简介
在本教程中,你将学习如何在 Ubuntu 22.04 服务器上安装 Elasticsearch。此外,你还将学习如何使用 Elasticsearch REST API 索引和操作数据。
Elasticsearch 是一个基于 Apache Lucene Library 的免费分布式搜索和分析引擎。它是一个快速且可扩展的分析引擎,提供了一个广泛的 API,允许你处理 JSON 请求并在几毫秒内获得反馈。这使其成为数据分析和搜索用例的理想选择。
Elasticsearch 是 ELK Stack(Elasticsearch、Logstash、Kibana)的关键组件,用于索引和存储数据。它的结构不是基于表和模式,而是基于文档,数据以键值对的形式存储。
本教程的目标是手把手教你如何在 Linux 服务器上安装 Elasticsearch。
准备工作
服务器准备
必要前提:
- 一个充满求知欲的大脑。
- 一台 Linux 服务器(推荐腾讯云、阿里云或雨云等)。
我将以 雨云 为例,带大家创建一台自己的云服务器,以便学习本篇文章的内容。
注册链接: https://rainyun.ivwv.site
创建雨云服务器
以下步骤仅供参考,请根据实际需求选择配置。
- 点击 云产品 → 云服务器 → 立即购买。
- 选择距离你较近的区域,以保证低延迟。
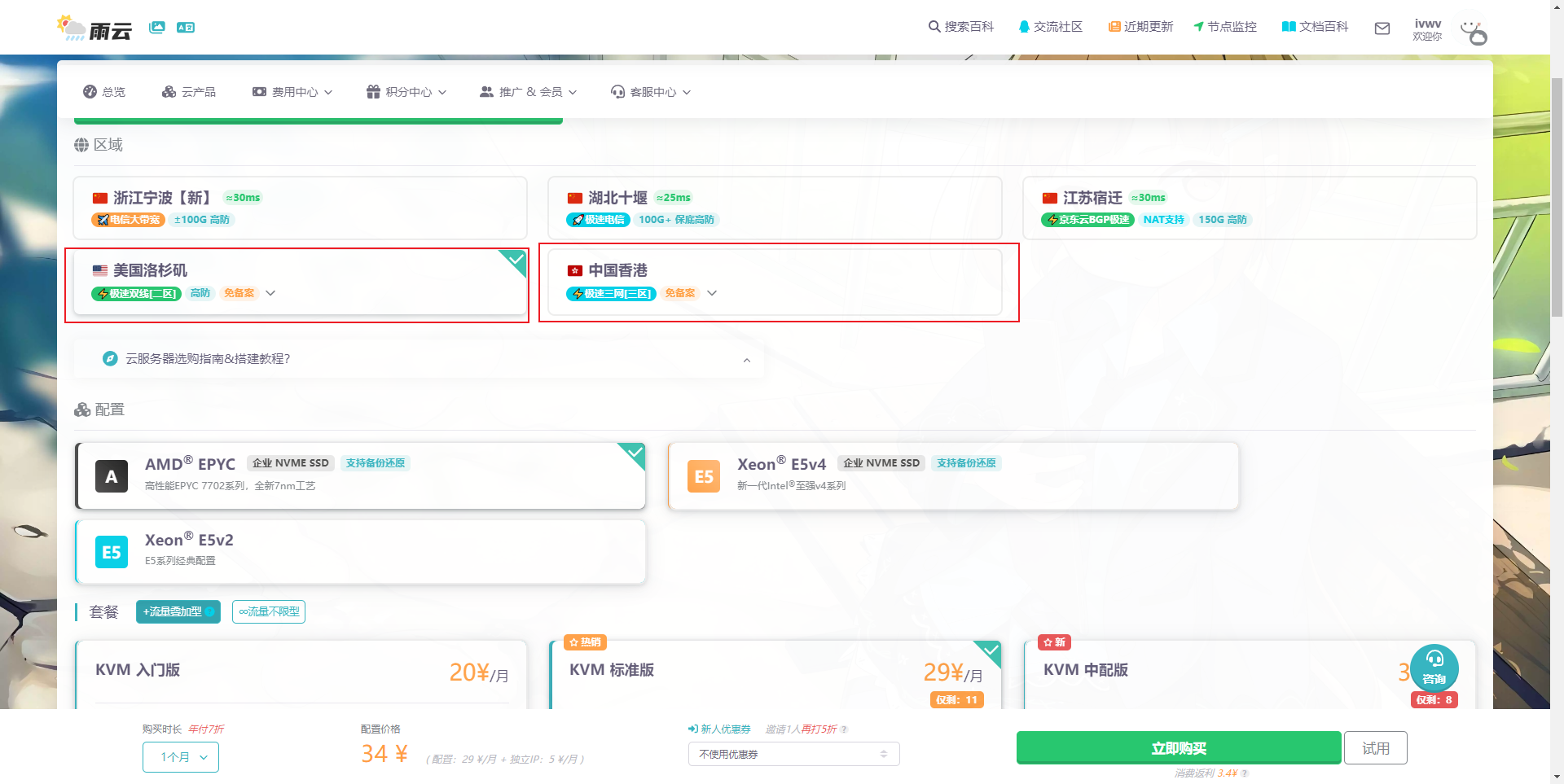
- 按照自己需求选择配置,选择Ubuntu 22.04 版本,按照自己需求是否预装Docker。
- 最后按照提示进行购买。
- 购买后等待机器部署完毕,点击刚刚创建好的服务器,进入管理面板,找到远程连接相关信息。
- 我们使用
PowerShell进行SSH远程连接到服务器,Win+R打开运行窗口,输入powershell后点击确定。

- 到此为止,我们的云服务器就远程连接上了。
第一步:安装 Elasticsearch
