目录
文章导入 :
概述 :
详解过程 :
DNS域名解析 :
DNS 域名解析过程分析 :
TCP连接搭建 :
等待TCP队列
建立TCP连接
发起 HTTP 请求 :
# 哪是如何进行 HTTP 请求的呢 ??
服务器响应 HTTP 请求 :
返回请求 :
浏览器解析 :
浏览器进行页面渲染 :
服务器关闭 TCP 连接 :
总结 :
文章导入 :
本文呢~ 您只看标题就晓得了文章内容,没错,是关于 Web服务篇--Http 协议的内容 。
咱直接开门见山 ,您平时上网,逛网页那是必不可少的了;
您肯定有过下面操作 : 在浏览器地址栏里输入 www.baidu.com ,然后页面就跳转到 您所需
要的页面。
那换言之,您在地址栏里输入内容,这个简简单单的操作能够执行,以至于给您带来您想要的
网页页面呈现在眼前, 这个操作的背后就是我们要讲的内容 ~!!
===>>>
这中间发生的过程,这 您上网,打开浏览器,网页从无到有的过程即是 文章核心~!!
概述 :
* 终端客户在 Web 浏览器地址栏 输入 访问地址 ( eg : http://www.ceshi.com:80/index.html)
* Web 浏览器请求 DNS 服务器把域名 www.ceshi.com 解析成 Web 服务器的 IP 地址
* Web 浏览器 将端口号( 默认是 80 ) 从访问地址 URL 中解析出来
* Web 浏览器通过解析后的IP 地址 及端口号 与 Web 服务器之间建立一条 TCP 连接
* 建立 TCP 连接后,Web 浏览器向 Web 服务器发送一条 HTTP 请求报文
* Web 服务器响应并读取浏览器的请求信息,然后返回一条 HTTP 响应报文
* Web 服务器关闭 HTTP 连接,关闭 TCP 连接,Web浏览器显示访问的网站内容 到 屏幕上 ~!
详解过程 :
您在浏览器地址栏输入 域名( 网址 )
上面这个简单的操作,为了更好的理解其背后的原因,我们就得把 DNS域名解析服务 再掰扯掰
扯了~!
DNS域名解析 :
那你在浏览器地址栏输入了一个 域名( 网址 ),那浏览器接受到后,它怎么弄呢 ?
且听咱家给你分析分析
直接告诉你,浏览器(也即 计算机 )一看你输入的东东( 网址 ),
浏览器直接懵逼,这是啥啊? ? 浏览器直接一个蒙圈,恩?? 问我浏览器为啥懵逼啊??
===>>>
来来来,我且问你,你输入的那些 域名 ( 网址 ),你肯定知道是啥意思,
www.baidu.com,那势必是百度的网站嘛,你光看那网址的表面意思就直接清楚了!
是啊 ~! 当然清楚,这话没错~! 你一看这域名你知道是 百度,我也知道是百度,
张三肯定也知道, 那浏览器它知不知道呢 ????
它是不知道的~!!!!
我们最早学计算机的时候,就清楚,这些计算机 ,机器,它们是压根就读不懂人话的,
它们喜欢什么 ??
===>>>
它们喜欢 二进制 ~!! 是数字 ~!! 是 01 ~!!
===>>>
诶 ? 这问题不就来了 , 你明明给浏览器地址栏输入的是 www.baidu.com
那也不是 数字啊?? 那为啥 浏览器 还能知道他要做啥呢??
当你发现这个矛盾的时候, DNS域名解析服务 就该登场了 ~!!
因为 DNS 就是解决这个问题的~!!!!
那根据上面所述,您在清楚了这个问题的矛盾点之后,您觉得这个矛盾应该怎么解决呢?
我的想法是 :
既然,浏览器要的是数字,你地址栏输入的内容,它有没有对应的数字呢?
废话~!! 当然有了, 除了域名,您是不是应该还清楚一个概念叫做 IP 啊?
===>>>
当然知道了, IP地址 谁不知道啊????
那不就得了,你所输入的 域名 ( 网址 ) 它对应的 IP 地址是多少啊 ??
===>>>
那怎么着?? 啥意思 ?? 是让您在地址栏输入 IP 地址嘛 ???
非也~!! 不是 ,那啥意思 ???
