机器学习:基于AdaBoosts算法对信用卡精准营销建立模型
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 订阅专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价 |
| 机器学习:基于神经网络对用户评论情感分析预测 |
| 机器学习:朴素贝叶斯模型算法原理(含实战案例) |
| 机器学习:逻辑回归模型算法原理(附案例实战) |
| 机器学习:基于逻辑回归对优惠券使用情况预测分析 |
| 机器学习:基于逻辑回归对超市销售活动预测分析 |
| 机器学习:基于KNN对葡萄酒质量进行分类 |
文章目录
- 机器学习:基于AdaBoosts算法对信用卡精准营销建立模型
- 1、AdaBoost算法简介
- 2、实验环境
- 3、实验内容
- 4、案例实战
- 4.1案例背景
- 4.2模型搭建
- 4.3模型预测及评估
1、AdaBoost算法简介
AdaBoost算法 (Adaptive Boosting) 是一种有效而实用的Boosting算法,它以一种高度自适应的方法顺序地训练弱学习器。AdaBoost根据前一次的分类效果调整数据的权重,上一个弱学习器中错误分类样本的权重会在下一个弱学习器中增加,正确分类样本的权重会相应减少,并且在每一轮迭代时会向模型加入一个新的弱学习器。不断重复调整权重和训练弱学习器的过程,直到误分类数低于预设值或迭代次数达到指定最大迭代次数时,我们会得到一个强分类器。
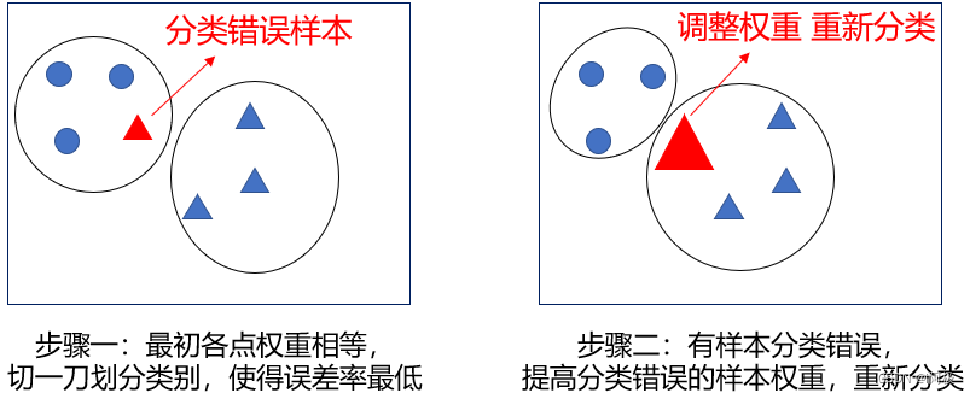
绘制了如下一张图来解释调整权重的概念,在步骤一中先切一刀对数就进行划分,此时将小三角形错误的划分到了圆形类别中,在步骤二便调整这一分类错误的小三角形的权重,使它变成一个大三角形,这样它和三角形类型的数据就更加接近了,因此重新分类时,它便能准确的分类到三角形类别。
预先设定AdaBoost算法在误分类数为0时终止迭代,即全部分类正确时(即误差率为0)停止迭代,并定义误差率为错误划分类别的样本权重之和,例如对于9个样本,每个样本的权重为1/9,若此时有2个样本划分错误,那么此时的误差率就是1/9 + 1/9=2/9。
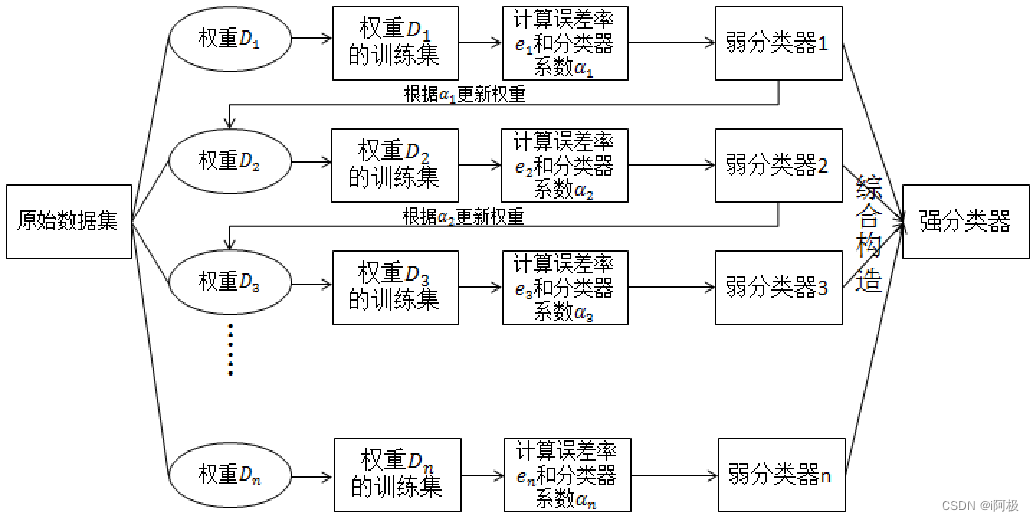
AdaBoost分类算法的流程图如下所示:
2、实验环境
Python 3.9
Anaconda
Jupyter Notebook
3、实验内容
AdaBoots信用卡精准营销模型
4、案例实战
4.1案例背景
当前经济增速下行,风控压力加大,各家商业银行纷纷投入更多资源拓展信用卡业务,信用卡产业飞速发展。因为市场竞争激烈,信用卡产品同质化严重,商业银行需要采用更快捷有效的方式扩大客户规模,实现精准营销,从而降低成本提高效益,增强自身竞争力。该精准营销模型也可以应用其他领域的精准营销,例如信托公司信托产品的精准营销等。
4.2模型搭建
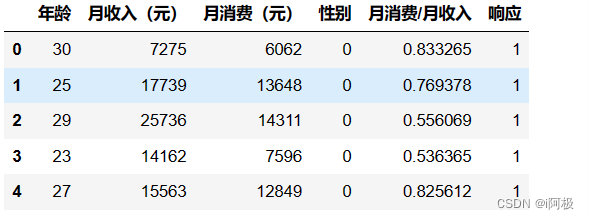
