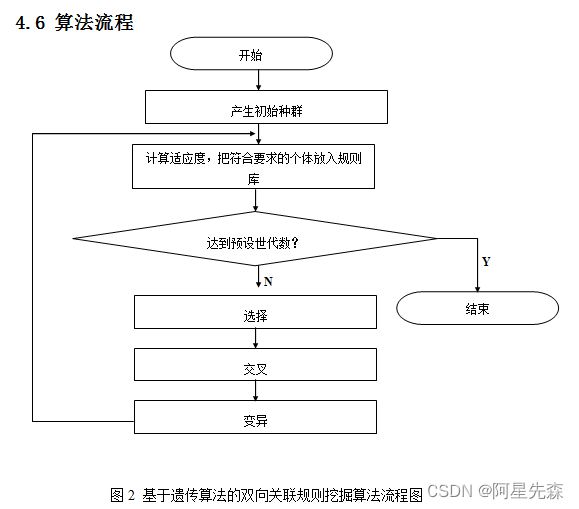
用数据挖掘技术研究了中药方剂配伍的规律。主要工作:分析了关联规则存在的问题,引入双向关联规则的概念;介绍了遗传算法的基本原理,研究了遗传算法在数据挖掘中的应用;将方剂库转换为位图矩阵,大大提高搜索效率;开发了一个基于遗传算法的中药药对药组挖掘系统。论文组织如下:介绍了研究背景和意义;阐述了相关的理论基础;提出了系统的设计方案;详细展示了基于遗传算法的双向关联规则挖掘系统的实现过程,包括位图矩阵的实现,个体的编码方法,适应度函数的设计,规则的提取,选择、交叉、变异等遗传操作的实现等;利用脾胃类方剂库对系统进行了测试,并对测试结果进行了分析。结果证明:该系统能够快速高效地从方剂库中找出具有重要意义的药对药组,对中医药的研究发展有一定意义。
我国作为最大的中药材资源国,有着传统中医药文明的发祥地的地位,但是如今正面临着诸多挑战。我国,在世界的中药市场上却未能占有基本的主导地位。反而日本、韩国等国家成功地利用现代数据挖掘科技把中药行业发展成现代产业,占据了国际市场相当的份额,因此,继承和发展中医药不仅是中医界也是全国其他科研院校和科研机构的重要课题。中药对数据挖掘就是利用药对数据库从大量的中药对中抽取隐含的、未知的、有意义的药物组配模式。中药对数据挖掘将为中医方剂理论研究和中医临床用药研究提供重要模式参考,也为方剂配伍理论研究,尤其是新药对、新药组发现研究提供新方法和现代技术手段。
关联规则是数据挖掘中的重要技术之一,它能反映在事务数据库中数据项之间同时出现的规律,并发现不同数据项之间的联系。关联规则通过量化的数字描述数据项A的出现对数据项B的出现产生的影响。例如在大型商场中牛奶的销售对面包的销售的影响,发现这样的规则不仅可以应用于商品货架设计、货存安排,而且可以根据购买模式对用户进行分类,制定相应商务决策、销售策略。
由于关联规则挖掘具有重要的现实意义,吸引了许多学者的研究,提出了众多的关联规则挖掘算法。目前,所有的关联规则挖掘算法都是基于支持度-置信度框架理论,具有较多的局限性。本文通过分析这些不足之处,引入双向关联规则的概念,实现了基于遗传算法的双向关联规则挖掘算法。
关联规则是形如A=>B的蕴涵式,挖掘关联规则分为两步:第一步是识别所有的频繁项集,即支持度不小于用户指定的最小支持度的项集;第二步是从频繁项集中构造其置信度不低于用户给定最小置信度的规则,即强规则。这种基于支持度-置信度框架理论的关联规则挖掘方法存在如下问题:
(1)不能有效地发现低支持度高置信度的有趣规则
基于支持度-置信度框架理论的关联规则挖掘方法找到的强规则必须同时满足最小支持度阈值和最小置信度阈值,但有时人们感兴趣的规则往往是低支持度高置信度的[8]。例如,超市中两物品A和B,它们的销售量虽然很低,但经常是同时被顾客购买,管理人员希望将这种低支持度高置信度的规则找出来。
(2)不能确定“相互依赖”的规则
关联规则反映A、B同时出现的概率和A出现的条件下B出现的条件概率。这样的规则只能确定A对B的“依赖”,不能同时确定B对A的“依赖”,但很多时候人们感兴趣的是“相互依赖”的规则。例如,中药的药组药对中,药之间必须是“相互依赖”的,如果药物A和B是药对,则必须是A通常与B配伍,同时B也是通常与A配伍。如果只是A通常与B配伍,但B并不常与A配伍,则A和B不是药对,因为B通常是只起辅助药性作用的药,这类药常在各种方剂中出现。用基于支持度-置信度框架理论的关联规则挖掘方法不能找出上述中药药组药对。
(3)找到的强规则并不一定是有趣的,甚至是错误的
假定对分析涉及的家用电脑和VCD播放机的事务感兴趣。在所分析的10000个事务中,6000个事务包含家用电脑,7500个事务包含VCD播放机,4000个事务同时包含家用电脑和VCD播放机。运行传统的关联规则挖掘程序,最小支持度30%,最小置信度60%,将发现下面的关联规则:
buys(X,“computer”) buys(X,“vcd-player”)
[support=40%,confidence=66%]
该规则是强关联规则。可事实上,电脑和VCD播放机是负相关的,买其中之一实际上减少了买另一种的可能性,因为购买VCD播放机的可能性是75%,大于66%。
定义1(双向关联规则):设I={i1,i2,…,im}是项的集合,任务相关的数据D是数据库事务的集合,其中每个事务T是项的集合,使得T正在上传…重新上传取消 I。每个事务有一个标示符,称作TID。设A是一个项集,事务T包含A当且仅当 A正在上传…重新上传取消T。如果A正在上传…重新上传取消I,B正在上传…重新上传取消I,并且A∩B=Æ,则形如AóB的表达式称为双向关联规则。
显然双向关联规则是同时满足A=>B和B=>A的规则。反过来也可以说同时满足A=>B和B=>A的规则是双向关联规则。所有双向关联规则Aó B有两个置信度。 一个是关联规则A=>B的置信度:
