CS224N WINTER 2022(一)词向量(附Assignment1答案)
CS224N WINTER 2022(二)反向传播、神经网络、依存分析(附Assignment2答案)
CS224N WINTER 2022(三)RNN、语言模型、梯度消失与梯度爆炸(附Assignment3答案)
CS224N WINTER 2022(四)机器翻译、注意力机制、subword模型(附Assignment4答案)
CS224N WINTER 2022(五)Transformers详解(附Assignment5答案)
序言
-
CS224N WINTER 2022课件可从https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1224/下载,也可从下面网盘中获取:
https://pan.baidu.com/s/1LDD1H3X3RS5wYuhpIeJOkA 提取码: hpu3本系列博客每个小节的开头也会提供该小结对应课件的下载链接。
-
课件、作业答案、学习笔记(Updating):GitHub@cs224n-winter-2022
-
关于本系列博客内容的说明:
-
笔者根据自己的情况记录较为有用的知识点,并加以少量见解或拓展延申,并非slide内容的完整笔注;
-
CS224N WINTER 2022共计五次作业,笔者提供自己完成的参考答案,不担保其正确性;
-
由于CSDN限制博客字数,笔者无法将完整内容发表于一篇博客内,只能分篇发布,可从我的GitHub Repository中获取完整笔记,本系列其他分篇博客发布于(Updating):
CS224N WINTER 2022(一)词向量(附Assignment1答案)
CS224N WINTER 2022(二)反向传播、神经网络、依存分析(附Assignment2答案)
CS224N WINTER 2022(三)RNN、语言模型、梯度消失与梯度爆炸(附Assignment3答案)
CS224N WINTER 2022(四)机器翻译、注意力机制、subword模型(附Assignment4答案)
CS224N WINTER 2022(五)Transformers详解(附Assignment5答案)
-
文章目录
- 序言
- lecture 7 机器翻译,注意力机制,subword模型
- slides
- notes
- suggested readings
- assignment4 参考答案
- 1. Neural Machine Translation with RNNs
- 2. Analyzing NMT Systems
- lecture 8 期末项目
- slides
- tips
- suggested readings
- projects
lecture 7 机器翻译,注意力机制,subword模型
slides
[slides]
-
机器翻译:slides p.4
-
统计机器翻译(SMT,1990s-2010s):slides p.7
核心观点是从数据中学习得到一个概率模型。
比如我们想要将中文翻译成英文,给定中文句子 x x x,目标是找到最好的英文句子 y y y作为译文:
argmax y P ( y ∣ x ) = argmax y P ( x ∣ y ) P ( y ) (7.1) \text{argmax}_yP(y|x)=\text{argmax}_yP(x|y)P(y)\tag{7.1} argmaxyP(y∣x)=argmaxyP(x∣y)P(y)(7.1)
式 ( 7.1 ) (7.1) (7.1)成立的原因是 P ( x ) P(x) P(x)是一个已知的常数(从中文语料库中利用语言模型计算得到),然后利用贝叶斯法则容易推得。我们可以这样解释式 ( 7.1 ) (7.1) (7.1)右侧的两项:
① P ( y ) P(y) P(y)是一个语言模型,用以使得翻译得到的英文语句尽可能地通顺流畅;
② P ( x ∣ y ) P(x|y) P(x∣y)是一个翻译模型,用以使得翻译得到的英文语句尽可能匹配中文语句;
式 ( 7.1 ) (7.1) (7.1)的建模难点显然在于如何构建翻译模型 P ( x ∣ y ) P(x|y) P(x∣y),这通常需要一系列的平行语料(parallel data),即人工编纂的中英互译样本对。
然后引入一个对齐向量(alignment) a a a,用以指示平行语料之间单词级别的对应关系(如中文中的明天对应英文中的Tommorrow),这是一个隐变量(latent variables),即并没有在数据中被直接指示出来,仅仅是我们为了更好的建模引入的假想变量,需要一些特殊的学习算法(如EM算法)来学习得到隐变量的参数分布,翻译模型由此改进为 P ( x , a ∣ y ) P(x,a|y) P(x,a∣y)。
但是语言之间的语义对应关系可能并不总是那么简单,不同的语言拓扑结构可能导致复杂的对应关系(多对一,一对多),甚至某些单词根本不存在对应词。这里推荐一篇比较古老的讲SMT中参数估计的paper(1994年发表于Computational Linguistics)。
