1. 实验目的
①掌握Matplotlib绘图基础;
②运用Matplotlib,实现数据集的可视化;
③运用Pandas访问csv数据集。
2. 实验内容
①绘制散点图、直方图和折线图,对数据进行可视化;
②下载波士顿数房价据集,并绘制数据集中各个属性与房价之间的散点图,实现数据集可视化;
③使用Pandas访问鸢尾花数据集,对数据进行设置列标题、读取数据、显示统计信息、转化为Numpy数组等操作;并使用Matpoltlib对数据集进行可视化。
3. 实验过程
题目一:
这是一个商品房销售记录表,请根据表中的数据,按下列要求绘制散点图。其中横坐标为商品房面积,纵坐标为商品房价格。
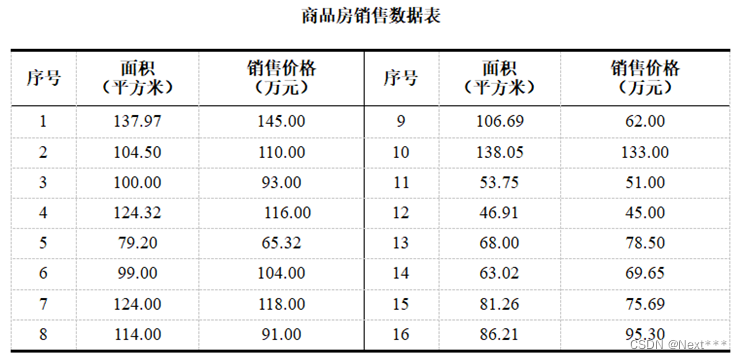
要求:
(1)绘制散点图,数据点为红色圆点;
(2)标题为:“商品房销售记录”,字体颜色为蓝色,大小为16;
(3)横坐标标签为:“面积(平方米)”,纵坐标标签为“价格(万元)”,字体大小为14。
源代码
import numpy as np
import matplotlib.pyplot as plt#设置rc参数
plt.rcParams["font.family"] = "SimHei"#设置默认字体为中文黑体
plt.rcParams['axes.unicode_minus'] = False #坐标轴上负号的显示可能会出错
area = np.array([137.97,104.50,100.00,124.32,79.20,99.00,124.00,114.00,106.69,138.05,53.75,46.91,68.00,63.02,81.26,86.21])
price = np.array([145.00,110.00,93.00,116.00,65.32,104.00,118.00,91.00,62.00,133.00,51.00,45.00,78.50,69.65,75.69,95.30])plt.scatter(area,price,color = 'red')
plt.title("商品房销售记录",fontsize = "16",color = "blue")