===>>>
您这么想,首先,您知道 www.baidu.com 对应的 IP 地址是多少嘛??
其次,还有一个问题就是 ,
那全世界就只有 www.baidu.com 这一个网址嘛 ??
全世界这么多 网址,数不清的网址,啥意思 ???
我还得一个一个 记它们网址对应的 IP ???
这不纯纯胡扯呢嘛 ~!!!!!
( 没错,我要是在浏览器输入 IP - 数字, 浏览器是轻松了,那我呢?累死我嘛? )
===>>>
所以,我们说,面对这个矛盾,这时候,DNS 服务就登场了,
DNS服务,它的全称是 DNS域名解析服务 ,就是解析您在浏览器地址栏输入
的内容( 即你输入的那些域名-网址 )
那既然是解析,那解析成什么呢 ??
===>>>
即解析成 浏览器(计算机) 能够读懂的数字,也即 IP 地址。
DNS服务(负责把域名和IP地址做 一 一 映射关系)
这不就正好解决了 ‘ 矛盾 ’
DNS 域名解析过程分析 :
浏览器首先看一下自己的DNS缓存里有没有(缓存时间比较短,大概只有1分钟,且只能容
纳1000条缓存)
如果没有就向操作系统的DNS缓存要,还没有就检查本机域名解析文件 hosts要,
在前面三个过程都没获取到的情况下,就会向 DNS 服务器进行查询,
浏览器就会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器(一般是电信运营
商提供的,也可以使用像Google提供的DNS服务器)发起域名解析请求(通过的是UDP协议
向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供
给我们该域名的IP地址)
下面,结合图示,来分析整个 DNS 服务的过程 :
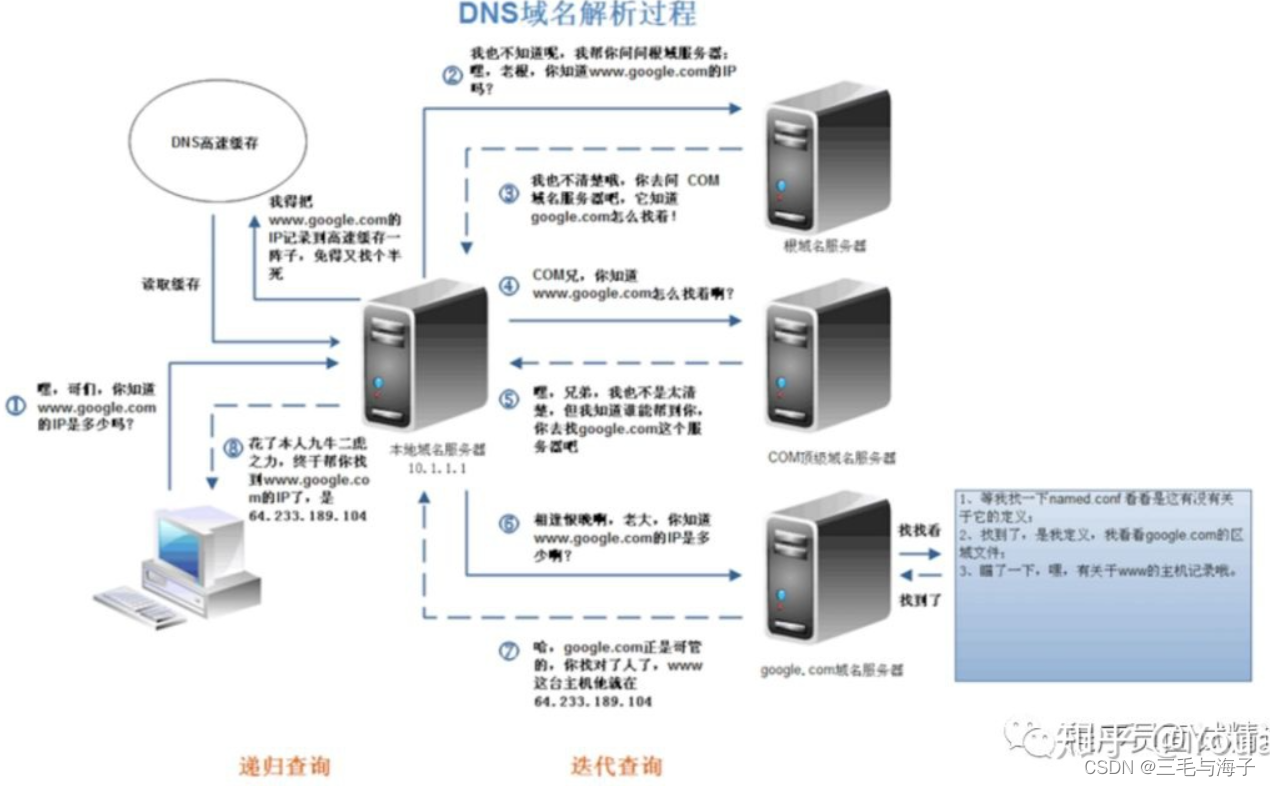
