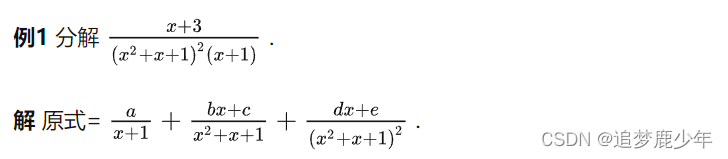Compaction是MOR表的一项核心机制,Hudi利用Compaction将MOR表产生的Log File合并到新的Base File中。本文我们会通过Notebook介绍并演示Compaction的运行机制,帮助您理解其工作原理和相关配置。
1. 运行 Notebook
本文使用的Notebook是:《Apache Hudi Core Conceptions (4) - MOR: Compaction》,对应文件是:4-mor-compaction.ipynb,请先修改Notebook中的环境变量S3_BUCKET,将其设为您自己的S3桶,并确保用于数据准备的Notebook:《Apache Hudi Core Conceptions (1) - Data Preparation》已经至少执行过一次。Notebook使用的Hudi版本是0.12.1,Spark集群建议配置32 vCore / 128 GB及以上。
2. 核心概念
Compaction负责定期将一个File Slice里的Base File和从属于它的所有Log File一起合并写入到一个新的Base File中(产生新的File Slice),唯有如此,MOR表的日志文件才不至于无限膨胀下去。以下是与Compaction有关的几项重要配置,在后面的介绍中我们会逐一介绍它们的作用:
| 配置项 | 默认值 |
|---|---|
| hoodie.compact.inline | false |
| hoodie.compact.schedule.inline | false |
| hoodie.compact.inline.max.delta.commits | 5 |
2.1. 排期与执行
Compaction的运行机制包括:排期(Schedule)和执行(Execute)两个阶段。排期阶段的主要工作是划定哪些File Slices将参与Compaction,然后生成一个计划(Compaction Plan)保存到Timeline里,此时在Timeline里会出现一个名为compaction的Instant,状态是REQUESTED;执行阶段的主要工作是读取这个计划(Compaction Plan)并执行它,执行完毕后,Timeline中的compaction就会变成COMPLETED状态。
2.2. 同步与异步