1、读取数据
import pandas as pd
df = pd.read_excel('信用卡精准营销模型.xlsx')
df.head()
2、提取特征变量和目标变量
X = df.drop(columns='响应')
y = df['响应']
3、划分训练集与测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
4、模型训练及搭建
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostClassifier(random_state=123)
clf.fit(X_train, y_train)
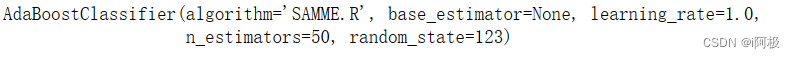
4.3模型预测及评估
1、预测测试集数据
y_pred = clf.predict(X_test)
print(y_pred)
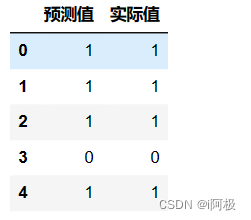
2、预测值与实际值对比
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()
3、查看准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)

4、查看预测分类概率
y_pred_proba = clf.predict_proba(X_test)
y_pred_proba[0:5]

5、绘制ROC曲线
from sklearn.metrics import roc_curve
fpr, tpr, thres = roc_curve(y_test.values, y_pred_proba[:,1])
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)
plt.show()
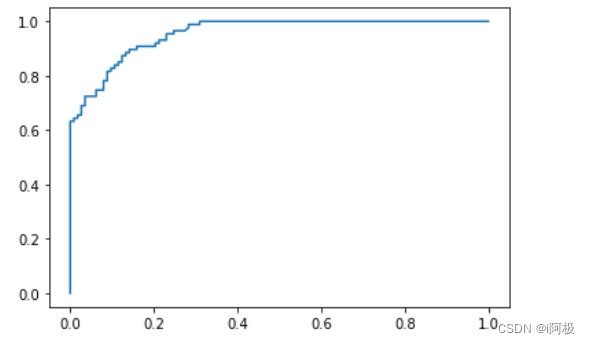
6、查看AUC值
from sklearn.metrics import roc_auc_score
score = roc_auc_score(y_test, y_pred_proba[:,1])
print(score)
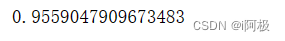
7、查看特征重要性
clf.feature_importances_
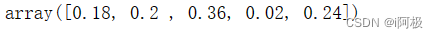
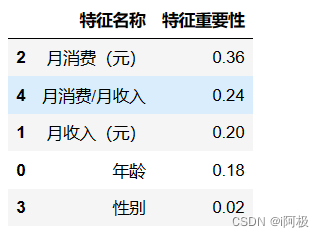
# 通过DataFrame的方式展示特征重要性
features = X.columns # 获取特征名称
importances = clf.feature_importances_ # 获取特征重要性# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