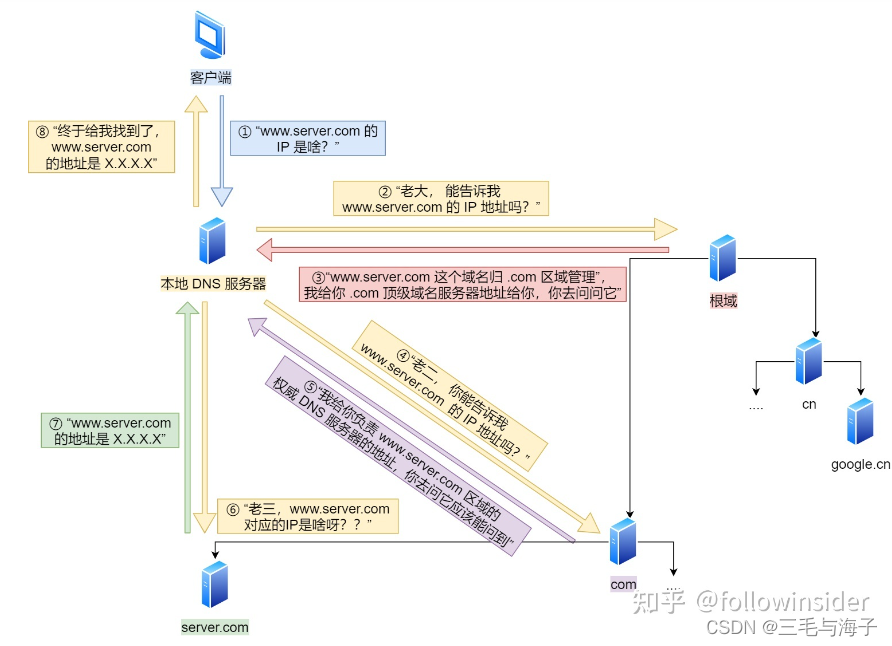
- 客户端首先会发出一个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存里的表格能找到www.server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:“老大, 能告诉我www.server.com的 IP 地址吗?” 根域名服务器是最高层次的,它不直接用于域名解析,但能指明一条道路。
- 根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址,你去问问它吧。”
- 本地 DNS 收到顶级域名服务器的地址后,发起请求问“老二, 你能告诉我 www.server.com 的 IP 地址吗?”
- 顶级域名服务器说:“我给你负责 www.server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
- 本地 DNS 于是转向问权威 DNS 服务器:“老三,www.server.com对应的IP是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端。
如此,浏览器便得到了,您要访问的网页的 IP 地址。
OK ,那现在我们已经拿到了 要访问网页的 IP 地址了,那我们是不是直接就可以浏览到 网
页里的内容了 ??
===>>>
答案是否定的,因为,现在才只是 Web服务往里长征的第一步 ~!!!!
===>>>
那现在拿到 IP 后,还要干嘛啊 ??
现在,只是拿到了 IP , 我们本篇主要的核心 -- HTTP协议 都还没露面呢~!!!
所以,我们接下来的工作就要为 HTTP 协议做准备了 ~!!