conf(A=>B) = P(B|A) = P(AB) / P(A)
另一个是关联规则B=>A的置信度:
conf(A=>B) = P(A|B) = P(AB) / P(B)
置信度conf(A=>B)表示A出现的条件下B出现的条件概率,也就是A和B同时出现的概率与A出现的概率的比值。它反映了A对B的依赖程度。它的值越大,则A对B的依赖越强;反之,值越小,则A对B的依赖越弱。如果值为1,则意味着A的每一次出现都伴随着B的出现(反过来则不一定),A对B是100%的依赖。
置信度conf(B=>A)表示B出现的条件下A出现的条件概率,也就是B和A同时出现的概率与B出现的概率的比值。它反映了B对A的依赖程度。它的值越大,则B对A的依赖越强;反之,值越小,则B对A的依赖越弱。如果值为1,则意味着B的每一次出现都伴随着A的出现(反过来则不一定),B对A是100%的依赖。
双向关联规则A óB的这两个置信度共同反映了A和B的相互依赖程度。我们很多时候对相互依赖程度高的规则——即下面定义的强双向规则感兴趣。
定义2(强双向规则):规则A=>B和B=>A同时满足最小置信度阈值(min_conf)的双向规则称作强双向规则。
下面把上述概念推广到多个项集之间的情况。
定义3(n个项集的双向关联规则):设CiÌI(2<i≤n),并且Ci∩Cj=Æ
(2<i≤n,2<j≤n,i≠j),n项集C1、C2、…,Cn的双向关联规则为同时满足C1=>C2C3…Cn、C2=>C1C3…Cn、…、Ci=>C1C2…Ci-1Ci+1…Cn、…、Cn=>C1C2…Cn-1的规则,此时C1=>C2C3…Cn、C2=>C1C3…Cn、…、Ci=>C1C2…Ci-1Ci+1…Cn、…、Cn=>C1C2…Cn-1的置信度分别为:
Conf(C1=>C2C3…Cn) = P(C2C3…Cn|C1) = P(C1C2…Cn) / P(C1)
Conf(C2=>C1C3…Cn) = P(C1C3…Cn|C2) = P(C1C2…Cn) / P(C2)
……
Conf(Cn=>C1C3…C(n-1)) = P(C1C2…C(n-1)|Cn) = P(C1C2…Cn) / P(Cn)
如果C1=>C2C3…Cn、C2=>C1C3…Cn、…、Ci=>C1C2…Ci-1Ci+1…Cn、…、Cn=>C1C2…Cn-1同时满足最小置信度阈值(min_conf),则项集C1、C2、…、Cn的双向关联规则是强双向规则。
项的集合称为项集(itemset),包含k个项的项集称为k-项集。我们把上述概念用于k-项集,可得到如下定义:
定义4(项的置信度):设Tk={I1,I2,…,Ik}是一个k-项集,Ii(1≤I≤k)是Tk的一项,则k-项集Tk的项Ii的置信度conf(Ii,Tk)为事务数据库D中包含{Ii}的事务同时包含{I1,I2,…,I(i-1),I(i+1),…,Ik}的百分比,即:
Conf(Ii,Tk) = P({I1,I2, …,I(i-1),I(i+1), ,Ik}|{Ii})=P({I1,I2, …,Ii, …,Ik})/P({Ii})
定义5(k-项集强双向规则):设Tk={I1,I2,…,Ik}是事务数据库D中一个k-项集,如果Tk的任一项的置信度都满足最小置信度阈值(min_conf),则称k-项集Tk为符合强双向规则的k-项集,简称k-项集强双向规则。
遗传算法(Genetic Algorithm, GA)是近几年发展起来的一种崭新的全局优化算法。1962年霍兰德(Holland)教授首次提出了GA算法的思想,它借用了仿真生物遗传学和自然选择机理,通过自然选择、遗传、变异等作用机制,实现各个个体的适应性的提高。从某种程度上说遗传算法是对生物进化过程进行的数学方式仿真。
这一点体现了自然界中"物竞天择、适者生存"进化过程。与自然界相似,遗传算法对求解问题的本身一无所知,它所需要的仅是对算法所产生的每个染色体进行评价,把问题的解表示成染色体,并基于适应值来选择染色体,使适应性好的染色体有更多的繁殖机会。在算法中也即是以二进制编码的串。并且,在执行遗传算法之前,给出一群染色体,也即是假设解。然后,把这些假设解置于问题的“环境”中,也即一个适应度函数中来评价。并按适者生存的原则,从中选择出较适应环境的染色体进行复制, 淘汰低适应度的个体,再通过交叉,变异过程产生更适应环境的新一代染色体群。对这个新种群进行下一轮进化,至到最适合环境的值。
由于遗传算法是由进化论和遗传学机理而产生的搜索算法,所以在这个算法中会用到很多生物遗传学知识,下面是将会用到的一些术语说明:
一、染色体(Chromosome)
染色体又可以叫做基因型个体(individuals),一定数量的个体组成了群体(population),群体中个体的数量叫做群体大小。