式 ( 7.1 ) (7.1) (7.1)还有一个难点在于如何计算 argmax \text{argmax} argmax,难道需要遍历所有的英文语句 y y y吗?这显然非常的不经济,通常的做法是在模型中强加条件独立性假设(impose strong independence assumption),然后利用动态规划算法(如Viterbi算法)来求解全局最优解,这个求解最优 y y y的过程称为解码(decoding)。
关于强加条件独立性假设这个做法,类比可以联想到概率论以及随机模型中大多假定样本独立同分布,或者参数之间具有独立性等等,不过这在SMT中究竟是指什么的确令人费解。于是笔者在上面那篇老古董paper里找到了independence assumption的说明(p. 40-42),具体如下:
一般性的公式是这样的:
P θ ( x , a ∣ y ) = P θ ( m ∣ y ) P θ ( x ∣ m , y ) P θ ( x ∣ a , m , y ) (7.2) P_\theta(x,a|y)=P_\theta(m|y)P_\theta(x|m, y)P_\theta(x|a,m,y)\tag{7.2} Pθ(x,a∣y)=Pθ(m∣y)Pθ(x∣m,y)Pθ(x∣a,m,y)(7.2)
然后我们定义 ϵ ( m ∣ l ) \epsilon(m|l) ϵ(m∣l)是语句长度的分布概率, t ( x ∣ y ) t(x|y) t(x∣y)是翻译概率;其中 θ \theta θ是模型参数, a a a即为对齐向量, m m m是中文语句 x x x的长度, l l l是英文语句 y y y的长度,那么条件独立性假设如下所示:
P θ ( m ∣ y ) = ϵ ( m ∣ l ) P θ ( a ∣ m , y ) = ( l + 1 ) − m P θ ( x ∣ a , m , y ) = ∏ j = 1 m t ( x j ∣ y a j ) (7.3) P_\theta(m|y)=\epsilon(m|l)\\ P_\theta(a|m,y)=(l+1)^{-m}\\ P_\theta(x|a,m,y)=\prod_{j=1}^m t(x_j|y_{a_j})\tag{7.3} Pθ(m∣y)=ϵ(m∣l)Pθ(a∣m,y)=(l+1)−mPθ(x∣a,m,y)=j=1∏mt(xj∣yaj)(7.3)
其中 a j a_j aj即中文语句 x x x的第 j j j个位置对应的英文语句 y y y的下标,这样转换的好处是引入了语句长度这个变量,我们就可以逐字翻译,具体而言在slides p.16中给出的SMT解码示例中,对每一个中文词生成候选的对应英文单词,然后进行一个全局性的搜索(包括位置对应,选取哪个候选词等等),这就可以使用动态规划来求解了。 -
神经机器翻译(NMT,2014):slides p.18
直接将机器翻译问题转化为seq2seq建模,常见可以用seq2seq建模的机器学习任务有:文本综述,对话系统,文本解析,代码生成。这涉及两个RNN网络层,一个是编码器(encoder),另一个是解码器(decoder):
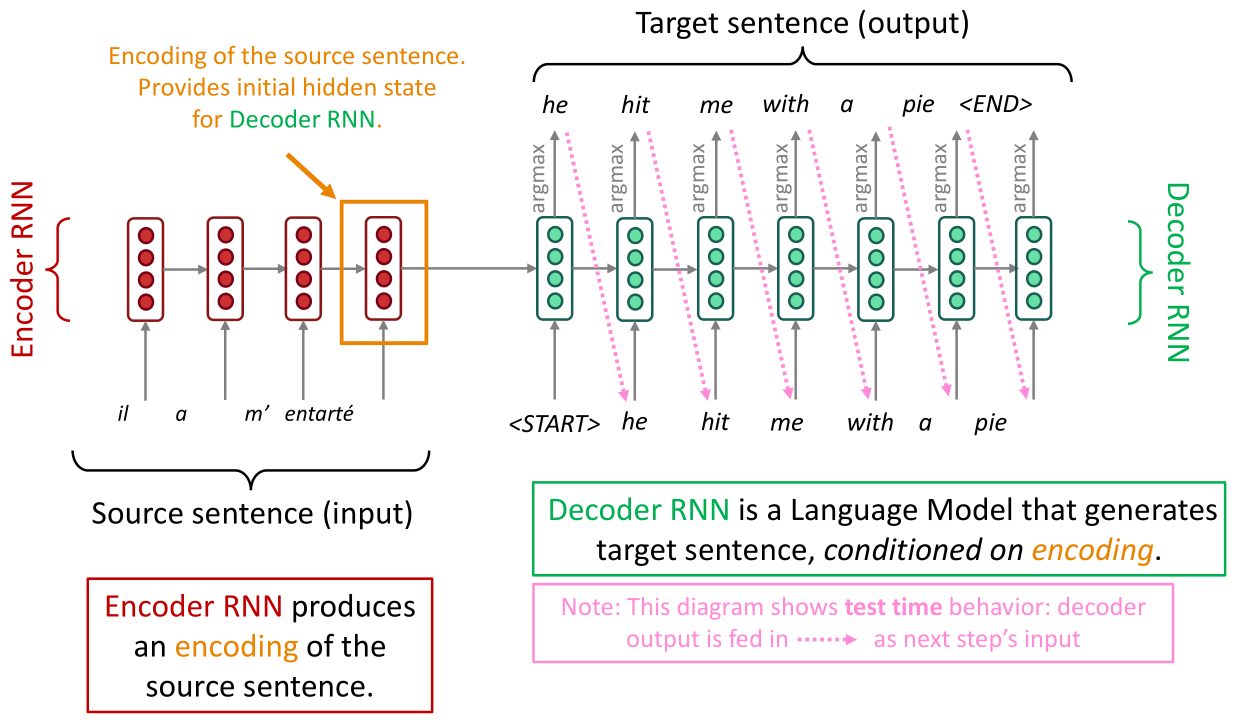
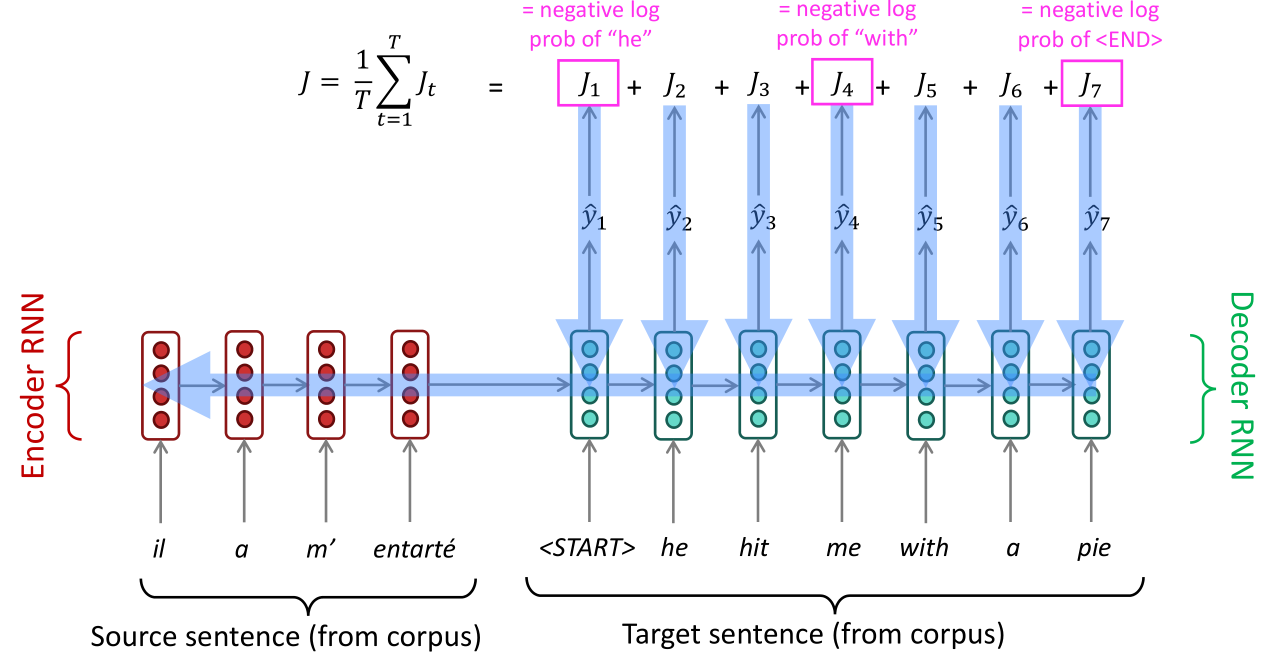
seq2seq模型是条件语言模型(Conditional Language Model)的一种范例,类似式 ( 7.1 ) (7.1) (7.1)中的标记,NMT直接计算 P ( y ∣ x ) P(y|x) P(y∣x)的值:
P ( y ∣ x ) = P ( y 1 ∣ x ) P ( y 2 ∣ y 1 , x ) P ( y 3 ∣ y 1 , y 2 , x ) . . . P ( y T ∣ y 1 , . . . , y T − 1 , x ) (7.4) P(y|x)=P(y_1|x)P(y_2|y_1,x)P(y_3|y_1,y_2,x)...P(y_T|y_1,...,y_{T-1},x)\tag{7.4} P(y∣x)=P(y1∣x)P(y2∣y1,x)P(y3∣y1,y2,x)...P(yT∣y1,...,yT−1,x)(7.4)
这时候我们再次审阅上图,注意右边的解码器是逐字进行解码(翻译)的,这就是式 ( 7.4 ) (7.4) (7.4)的思想,首先翻译第一个单词,然后给定第一个单词翻译第二个单词,依此类推。如何训练seq2seq模型:
上图是单层的encoder-decoder架构,也可以改进为多层的形式,这个可能与直观上的多层有一些区别,并非encoder的最后一层输出接到decoder的第一层输入上,而是encoder每一层都会与decoder的对应层相连接,具体如下图所示:
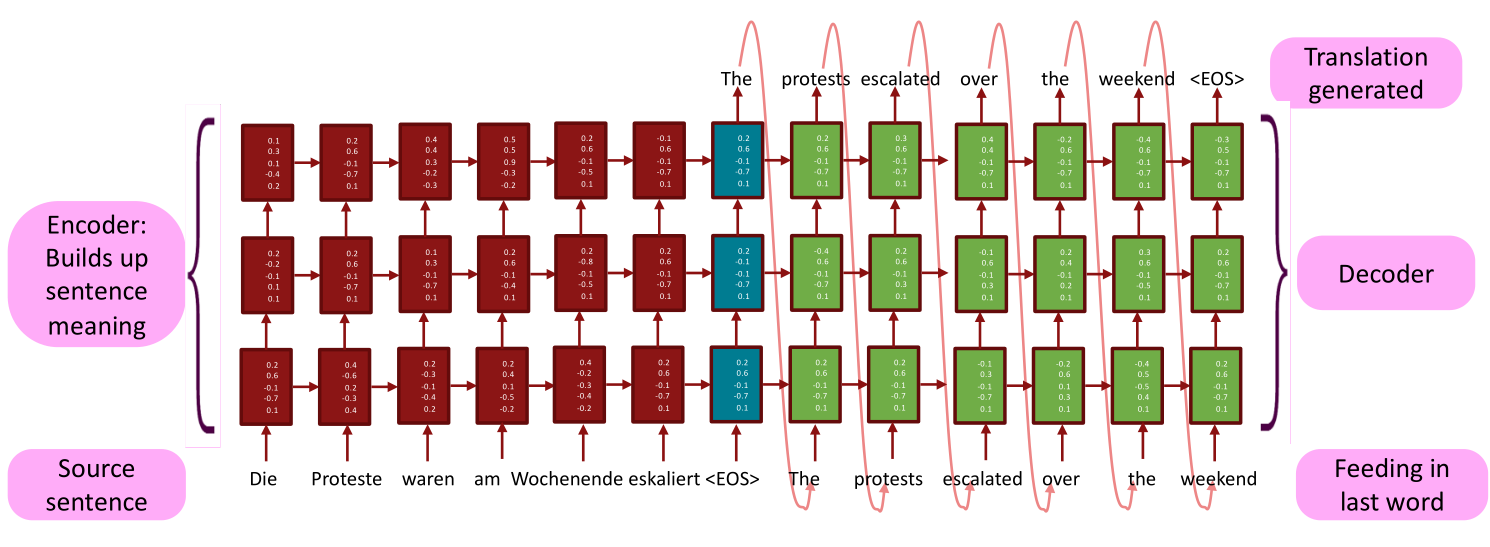
接下来要说的是NMT中非常关键的问题:式 ( 7.4 ) (7.4) (7.4)到底如何求解(解码)?