首先,来理一下逻辑思绪
===>>>
我们为什么要进行 HTTP 协议 ,是因为,浏览器 要和 Web服务器 进行沟通
浏览器要向Web服务器进行资源索取,
而要进行资源索取就必须得两个 端进行连接搭建
也就是说 浏览器就得和Web服务器进行 连接沟通
只有 浏览器和 Web 服务器 进行了 连接沟通 ,你浏览器才可以申请到 你想要访问网站
的信息, 你才可以浏览 你想要浏览的页面 ( 才能呈现出来 )
而 HTTP 网络请求进行的第一步就是浏览器和服务器 建立TCP连接 ,
所以 在网络请求之前,我们需要先看看 HTTP 和 TCP 两个协议的关系,
因为浏览器使用 HTTP 协议作为 应用层协议,用来封装请求的文本信息;
并使用 TCP/IP 作传输层协议将它发到网络上,所以 在 HTTP 协议开始工作之前,浏览器
需要通过 TCP 与服务器建立连接,也就是说 HTTP 的内容是通过 TCP 的传输数据阶段来
实现的~!!
TCP连接搭建 :
那现在就是,我们要进行 TCP连接的搭建
===>>>
TCP 连接的第一步 就是要准备 IP地址 和 端口号 ~!!
显然, IP 地址 我们已经通过 DNS域名解析服务获取到了
那端口号的获取 ???
===>>>
一般情况下,我们是通过 URL 来获取端口号的 ~!
( URL 就是在浏览器地址栏输入的内容,但大多数情况下,我们输入的都
URL 的简写,就只输入了 域名,没有连着 端口号一起输入)
所以,如果 URL 没有指明 端口号的情况下, 端口号的获取是和协议有
关的, http 协议对应的端口号默认就是 80 端口,
https 协议对应的端口号 是 443 端口 。
等待TCP队列
既然IP地址和端口准备好了,那么下一步是不是可以建立TCP连接了呢?
答案是“不一定可以”。Chrome有个机制,同一个域名同时最多只能建立6个TCP连接,如
果在同一个域名下同时有10个请求发生,那么其中4个请求会进入排队等待状态,直至进
行中的请求完成。
当然,如果当前请求数量少于6,会直接进入下一步,建立TCP连接。
建立TCP连接
排队等待结束之后,终于可以快乐地和服务器握手了,在HTTP工作开始之前,浏览器通
过TCP与服务器建立连接。
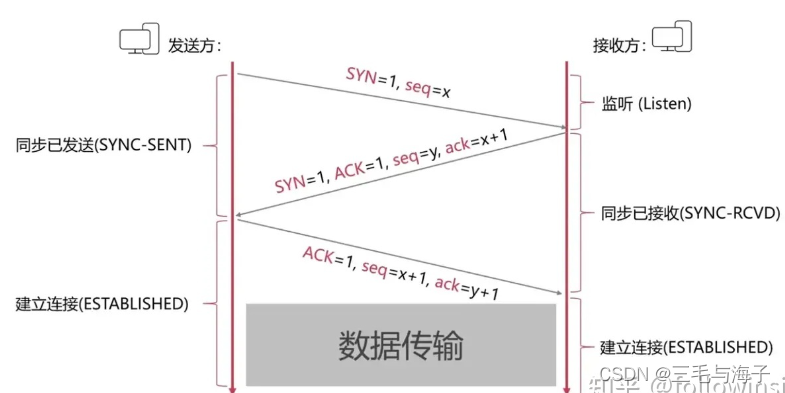
首先,发送方会发送连接请求,带上SYN = 1 seq= x的字段信息,此时发送方状态为同
步已发送。其次,接收方接受请求后,回复连接请求,带上SYN = 1 ACK = 1 seq = y
ack = x + 1的字段信息,此时接收方的状态为同步已接收
最后,发送方接受响应后,回复带上ACK = 1 seq = x + 1 ack = y + 1的字段信息,此
时,发送方的状态为建立连接状态,而接收方的状态得等发送方这时的回复收到后再转为
建立连接。
( 上面整个表述的过程就是我们经常说的 三次握手 ~!!!)
此时的状态即是 TCP 连接建立 ,浏览器与服务端 可以进行 数据传输了~!!!!
至此 ,从最开始 到目前为止,我们所有的工作都是为 HTTP 协议做的准备 ~!!
也即是说,从现在开始,我们才真正开始进行 HTTP 协议服务~!!!!!!