二、基因(Gene)
基因是串中的元素,基因用于表示个体的特征。例如有一个串S=1011,则其中的1,0,1,1这4个元素分别称为基因。
三、适应度(Fitness)
各个个体对环境的适应程度叫做适应度(fitness)。为了体现染色体的适应能力,引入了对问题中的每一个染色体都能进行度量的函数,叫适应度函数. 这个函数是计算个体在群体中被使用的概率。
四、种群(population)
染色体带有特征的个体的集合称为种群。该集合个体数称为种群个体的大小。
由于事务数据库一般只具有对大量数据的存取、检索功能,对于用户的一般性的使用可以满足,然而,正是由于数据库中存放了大量的数据,不同的数据项,以及多个数据项之间还存在有大量的隐含的、未知的、有意义的数据关系,这些关系对于用户有着及其重要的作用,所以数据挖掘便在此情况下产生了。
遗传算法是数据挖掘技术中的一个重要算法。这是由于它具有快捷、简便、鲁棒性强、适于并行处理以及高效、实用等显著特点,在各类结构对象的优化过程中显示出明显的优势。它的思想源于生物遗传学和适者生存的自然规律,是具有“生存+检测”的迭代过程的搜索算法。遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;初始种群编码、初始群体个数的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
与传统的搜索方法相比,遗传算法具有如下特点:
(1)搜索过程不直接作用在变量上,而是在参数集进行了编码的个体。此编码操作,使得遗传算法可直接对结构对象(集合、序列、矩阵、树、图、链和表)进行操作。
(2)搜索过程是从一组解迭代到另一组解,采用同时处理群体中多个个体的方法,降低了陷入局部最优解的可能性,并易于并行化。
(3)采用概率的变迁规则来指导搜索方向,而不采用确定性搜索规则。对搜索空间没有任何特殊要求,只利用适应性信息,不需要导数等其它辅助信息,适应范围更广。
中国自古以来就有着传统中医药文明的发祥地的地位,中药是我国特有的资源,但是中国本土中医学长期以来的发展并不是很大,在国际医学界就更不具有很强的地位。多年的时间过去了,中药方剂的更新和发展并没有很大的变化,很多都还建立在很久以前就有的方剂基础之上,没有出现比较多的较新的方剂,应用遗传算法的数据挖掘系统在此情况下可以发挥着及其重要的作用。通过数据系统能够在药对数据库的大量数据中,找到很多隐含的、未知的、并很有应用价值的药对药组以及很多的有意义的药物组配的规则和模式。中药对数据挖掘还将为中医方剂理论研究和中医临床用药研究提供重要模式参考,也为方剂配伍理论研究,尤其是新药对、新药组发现研究提供新方法和现代技术手段。
在系统进行数据挖掘过程中,为了减少对事务数据库的扫描、提高挖掘效率,本文先把事务数据库转化成位图矩阵,然后再在此位图矩阵上挖掘有趣的强双向关联规则。下面是对位图矩阵模型的描述。
用Ik(k为自然数)表示事务数据库中的一项,I1、I2、…、Ik、…、In表示事务数据库中的所有项。用Tj(i1,i2,…,ik,…,in)表示事务数据库中的一个事务,ik对应Ik,占用1位(bit),当事务Tj含有Ik这项时,Tj的ik位为1,否则为0,所以事务Tj可以用位图i1i2…ik…in来表示。T1、T2、…、Tj、…、Tm表示事务数据库中所有的事务,T1、T2、…、Tj、…、Tm都可以用位图i1i2…ik…in来表示,这样所有这些位图就构成了事务数据库的位图矩阵。
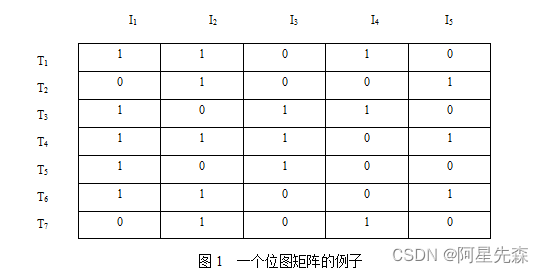
图1就是一个位图矩阵。该位图矩阵对应的事务数据库含I1、I2、I3、I4、I5共5个项,含T1、T2、T3、T4、T5、T6、T7共7个事务。事务T1的位图为11010,所以含I1、I2、I4三个项;事务T2的位图为01001,所以含I2、I5两个项;事务T3的位图为10110,所以含I1、I3、I4三个项;事务T4的位图为11101,所以含I1、I2、I3、I5四个项;事务T5的位图为10100,所以含I1、I3两个项;事务T6的位图为11001,所以含I1、I2、I5三个项;事务T7的位图为01010,所以含I2、I4两个项。
得到事务数据库的位图矩阵后,就很容易求出某双向关联规则的支持度计数。例如,要求出图1所对应事务数据库中I2和I4同时出现的次数。先设计只包含I2、I4两个项的事物T,其位图为01010。判断由I2和I4构成的规则是否出现在事务Tk中,只需判断T的位图与Tk的位图按位相与操作后得到的新位图是否与T的位图相同。如果相同,则说明事物Tk包含由I2和I4构成的规则;反之则不是。通过用T的位图与事务数据库中每一事务的位图进行上述操作,可以求出由I2和I4构成的规则的支持度计数。这种方法是高效的,理由有两点:一是事务数据库的位图矩阵相对于事务数据库本身在尺寸上大大减小了;二是按位相与运算速度很快。