正如上文所述,解码器是逐字解码的,那么根据语言模型的思想,很容易想到一种贪心解码(greedy decoding)的方式,在式 ( 7.4 ) (7.4) (7.4)中,我们每次解码得到概率值最大的 y i y_i yi,即首先根据 P ( y 1 ∣ x ) P(y_1|x) P(y1∣x)的取值搜索到最优的 y 1 y_1 y1,然后根据 P ( y 2 ∣ y 1 , x ) P(y_2|y_1,x) P(y2∣y1,x)的取值搜索到最优的 y 2 y_2 y2,依此类推。
显然这种贪心的方法未必能得到全局最优,但如果全局搜索则时间复杂度为 O ( ∣ V ∣ T ) O(|V|^T) O(∣V∣T),即遍历所有的 { y 1 , . . . , y T } \{y_1,...,y_T\} {y1,...,yT}的取值组合,或许可以使用动态规划的方法进行优化,但是这里提出的是一种经典的束搜索(beam search)策略。
束搜索(slides p.32-44有动画演示 )的核心思想是在每一步解码时,不同于贪心解码仅仅找到一个最优的解,而是找到前 k k k个最优的解作为候选(NMT中一般取5~10),然后一步步迭代下去,如果只是这样(稍微改进一些贪心算法),那么复杂度显然为 O ( k T ) O(k^T) O(kT),实际上束搜索还会考虑剪枝,具体而言,当分支数达到 k 2 k^2 k2时,只保留 k k k个最好的分支,然后接着进行后续的分支搜索。
束搜索不保证找到最优解,但相对于贪心算法更可能找到最优解。
-
统计机器翻译与神经机器翻译的对比:slides p.47
NMT相对于SMT最大的优势是可以生成更流畅的译文,此外NMT更好的利用了上下文信息以及短语的相似性。此外NMT相对来说人力成本更低,因为无需进行特征工程。NMT的劣势在于可解释性差,而且难以引入规则进行翻译控制。
-
机器翻译模型的评估指标(BLEU):slides p.49
BLUE不仅是机器翻译模型的指标,它是大多数seq2seq模型的评估指标之一,assignment4中会有BLEU的逻辑,它核心思想是比较预测序列与标准序列之间的相似性(基于n-gram短语)。
BLEU并非总是有效,因为如果翻译结果与标准翻译之间在n-gram短语上的重合度太低,评价就会很差,但是翻译这个事情本身就没有一个绝对标准的答案。
-
机器翻译的疑难:出现词汇表外的单词、迁移性(用中英互译的数据训练,但是需要在中法互译的测试集上评估)、低资源训练(训练数据很少)、代词零冠词辨别错误、形态一致性(morphological agreement)错误、常识与俚语。
但是尽管如此,NMT应该算是深度学习历史上取得的最大成功之一,因为自2014年出现后基本上彻底取代SMT。
-
-
注意力机制:slides p.59
回顾上文提到seq2seq模型的解码器是逐字解码的,问题在于它每次解码都将用到源语句的所有信息,事实上从人类翻译的角度来看中译英,每翻译一个英文单词,只需要关注中文语句中的一小块区域(这其实有点类似alignment的思想),在模型中即在解码器的每一步迭代中,使用一种方式直接连接到编码器(use direct connection to the encoder),这就是注意力机制。(slides p.63-74有动画演示)
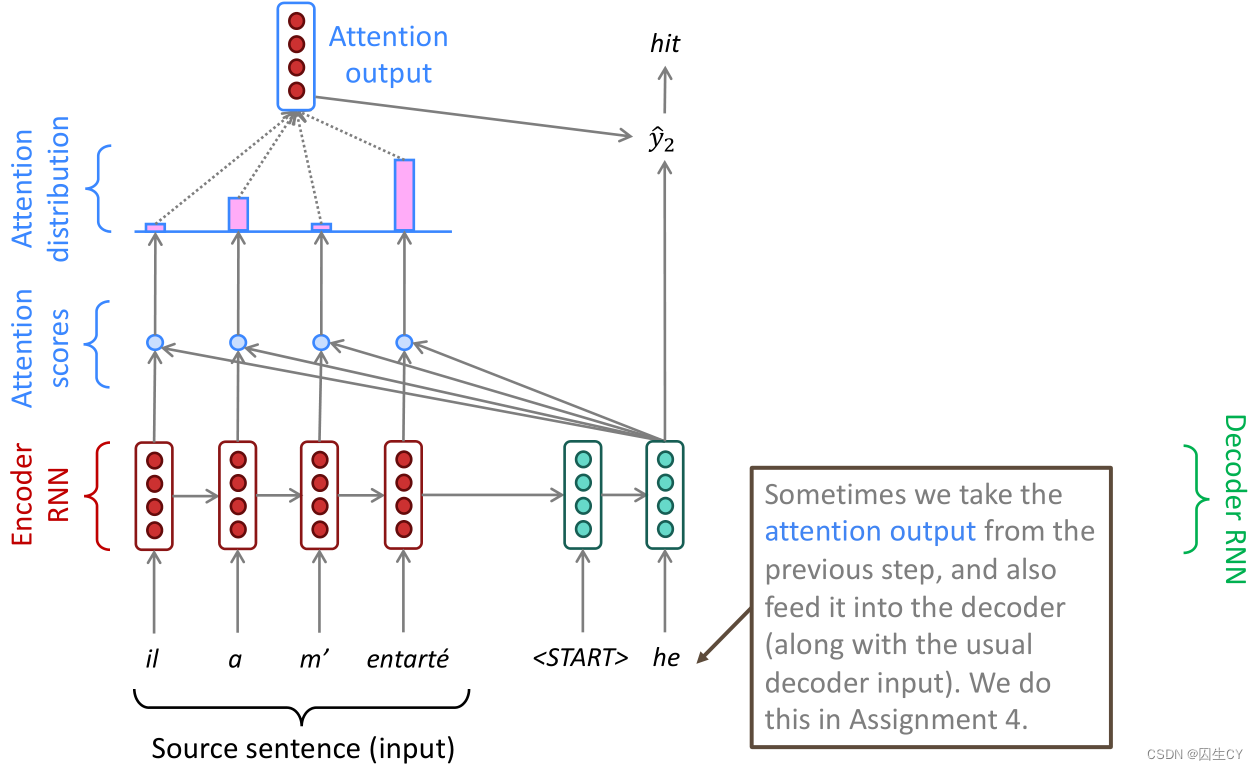
如上图所示,当我们要开始翻译he的下一个单词时,我们计算he与源语句中每个输入单词的相似度(一般使用点积)得到注意力得分(Attention scores),得分越高给予的注意力权重也就越高,根据注意的输出结果预测得到 y ^ 2 \hat y_2 y^2,解码得到下一个单词(hit)。
具体而言,我们使用数学表达式描述整个流程:
-
已知编码器的隐层状态 h i ∈ R h , i = 1 , . . . , N h_i\in\R^h,i=1,...,N hi∈Rh,i=1,...,N
-
在第 t t t步,我们获取到解码器的隐层状态 s t ∈ R h s_t\in\R^h st∈Rh,可以计算得到注意力得分 e t e^t et(使用点积):
e t = [ s t ⊤ h 1 , . . . , s t ⊤ h N ] ∈ R N (7.5) e^t=[s_t^\top h_1,...,s_t^\top h_N]\in\R^N\tag{7.5} et=[st⊤h1,...,st⊤hN]∈RN(7.5) -
根据 ( 7.5 ) (7.5) (7.5)的得分值,使用softmax计算得分值的概率分布:
α t = softmax ( e t ) ∈ R N (7.6) \alpha^t=\text{softmax}(e^t)\in\R^N\tag{7.6} αt=softmax(et)∈RN(7.6) -
根据 ( 7.6 ) (7.6) (7.6)的概率分布,对编码其隐层状态进行加权得到注意力输出:
a t = ∑ i = 1 N α i t h i ∈ R h (7.7) a_t=\sum_{i=1}^N\alpha_i^th_i\in\R^h\tag{7.7} at=i=1∑Nαithi∈Rh(7.7) -
最后将注意力输出 a t a_t at与解码器隐层状态 s t s_t st拼接得到带注意力的解码器隐层状态 [ a t ; s t ] ∈ R 2 h [a_t;s_t]\in\R^{2h} [at;st]∈R2h
综上所述,注意力机制不仅有效提升NMT模型的效果,而且还缓解了梯度消失的问题(因为可以有效联系长距离的记忆),此外注意力权重一定程度上是具有可解释性的。
可能有人会觉得式 ( 7.5 ) (7.5) (7.5)中计算注意力得分的方式(点积注意力)太肤浅,凭什么说两种不同语言单词之间的相似度可以用以刻画注意力得分。笔者认为在这种假定下,编码器和解码器都要尽可能地将两种语言编码成具有一定共源性的隐层状态,即尽可能地将两种语言编码地要像一种语言。不过的确式 ( 7.5 ) (7.5) (7.5)是有很多变体的(点积注意力要求两个隐层状态的维度是相等的,否则无法求点积,这种要求略显无理),具体如下:
-