从运行模式上看,Compaction又分同步、异步以及半异步三种模式(“半异步”模式是本文使用的一种叫法,为的是和同步、异步两种模式的称谓对齐,Hudi官方文档对这一模式有介绍,但没有给出命名),它们之间的差异主要体现在从(达到规定阈值的某次)提交(Commit)到排期(Schedule)再到执行(Execute)三个阶段的推进方式上。在Hudi的官方文档中,交替使用了Sync/Async和Inline/Offline两组词汇来描述推进方式,这两组词汇是有微妙差异的,为了表述严谨,我们使用同步/异步和立即/另行这两组中文术语与之对应。以下是Compaction三种运行模式的详细介绍:
- 同步模式(Inline Schedule,Inline Execute)

同步模式可概括为:立即排期,立即执行(Inline Schedule,Inline Execute)。在该模式下,当累积的增量提交(deltacommit)次数到达一个阈值时,会立即触发Compaction的排期与执行(排期和执行是连在一起的),这个阈值是由配置项 hoodie.compact.inline.max.delta.commits 控制的,默认值是5,即:默认情况下,每5次增量提交就会触发并执行一次Compaction。锁定同步模式的配置是:
| 配置项 | 设定值 |
|---|---|
| hoodie.compact.inline | true |
| hoodie.compact.schedule.inline | false |
- 异步模式(Offline Schedule,Offline Execute)

异步模式可概括为:另行排期,另行执行(Offline Schedule,Offline Execute)。在该模式下,任何提交都不会直接触发和执行Compaction,除非使用了支持异步Compaction的Writer,否则用户需要自己保证有一个独立的进程或线程负责定期执行Compaction操作。Hudi提供了四种运行异步Compaction的方式:
- 通过hudi-cli或提交Spark作业驱动异步Compaction
- 提交Flink作业驱动异步Compaction
- 在HoodieDeltaStreamer中配置并运行异步Compaction
- 在Spark Structured Streaming中配置并运行异步Compaction