本设计使用的后台数据库为SQL2000,用到的数据表为药物表和方剂表。位图矩阵的建立是在查询数据库中数据的基础上产生的。
在查询数据库得到的位图矩阵中,行表示方剂,列表示此数据库中的药物,矩阵中的数据项由1和0表示,假如R[i,j] = 1(R表示位图矩阵,i表示横坐标,j表示纵坐标),表示第i个方剂中含有第j位对应的药物。建立位图矩阵的步骤如小:
(1)使用sql查询语句,通过查询方编号得到方剂表中的方剂的总数量,以此得到位图矩阵的行,也就相当于上一小节提到的事务Tk。
String queryId = "select 方编号 from 方剂表";
Class.forName("com.microsoft.jdbc.sqlserver.SQLServerDriver");
//通过 JDBC建立数据库连接
Connection dbConn = DriverManager.getConnection(dbURL, userName, userPwd);
//连接到数据库,提供相应的用户名、密码
Statement stmt = dbConn.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE, ResultSet.CONCUR_UPDATABLE);
//用dbConn连接创建SQL语句对象
ResultSet rsId = stmt.executeQuery(queryId);
while(rsId.next()){
drugId[i++] = rsId.getString(1); //把方编号存入数组
}
经过以上语句,此时得到了位图矩阵所需要的行的信息,即方编号,并把此数据存放到名字为drugId的数组中,数组中存放的数据的个数即为方剂的数量,也就是以后用到的位图矩阵的行数。
(2)接下来需要得到位图矩阵的列数和列所对应的药物的名称。
String drugName[]= new String[405];
定义存放药名的数组。
String queryName = "select 药名 from 药物表";
定义查询药物表中药名的sql语句。
ResultSet rsName = stmt.executeQuery(queryName);
定义存放查询得到的结果集的变量。
int p = 0;
while(rsName.next()){
if(p==0){
drugName[i++] = rsName.getString(1);
}
此句判断如果数组中没有数,则直接放入该数。
else{
int j;
for(j=0;j<i;j++){
if(drugName[j].equals(rsName.getString(1)))
break;
}
此循环语句用于判断drugName数组中是否存有与当前药名相同的数据,如果有就直接跳出循环,否则一直执行到所存放的数据处。
f(j==i){
drugName[i++] = rsName.getString(1);
}
如果没有重复数据,则把当前药名存入数组中。
}
p++;
}
由以上语句得到了位图矩阵的列的信息,列的每一位表示一味药,并且药名存放在drugName数组中,此数组中数据的个数即为位图矩阵列的个数。
(3)在行信息和列信息都产生好之后,第三步是产生矩阵的数据,把个矩阵构造完成。
for(i=0;i<1060;i++){
外层for循环控制位图矩阵的行,根据每行为一个方剂,做为一个整体确定每行中的数据项的值。
String queryName1 = "select 药名 from 药物表 where 方编号="+drugId[i];
申明sql语句,用于指定的方编号,查询得到对应方剂中所存放的药物。
ResultSet rsName1 = stmt.executeQuery(queryName1);
申明rsName1结果集对象,每次查询所得到的值都存放在其中,方便以后的数据取用。
while(rsName1.next()){
temp[l++] = rsName1.getString(1);
}
把每次查找出的药名存放在临时数组'temp'中,用于矩阵数据的确定。
int k;
for(k=0;k<l;k++){
外层for循环用于控制数组temp的下标。
for(j=0;j<405;j++){
内层for循环用于控制数组drugName的下标。
if(temp[k].equals(drugName[j])){
matrix[i][j] = '1';
}
else if(matrix[i][j]=='1'&&!(temp[k].equals(drugName[j]))){