乘法注意力(multiplicative attention): e i = s ⊤ W h i e_i=s^\top Wh_i ei=s⊤Whi,其中 W ∈ R d 2 × d 1 W\in\R^{d_2\times d_1} W∈Rd2×d1是权重矩阵,这似乎可以称为双线性注意力。(Effective Approaches to Attention-based Neural Machine Translation)
-
降秩乘法注意力(reduced multiplicative attention): e i = s ⊤ ( U ⊤ V ) h i = ( U s ) ⊤ ( V h i ) e_i=s^\top(U^\top V)h_i=(Us)^\top(Vh_i) ei=s⊤(U⊤V)hi=(Us)⊤(Vhi),其中 U ∈ R k × d 2 , V ∈ R k × d 1 , k ≪ d 1 , d 2 U\in\R^{k\times d_2},V\in\R^{k\times d_1},k\ll d_1,d_2 U∈Rk×d2,V∈Rk×d1,k≪d1,d2,其实就是把 s s s和 h i h_i hi做一次线性变换后再计算相似性,只不过这里的线性变换是低秩变换,应该是用于隐层状态维度很大的情况,否则还不一定有点积注意力好使。
-
加法注意力(additive attention): e i = v ⊤ tanh ( W 1 h i + W 2 s ) ∈ R e_i=v^\top\tanh(W_1h_i+W_2s)\in\R ei=v⊤tanh(W1hi+W2s)∈R,这个是本讲下面推荐阅读部分的第六篇首次提出。(Neural Machine Translation by Jointly Learning to Align and Translate)。
其中 W 1 ∈ R d 3 × d 1 , W 2 ∈ R d 3 × d 2 , v ∈ R d 3 W_1\in\R^{d_3\times d_1},W_2\in\R^{d_3\times d_2},v\in\R^{d_3} W1∈Rd3×d1,W2∈Rd3×d2,v∈Rd3, d 3 d_3 d3称为注意力维度,是模型的超参数。
本质上这种注意力是用全连接层接一个激活函数来实现的。
-
-
注意力机制的拓展内容:slides p.80
注意力机制的更广义的一个定义:
- 给定一系列值向量(values),给定一系列查询向量(query),注意力机制是基于查询向量来计算得到值向量的一个加权和。
这种定义在Transformer的多头注意力机制中将会详细描述。
notes
[notes]
-
记录一下seq2seq中解码器的数学表达式(slides部分只有图,没有给数学表达式):notes p.5-6
s i = f ( s i − 1 , y i − 1 , c i ) e i , j = a ( s i − 1 , h j ) α i , j = exp ( e i , j ) ∑ k = 1 n exp ( e i , j ) c i = ∑ j = 1 n α i , j h j (7.8) \begin{aligned} s_i&=f(s_{i-1},y_{i-1},c_i)\\ e_{i,j}&=a(s_{i-1},h_{j})\\ \alpha_{i,j}&=\frac{\exp(e_{i,j})}{\sum_{k=1}^n\exp(e_{i,j})}\\ c_i&=\sum_{j=1}^n\alpha_{i,j}h_j \end{aligned}\tag{7.8} siei,jαi,jci=f(si−1,yi−1,ci)=a(si−1,hj)=∑k=1nexp(ei,j)exp(ei,j)=j=1∑nαi,jhj(7.8)
其中 s i − 1 s_{i-1} si−1是编码器中之前的隐层状态, y i − 1 y_{i-1} yi−1是前一步生成的单词, c i c_i ci是上下文向量, a a a是映射到实数轴上的任意函数, h j h_j hj是解码器的隐层状态。 -
其他的NMT模型的学术工作:notes p.6-8
-
Effective Approaches to Attention-based Neural Machine Translation:
使用的注意力得分计算方式为下面三种之一:
score ( s , h i ) = { s ⊤ h i s ⊤ W h i W [ s , h i ] ∈ R (7.9) \text{score}(s,h_i)=\left\{\begin{aligned} &s^\top h_i\\ &s^\top Wh_i\\ &W[s,h_i] \end{aligned}\right.\in\R\tag{7.9} score(s,hi)=⎩⎪⎨⎪⎧s⊤his⊤WhiW[s,hi]∈R(7.9)
前两个都是slides部分提到的点积注意力和乘法注意力,最后一个有点奇怪, W W W如果是一个矩阵那么计算结果应该是一个向量才对,看了一下原paper其实就是additive attention,notes中写错了。 -
Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation:
提出的是一种模型架构,可以用于任意两种语言之间的机器翻译训练,模型的输入是源语言语句和目标语言的编号,输出为目标语言的译文。文中宣称可以进行零射翻译(即两种语言之间不存在平行语料供以训练,这应该是依赖迁移学习)
-
另外的一些工作概述:
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention:图片转文字的注意力机制,很有趣的工作。
- Modeling Coverage for Neural Machine Translation:注意力机制的改进。
- Incorporating Structural Alignment Biases into an Attentional Neural Translation Model:注意力机制的改进,引入更多的考察因子,如positional bias, Markov conditioning, fertility and agreement over translation directions.