Elasticsearch 没有正式托管在 Ubuntu 的默认软件包存储库中。唯一的方法是将 Elastic 的软件包源列表添加到源列表目录。添加后,你可以使用 APT 软件包管理器进行安装。
首先,你需要添加 Elasticsearch GPG 签名密钥,以便验证 Elasticsearch 软件包。经过身份验证的软件包可确保你的系统可以通过软件包管理器信任安装在你系统上的软件包的完整性。
要添加签名密钥,请使用 curl 命令导入 Elasticsearch 公共 GPG 密钥。
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
添加 GPG 密钥后,将 Elastic 源列表添加到 sources.list.d 目录。
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
接下来,更新本地软件包列表 ,以通知系统新添加的存储库。
sudo apt update
然后使用以下命令安装 Elasticsearch:
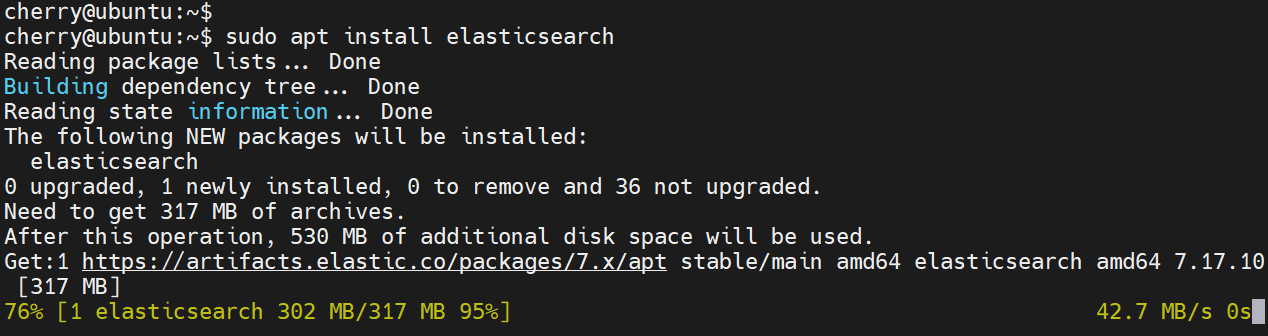
$ sudo apt install elasticsearch
该命令将安装 Elasticsearch,还会创建一个名为 elasticsearch 的用户和组。
第二步:配置 Elasticsearch
Elasticsearch 的主要配置文件是位于 /etc/elasticsearch 目录中的 elasticsearch.yml 文件。这是一个 YAML 文件,用于存储集群、节点、内存、路径和网络设置。它是主要的配置文件,并在很大程度上控制着 Elasticsearch 的功能。
为了根据你的偏好自定义 Elasticsearch,需要进行一些配置。因此,请使用你喜欢的文本编辑器访问该文件。在本示例中,我们使用 nano 编辑器。