在后面的测试用例中,我们将使用第一种方式演示如何进行异步的Compaction排期与执行。和同步模式一样,在异步模式下,同样是当增量提交(deltacommit)次数达到一定的阈值时才会触发排期,这个阈值依然是hoodie.compact.inline.max.delta.commits。
异步模式面临的场景要比同步模式复杂一些,同步模式下,每次提交时都会检查累积的提交次数是否已达规定阈值,所以在同步模式下,每次排期涵盖的增量提交数量基本是固定的,就是阈值设定的次数,但是在异步模式下,由于发起排期和增量提交之间没有必然的协同关系,所以在发起排期时,Timeline中可能尚未积累到足够数量的增量提交,或者增量提交数量已经超过了规定阈值,如果是前者,不会产生排期计划,如果是后者,排期计划会将所有累积的增量提交涵盖进来。锁定异步模式的配置是:
| 配置项 | 设定值 |
|---|---|
| hoodie.compact.inline | false |
| hoodie.compact.schedule.inline | false |
- 半异步模式(Inline Schedule,Offline Execute)

半异步模式可概括为:立即排期,另行执行(Inline Schedule,Offline Execute),即:排期会伴随增量提交(deltacommit)自动触发,但执行还是通过前面介绍的四种异步方式之一去完成。锁定半异步模式的配置是:
| 配置项 | 设定值 |
|---|---|
| hoodie.compact.inline | false |
| hoodie.compact.schedule.inline | true |
3. 同步Compaction
3.1. 关键配置
《Apache Hudi Core Conceptions (4) - MOR: Compaction》的第1个测试用例演示了同步Compaction的运行机制。测试用的数据表有如下几项关键配置:
| 配置项 | 默认值 | 设定值 |
|---|---|---|
| hoodie.compact.inline | false | true |
| hoodie.compact.schedule.inline | false | false |
| hoodie.compact.inline.max.delta.commits | 5 | 3 |
| hoodie.copyonwrite.record.size.estimate | 1024 | 175 |
这些配置项在介绍概念时都已提及,通过这个测试用例将会看到它们组合起来的整体效果。
