目录
1. 聚合函数介绍
1.1 AVG和SUM函数
1.2 MIN和MAX函数
1.3 COUNT函数
2. GROUP BY
2.1 基本使用
2.2 使用多个列分组
2.3 GROUP BY中使用WITH ROLLUP
3. HAVING
3.1 基本使用
3.2 WHERE和HAVING的对比
4. SELECT的执行过程
4.1 查询的结构
4.2 SELECT执行顺序
4.3 SQL的执行原理
5 聚合函数课后练习
1.where子句可否使用组函数进行过滤?
2.查询公司员工工资的最大值,最小值,平均值,总和
3.查询各job_id的员工工资的最大值,最小值,平均值,总和
4.选择具有各个job_id的员工人数
5.查询员工最高工资和最低工资的差距(DIFFERENCE)
6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
8.查询每个工种、每个部门的部门名、工种名和最低工资
1. 聚合函数介绍

聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用
1.1 AVG和SUM函数
SELECT AVG(salary), MAX(salary),MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';![]()
1.2 MIN和MAX函数
SELECT MIN(hire_date), MAX(hire_date)
FROM employees;1.3 COUNT函数
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;![]()
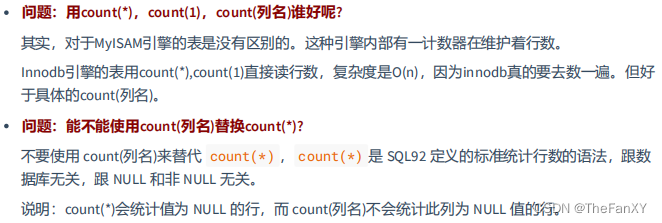
除了COUNT()其他的函数都是默认过滤空值的,AVG() = SUM()/ COUNT()
因此求平均奖金率类似的问题,可以采用:
# 错误
SELECT AVG(commission_pct) FROM employees
# 正确
SELECT SUM(commission_pct) / COUNT(commission_pct) FROM employees
# 正确
SELECT AVG(IFNULL(commission_pct, 0)) FROM employees2. GROUP BY
2.1 基本使用

可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];明确: WHERE一定放在FROM后面
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;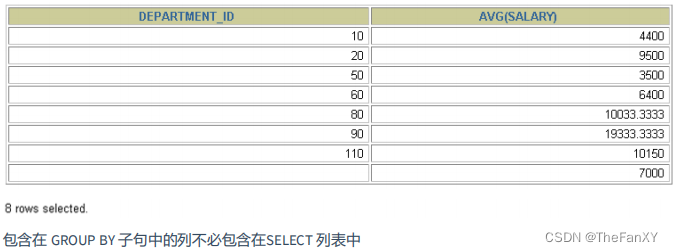
SELECT AVG(salary)
FROM employees
GROUP BY department_id;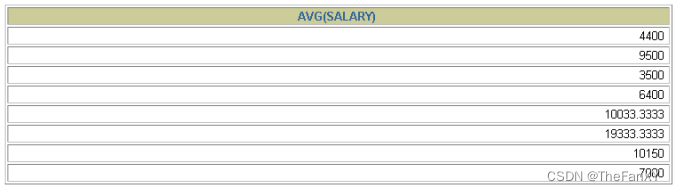
2.2 使用多个列分组
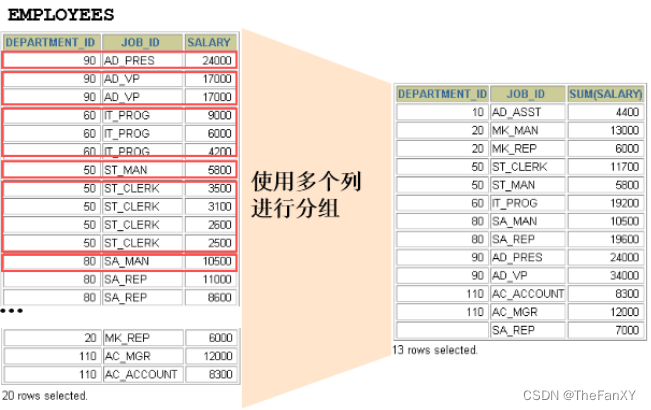
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id;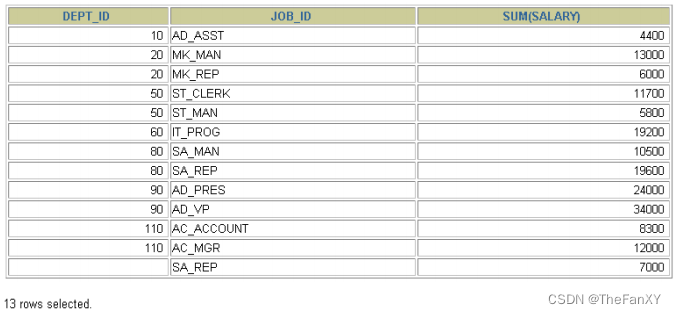
SELECT中出现的非组函数的字段必须声明在GROUP BY当中,但GROUP BY中声明的字段不一定需要放在SELECT当中
GROUP BY声明在FROM,WHERE后面,ORDER BY,LIMIT前面
2.3 GROUP BY中使用WITH ROLLUP
SELECT department_id,AVG(salary)
FROM employees
WHERE department_id > 80
GROUP BY department_id WITH ROLLUP;注意:当使用 ROLLUP 时,不能同时使用 ORDER BY 子句进行结果排序,即 ROLLUP 和 ORDER BY 是互相排斥的。
3. HAVING
3.1 基本使用
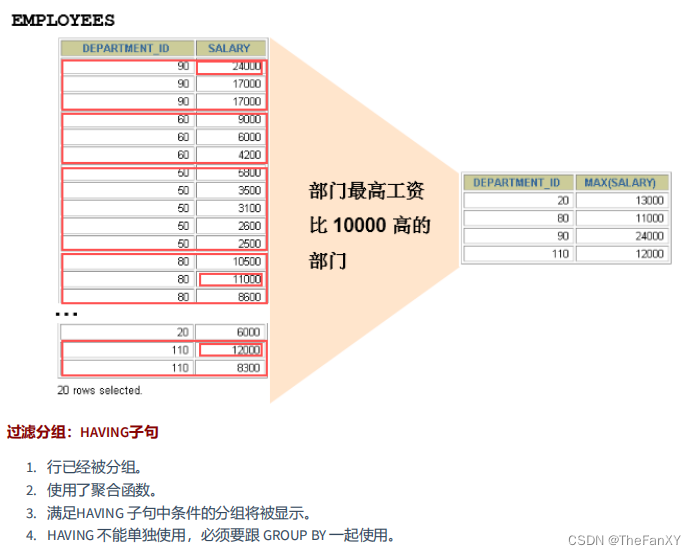

SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ; 非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数。如下:
非法使用聚合函数 : 不能在 WHERE 子句中使用聚合函数。如下:
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000
GROUP BY department_id; 3.2 WHERE和HAVING的对比
3.2 WHERE和HAVING的对比

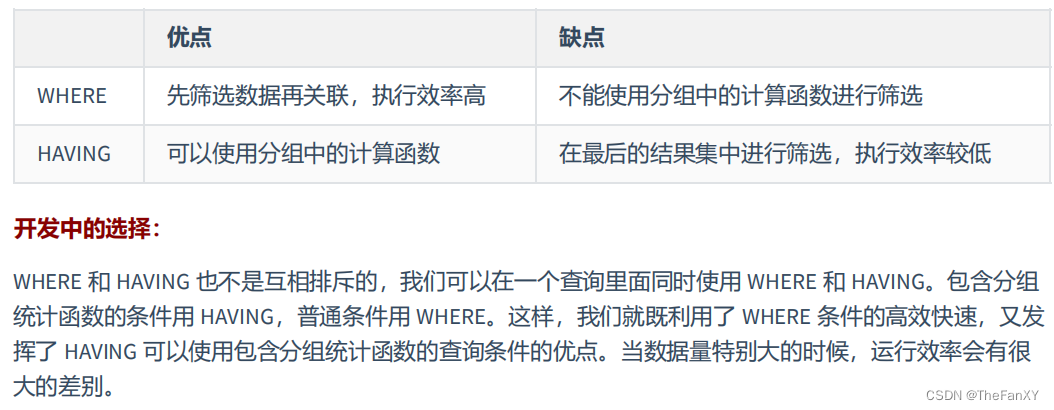
4. SELECT的执行过程
4.1 查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页4.2 SELECT执行顺序
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
2.SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同)
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
 比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 74.3 SQL的执行原理


5 聚合函数课后练习
1.where子句可否使用组函数进行过滤?
No!2.查询公司员工工资的最大值,最小值,平均值,总和
SELECT MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees;3.查询各job_id的员工工资的最大值,最小值,平均值,总和
SELECT job_id, MAX(salary), MIN(salary), AVG(salary), SUM(salary)
FROM employees
GROUP BY job_id;4.选择具有各个job_id的员工人数
SELECT job_id, COUNT(*)
FROM employees
GROUP BY job_id;5.查询员工最高工资和最低工资的差距(DIFFERENCE)
SELECT MAX(salary), MIN(salary), MAX(salary) - MIN(salary) DIFFERENCE
FROM employees;6.查询各个管理者手下员工的最低工资,其中最低工资不能低于6000,没有管理者的员工不计算在内
7.查询所有部门的名字,location_id,员工数量和平均工资,并按平均工资降序
SELECT department_name, location_id, COUNT(employee_id), AVG(salary) avg_sal
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
GROUP BY department_name, location_id
ORDER BY avg_sal DESC;8.查询每个工种、每个部门的部门名、工种名和最低工资
SELECT department_name,job_id,MIN(salary)
FROM departments d LEFT JOIN employees e
ON e.`department_id` = d.`department_id`
GROUP BY department_name,job_id