sudo nano /etc/elasticsearch/elasticsearch.yml
首先,指定一个集群名称。请注意,只有当节点的集群名称与同一集群中的其他节点相同时,该节点才能加入集群。
滚动到 Cluster 部分,并取消注释 cluster.name 指令。为你的集群提供一个描述性的名称。为了演示目的,我们将其重命名为 my-cluster。
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-cluster
#
接下来,配置节点名称。这由 node.name 指令定义。默认情况下,此设置为 node-1。你可以通过取消注释并提供你喜欢的名称来手动配置它。在这里,我们将其命名为 sample-node。
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: sample-node
#
默认情况下,Elasticsearch 侦听来自 localhost 或 IP 地址 127.0.0.1 的流量。要查询另一个服务器,请将 network.host 指令设置为相应的 IP 地址。向下滚动到“网络”部分,并将其设置为你首选的 IP。在我们的例子中,我们将其设置为 localhost。
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
network.host: localhost
#
最后,指定 Elasticsearch 侦听的 HTTP 端口。默认情况下,这是端口 9200。你可以保持原样或提供不同的端口。
完成修改设置后,保存更改并退出配置文件。接下来,运行以下命令以通知系统所做的更改。
sudo systemctl daemon-reload
接下来,启用 Elasticsearch 服务以在启动时启动。