-
-
BLEU评价指标:notes p.11
slides中关于BLEU的内容比较少,只是提及使用n-gram短语的相似度生成指标。但是assignment4中是需要实现BLEU的。
具体而言,设 k k k为我们想要考察的最长的n-gram短语,比如 k = 4 k=4 k=4时,BLEU得分只统计长度不超过4的短语,于是有 p n p_n pn表示长度为 n n n的n-gram短语的精确度得分:
p n = # match n-grams # n-grams in candidate translation (7.10) p_n=\frac{\#\text{match n-grams}}{\#\text{n-grams in candidate translation}}\tag{7.10} pn=#n-grams in candidate translation#match n-grams(7.10)
最后令 w n = 1 / 2 n w_n=1/2^n wn=1/2n表示 p n p_n pn几何权重,再定义惩罚项(brevity penalty):
β = e min ( 0 , 1 − l e n r e f l e n M T ) (7.11) \beta=e^{\min\left(0,1-\frac{\rm len_{ref}}{\rm len_{MT}}\right)}\tag{7.11} β=emin(0,1−lenMTlenref)(7.11)
其中 l e n r e f \rm len_{ref} lenref是标准翻译语句的长度, l e n M T \rm len_{MT} lenMT是模型输出的翻译语句的长度,于是:
BLEU = β ∏ n = 1 k p n w n (7.12) \text{BLEU}=\beta\prod_{n=1}^kp_n^{w_n}\tag{7.12} BLEU=βn=1∏kpnwn(7.12) -
**如何处理巨大的softmax输出?**notes p.13
解码器输出的是单词的概率分布,比如英文一般有30000到40000个单词,那么输出的概率分布维度就有三万多,这是非常夸张的softmax输出,而且这样的概率分布往往很不精准,因此需要一些技术性操作:
-
噪声对比估计(Noise Contrastive Estimation,NCE):这在Word2Vec中也提到了(但是没有细说),即从负样本中随机采样 k k k个单词,从而使得输出维度变为 ∣ V ∣ / k |V|/k ∣V∣/k,其思想是:
将真实样本和噪声样本进行对比,并从中找寻真实样本的规律,即「利用比较学习」将概率生成问题转化为二分类问题,换言之,就是将真实样本与从简单分布随机采样的错误样本进行对比,并试图找出真实样本与错误样本的差异。
一般取 k = 1 k=1 k=1,即划归为二分类问题,具体而言:
- 从经验分布 P ~ ( c ) \tilde P(c) P~(c)中抽样上下文 c c c
- 从经验分布 P ~ ( w ∣ c ) \tilde P(w|c) P~(w∣c)中抽样一个样本作为正样本,标签 Y = 1 Y=1 Y=1
- 从噪声分布 P n ( w ∣ c ) P_n(w|c) Pn(w∣c)中抽样 k k k个样本作为负样本,标签 Y = 0 Y=0 Y=0
- 通过逻辑回归来区分两个分布。
于是我们只需要将预测的概率分布转化为预测属于上述 k + 1 k+1 k+1类的哪一类即可。
-
分层softmax(首次提出):这个也是在Word2Vec中提到的,就是执行若干次二分类来处理多分类问题。
-
词汇表降维:
第一种是直观的引入
<unk>标记,但是这样可能会预测输出很多<unk>标记,不过笔者觉得可以利用语言模型进行后处理,填补掉这些<unk>。但是我看到的常见做法是直接从源语句中把对应的单词直接照抄过来,这似乎是一种解法,但是在Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation中有一句话值得留意:This approach is both unreliable at scale — the attention mechanism is unstable when the network is deep — and copying may not always be the best strategy for rare words — sometimes transliteration is more appropriate.
这种方法在规模上是不可靠的——当网络很深时,注意力机制是不稳定的——而且抄袭可能并不总是稀有单词的最佳策略——有时音译更合适
另一种就很强大了,直接用字符级别的表示(即预测输出的字母,这样输出维数就小太多了),推荐一篇专门讲这种方法的paper。
还有的做法是讲词汇表进行子集划分,目标预测在哪个子集中,这个做法可以追溯到这篇paper。
-
-
subword模型:notes p.15
使用字母级别的序列输入输出是否可行?
一定程度上这或许是可行的,当然这并非都是字母,可以是子单词(subword)级别的,比如英文中有很多前缀后缀(est,er,pre),这些前后缀都是有意义的,可用于单词的派生,即便是中文也有偏旁、部首的概念,其实可能都是可以作为特征来进行编码的。但是笔者感觉可能这样的数据集会比较难找,因为主流的都是用单词级别的序列进行建模的。
推荐阅读的最后两篇都是关于字符级别编码的,有兴趣可以进行查阅。
-
混合机器翻译:notes p.16
指兼用NMT与SMT,或是兼用字符编码与单词编码(推荐阅读第9篇)的方法进行机器翻译的建模。
suggested readings
-
2015年的CS225N课程统计机器翻译的slides,感觉没有什么特别的地方。(Statistical Machine Translation slides, CS224n 2015)
-
这是一本著作,链接是购买链接,未能找到免费资源。(Statistical Machine Translation)
-
机器翻译类型的学习任务经典评估指标BLEU的2002年首次提出的paper。(BLEU)
-
2014年的一篇使用神经网络求解seq2seq问题的paper,感觉比较普通。(Sequence to Sequence Learning with Neural Networks)
-
2012年上传于ARXIV,关于语音识别的seq2seq学习模型的paper。(Sequence Transduction with Recurrent Neural Networks)
-
2014年上传于ARXIV,在神经机器翻译中引入了对齐的概念(为什么不使用注意力机制呢?)。(Neural Machine Translation by Jointly Learning to Align and Translate)
好吧我刚注意到这是NMT的提出文,神经机器翻译就此问世,里面其实是有注意力机制以及各种变体的(如additive attention)。
-
注意力机制与增强RNN,这是一篇质量很高的博客,值得学习。(Attention and Augmented Recurrent Neural Networks)
-
2017年上传于ARXIV,英德翻译的机器翻译模型,提供了一个开源框架。(Massive Exploration of Neural Machine Translation Architectures)
-
2016年上传于ARXIV,英语翻译捷克语的paper,其中也有关于字符级别翻译的内容(混用字符编码与单词编码)。(Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models)
10. 2018年上传于ARXIV,这篇很有意思研究的是关于字符级别的机器翻译(即不是使用单词级别,而是组成单词的一个个字母来编码),这个就很偏离自然语言处理的主流,但是也是一种有趣的做法,以前有人问过我为什么一定要编码单词而非字母,我们通常会认为单词可以包含更多的语义特征,建立上下文联系,但是对于英文来说,可能字符级别的数据也是有意义的(如单词的派生之类的可以从字符级别的编码特征中学习得到)。(Revisiting Character-Based Neural Machine Translation with Capacity and Compression)
assignment4 参考答案
[code] [handout] [latex template] [Azure Guide] [Practical Guide to VMs]
Assignment4参考答案(written+coding):囚生CYのGitHub Repository
1. Neural Machine Translation with RNNs
代码实现的是一个解码器为 BiLSTM \text{BiLSTM} BiLSTM,解码器为 LSTM \text{LSTM} LSTM的 NMT \text{NMT} NMT模型,注意力机制用的是乘法注意力(作业式 ( 7 ) (7) (7)),源语言为小语种切罗基语(虽然这个语言在谷歌翻译中没有,不过在百度翻译里是有的,所以下面的一些问题是可以作弊的)。
关于模型结构 BiLSTM \text{BiLSTM} BiLSTM,下面这张摘自作业中的图已经写得很明白了:
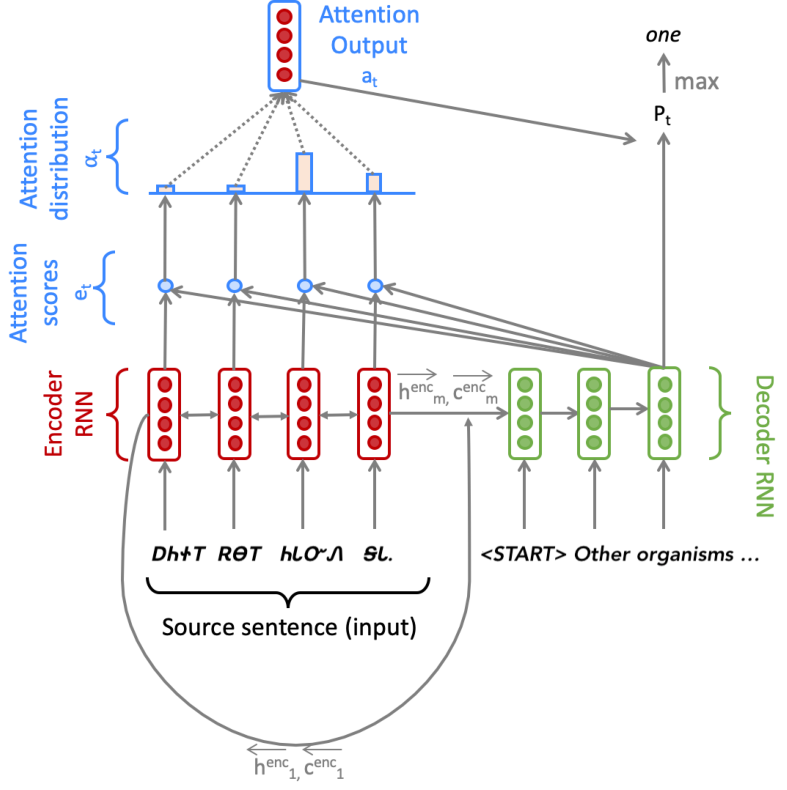
具体的数学公式笔者觉得跟双向 RNN \text{RNN} RNN区别不大,自己看一下吧,反正代码里也不用实现,直接调用接口就行了。
-
( a ) (a) (a) 序列填补,非常基础的工作;