发起 HTTP 请求 :
# 我们现在建立了 TCP连接,即是说 浏览器和服务端可以进行通信 ( 数据传输 );
HTTP 协议中的数据正是在这个通信过程中传输的。
# 哪是如何进行 HTTP 请求的呢 ??
首先浏览器会向服务器发送请求行,
它包括了请求方法、请求URI(Uniform Resource Identifier)和HTTP版本协议。
发送请求行,就是告诉服务器浏览器需要什么资源,最常用的请求方法是Get。比如,直接
在浏览器地址栏键入极客时间的域名(http://time.geekbang.org),这就是告诉服务器要
Get它的首页资源。
另外一个常用的请求方法是POST,它用于发送一些数据给服务器,比如登录一个网站,就
需要通过POST方法把用户信息发送给服务器。如果使用POST方法,那么浏览器还要准备
数据给服务器,这里准备的数据是通过请求体来发送。
在浏览器发送请求行命令之后,还要以请求头形式发送其他一些信息,把浏览器的一些基础
信息告诉服务器。比如包含了浏览器所使用的操作系统、浏览器内核等信息,以及当前请求
的域名信息、浏览器端的Cookie信息,等等。
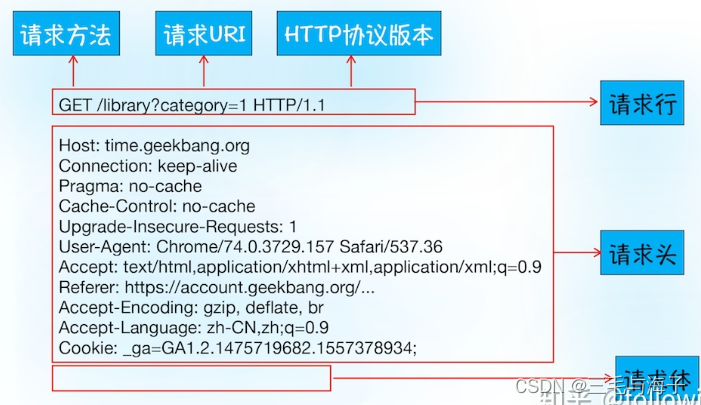
结合上图就可以理解 浏览器是如何发送请求信息给服务器的。
至此, 浏览器到 Web服务器 发送的 HTTP 请求,就到了 Web服务器端 ~!!
这是 我们整个 Web服务的前半部分,也是 HTTP 服务的前半部分~!!
接下来就到了,Web服务器 处理 这 HTTP 请求后的事情了 ~!!
Web服务器 处理完后,还需要再 返回给 浏览器~!!!!
服务器响应 HTTP 请求 :
# 接下来,Web服务器则会根据 浏览器发送的请求信息来准备数据 ~!
返回请求 :
首先服务器会返回响应行,包括协议版本和状态码。
但并不是所有的请求都可以被服务器处理的,那么一些无法处理或者处理出错的信息,怎
么办呢?服务器会通过请求行的状态码来告诉浏览器它的处理结果。
比如 :
===>>>
最常用的状态码是200,表示处理成功;
如果没有找到页面,则会返回404;
常见状态码 :

随后,正如浏览器会随同请求发送请求头一样,服务器也会随同响应向浏览器发送响应
头。响应头包含了服务器自身的一些信息,比如服务器生成返回数据的时间、返回的数据
类型(JSON、HTML、流媒体等类型),以及服务器要在客户端保存的Cookie等信息。
发送完响应头后,服务器就可以继续发送响应体的数据,通常,响应体就包含了HTML的
实际内容。
浏览器解析 :
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源
时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个
时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序