3.2. 测试计划
该测试用例会先后插入或更新三批数据,然后进行同步的Compaction排期和执行,过程中将重点观察时间线和文件布局的变化,整体测试计划如下表所示:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
|---|---|---|---|
| 1 | Insert | 96MB | +1 Base File |
| 2 | Update | 788KB | +1 Log File |
| 3 | Update | 1.2MB | +1 Log File +1 Compacted Base File |
提示:我们将使用色块标识当前批次的Instant和对应存储文件,每一种颜色代表一个独立的File Slice。
3.3. 第1批次
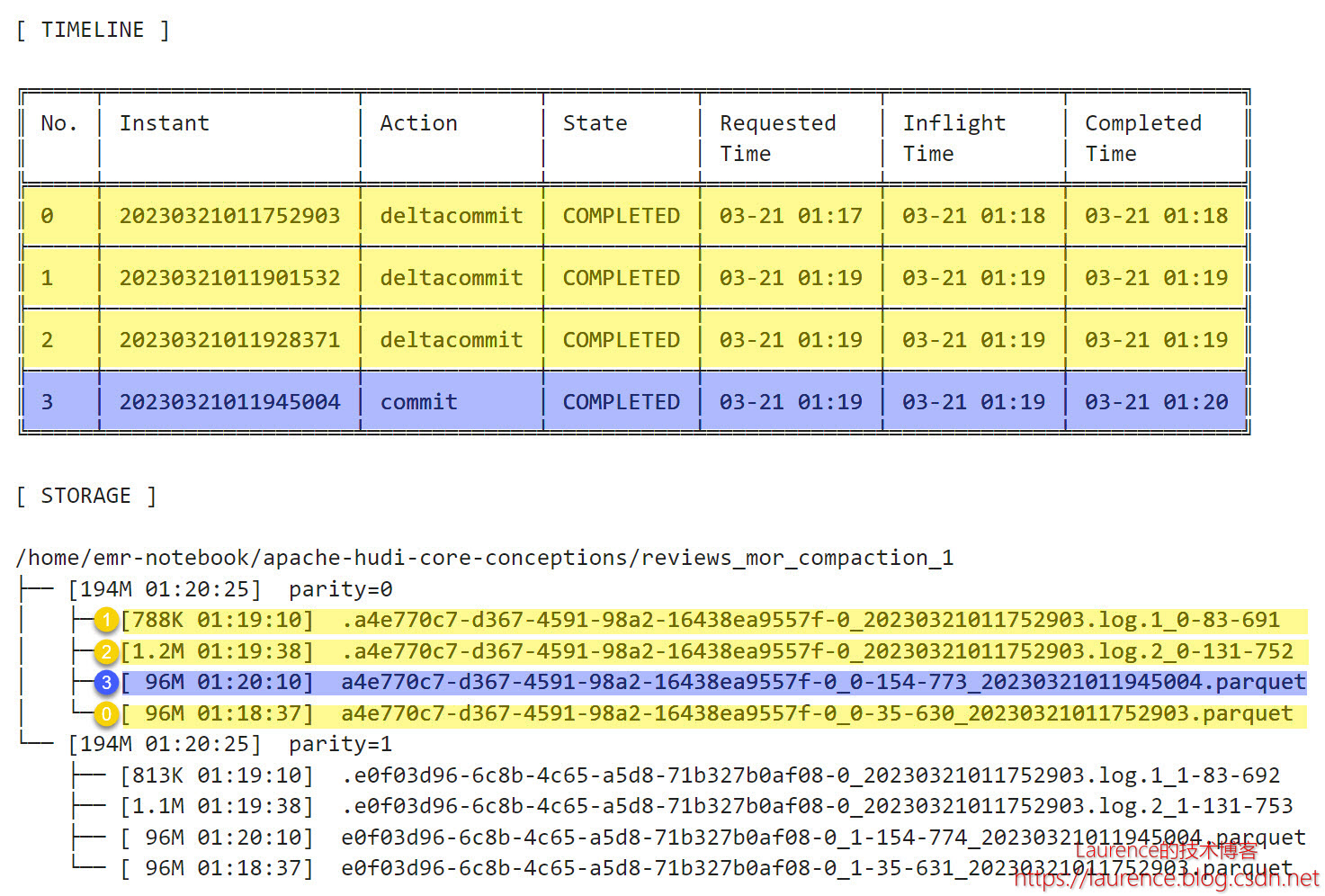
第1批次单分区写入96MB数据,Hudi将其写入到一个Parquet文件中,第一个File Group随之产生,它也是后续 Log File的Base File。需要注意的一个细节是:对于MOR表来说,只有进行Compaction的那次提交才会被称为“commit”,在Compaction之前的历次提交都被称作“deltacommit”,即使对于新建Base File写入数据的那次提交也是如此,就如同这里一样。
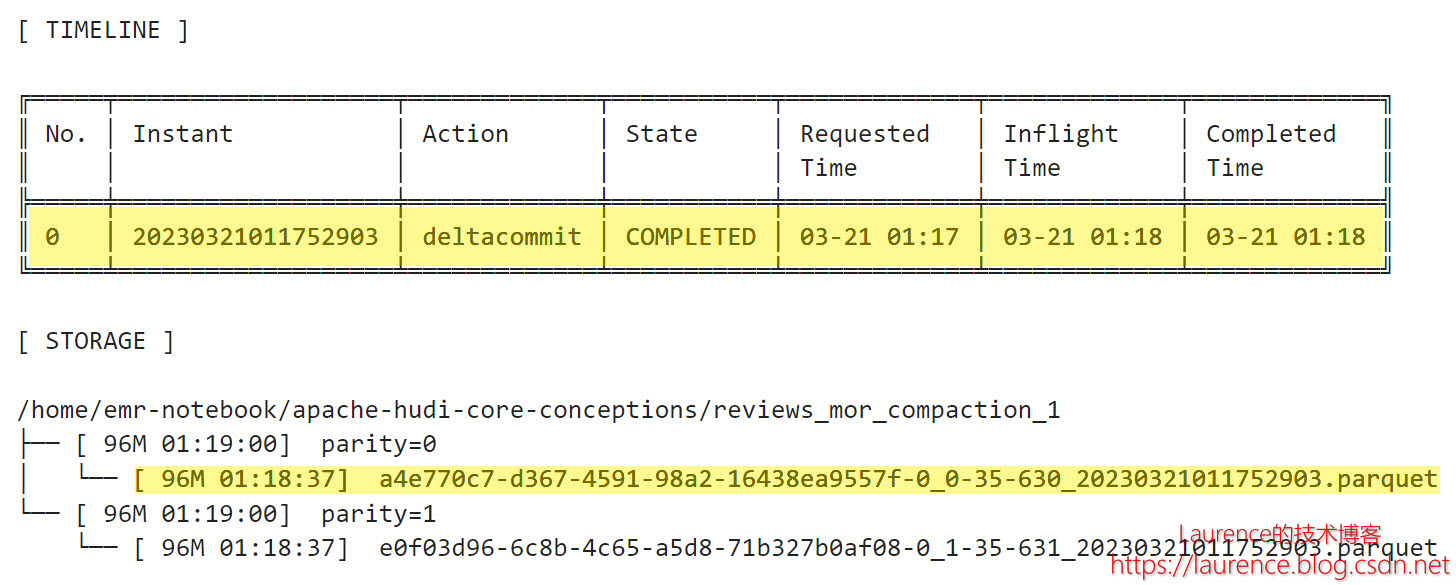
3.4. 第2批次
第2批次更新了一小部分数据,Hudi将更新数据写入到了Log文件中,大小788KB,fileVersion是1,它从属于上一步生成的Parquet文件,即Parquet文件是它的Base File ,这个Log文件的fileId和尾部的时间戳(baseCommitTime)与Parquet文件是一样的。当前的Parquet文件和Log文件组成了一个File Slice。
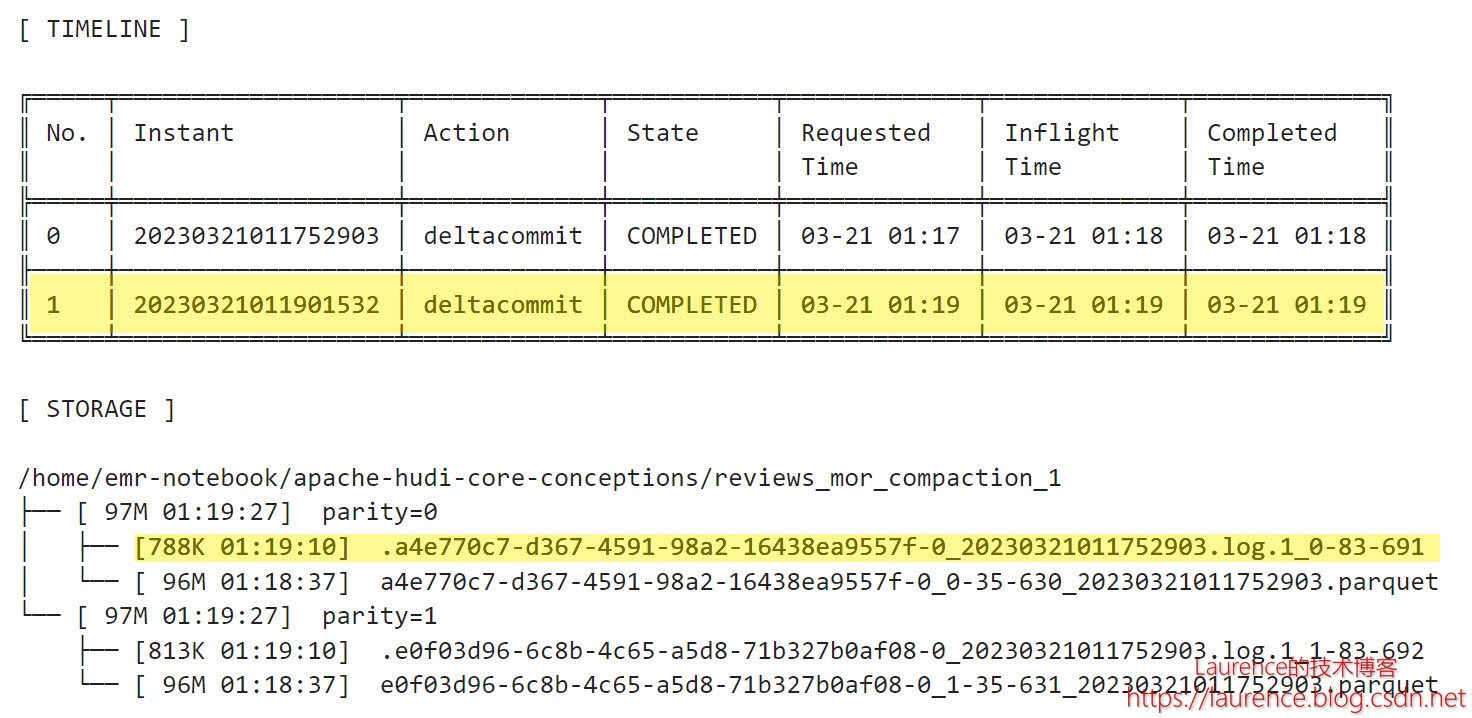
3.5. 第3批次
第3批次再次更新了一小部分数据,Hudi将更新数据又写入到一个Log文件中,大小1.2MB,fileVersion是2。与上一个Log文件一样,fileId和尾部的时间戳(baseCommitTime)与Parquet文件一致,所以它也是Parquet文件的Delta Log,且按Timeline排在上一个Log文件之后。当前的File Slice多了一个新的Log文件。但是,不同于第2批次,第3批次的故事到这里还没有结束,在该测试用例中,当前测试表的设置是:每三次deltacommit会触发一次Compaction,因此,第3次操作后就触发了第1次的Compaction操作:
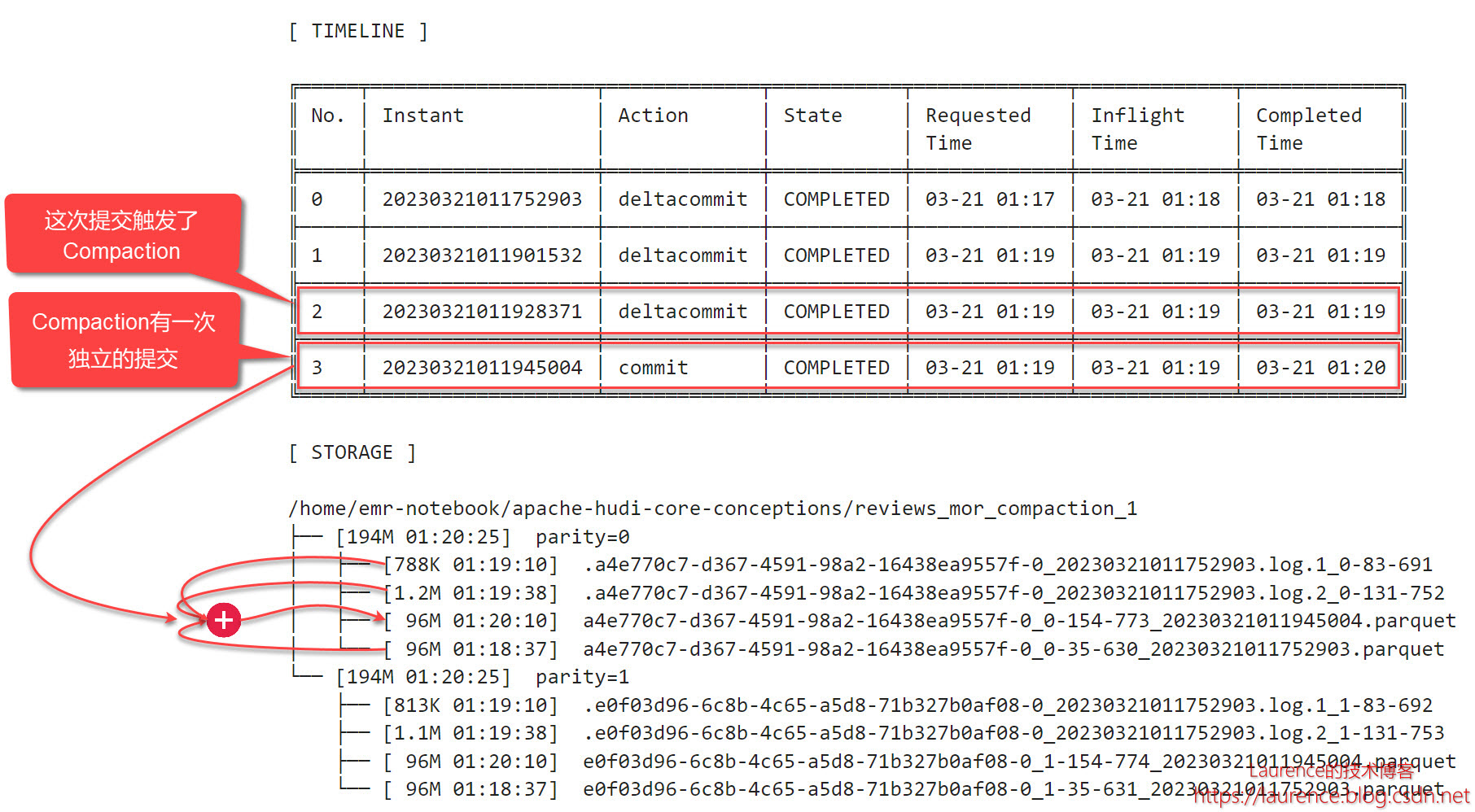
于是,在Timeline上出现了一个commit(No.3),同时,在文件系统上,生成了一个新的96MB的Parquet文件,它是第一个Parquet文件连同它的两个Log文件重新压缩后得到的,这个新的Parquet文件fileId没变,但是instantTime变成了Compaction对应的commit时间,于是,在当前File Group里,第二个File Slice产生了,目前它还只有一个Base File,没有Log File。
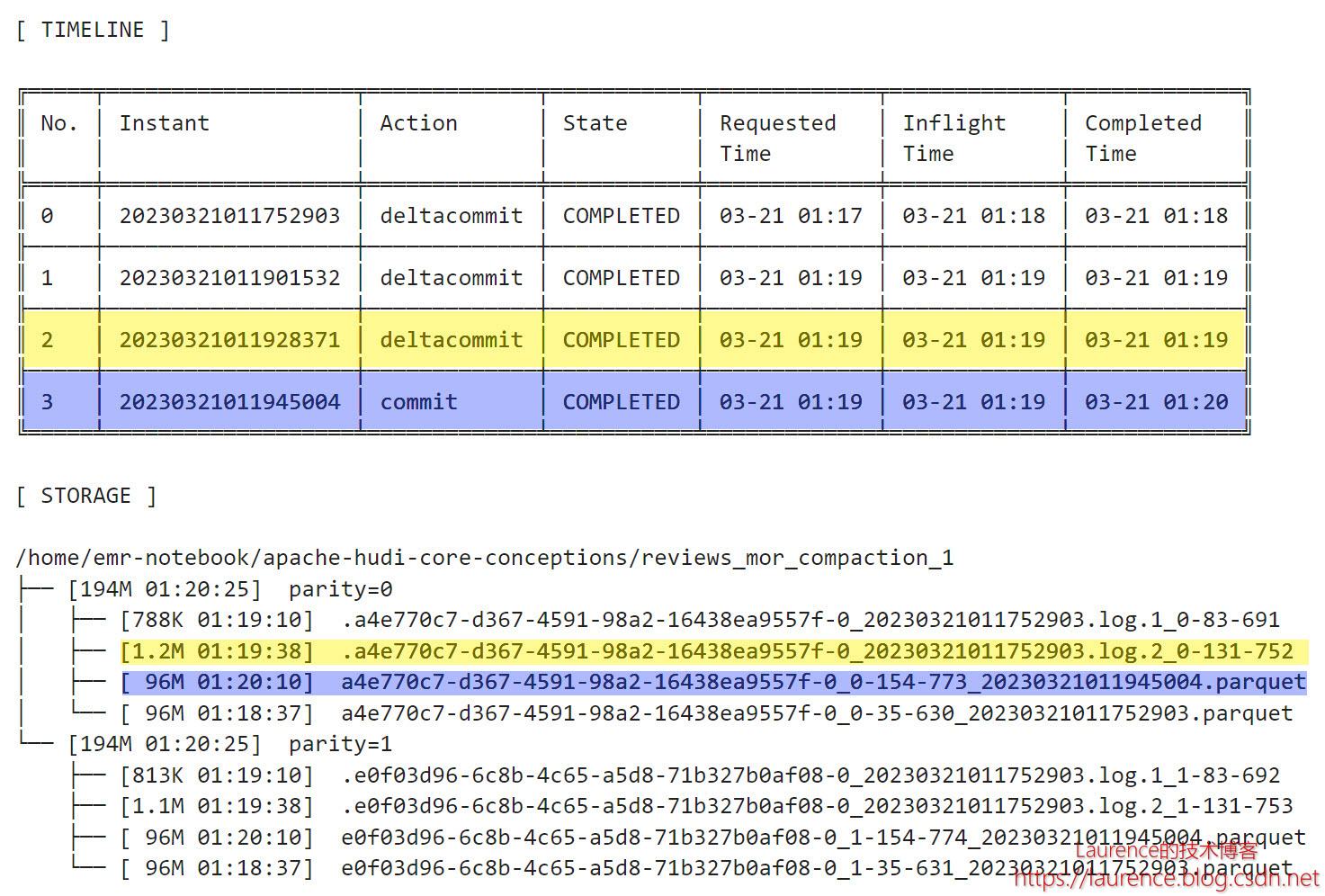
3.6. 复盘
最后,让我们将此前的全部操作汇总在一起,重新看一下整体的时间线和最后的文件布局:
4. 异步Compaction
4.1. 关键配置
《Apache Hudi Core Conceptions (4) - MOR: Compaction》的第2个测试用例演示了异步Compaction的运行机制。测试用的数据表有如下几项关键配置:
| 配置项 | 默认值 | 设定值 |
|---|---|---|
| hoodie.compact.inline | false | false |
| hoodie.compact.schedule.inline | false | false |
| hoodie.compact.inline.max.delta.commits | 5 | 3 |
| hoodie.copyonwrite.record.size.estimate | 1024 | 175 |
这些配置项在介绍概念时都已提及,通过这个测试用例将会看到它们组合起来的整体效果。
4.2. 测试计划
该测试用例会先后插入或更新三批数据,然后进行异步的Compaction排期和执行,过程中将重点观察时间线和文件布局的变化,整体测试计划如下表所示:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
|---|---|---|---|
| 1 | Insert | 96MB | +1 Base File |
