会重传 fin, 重传几次发现都没有 ack, 那它就会重置连接, 如果还不行, 就会释放连接.
3.主机掉电
瞬间主机就关机了, 来不及进行任何挥手操作.
这又分两种情况 :
- 对端是发送方
对端发送数据报后接收不到 ack, 就会超时重传, 再收不到就会重置链接, 还不行就释放连接.
- 对端是接收方
对端是接收方就无法立即知道, 我这边是没来的及发还是已经没了.
其实 TCP 内置了 “心跳包” 保活机制, 它是周期性的, 如果没了就是挂了.
虽然对端是接收方, 但是对端也会定期发送一个心跳包(ping), 我这边也会返回一个(pong).
如果每个 ping 发出后都得到了 pong 那没问题, 但如果多个 ping 发出去都得不到一个 pong, 那对方多半是挂了. 那就释放连接了.
4.网络断开
其实这和第三点一样.
两个主机进行通信就是基于网络, 如果网络都没了, 那和挂了没区别.
总结
TCP 的传输效率是远不及 UDP 的, 正是因为 TCP 要保证传输的可靠性, 所以牺牲了效率, 但是 TCP 又以滑动窗口, 流量控制, 拥塞控制, 延时应答, 捎带应答等等特性, 来尽可能提高效率. (尽可能减少可靠性带来的效率损失)


![[论文翻译]Deep learning](https://img-blog.csdnimg.cn/20200802130116956.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RpYW9rdWkyMzEy,size_16,color_FFFFFF,t_70)
![[论文翻译] Deep Learning](https://img-blog.csdnimg.cn/20200811114635497.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RpYW9rdWkyMzEy,size_16,color_FFFFFF,t_70#pic_center)