}
else {
matrix[i][j] = '0';
}
判断当temp数组和drugName数组的值相等时,对应的位图矩阵的值为字符1,当当前位图矩阵的值为字符1,但是数组temp与drugName数组的不等时,不作任何动作,当以上条件都不满足时,位图矩阵对应位置的值为字符0。
}
}
经过以上的程序段,就构造出了一个由0和1作为其每项值的矩阵,此矩阵就是所要构建的位图矩阵。位图矩阵的构造完成,为以后的运算带来了不用反复查询事务数据库的繁琐,提高了算法的效率,增加了运算的速度。
用遗传算法进行双向关联规则挖掘,编码是要解决的首要问题。编码方法不仅决定了个体排列形式,而且决定了个体从搜索空间的基因型变换到解空间的表现型时的解码方法。编码方法还影响到交叉、变异等遗传操作。由于前面我们已经用位图矩阵来描述事务数据库,对双向关联规则的挖掘可以直接在位图矩阵上进行。因此本文理所当然采用二进制编码,编码串的长度为事务数据库中项的个数。由前面产生的位图矩阵可以知道,编码串的长度为405。
产生初始种群的代码如下:
for(i=0;i<50;i++){
int t = (int)(Math. random()*28);
//随机产生每行字符数组(个体染色体)中'1'的个数.
while(true){ //如果是0就重新生成.
if(t==0){
t = (int)(Math.random()*28);
}
else
break;
}
int tempLoc[] = new int[t];
//int数组装随机产生的数的下标数(即产生'1'的位置).
for(j=0;j<405;j++){
radomDrug[i][j] = '0';
}
for(j=0;j<t;j++){
int loc;
if(j==0){
loc = (int)(Math.random()*405);
tempLoc[j] = loc;
radomDrug[i][loc] = '1';
}
else{
loc = (int)(Math.random()*405);
for(p=0;p<j;p++){
if(loc==tempLoc[p]){
loc = (int)(Math.random()*405);
p = 0;
}
}
if(p==j){
tempLoc[j] = loc;
radomDrug[i][loc] = '1';
}
}
}
} //产生随机数完毕。
产生初始种群,也就是生成随机数的过程。首先用一个整形变量t存放每次随机产生的1 的个数,因为,通过查询药物数据库中方剂表可以得知,整个方剂表中,所有方剂中的药物最多不超过27味,所以,需要用一个变量控制每次随机产生的个体(随机数)中1的个数。在t产生之后,紧接着就是产生每个个体中1的位置,在此处,代码中所体现的就是用用一个整形数组tempLoc存放,而数组中所存数据的个数则是上一步随机产生的变量t的值来控制,并且在产生除第一个位置的时候,每产生一个位置后都首先与之前tempLoc数组中的数判断,如果当前产生的数与tempLoc数组中的数相同,则要求重新随机产生,直到没有重复为止。位置得到以后,所要做的就是对应位置上项的值给赋值为1,其余的赋值为0,这样经过几层循环的运算后就得到了所要进行遗传算法运算的初始种群了。
遗传算法中使用适应度来度量种群中各个体在优化计算中可能达到或有助于找到最优解的优良程度,适应度较高的个体遗传到下一代的概率就较大。适应度函数直接影响问题求解的效率。
本文挖掘的双向关联规则,要求规则中任一项的置信度都必须满足最小置信度阈值(min_conf)。例如, C1、C2、…、Cn的双向关联规则须同时满足:
P(C1C2…Cn) / P(C1) ≥ min_conf
P(C1C2…Cn) / P(C2) ≥ min_conf
……
P(C1C2…Cn) / P(Cn) ≥ min_conf
……
显然只需满足:
P(C1C2…Cn) / max(P(C1),P(C2),…,P(Cn)) ≥ min_conf
即可。max(P(C1), P(C2),…,P(Cn))表示P(C1), P(C2),…,P(Cn)之中的最大值。
于是,将适应度函数设计为:
F(rc1c2…cn) = count(C1C2....Cn) / max(count(C1), count(C2) ,…count(Cn))
其中, rc1c2…cn为C1、C2、…,Cn构成的双向关联规则,count(C1C2....Cn)为C1C2....Cn 的支持度计数,count(C1)、count(C2) 、…、count(Cn) 分别为C1、C2、…、Cn的支持度计数, max(count(C1), count(C2) ,…count(Cn))表示count(C1),、count(C2), 、…、count(Cn), 中的最大值。