| 2 | Update | 788KB | +1 Log File |
| 3 | Update | 1.2MB | +1 Log File |
| 4 | Offline Schedule | N/A | N/A |
| 5 | Offline Execute | 96.15MB | +1 Compacted Base File |
由于该测试用例的前三步操作与第3节(第1个测试用例)完全一致,所以不再赘述,我们会从第4步操作(Notebook的3.8节)开始解读。
4.3. 异步排期
在完成了和第3节完全一样的前三批操作后,时间线和文件系统的情形如下:
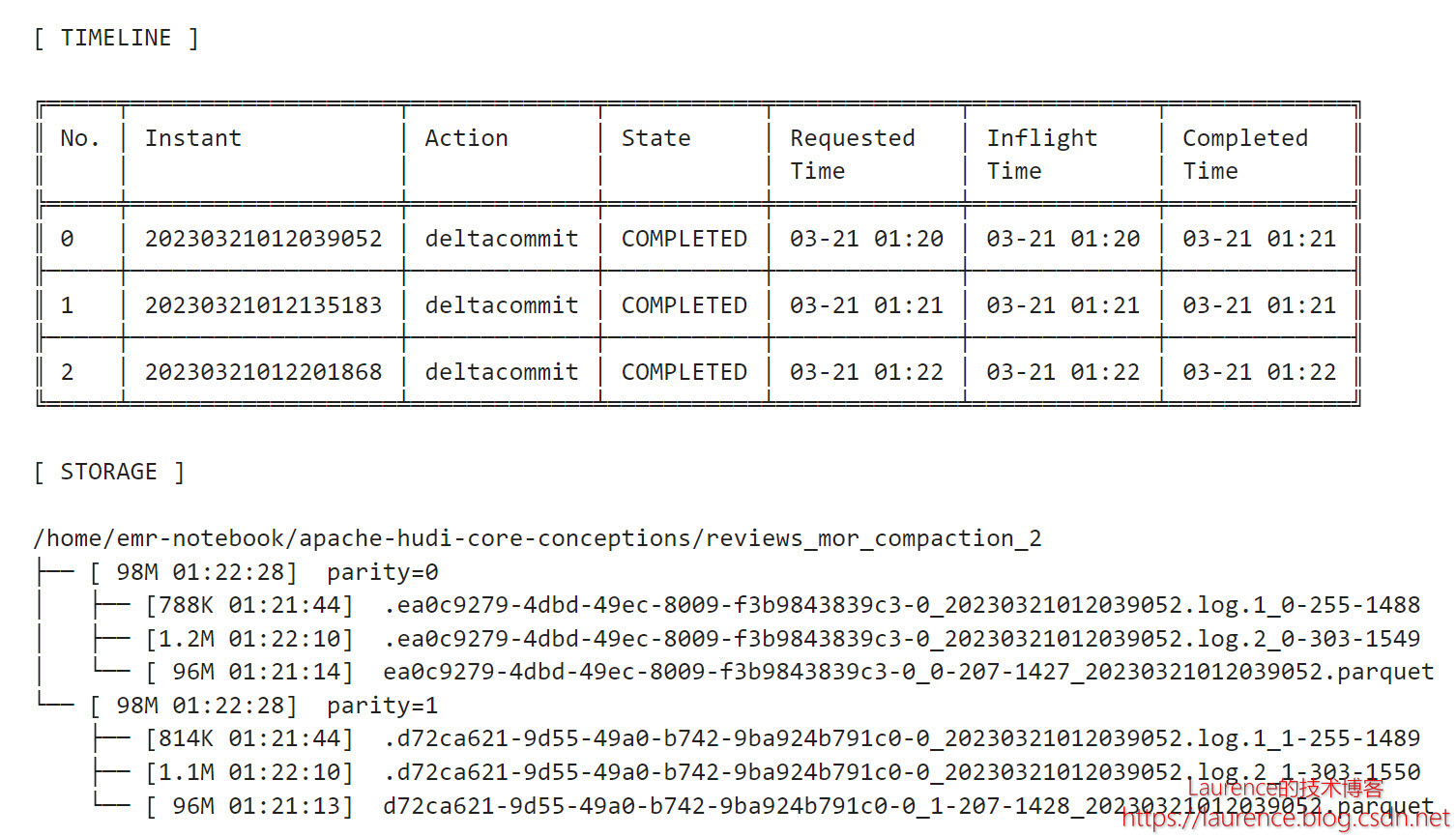
这和3.5节执行后的状况非常不同,没有发生Compaction,连排期也没有看到,因为我们关闭了hoodie.compact.inline。于是,在接下来的第4步操作中(Notebook的3.8节),我们通过spark-submit手动发起了一个排期作业(--mode 'schedule'):
sudo -u hadoop spark-submit \--jars '/usr/lib/hudi/hudi-spark-bundle.jar' \--class 'org.apache.hudi.utilities.HoodieCompactor' \/usr/lib/hudi/hudi-utilities-bundle.jar \--spark-memory '4g' \--mode 'schedule' \--base-path "s3://${S3_BUCKET}/${TABLE_NAME}" \--table-name "$TABLE_NAME" \--hoodie-conf "hoodie.compact.inline.max.delta.commits=3"
执行后,文件布局没有变化,但是在时间线中出现了一个状态为REQUESTED的compaction:
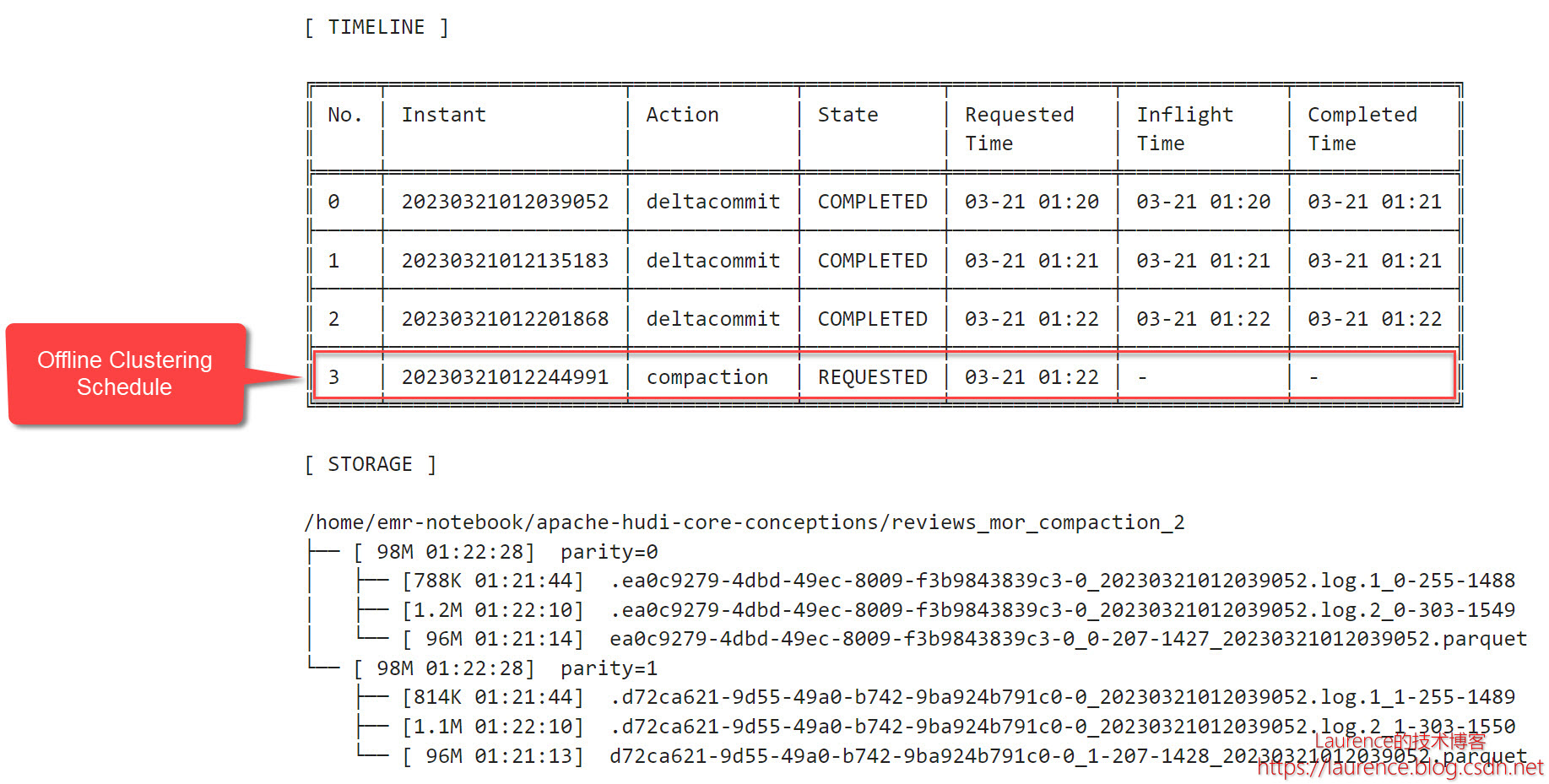
4.4. 异步执行
第5步操作(Notebook的3.9节)通过spark-submit手动发起了一个执行作业(--mode 'execute'):