max_length = max(list(map(len, sents)))sents_padded=[sent + [pad_token] * (max_length - len(sent)) for sent in sents] -
( b ) (b) (b) 初始化嵌入层,非常基础的工作,注意设置
torch.nn.Embedding的padding_idx参数;self.source = nn.Embedding(len(vocab.src), embed_size, padding_idx=src_pad_token_idx) # 切罗基语字符嵌入层self.target = nn.Embedding(len(vocab.tgt), embed_size, padding_idx=tgt_pad_token_idx) # 英语单词嵌入曾 -
( c ) (c) (c) 初始化机器翻译模型的所有网络层,提示中都说明了每个变量对应作业文件里的哪个数学标记,非常好写:
self.encoder = nn.LSTM(embed_size,hidden_size, bias=True, bidirectional=True)self.decoder = nn.LSTMCell(embed_size + hidden_size, hidden_size, bias=True)self.h_projection = nn.Linear(2 * hidden_size, hidden_size, bias=False) # 双向LSTM得到双倍的隐层状态拼接后与W_h相乘, 形状是h×2hself.c_projection = nn.Linear(2 * hidden_size, hidden_size, bias=False) # 双向LSTM得到双倍的记忆元胞拼接后与W_c相乘, 形状是h×2hself.att_projection = nn.Linear(2 * hidden_size, hidden_size, bias=False) # W_attProj形状是2h×hself.combined_output_projection = nn.Linear(3 * hidden_size, hidden_size, bias=False) # W_u形状是h×3hself.target_vocab_projection = nn.Linear(hidden_size, len(vocab.tgt), bias=False) # W_vocab形状是V_t×hself.dropout = nn.Dropout(p=dropout_rate) -
( d ) (d) (d) 按照代码里的提示一步步走,通过测试:
python sanity_check.py 1dX = self.model_embeddings.source(source_padded) # (seqlen, batchsize, embsize)X = pack_padded_sequence(X, source_lengths)enc_hiddens, (last_hidden, last_cell) = self.encoder(X) # last_hidden / last_cell : (2, batchsize, hiddensize)enc_hiddens = pad_packed_sequence(enc_hiddens)[0] # (seqlen, batchsize, embsize)enc_hiddens = enc_hiddens.permute(1, 0, 2) # (batchsize, seqlen, embsize)init_decoder_hidden = self.h_projection(torch.cat((last_hidden[0], last_hidden[1]), dim=1)) # (batchsize, 2 * hiddensize) -> (batchsize, hiddensize)init_decoder_cell = self.c_projection(torch.cat((last_cell[0], last_cell[1]), dim=1)) # (batchsize, 2 * hiddensize) -> (batchsize, hiddensize)注意需要下载
nltk_data的punkt分词器,建议提前离线下载好。 -
( e ) (e) (e) 通过测试:
python sanity_check.py 1eenc_hiddens_proj = self.att_projection(enc_hiddens) # (batchsize, seqlen, hiddensize)Y = self.model_embeddings.target(target_padded) # (tgtlen, batchsize, embsize)for Y_t in torch.split(Y, 1):Y_t = torch.squeeze(Y_t, dim=0) # (1, batchsize, embsize) -> (batchsize, embsize)Ybar_t = torch.cat((Y_t, o_prev), dim=1) # (batchsize, embsize + hiddensize)dec_state, o_t, e_t = self.step(Ybar_t, dec_state, enc_hiddens, enc_hiddens_proj, enc_masks)o_prev = o_tcombined_outputs.append(o_t)combined_outputs = torch.stack(combined_outputs, dim=0) # (tgtlen, batchsize, hiddensize) -
( f ) (f) (f) 这一问始终不能通过测试,但是我觉得应该是没有问题才对,不排除测试样例出错的可能性。
-
( g ) (g) (g) 这个应该说的是做 mask \text{mask} mask的用处,本质上在句子中抹去一些单词以达到屏蔽或选择特定元素的目的,这有点类似 dropout \text{dropout} dropout以及 ReLU \text{ReLU} ReLU激活函数的用处,可以防止模型过拟合。
还有一个就是更重要的点是 mask \text{mask} mask将
src_len之前的设为 1 1 1,之后的设为 0 0 0,因为在序列模型的生成中不能通过未来的数据作为已知的信息,而注意力机制会产生这个问题,因此通过 mask \text{mask} mask来修正模型对未来数据的已知。
接下来依次执行run.bat vocab,run.bat train_local,run.bat train,run.bat test,这里有一个问题就是可能win32file这个库无法导入,报错为:
ImportError: DLL load failed: 找不到指定的程序。
在 Win11 \text{Win11} Win11上实在是摆不平这个问题,只能到虚拟机上跑了。
- ( h ) (h) (h) BLEU \text{BLEU} BLEU指标达到 13.068 13.068 13.068,符合要求。
- ( i ) (i) (i) 一些简单的看法:
- ( 1 ) (1) (1) 点积注意力只能用于解码器隐层和编码器隐层维度相同,乘法则没有这个限制,且点积本身就是乘法的一种特殊形式,但是点积用起来很方便,不需要找权重矩阵 W W W;
- ( 2 ) (2) (2) 加法注意力揭示了解码器与编码器隐层更复杂的关联(使用了更多的参数),理论上效果会更好,但是加法注意力本身运算复杂度更高,容易使得模型训练时间加长。
2. Analyzing NMT Systems
-
( a ) (a) (a) 切罗基语是一种多义合成语言,单词的每个字符都表示该单词的一部分含义,因此使用字符级别的编码是更合适的,而且这样做相较于单词级别的编码,词嵌入空间也更小,可以简化模型。
-
( b ) (b) (b) 提示中说前缀是一种语素,即前缀也表达了某种含义,切罗基语中的字符可以表示一种前缀,因此每个字符都是具有独立语义的,应当使用字符级别的编码。
-
( c ) (c) (c) 所谓多语言训练,指的是在源语言平行语料较少的情况下,可以考虑将源语言与平行语料较多的语言混合起来一起训练(比如将切罗基语和中文混合起来,一起翻译成英文,基于这两混合的平行语料训练机器翻译模型)。
这种做法的合理性来源于迁移学习,即假定不同语言之间存在概率分布上的共性,因此使用中英互译语料训练得到的模型也可以套用在切罗基语译英语的模型上。
另一种解释是机器学习模型架构是具有共通性的,训练数据少因而难以将模型参数训练收敛到最优解,但是如果我们用另一种语言的平行语料来进行预训练,可以得到模型参数的一个较好的初始点(比如距离最优解很近),从这个初始点开始进行训练,即便是平行语料较少的切罗基语,也可以较好地收敛到最优解。
-
( d ) (d) (d) 可以到https://www.cherokeedictionary.net/去查询切罗基语的单词含义(但是我查了几个好像都没有结果,不知道具体是什么操作)。
- ( 1 ) (1) (1) 这个属于代词错误,应该是切罗基语中各个人称代词是不加区分的。这种问题类似英文中的 uncle,aunt \text{uncle,aunt} uncle,aunt翻译到中文中有若干单词与其对应,这种问题通常是比较无解的,但是这里显然还有另一个问题,就是前后代词不一致,那么就应该考虑建立文本序列长距离的联系,可以使用 LSTM \text{LSTM} LSTM或 GRU \text{GRU} GRU来挖掘前后代词距离较远的情况下的语义联系。
- ( 2 ) (2) (2) 这个应该是遇到了一个训练集中不存在的切罗基语的单词(零射问题),解决方案可能只能是扩充训练集语料,否则感觉是比较无解的。