plt.xlabel("面积(平方米)",fontsize = '14')
plt.ylabel("价格(万元)",fontsize = '14')plt.show()
题目二:
按下列要求完成程序。
(1)下载波士顿数据集,读取全部506条数据,放在NumPy数组x、y中(x:属性,y:标记);
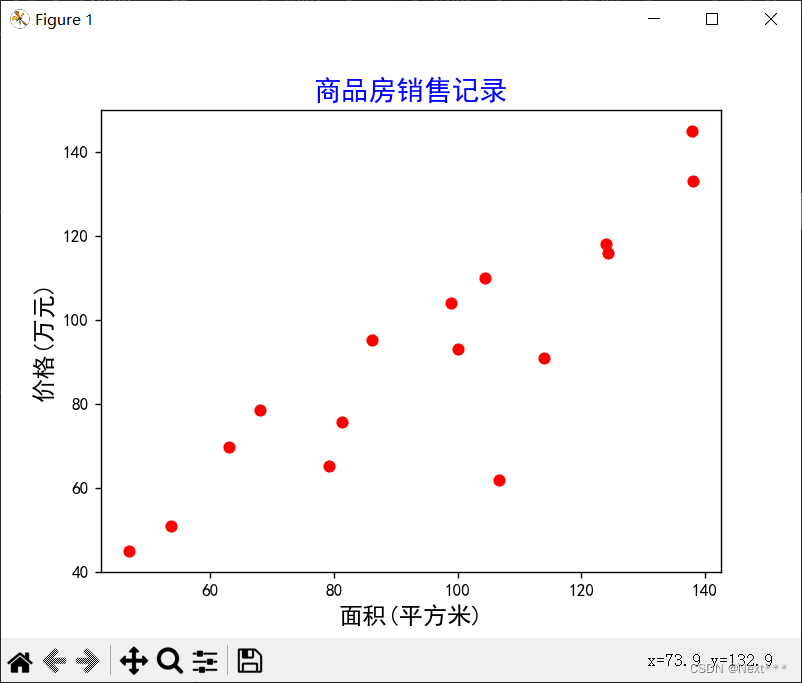
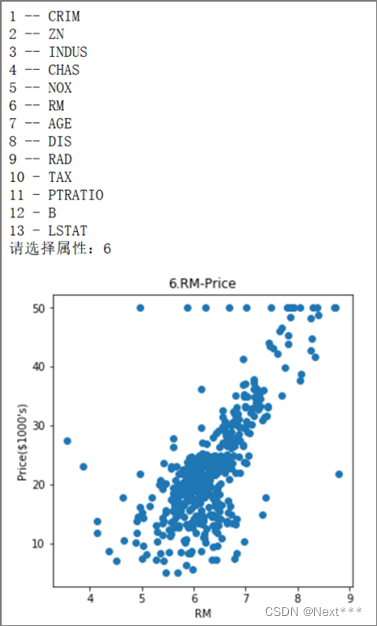
(2)使用全部506条数据,实现波士顿房价数据集可视化,如图1所示;
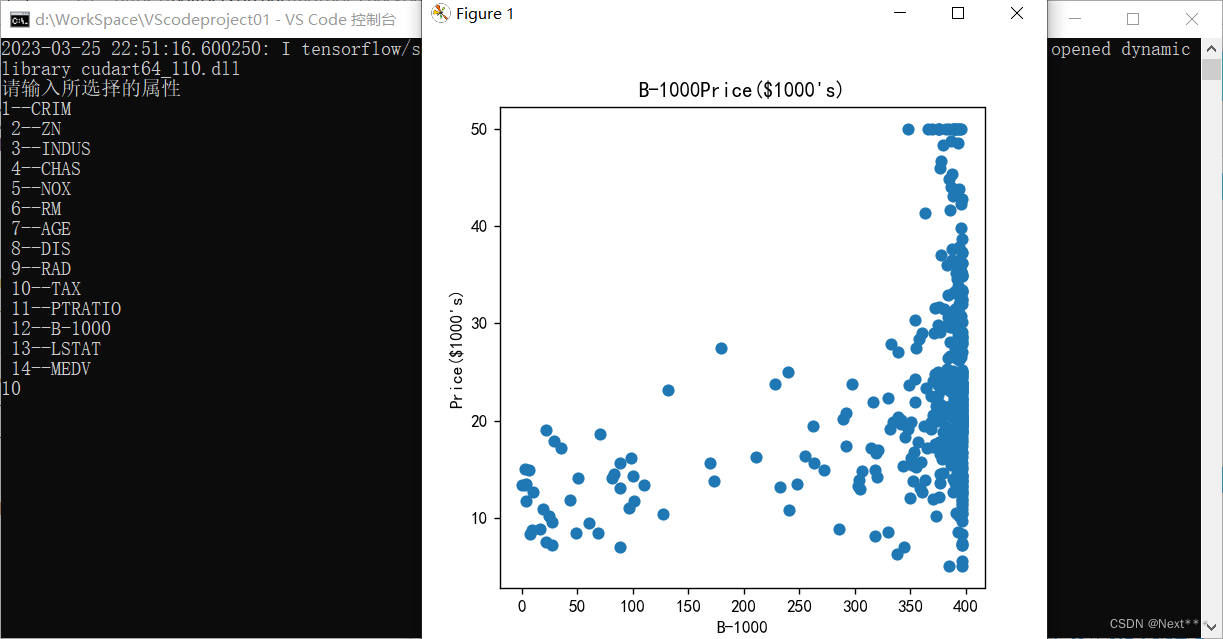
(3)要求用户选择属性,如图2所示,根据用户的选择,输出对应属性的散点图,如图3所示
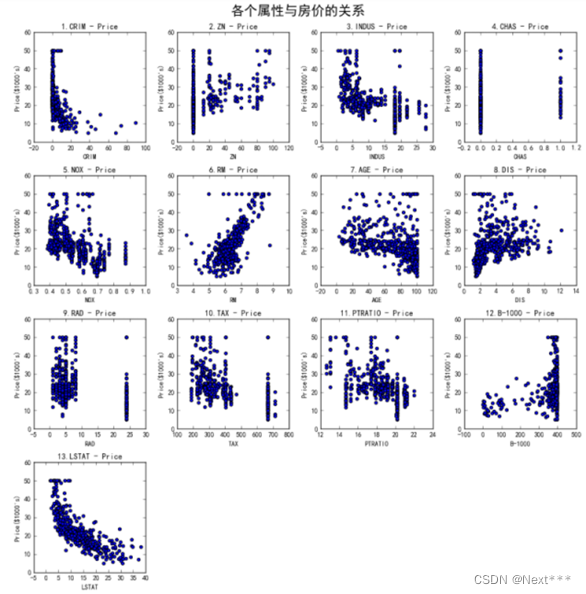
请用户输入属性:
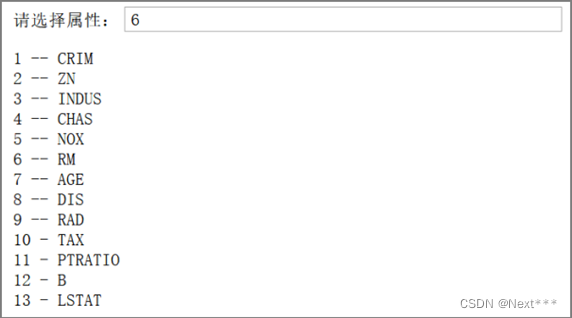
运行结果:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as npboston_housing = tf.keras.datasets.boston_housing
(train_x, train_y), (test_x, test_y) = boston_housing.load_data(test_split=0)plt.rcParams['font.sans-serif'] = "SimHei"
plt.rcParams['axes.unicode_minus'] = Falsetitles = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX","PTRATIO", "B-1000", "LSTAT", "MEDV"