sudo systemctl enable elasticsearch
然后如下所示启动 Elasticsearch 服务。这通常需要大约一分钟,并且一旦你按下 ENTER 键,该命令可能会显示为卡住或冻结。所以,不要惊慌。耐心一点就好。
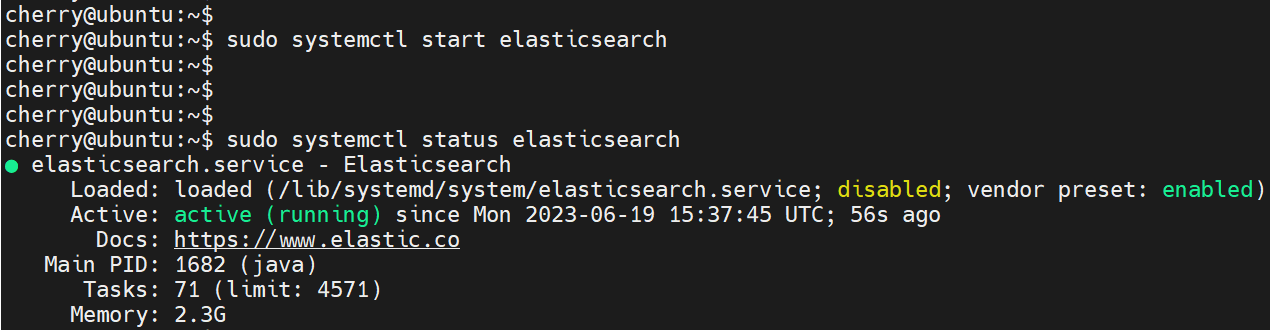
sudo systemctl start elasticsearch
要确认 Elasticsearch 正在运行,请执行以下命令:
sudo systemctl status elasticsearch
从输出中,你可以看到 Elasticsearch 正在运行。
第三步:测试 Elasticsearch
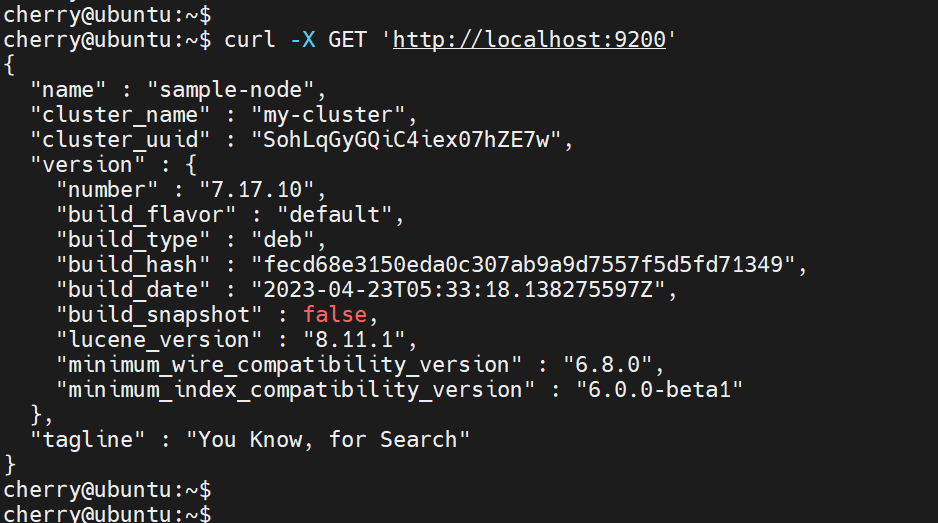
至此,Elasticsearch 已安装并在端口 9200 上运行,这是其默认端口。测试 Elasticsearch 是否工作的最简单方法是使用 curl 命令 发送 GET 请求来查询 Elasticsearch 服务器,如下所示。
curl -X GET '<http://localhost:9200>'
如果你的安装顺利进行,你应该以 JSON 格式获得以下输出,其中显示了服务器详细信息。
有关 Elasticsearch 服务器的深入信息,请运行以下命令:
curl -X GET '<http://localhost:9200/_nodes?pretty>'
?pretty 指令将输出格式化为人类可读的格式。
第四步:配置 UFW 防火墙
目前,任何拥有你的服务器 IP 的人都可以访问 Elasticsearch HTTP API。你可能希望将访问权限限制为仅你的 IP 地址,而不是其他人。
你可以通过 配置 UFW 防火墙 来实现此目的,方法是应用以下规则,其中 [你的-ip-地址] 是你的公共 IP 地址。