由以上的表达式可以得出,要计算种群中个体的适应度首先要计算出
count(C1C2…Cn)和max(count(C1), count(C2) ,…count(Cn)),它们两个作为计算适应度函数的分子与分母。它们两个表达式对应于位图矩阵和种群的关系是以下关系:
count(C1C2…Cn)的计算是通过把每个随机数(种群个体)与位图矩阵中的每个方剂对应的数(每项个值所组成的数)进行与操作,计算其结果等于随机数自身的次数。
count(Ci)是对在位图矩阵的第i列中所有1的累加,即计算在位图矩阵的第i列中为1的次数。max(count(C1), count(C2) ,…count(Cn))则是表示所有累加值中的最大数。
由于在本设计中,使用的编程语言为java语言,为了方便随机个体与位图矩阵中的每项的值进行比较,采用了位图矩阵以及得到的种群都是由0、1字符组成的方式,并不是有真正的二进制数表示。因此,在进行上面提到的个体与位图矩阵的每行的与操作时,是一项一项的比较,并不是真正意义上的与操作。在设计中进行与操作的方式是,判断个体中含有‘1’的位置在位图矩阵的每行对应位置是否也会为‘1’,如果判断为真就相当于进行的与操作等于它本身,则count需要加1,如果某一位置上的‘1’在位图矩阵中的对应位置为‘0’,则相当于进行的与操作不等于它本身,从而count不需要加1。
因此,第一,对位图矩阵中的所有值为‘1’的位置进行记录,此处是用的向量组进行记录,每个向量记录每行中的为‘1’的位置。外循环控制行数,在每次外循环时就给向量分配内存空间,内循环控制每行中的下标的移动,随着下标的移动,查询到值为 ‘1’的下标,并记录到向量中。
Vector Mloc[] = new Vector[1060];
for(i=0;i<1060;i++){
Mloc[i] = new Vector();
for(j=0;j<405;j++){
if(matrix[i][j]=='1'){
Mloc[i].add(j);
}
}
}
第二,把产生的种群中的所有值为‘1’的位置进行记录,在此处同样是通过向量组进行的记录,每个向量记录每个种群个体中的‘1’的位置。
Vector Rloc[] = new Vector[50];
for(i=0;i<50;i++){
Rloc[i] = new Vector();
for(j=0;j<405;j++){
if(radomDrug[i][j]=='1'){
Rloc[i].add(j);
}
}
}
第三,根据位图矩阵和初始种群中‘1’的位置得到的两个向量数组Mloc和Rloc,每次把Rloc数组中的一向量与数组Mloc中的所有向量比较,每次都比较两个向量中所存放的‘1’的位置,如果Rloc中的向量所存放的数在Mloc中的向量都有相同的数存在,即种群个体与位图矩阵每行所组成的数进行与操作的值等于种群个体自身,则使用数组count记录下每次与操作都等于其自身的次数。
for(i=0;i<50;i++){
flag = false; count[i] = 0;
for(p=0;p<1060;p++){
for(j=0;j<Rloc[i].size();j++){
if(Mloc[p].contains(Rloc[i].get(j))){
flag = true;
}
else{
flag = false;
}
}
if(flag){
count[i]++;
}
}
}
经过此段代码的运算,数组count存放了每个初始种群个体与位图矩阵进行与操作等于其自身的次数,即得到了计算适应度函数的分子的值。
第四,计算适应度的分母,即计算出每个初始种群个体中为‘1’的位置在位图矩阵对应列中出现的次数,然后通过max函数计算出刚计算出的次数中的最大值,最后存放计算出的每个最大值在数组中,用于适应度的计算。
for(i=0;i<50;i++){
int countR[] = new int[405];
//countR存放随机数中每行中的为1的数所对应位图矩阵中此列的1个个数。
int k=0;
for(j=0;j<405;j++){
if(radomDrug[i][j]=='1'){
countR[k++] = countD[j];
}
}
int max = 0;
for(int tt=0;tt<k;tt++){
//找到每行中为1的数在位图矩阵中对应列出现的个数的最大值。
if(max<Math.max(max,countR[tt])){
max = countR[tt];
}
}
countMax[i] = max;
}
第五,把上面计算得到的分子分母值进行计算,得到每个初始种群个体的适应度。
float fit[] = new float[50]; //计算选择概率放在fit数组中.
