String、数组[T:n]、列表Vec\哈希表HashMap<K,V>等。
切片slice;
循环缓冲区 VecDeque、双向列表 LinkedList等。(这是指双向链表吗?)
这些集合容器的共性:
可以遍历
可以进行 map-reduce操作。
可以从一种类型转换成另一种类型。
主要学一下切片和哈希
切片
定义:是一组类型相同,但是长度不确定,在内存中连续存放的数据结构。
fn main() {let arr = [1, 2, 3, 4, 5];let vec = vec![1, 2, 3, 4, 5];let s1 = &arr[..2];let s2 = &vec[..2];println!("s1: {:?}, s2: {:?}", s1, s2);// &[T] 和 &[T] 是否相等取决于长度和内容是否相等assert_eq!(s1, s2);// &[T] 可以和 Vec<T>/[T;n] 比较,也会看长度和内容assert_eq!(&arr[..], vec);assert_eq!(&vec[..], arr);
}
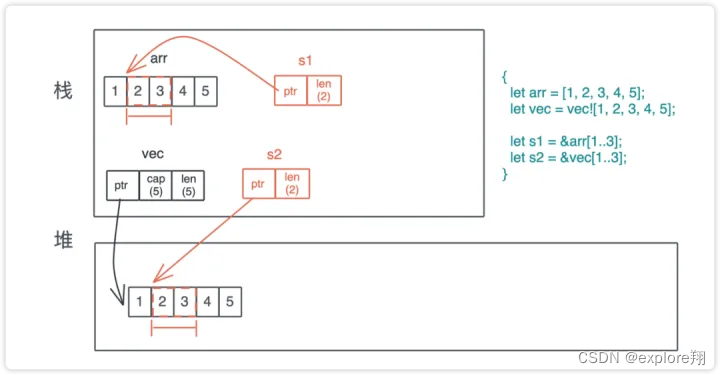
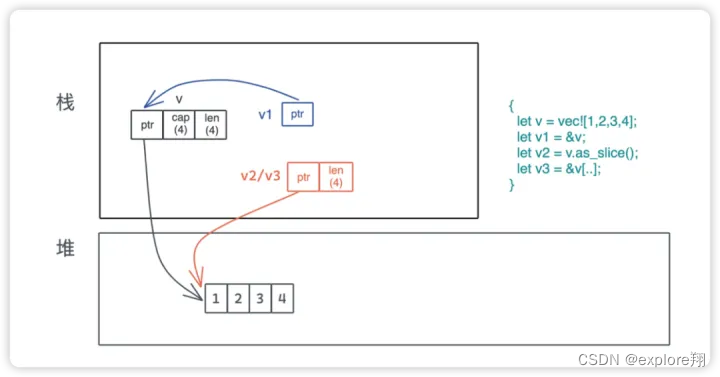
从上面可以看出,切片通常用引用的形式,实际是指针指向实际数据空间,而vec的引用是指向指针的指针。
String 是一个特殊的 Vec,所以在 String 上做切片,也是一个特殊的结构 &str。
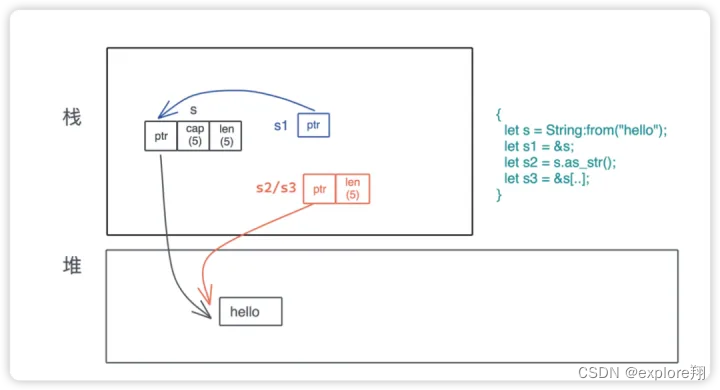
直接对string引用,就是一个指针,如果是&str或者且切片,就是胖指针了。
迭代器可以说是切片的孪生兄弟。**切片是集合数据的视图,而迭代器定义了对集合数据的各种访问操作。**iterator trait 有很多方法,但一般我们只需要定义它的关联类型 Item 和 next() 方法。
Item 定义了每次从迭代器里取出的数据类型。
next()是取下一个值的方法。为None,代表没有了。
切片将它们抽象成相同的访问方式,实现了在不同数据结构之上的同一抽象,这种方法很值得我们学习
哈希表
跟创建动态数组 Vec 的方法类似,可以使用 new 方法来创建 HashMap,然后通过 insert 方法插入键值对。
使用迭代器和 collect 方法创建
在实际使用中,不是所有的场景都能 new 一个哈希表后,然后悠哉悠哉的依次插入对应的键值对,而是可能会从另外一个数据结构中,获取到对应的数据,最终生成 HashMap。
例如考虑一个场景,有一张表格中记录了足球联赛中各队伍名称和积分的信息,这张表如果被导入到 Rust 项目中,一个合理的数据结构是 Vec<(String, u32)> 类型,该数组中的元素是一个个元组,该数据结构跟表格数据非常契合:表格中的数据都是逐行存储,每一个行都存有一个 (队伍名称, 积分) 的信息。
但是在很多时候,又需要通过队伍名称来查询对应的积分,此时动态数组就不适用了,因此可以用 HashMap 来保存相关的队伍名称 -> 积分映射关系。 理想很丰满,现实很骨感,如何将 Vec<(String, u32)> 中的数据快速写入到 HashMap<String, u32> 中?