- ( 3 ) (3) (3) 这个应该是某种固定用法的翻译错误,类似英文中俚语翻译到中文可能会出这种偏差,解决方案是可能可以通过建立俚语字典(引入强制规则)。
-
( e ) (e) (e) 这一问需要完全运行完代码得到KaTeX parse error: Expected '}', got '_' at position 18: …ext{output/test_̲outputs.txt}才能作答,代码运行时间是比较长的:
-
( 1 ) (1) (1) 找了一个 there is no distinction between \text{there is no distinction between} there is no distinction between,的确是在KaTeX parse error: Expected '}', got '_' at position 10: \text{chr_̲en_data/train.e…中出现过,这说明机器翻译系统的确有学习到整个序列的特征。
当然肯定可以找到一个没有出现过的短语,那我又可以说机器翻译系统的解码过程是逐字解码的,出现新的短语也不奇怪。
-
仍然以 there is no distinction between \text{there is no distinction between} there is no distinction between为例,下一个单词是 them \text{them} them,但是在训练集中下一个单词是 Jew \text{Jew} Jew,说明模型的解码并没有在做贪心解码,而是在寻求全局最优(可见[slides]中机器翻译解码算法的相关内容)。
-
-
( f ) (f) (f) 关于 BLEU \text{BLEU} BLEU在[notes]部分笔注已做详细记录( 5.3 5.3 5.3节),但是好像跟这里的公式有一些区别。
p n = ∑ ngram ∈ c min ( max i = 1 , 2 , . . . , n Count r i ( ngram ) , Count c ( ngram ) ) ∑ ngram ∈ c Count c ( ngram ) BP = { 1 if len ( c ) ≥ len ( r ) exp ( 1 − len ( r ) len ( c ) ) otherwise BLEU = BP × exp ( ∑ n = 1 k λ n log p n ) (a4.2.1) p_n=\frac{\sum_{\text{ngram}\in c}\min\left(\max_{i=1,2,...,n}\text{Count}_{r_i}(\text{ngram}),\text{Count}_{c}(\text{ngram})\right)}{\sum_{\text{ngram}\in c}\text{Count}_c(\text{ngram})}\\ \text{BP}=\left\{\begin{aligned} &1&&\text{if len}(c)\ge\text{len}(r)\\ &\exp\left(1-\frac{\text{len}(r)}{\text{len}(c)}\right)&&\text{otherwise} \end{aligned}\right.\\ \text{BLEU}=\text{BP}\times \exp\left(\sum_{n=1}^k\lambda_n\log p_n\right)\tag{a4.2.1} pn=∑ngram∈cCountc(ngram)∑ngram∈cmin(maxi=1,2,...,nCountri(ngram),Countc(ngram))BP=⎩⎪⎨⎪⎧1exp(1−len(c)len(r))if len(c)≥len(r)otherwiseBLEU=BP×exp(n=1∑kλnlogpn)(a4.2.1)
其中 c c c是机器翻译得到的序列, r i r_i ri是标准翻译的序列(可能会有多个), len ( r ) \text{len}(r) len(r)是从 r i r_i ri中找一个长度最接近 c c c的序列(如果有多个长度最近的则选那个最短的), k k k是指定的最长的 ngram \text{ngram} ngram,一般取 4 4 4, λ i \lambda_i λi是一系列累和为 1 1 1的权重系数。为了方便解下面的题,笔者编写了一段用于计算 BLEU \text{BLEU} BLEU的代码:
# -*- coding: utf-8 -*- # @author: caoyang # @email: caoyang@163.sufe.edu.cn # 计算BLEU指数import numpy from collections import Counterdef calc_bleu(nmt_translation, reference_translations, lambdas, k=4):# 权重系数的长度应当与ngram的最大长度相同assert len(lambdas) == k# 期望输入的是已经分好词的两个语句序列, 否则需要首先进行分词if isinstance(nmt_translation, str):nmt_translation = nmt_translation.split()for i in range(len(reference_translations)):if isinstance(reference_translations[i], str):reference_translations[i] = reference_translations[i].split()# 变量初始化nmt_ngram_counters = [] # 储存机器翻译序列的中所有的ngram短语, 并记录它们在机器翻译序列的中出现的次数reference_ngram_counters = [] # 储存机器翻译序列的中所有的ngram短语, 并记录它们在机器翻译序列的中出现的次数p_ns = [] # 储存所有p_n的取值length_nmt_translation = len(nmt_translation) # 机器翻译序列的长度len(c)# 计算len(r)length_reference_translation_min = float('inf') flag = float('inf')for reference_translation in reference_translations:length_reference_translation = len(reference_translation)error = abs(length_reference_translation - length_nmt_translation)if error <= flag and length_reference_translation <= length_reference_translation_min:length_reference_translation_min = length_reference_translationflag = error# 统计机器翻译序列中的ngram频次for n in range(k):ngrams = []for i in range(length_nmt_translation - n):ngrams.append(' '.join(nmt_translation[i:i + n + 1]))nmt_ngram_counters.append(dict(Counter(ngrams)))# print(nmt_ngram_counters)# print('-' * 64)# 统计标准翻译序列中的ngram频次for reference_translation in reference_translations:reference_ngram_counters.append([])for n in range(k):ngrams = []for i in range(len(reference_translation) - n):ngrams.append(' '.join(reference_translation[i:i + n + 1]))reference_ngram_counters[-1].append(dict(Counter(ngrams)))# print(reference_ngram_counters)# print('-' * 64)# 计算p_nfor n in range(k):p_n_numerator = 0 # p_n的分子部分p_n_denominator = 0 # p_n的分母部分for ngram in nmt_ngram_counters[n]:p_n_numerator += min([max([reference_ngram_counters[i][n].get(ngram, 0) for i in range(len(reference_ngram_counters))]), nmt_ngram_counters[n][ngram]])p_n_denominator += nmt_ngram_counters[n][ngram]p_n = p_n_numerator / p_n_denominatorp_ns.append(p_n)# 计算BPif length_nmt_translation > length_reference_translation_min:bp = 1else:bp = numpy.exp(1 - length_reference_translation_min / length_nmt_translation)# 