int fitD[] = new int[50]; //计算适应度,并保存在fitD数组中.
for(i=0;i<50;i++){
fit[i] = ((float)count[i])/((float)countMax[i]);
fitD[i] = (int)(fit[i]*100);
System.out.print(fit[i]+"_ "+fitD[i]+". ");
} //计算出随机数的置信度。
由于挖掘的双向关联规则只要满足最小置信度阈值就是需要的规则,因此在每一代种群计算适应度后,将其中适应度大于或等于min_conf,则把该个体放入规则库中。放入时判断规则库中是否已存在该个体,如果存在,则不放入,在设计中,min_conf是通过输入框输入的到,并把值存放到变量getV中。
for(i=0;i<50;i++){
if(fitD[i]>=getV){
if(z==0){
for(j=0;j<405;j++){
rule[h][j] = radomDrug[i][j];
}
rfitD[h] = fit[i];
h++;
}
else{
int k;
for(k=0;k<50;k++){
for(j=0;j<h;j++){
if(gener[k].equals(ruleStr[j])==false){
continue;
}
else{
break;
}
}
if(j==h){
for(j=0;j<405;j++){
rule[h][j] = radomDrug[i][j];
}
rfitD[h] = fit[i];
h++;
}
}
}
}
}
遗传操作主要包括选择、交叉和变异。
(1)选择(selection)
本文的选择操作采用轮盘赌选择法,将个体的适应度与种群的总适应度(种群所有个体的适应度之和)相比,得到该个体的相对适应度,所有个体的相对适应度之和为1。使用个体的相对适应度来作为其在选择操作中被选中的概率,每一轮选择产生一个[0,1]均匀随机数,将该随机数作为选择指针来确定被选个体,适应度大的个体被选中的概率大,参与复制、交叉生成新一代种群的机会就大,反映了自然界生物进化“物竞天择,适者生存”的自然法则。
在本设计中,轮盘赌选择法的实现方式是,首先计算出总的适应度的和sum,然后随机产生1到sum之间的数,根据产生的随机数得到对应的种群个体,此方式正是模拟了遗传的特点,适应度大的被选中的几率就大,反之被选中的几率就小。下面此循环就是计算适应度的总和。
for(i=0;i<50;i++){
sum += fitD[i];
}
以下代码则是轮盘赌算法的实现:
for(i=0;i<50;i++){ //根据随机选择个体.
n = ((int)(Math.random()*val))+1;
sum = 0; j = 0; m = 0;
while(true){
sum += fitD[j];
if(sum>=n){
break;
}
else
m++; j++;
}
gener[i] = Ch[m];
}
最后,把根据轮盘赌算法选中的种群个体存放到gener数组中。
(2)交叉(crossover)
实际应用的事务数据库中项的个数往往比较大,即编码串比较长。为了促进解空间的搜索,防止过早地收敛,本文交叉操作的交叉点数由 确定,其中的n为遗传算法的一个输入参数,在运行时设置,可以设置为10、20等。交叉位随机产生。例如,图1所对应的事务数据库,如果n设置成10,则为单点交叉,对于父代个体1“11010”和父代个体2“01001”,若随机产生的交叉点是3,则交叉后产生的子代个体1和子代个体2分别为“11001”、“01010”。
染色体的交叉的实现代码如下:
while(i<jcha/2){
m = (int)(Math.random()*50);
//选择进行交换的两个体的下标m,n.
int ra = (int)(Math.random()*50);
n = (m+ra)%50;
p = (int)(Math.random()*405);
//p值为染色体交换位.
CharSequence rt1 = gener[m].subSequence(p,gener[m].length());
//第p位后的染色体交换.
CharSequence rt2 = gener[n].subSequence(p,gener[n].length());
gener[m] = gener[m].replace(gener[m].subSequence(p,gener[m].length()),rt2);
gener[n] = gener[n].replace(gener[n].subSequence(p,gener[n].length()),rt1);
i++;
}
(3)变异(mutation)
因为初始种群的产生是随机的,所以事务数据库中所有的项并不一定都出现在初始种群中,这会造成部分规则的遗漏以及过早收敛。因此本文进行变异操作时,先以一概率随机选择个体,选中后,随机产生变异位,对变异位作翻转操作。
变异的实现,在本设计中是通过随机产生需要进行变异的种群个体和选中个体中需要变异的的染色体位置,然后把此位置对应的值进行翻转,把‘1’变成‘0’,或者把值为‘0’的变成‘1’。
for(j=0;j<byg;j++){
p = (int)(Math.random()*405); //个体中染色体变异.