sudo ufw allow from [你的-ip-地址] to any port 9200
要添加另一个 IP 地址,请再次运行相同的命令,这次使用不同的 IP 地址。
如果防火墙未启用,请确保启用它。
sudo ufw enable
重新加载防火墙以使规则生效。
sudo ufw reload
然后验证防火墙状态。
sudo ufw status
第五步:使用 Elasticsearch
Elasticsearch 使用 RESTful API,允许它执行与 CRUD 操作相对应的基本操作,例如创建、读取、更新和删除。与这些操作等效的 HTTP 方法分别是 POST、GET、PUT 和 DELETE。
要开始使用 Elasticsearch,你需要先使用一些数据填充索引。索引相当于关系数据库中的数据库。它是文档的集合,每个文档都包含按键值对组织的字段,其中包含数据。
要创建文档,你需要使用索引名称、类型和 ID,向 API 发送 PUT 请求(使用 Curl 命令)。
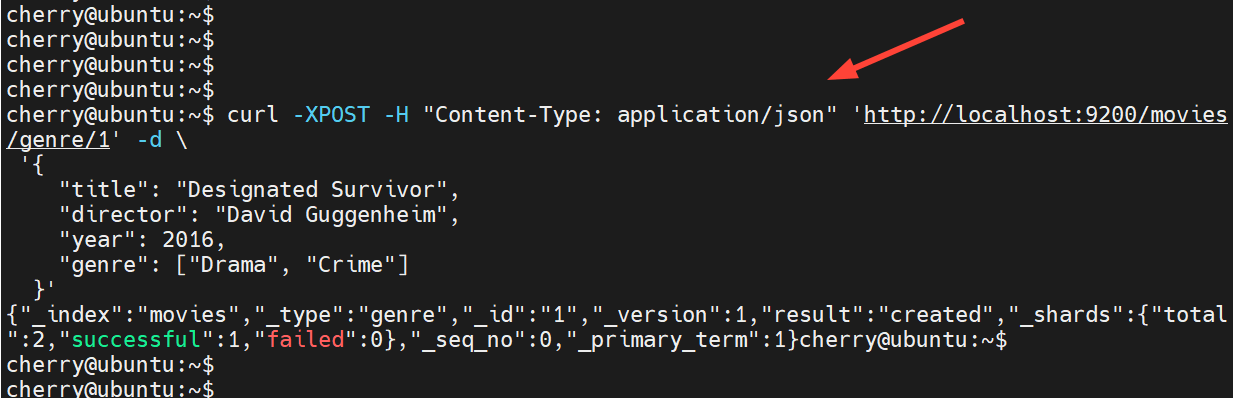
让我们索引一些内容。在下面的命令中,我们创建了一个名为 movies 的索引,类型为 genre,ID 为 1。该索引以 JSON 格式存储有关电影的信息。
curl -XPOST -H "Content-Type: application/json" 'http://localhost:9200/movies/genre/1' -d \\'{"title": "Designated Survivor","director": "David Guggenheim","year": 2016,"genre": ["Drama", "Crime"]}'
你应该获得与我们类似的输出。
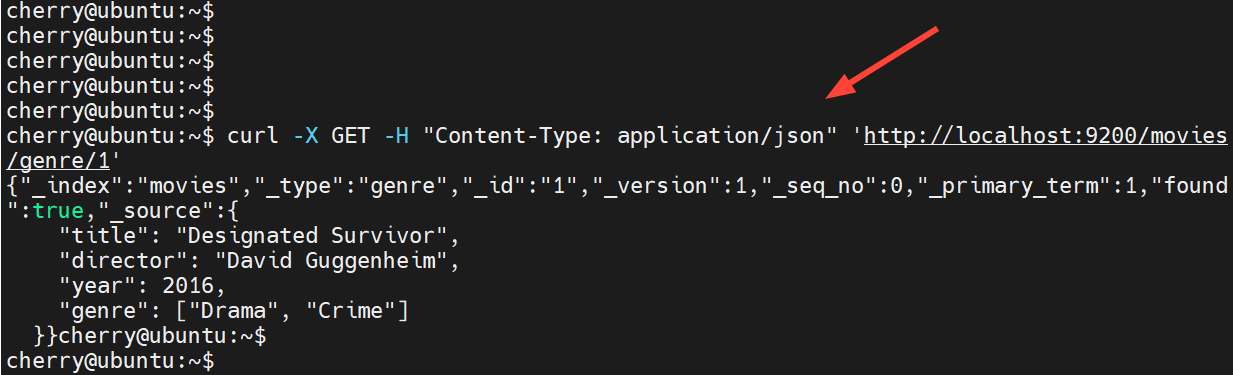
要检索此条目,请发送 HTTP GET 请求,如下所示。