sudo -u hadoop spark-submit \--jars '/usr/lib/hudi/hudi-spark-bundle.jar' \--class "org.apache.hudi.utilities.HoodieCompactor" \/usr/lib/hudi/hudi-utilities-bundle.jar \--spark-memory '4g' \--mode 'execute' \--base-path "s3://${S3_BUCKET}/${TABLE_NAME}" \--table-name "$TABLE_NAME"
执行后,原compaction状态由REQUESTED变为COMPLETED,原Base File和两个Log File被合并打包成一个新的Base File文件,大小96MB:
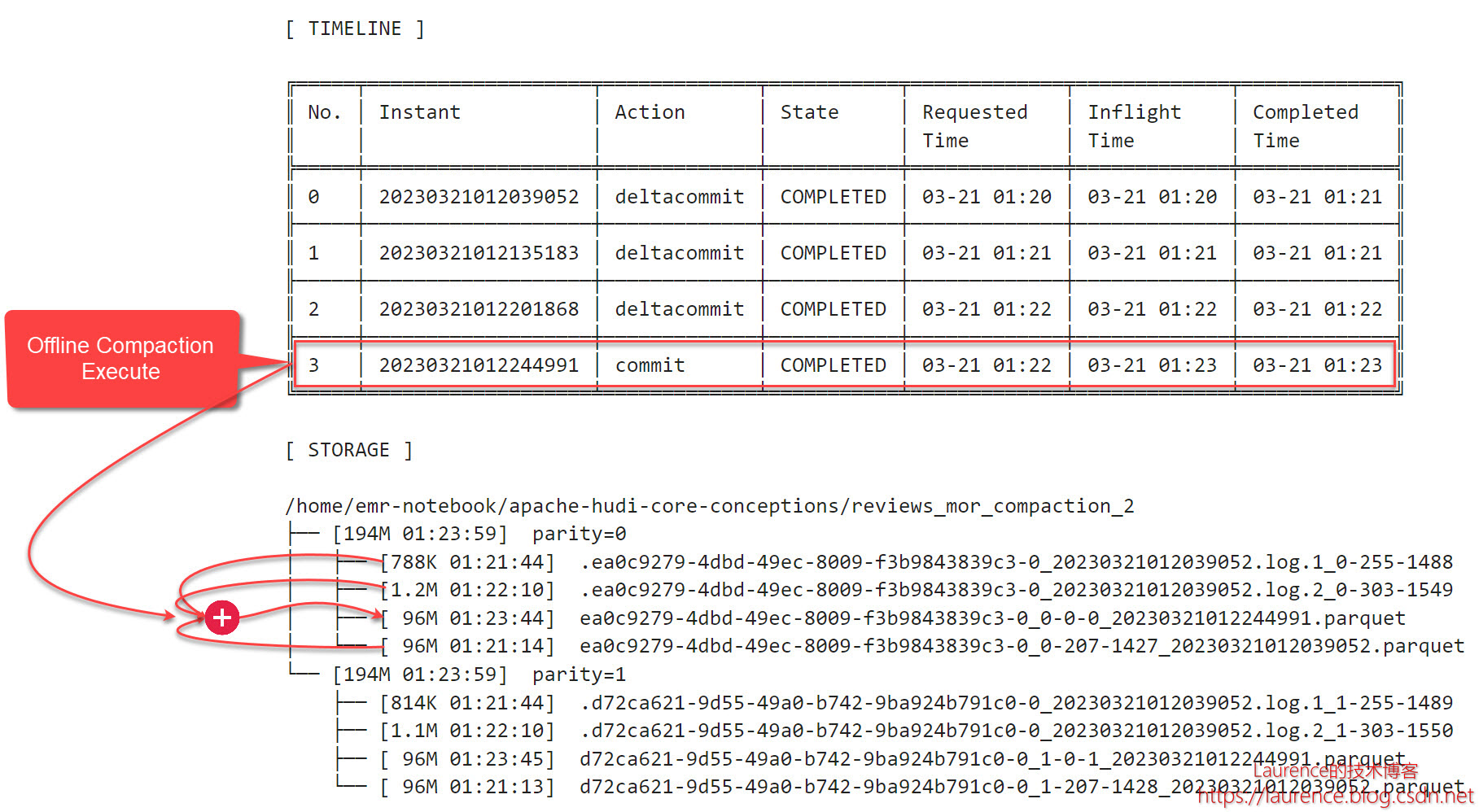
4.5. 异步排期 + 异步执行
异步的排期和执行可以通过一个命令一步完成,《Apache Hudi Core Conceptions (4) - MOR: Compaction》的第3个测试用例演示了这一操作。它的前三步操作与第2个测试用例一样,在第四步时,使用了“Schedule + Execute”一起执行的方式(--mode 'scheduleAndExecute')一步完成了Compaction操作,命令如下:
sudo -u hadoop spark-submit \--jars '/usr/lib/hudi/hudi-spark-bundle.jar' \--class 'org.apache.hudi.utilities.HoodieCompactor' \/usr/lib/hudi/hudi-utilities-bundle.jar \--spark-memory '4g' \--mode 'scheduleAndExecute' \--base-path "s3://${S3_BUCKET}/${TABLE_NAME}" \--table-name "$TABLE_NAME" \--hoodie-conf "hoodie.compact.inline.max.delta.commits=3"
5. 半异步Compaction
5.1. 关键配置
《Apache Hudi Core Conceptions (4) - MOR: Compaction》的第4个测试用例演示了半异步Compaction的运行机制。测试用的数据表有如下几项关键配置:
| 配置项 | 默认值 | 设定值 |
|---|---|---|
| hoodie.compact.inline | false | false |