遍历列表,将每一个元组作为一对 KV 插入到 HashMap 中,很简单,但是……也不太聪明的样子,换词说就是 —— 不够 rusty。
好在,Rust 为我们提供了一个非常精妙的解决办法:先将 Vec 转为迭代器,接着通过 collect 方法,将迭代器中的元素收集后,转成 HashMap:
fn main() {use std::collections::HashMap;let teams_list = vec![("中国队".to_string(), 100),("美国队".to_string(), 10),("日本队".to_string(), 50),];let teams_map: HashMap<_,_> = teams_list.into_iter().collect();
获取哈希表元素时
get 方法返回一个 Option<&i32> 类型:当查询不到时,会返回一个 None,查询到时返回 Some(&i32)
&i32 是对 HashMap 中值的借用,如果不使用借用,可能会发生所有权的转移
错误处理
错误处理的三种方式:使用返回值、异常处理和类型系统。而 Rust 目前看到的方案:主要用类型系统来处理错误,辅以异常来应对不可恢复的错误。
C语言中基本用返回值(错误码)来处理错误,比如文件fopen(filename)打开失败返回NULL,创建socket失败返回-1等。这样有很多局限,返回值本来有自己的语义,非要把错误和返回值混淆在一起,**加重了开发者的心智负担。**开发者很有可能会忘记处理,或者记错返回值的语义。
C++,JAVA中用异常处理来处理错误。C++ 异常处理涉及到三个关键字:try、catch、throw。
如果有一个块throw抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。
您可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
以下是尝试除以零时抛出异常的实例:
double division(int a, int b)
{
if( b == 0 )
{
throw “Division by zero condition!”;
}
return (a/b);
}
int main ()
{
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
}catch (const char msg) {
cerr << msg << endl;
}*
return 0;
}
异常处理的缺点:第一是可以看大异常处理的程序流很复杂,函数返回点可能在你意料之外,这就导致了代码管理和调试的困难,所以保证异常安全的第一个原则就是:避免抛出异常。
异常处理另外一个比较严重的问题是:开发者会滥用异常。异常处理的开销要比处理返回值大得多,滥用会有很多额外的开销。
Rust总结前辈的经验,使用类型系统来构建主要的错误处理流程。构建了Option类型和Result类型。
pub enum Option {
None,
Some(T),
}
#[must_use = “this Result may be an Err variant, which should be handled”]
pub enum Result<T, E> {
Ok(T),
Err(E),
}
Option是一个简单的enum, 它可以处理有值/没值 这种最简单的错误类型。
Result是一个复杂些的enum。当函数出错时,可以返回Err(E),否则Ok(T)。
可以看到Result类型有must_use, 如果没有使用就会报warning,以保证错误被处理了。

上图中的例子,如果我们不处理read_file的返回值,就开始有提示了。 (那这不是回到了 Golang的 到处都是 if err != nil的情况了吗?)Go 语言为人诟病的其中一点就是 if err != nil {} 的大量使用,缺乏一些程序设计的美感
?操作符
如果执行传播错误,不想当时处理,就用?操作符。这样让错误传播和异常处理不相上下,同时又避免了异常处理带来的问题。(一个设计良好的程序,一个功能涉及十几层的函数调用都有可能。而错误处理也往往不是哪里调用出错,就在哪里处理,实际应用中,大概率会把错误层层上传然后交给调用链的上游函数进行处理,错误传播将极为常见。)