curl -X GET -H "Content-Type: application/json" 'http://localhost:9200/movies/genre/1'
你应该获得以下输出。
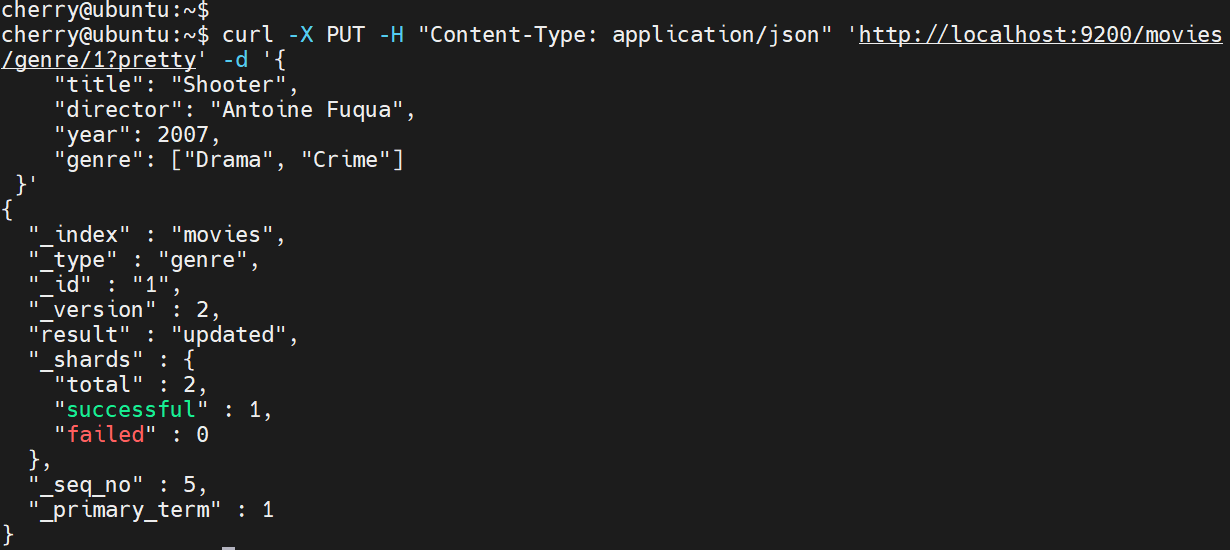
现在,我们将使用 HTTP PUT 请求修改条目。
curl -X PUT -H "Content-Type: application/json" 'http://localhost:9200/movies/genre/1?pretty' -d \\
'{"title": "Shooter","director": "Antoine Fuqua","year": 2007,"genre": ["Drama", "Crime"]}'
Elasticsearch 将确认所做的更改并显示以下输出。修改电影记录后,请注意版本号已自动增加到 2。这表示已对文档进行了修改。
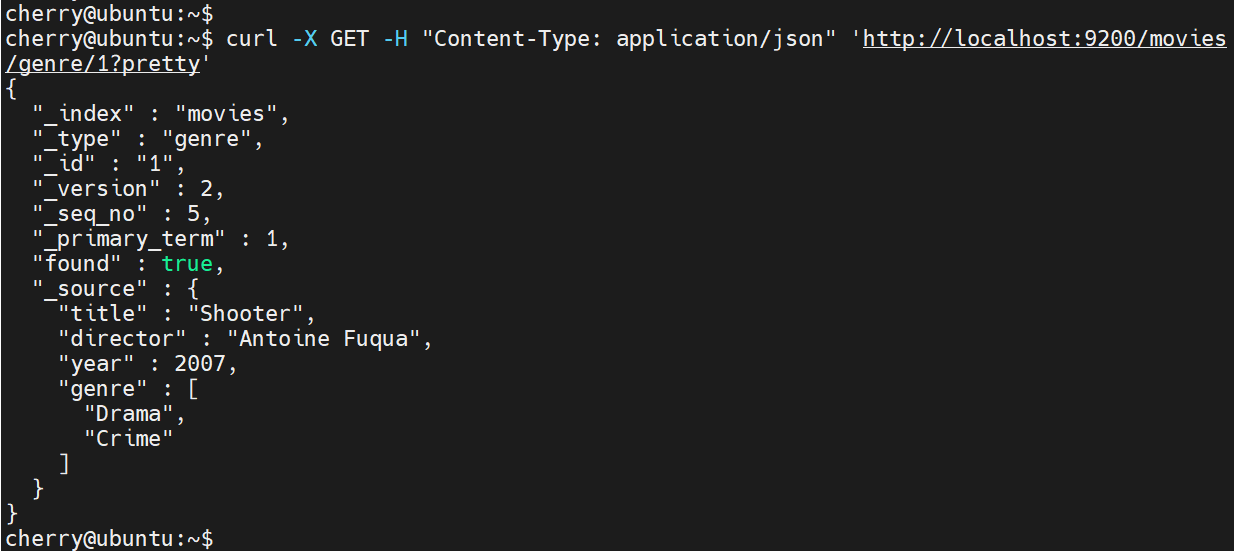
要验证所做的更改,请通过发送 GET 请求来查看记录。
curl -X GET -H "Content-Type: application/json" 'http://localhost:9200/movies/genre/1?pretty'
命令末尾的 ?pretty 部分将输出格式化为更易于人类阅读的格式。
结论
完成本教程中的每个步骤后,你已成功安装和配置了 Elasticsearch,并使用 HTTP POST、GET 和 PUT 方法测试了其功能。
有关 Elasticsearch 的更多信息,请参阅 Elasticsearch 官方文档。
雨云 - 新一代云服务提供商: https://rainyun.ivwv.site
我的博客:https://blog.ivwv.site