计算BLEUbleu = bp * numpy.exp(sum([lambda_ * numpy.log(p_n) for lambda_, p_n in zip(lambdas, p_ns)]))return bleureference_translations = ['the light shines in the darkness and the darkness has not overcome it','and the light shines in the darkness and the darkness did not comprehend it', ]nmt_translations = ['and the light shines in the darkness and the darkness can not comprehend','the light shines the darkness has not in the darkness and the trials', ]for nmt_translation in nmt_translations:bleu = calc_bleu(nmt_translation=nmt_translation, reference_translations=reference_translations, lambdas=[.5, .5, .0, .0],k=4)print(bleu)-
( 1 ) (1) (1) 直接运行上面的代码,可得:
BLEU ( c 1 ) = 0.877 BLEU ( c 2 ) = 0.797 (a4.2.2) \text{BLEU}(c_1)=0.877\quad \text{BLEU}(c_2)=0.797\tag{a4.2.2} BLEU(c1)=0.877BLEU(c2)=0.797(a4.2.2)
我认同这个结果, c 1 c_1 c1确实翻译得要更正确。 -
( 2 ) (2) (2) 注释掉 78 78 78行再运行,可得:
BLEU ( c 1 ) = 0.716 BLEU ( c 2 ) = 0.797 (a4.2.3) \text{BLEU}(c_1)=0.716\quad \text{BLEU}(c_2)=0.797\tag{a4.2.3} BLEU(c1)=0.716BLEU(c2)=0.797(a4.2.3)
现在我就不那么认同这个结果了。 -
( 3 ) (3) (3) 译文通常都是不唯一的,因此如果只有一个参考译文作为评判标准,的确是不够客观与准确的。在有多参考译文的情况下, BLEU \text{BLEU} BLEU表现得更好。
-
( 4 ) (4) (4) 与人类评估相比的优势:简便快捷,可以批量操作,省时省力;不容易出现疲劳误判等;
与人类评估相比的劣势: BLEU \text{BLEU} BLEU本质上只考虑了短语的频数特征,并没有考察译文的流畅性,完全可以构造出一个 BLEU \text{BLEU} BLEU值很高但完全读起来狗屁不通的译文(比如颠倒一下前后句)。此外 BLEU \text{BLEU} BLEU的表现受参考译文数量制约。
-
lecture 8 期末项目
本以为这一讲可以跳过,结果劈头盖脸的71页slides,还有一篇非常不错的推荐阅读(关于深度学习项目实践中的一些有用的做法)。
slides
[slides]
-
自然语言处理领域常用的论文检索网站:
① ACL anthology:这个是最好用的,ACL和EMNLP这两个最重要的顶会,以及其他一些学术会议历年的论文都可以找到。
② NeurlPS:NIPS顶会的期刊论文。
③ ICLR
④ arxiv
-
如果你想击败目前各研究领域最先进的研究成果,可以查看下面几个网站:
① https://paperswithcode.com/sota:论文+代码
② https://nlpprogress.com/:总结目前自然语言研究各领域的最先进研究成果
以及一些特定的自然语言处理领域任务的公开排行榜:
① https://gluebenchmark.com/leaderboard/
② https://www.conll.org/previous-tasks/
-
2022年的研究热点:
-
提升模型在鲁棒性(跨领域适应性),推荐网站[RobustnessGym];
-
做一些综述性工作,如看看大规模的预训练模型都在学习什么;
-
研究如何从特定任务的大模型中得到知识以及好的任务评测结果(无需大规模训练数据),如迁移学习;
-
研究大模型的偏差(bias),可信度(trustworthiness),可解释性(explainability);
-
研究如何增强数据来提升模型性能;
-
研究低资源场景下的建模问题;
-
从一些稀有的角度来提升性能,解决偏差;
-
将大模型变小:model pruning,model quantization,高效问答;
-
寻求模型功能性提升:如更快的训练速度;babyAI,gSCAN
-
-
寻找数据:自己积累的数据集、项目合作的数据集、其他研究者公开发布的数据集(论文中提供)。
一些公开的数据源:
ldc数据检索,
斯坦福数据(需要申请),统计机器翻译数据,
依存分析数据,
HuggingFace数据,
Paperwithcode数据(好像失效了),
Kaggle,
machinelearningmasteryNLP数据,
GitHub@nlp-datasets,
gluebenchmark
nlp.stanford情感分析数据
https://research.fb.com/downloads/babi/
tips
[Custom project tips]
有一个很有趣的点是他们的课程项目是需要制作海报(poster),这有点类似我们做关于proposal的pre,但是所有内容都需要浓缩到一张纸上,这是一个挺不错的做法,感觉可以借鉴一下。
suggested readings
Practical Methodology
这篇推荐阅读值得记录,对做项目是很有帮助的。
-
首先确定你的目标(使用何种评价指标,期望的目标值),然后尽快先把项目框架搭好,从原始数据流入到模型输出评估绘图的架子先搭好,然后一一实现其中的方法,不要做完一步才想下一步怎么做。
-
错误分析:过拟合?欠拟合?数据缺陷?硬件软件不足?
-
持续性地引入更多地数据、调参、尝试新算法,这一切都基于你的实验发现。
-
除非训练集包含数以百万计的样本,否则从一开始就应该使用一些正则化手段,这包括:
① 早停(early stopping)
② 丢弃(dropout)
③ 批标准化(batch normalization)
-
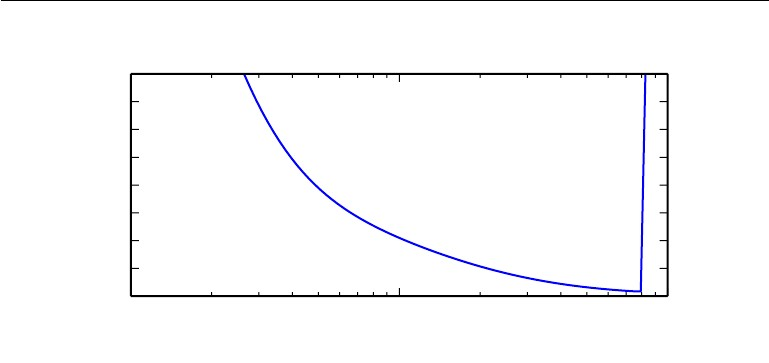
学习率是最重要的超参数,如果你的时间只够调一个参,那就是学习率。学习率关于训练损失函数值的图像通常是一个U型,即随着学习率从很小(比如 1 0 − 6 10^{-6} 10−6)不断增大,训练损失也会不断下降,直到一个阈值,训练损失会突然骤升,我们需要找到那个最优的学习率。
-
一般来说,减小权重衰减、减小dropout概率、增加直接零填充(implicit zero padding),增加CNN的核宽度、增加隐层节点数量都会提升模型的性能(但是会增加训练时间)。
-
参数自动化调优:GridSearch应该是一个迭代进行的过程,即在预先定义好的网格点上搜索完之后会接着更新更细化的网格点(根据前一次所有网格点的模型性能值),接着搜索超参数的组合(感觉这样是会落到局部最优)。
也可以直接随机搜索,定义好每个参数的搜索的一个概率分布,然后随机跑参数组合进行测试。
然后更有甚者,学习新模型来调参,因为寻找最优参数的问题本质也是一个优化问题,这有点像运筹优化研究领域那些针对黑盒系统(只能输入输出)的优化手段了。
-
一些调试测试的方法:
- 可视化模型所执行的行为:如图像实体识别模型可以看看到底识别了些什么,语法改错模型看看模型到底改了什么错误,等等。
- 可视化最坏的错误:找出训练集中那些模型最难预测的样本。
- 利用训练误差与测试误差来推导底层软件实现是否有问题。比如训练误差很低,但是测试误差很高,这很可能源于测试集与训练集具有明显的分布差异。
- 在极小的一个数据集上先跑通代码。
- 将反向传播导数与数值导数进行比较:这个实现起来会比较困难,但是对于发现大模型中的梯度消失和梯度爆炸是有帮助的。
- 制作监视梯度和激活函数的图像:这主要是观察模型的参数是否真的在每次迭代中得到了更新,很多时候,可能一些层的参数根本就一直没有变过(因为梯度太小)。
projects
[instructions] [handout (IID SQuAD track)] [handout (Robust QA track)]
CS224N的课程项目是1-3人组队,可以选择教授提供的默认项目(SQuAD),也可以另起炉灶,可以在已有的公开项目上进行深入工作,但是必须编写详实的文档。
单人项目将会独立进行评估。
关于CS224N课程的期末项目的报告,历年以来都是公开的:
2022年CS224N期末项目报告汇总
2021年CS224N期末项目报告汇总
2020年CS224N期末项目报告汇总
2019年CS224N期末项目报告汇总
每年还是有不少做的是自然语言处理以外工作的项目,比如也有人会做图像处理领域的工作。
上面的链接中都有每年被评为最好的几个项目,实话说有几个完全都看不懂做得是什么工作(躺平)。
![[论文翻译] Deep Learning](https://img-blog.csdnimg.cn/20200811114635497.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2RpYW9rdWkyMzEy,size_16,color_FFFFFF,t_70#pic_center)