]plt.figure(figsize=(14, 14))for i in range(13):plt.subplot(4, 4, i + 1)plt.scatter(train_x[:, i], train_y)plt.xlabel(titles[i])plt.ylabel("Price($1000's)")plt.title(str(i + 1) + "." + titles[i] + " - Price")plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.suptitle("各个属性与房价的关系", x=0.5, y=0.98, fontsize=20)
plt.show()plt.close()print("请输入所选择的属性")
print( "1--CRIM\n", "2--ZN\n", "3--INDUS\n", "4--CHAS\n", "5--NOX\n", "6--RM\n", "7--AGE\n", "8--DIS\n", "9--RAD\n", "10--TAX\n","11--PTRATIO\n", "12--B-1000\n", "13--LSTAT\n", "14--MEDV")
n = int(input())
sc = titles[i - 1] + "Price($1000's)"
plt.figure(figsize=(5,5))
plt.scatter(train_x[:,i-1],train_y)
plt.xlabel(titles[i - 1])
plt.ylabel("Price($1000's)")
plt.title(sc)
plt.show()
题目三:
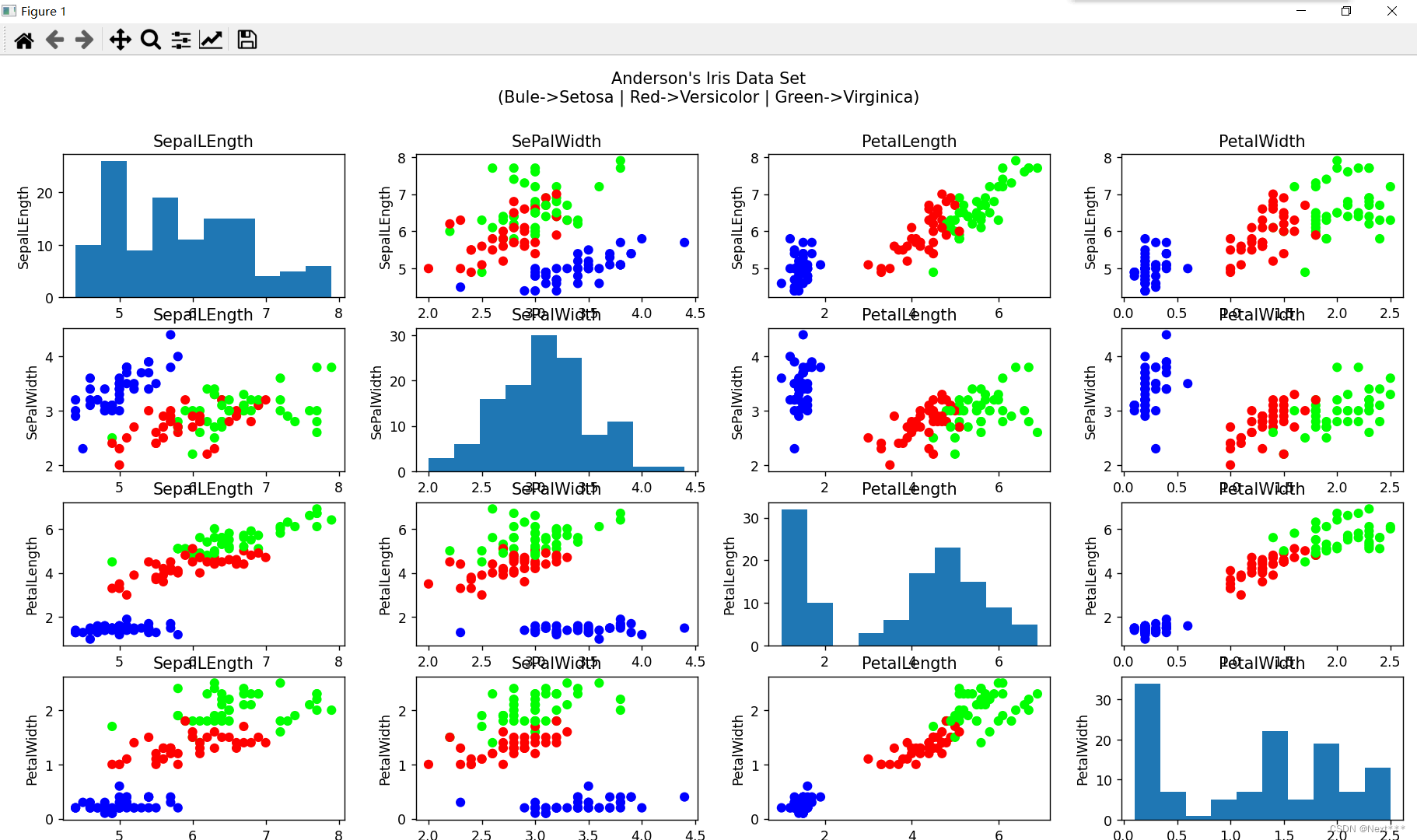
使用鸢尾花数据集,绘制如下图形,其中对角线为属性的直方图。
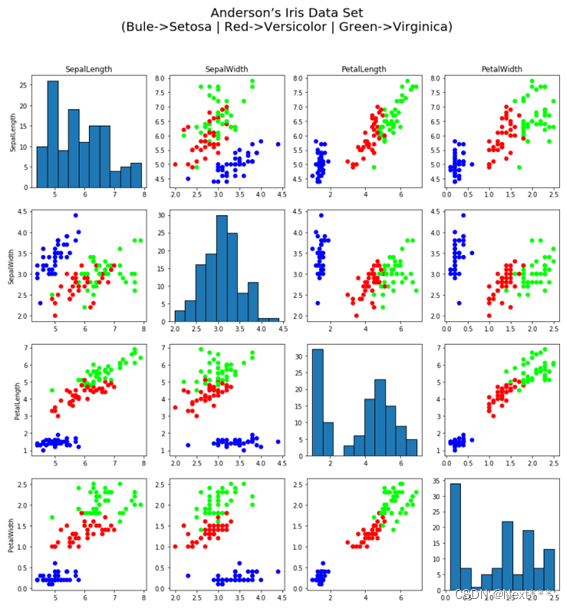
提示:绘制直方图函数 plt.hist(x, align= ‘mid’, color, edgecolor)
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pdTRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)#设置列标题