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};fn read_username_from_file() -> Result<String, io::Error> {// 打开文件,f是`Result<文件句柄,io::Error>`let f = File::open("hello.txt");let mut f = match f {// 打开文件成功,将file句柄赋值给fOk(file) => file,// 打开文件失败,将错误返回(向上传播)Err(e) => return Err(e),};// 创建动态字符串slet mut s = String::new();// 从f文件句柄读取数据并写入s中match f.read_to_string(&mut s) {// 读取成功,返回Ok封装的字符串Ok(_) => Ok(s),// 将错误向上传播Err(e) => Err(e),}
}
}这个例子中,错误传播到调用该函数的地方,自己不关心怎么处理,至于怎么处理就是调用者的事,如果是错误,它可以选择继续向上传播错误,也可以直接 panic,亦或将具体的错误原因包装后写入 socket 中呈现给终端用户。
但是上面的代码也有自己的问题,那就是太长了
明星出场,必须得有排面,来看看 ? 的排面:
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io;
use std::io::Read;fn read_username_from_file() -> Result<String, io::Error> {let mut f = File::open("hello.txt")?;let mut s = String::new();f.read_to_string(&mut s)?;Ok(s)
}
}
其实 ? 就是一个宏,它的作用跟上面的 match 几乎一模一样:
如果结果是 Ok(T),则把 T 赋值给 f,如果结果是 Err(E),则返回该错误,所以 ? 特别适合用来传播错误。
Rust 中的错误主要分为两类:
可恢复错误,通常用于从系统全局角度来看可以接受的错误,例如处理用户的访问、操作等错误,这些错误只会影响某个用户自身的操作进程,而不会对系统的全局稳定性产生影响
不可恢复错误,刚好相反,该错误通常是全局性或者系统性的错误,例如数组越界访问,系统启动时发生了影响启动流程的错误等等,这些错误的影响往往对于系统来说是致命的
很多编程语言,并不会区分这些错误,而是直接采用异常的方式去处理。Rust 没有异常,但是 Rust 也有自己的卧龙凤雏:Result<T, E> 用于可恢复错误,panic! 用于不可恢复错误。
在 Rust 中触发 panic 有两种方式:被动触发和主动调用
fn main() {
let v = vec![1, 2, 3];
v[99];
} 数组访问越界会出发被动panic
在某些特殊场景中,开发者想要主动抛出一个异常,例如开头提到的在系统启动阶段读取文件失败。
对此,Rust 为我们提供了 panic! 宏,当调用执行该宏时,程序会打印出一个错误信息,展开报错点往前的函数调用堆栈,最后退出程序。
首先,来调用一下 panic!,这里使用了最简单的代码实现,实际上你在程序的任何地方都可以这样调用:
fn main() {
panic!(“crash and burn”);
}
当出现 panic! 时,程序提供了两种方式来处理终止流程:栈展开和直接终止。
其中,默认的方式就是 栈展开,这意味着 Rust 会回溯栈上数据和函数调用,因此也意味着更多的善后工作,好处是可以给出充分的报错信息和栈调用信息,便于事后的问题复盘。直接终止,顾名思义,不清理数据就直接退出程序,善后工作交与操作系统来负责。
对于绝大多数用户,使用默认选择是最好的,但是当你关心最终编译出的二进制可执行文件大小时,那么可以尝试去使用直接终止的方式,例如下面的配置修改 Cargo.toml 文件,实现在 release 模式下遇到 panic 直接终止:
[profile.release]
panic = ‘abort’
线程 panic 后,程序是否会终止?
长话短说,如果是 main 线程,则程序会终止,如果是其它子线程,该线程会终止,但是不会影响 main 线程。因此,尽量不要在 main 线程中做太多任务,将这些任务交由子线程去做,就算子线程 panic 也不会导致整个程序的结束。
最后panic不要乱用。不可恢复时采用。
同时,这里也体验到了宏编程的思想和简洁性。实际上panic做的工作很多,但是被包含在宏里了,写代码就很方便了。
总结:
相比 C/Golang 直接用返回值的错误处理方式,Rust 在类型上更完备,构建了逻辑更为严谨的 Option 类型和 Result 类型,既避免了错误被不慎忽略,也避免了用啰嗦的表达方式传递错误;
相对于 C++ / Java 使用异常的方式,Rust 区分了可恢复错误和不可恢复错误,分别使用 Option / Result,以及 panic! / catch_unwind 来应对,更安全高效,避免了异常安全带来的诸多问题;
对比它的老师 Haskell,Rust 的错误处理更加实用简洁,这得益于它强大的元编程功能,使用 ?操作符来简化错误的传递。