for(k=0;k<10;k++){
p1[k] = (((int)(Math.random()*405))+p)%405;
}
int p2 = (int)(Math.random()*50); //产生变异的个体的位置.
char bianyi[] = gener[p2].toCharArray();
for(k=0;k<10;k++){
if(bianyi[p1[k]]=='1'){
bianyi[p1[k]] = '0';
}
else{
bianyi[p1[k]] = '1';
}
}
for(k=0;k<405;k++){ //变异后再转换成字符串.
if(k==0){
gener[p2] = String.valueOf(bianyi[k]);
}
else{
gener[p2] += String.valueOf(bianyi[k]);
}
}
}
测试
本论文将上述方法用于中药配伍规律的研究中,从大量古今中药方剂中挖掘药对药组。药对是临床上相对固定的两味药物的配伍形式,是中药配伍中的最小单位;药组是临床上相对固定的两味药物以上的配伍形式,也可以把它看作不限于两味药物的特殊药对,这些药对药组对于研究中药配伍规律具有重要意义。
本文实验基于脾胃类方剂库。该方剂库含1060首方剂,涉及405味药。实验采用了基于遗传算法的双向关联规则挖掘算法来寻找药对药组。
此系统具有的数据挖掘功能,其中有两个选择的模式,一是一般模式状态下的双向关联规则挖掘,用户可以输入相应的最小置信度和遗传的代数。
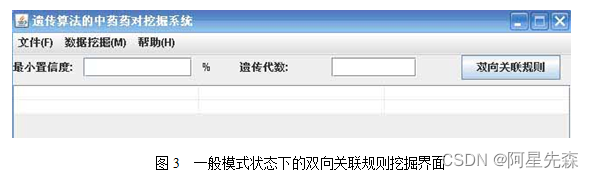
二是高级设置模式下的双向关联规则挖掘,用户可以输入初始种群个数、遗传代数、最小置信度和变异率四个参数。
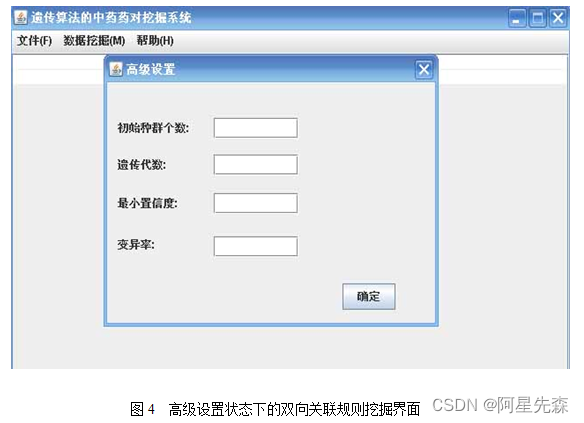
在以上两个模式下,根据输入的参数运行得到的结果的状态如下所示:
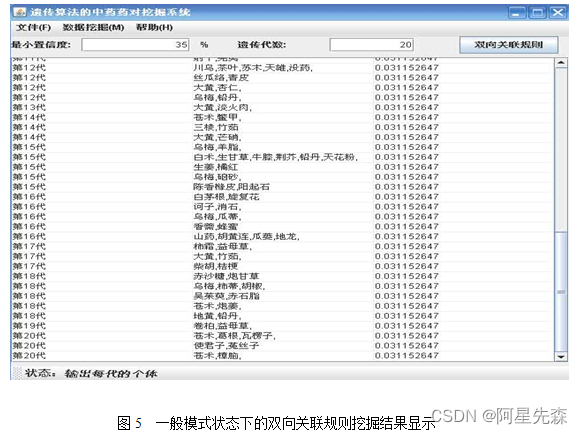
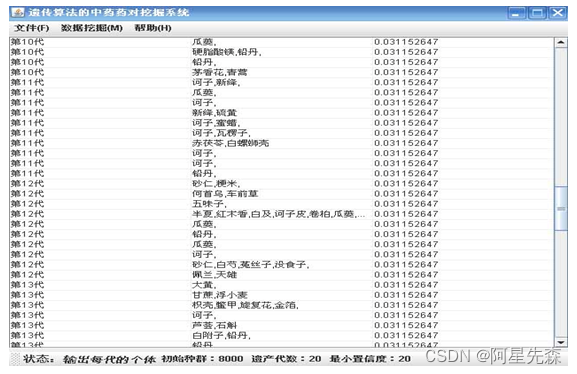
由以上两种模式下运行得到的结果表明:
(1)用基于遗传算法的双向关联规则挖掘算法得到的药对药组,每味药都满足最小置信度要求,所以那些高支持度低置信度药就被排除了,得到的药对药组都具有重要意义。
(2)基于遗传算法的双向关联规则挖掘算法能找出了有意义的药对药组。
(3)基于遗传算法的双向关联规则挖掘算法不需要反复扫描事务数据库,挖掘规则的速度大大提高。