COLUMN_NAMES = ['SepalLEngth', 'SePalWidth', 'PetalLength', 'PetalWidth', 'Species'
]
#下载鸢尾花数据集,并设置列标题
dr_iris = pd.read_csv(train_path, names=COLUMN_NAMES, header=0)iris = np.array(dr_iris)fig = plt.figure(figsize=(15, 15))fig.suptitle("Anderson's Iris Data Set\n(Bule->Setosa | Red->Versicolor | Green->Virginica)"
)
for i in range(4):for j in range(4):plt.subplot(4, 4, 4 * i + (j + 1))if (i == j):plt.hist(iris[:, j], align='mid')else:plt.scatter(iris[:, j], iris[:, i], c=iris[:, 4], cmap='brg')plt.title(COLUMN_NAMES[j]) # 横坐标标签使用子图标题来实现plt.ylabel(COLUMN_NAMES[i])plt.tight_layout(rect=[0, 0, 1, 0.93])plt.show()
4.实验小结&讨论题
① 实验过程中遇到了哪些问题,你是如何解决的?
没有熟悉使用pycharm,询问了同学。
② 根据题目二的数据进行可视化结果,分析波士顿数据集中各个属性对房价的影响。
占地面积与房价大致呈线性相关。
③ Numpy和Pandas各有什么特点和优势?在应用中应如何选择?
Pandas拥有Numpy一些没有的方法,例如describe函数。其主要区别是:Numpy就像增强版的List,而Pandas就像列表和字典的合集,Pandas有索引。Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
④ 在题目基本要求的基础上,你对每个题目做了那些扩展和提升?或者你觉得在编程实现过程中,还有哪些地方可以进行优化?
完全按照题目的要求来做的。