就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自
从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉
浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。
浏览器进行页面渲染 :
最后,浏览器利用自己内部的工作机制,把请求的静态资源和html代码进行渲染,渲染之后
呈现给用户,浏览器是一个边解析边渲染的过程。
首先浏览器解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成
后,浏览器开始布局渲染树并将其绘制到屏幕上。
这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。DOM节点中的各个元素都
是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒
模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个
过程称为repain。
页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在
移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和
repain。
JS的解析是由浏览器中的JS解析引擎完成的。JS是单线程运行,JS有可能修改DOM结构,意味
着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载。
服务器关闭 TCP 连接 :
通常情况下,一旦服务器向客户端返回了请求数据,它就要关闭 TCP 连接。不过如果浏览
器或者服务器在其头信息中加入了:
Connection:Keep-Alive 那么TCP连接在发送后将仍然保持打开状态,这样浏览器就可以继续通过同一个TCP连接发
送请求。保持TCP连接可以省去下次请求时需要建立连接的时间,提升资源加载速度。比
如,一个Web页面中内嵌的图片就都来自同一个Web站点,如果初始化了一个持久连接,
你就可以复用该连接,以请求其他资源,而不需要重新再建立新的TCP连接。
那么,关于 TCP 连接的关闭 ,我们需要讲一点 :
===>>>
关闭TCP连接就需要进行四次挥手了。
中断连接端可以是客户端,也可以是服务器端。
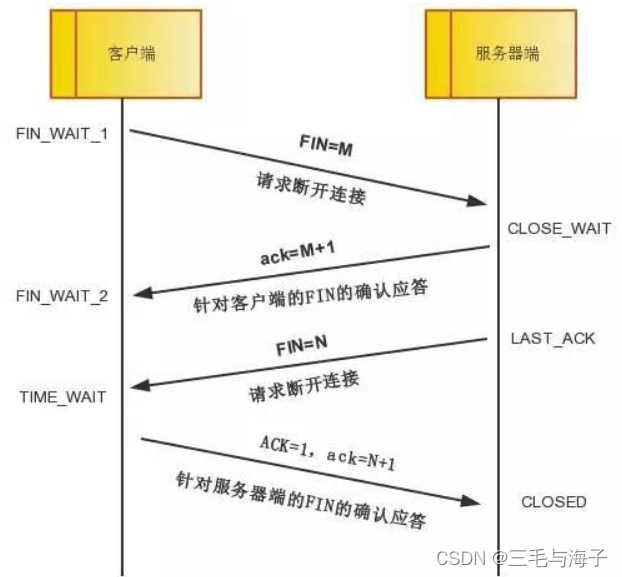
上示即为 四次挥手 的过程 ~!!!
上面是一方主动关闭,另一方被动关闭的情况,实际中还会出现同时发起主动
关闭的情况,也是通过四次握手。
当 TCP 连接断开后,自此一次完整的HTTP事务宣告完成。
总结 :
我们可以以一张图来 大致解释整个过程 :
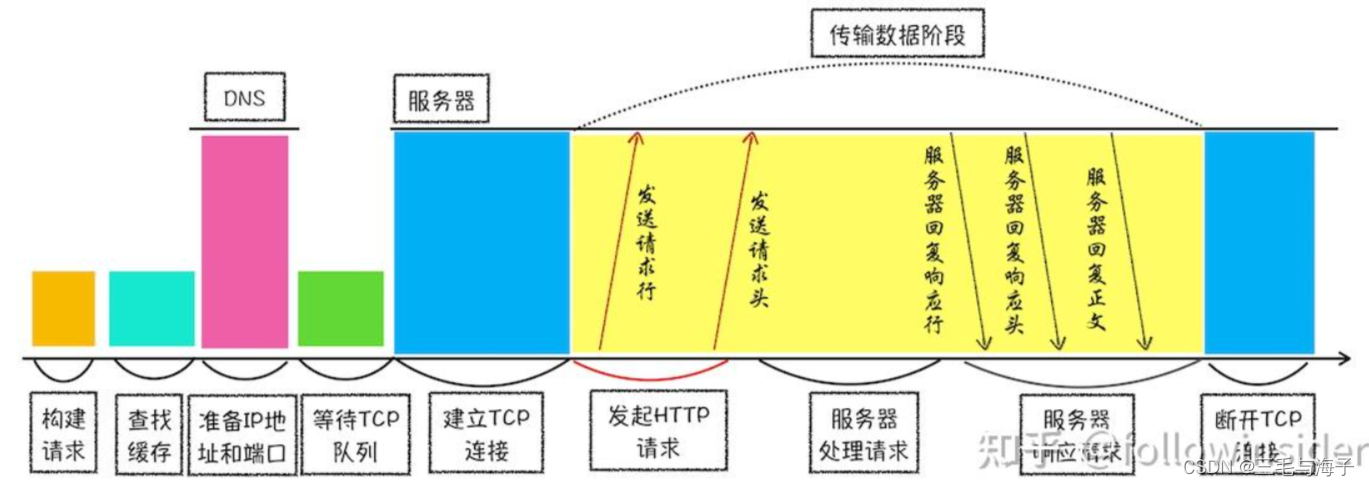
至此,我们整个 Web服务响应的过程就介绍完毕了~!!!!