| hoodie.compact.schedule.inline | false | true |
| hoodie.compact.inline.max.delta.commits | 5 | 3 |
| hoodie.copyonwrite.record.size.estimate | 1024 | 175 |
这些配置项在介绍概念时都已提及,通过这个测试用例将会看到它们组合起来的整体效果。
5.2. 测试计划
该测试用例会先后插入或更新三批数据,然后进行异步的Compaction Execute,过程中将重点观察时间线和文件布局的变化,整体测试计划如下表所示:
| 步骤 | 操作 | 数据量(单分区) | 文件系统 |
|---|---|---|---|
| 1 | Insert | 96MB | +1 Base File |
| 2 | Update | 788KB | +1 Log File |
| 3 | Update | 1.2MB | +1 Log File |
| 4 | Offline Execute | 96.15MB | +1 Compacted Base File |
由于该测试用例的前三步操作与第3节(第1个测试用例)完全一致,所以不再赘述,我们会从第3步操作(Notebook的5.7节)开始解读。
5.3. 同步排期
在完成了和第3节完全一样的前三批操作后,时间线和文件系统的情形如下:
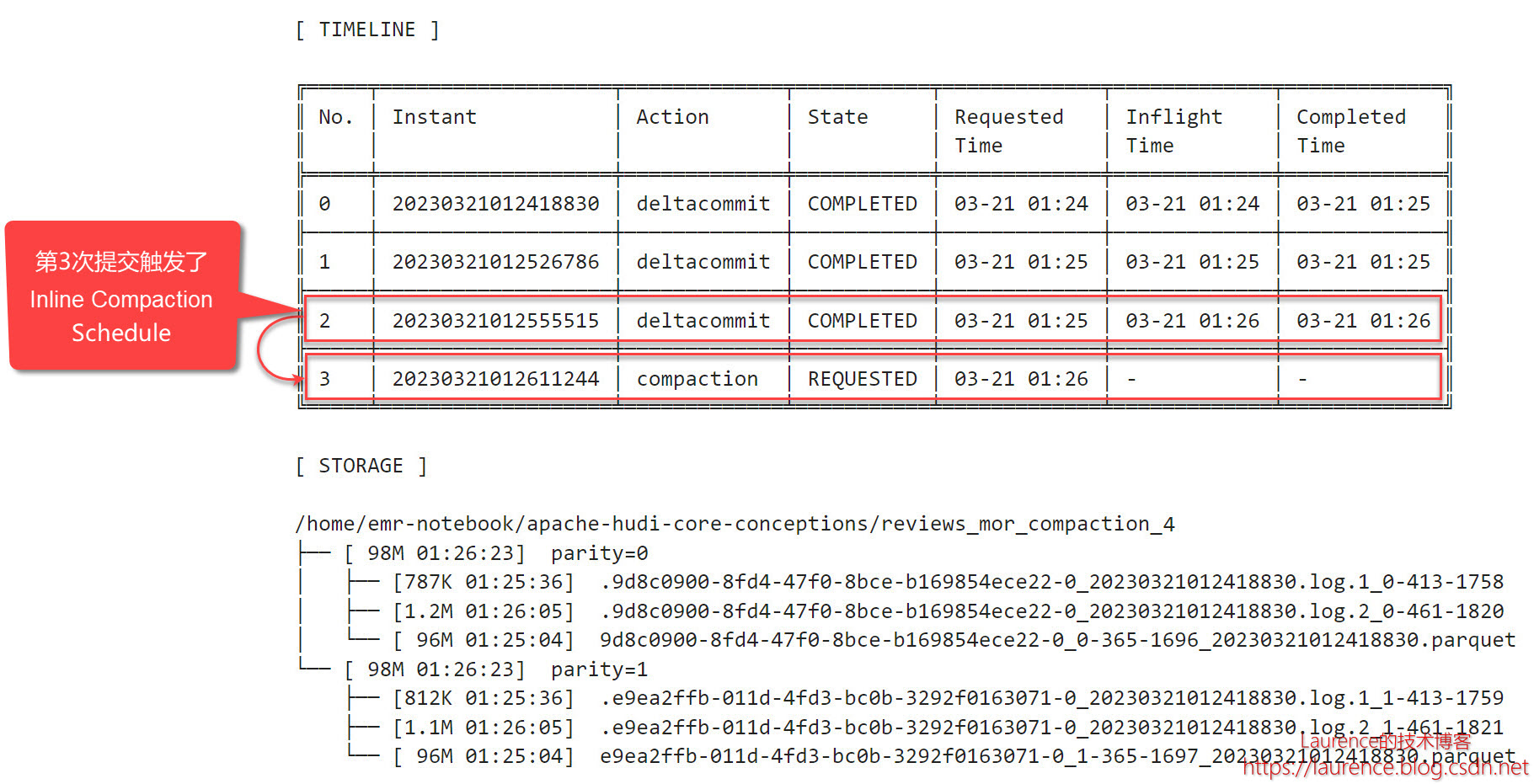
在该模式下,第3次提交自动触发了Compaction排期,状态为REQUESTED。
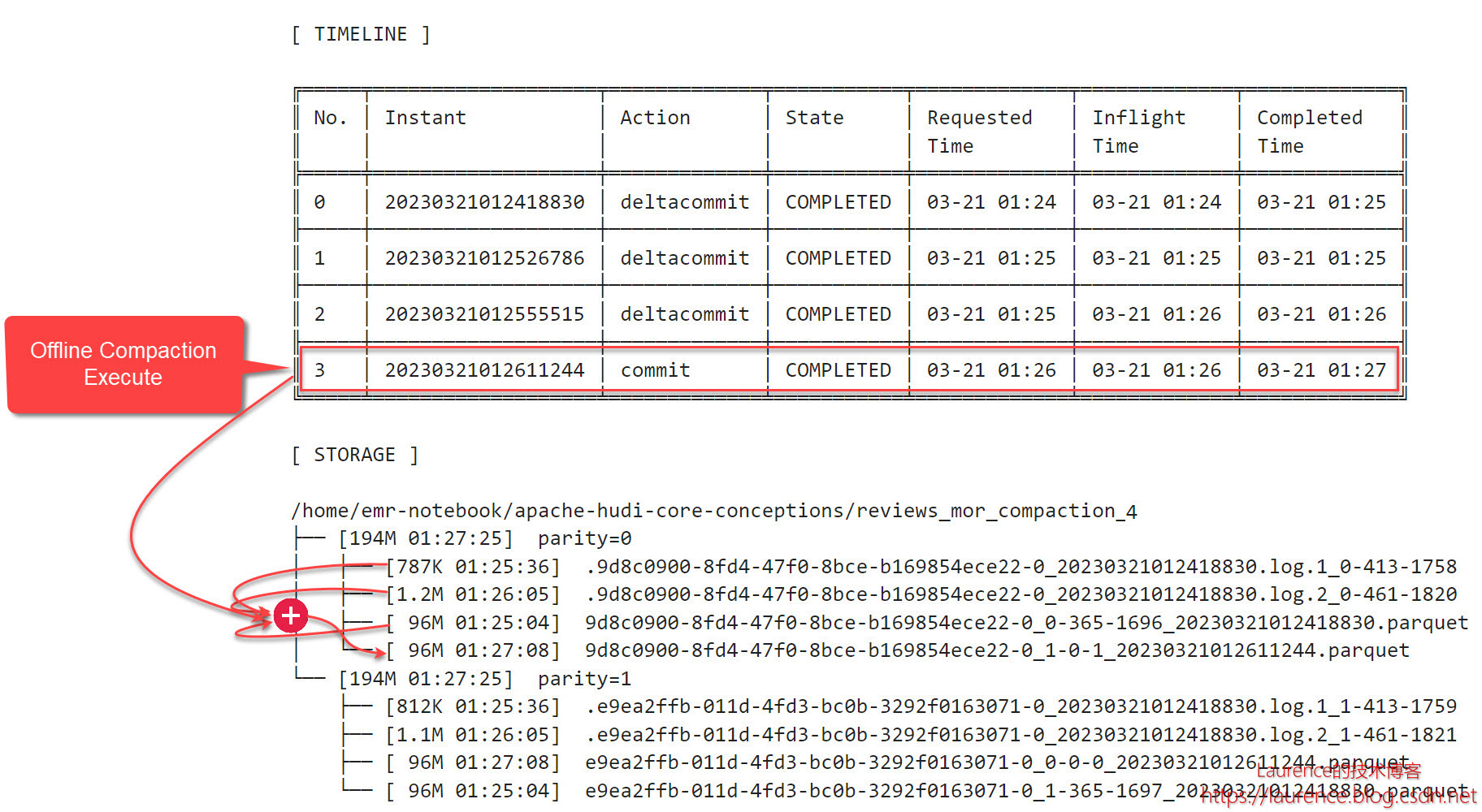
5.4. 异步执行
在接下来的第4步操作中,通过spark-submit手动发起了一个执行作业,排期计划被consume,原REQUESTED状态的Compaction变成了COMPLETED:
关于作者:耿立超,架构师,著有 《大数据平台架构与原型实现:数据中台建设实战》一书,多年IT系统开发和架构经验,对大数据、企业级应用架构、SaaS、分布式存储和领域驱动设计有丰富的实践经验,个人技术博客:https://laurence.blog.csdn.net
![[ 应急响应基础篇 ] evtx提取安全日志 事件查看器提取安全日志](https://img-blog.csdnimg.cn/ce0be5ee41dc4990bfe0536d72683fdb.png)