为了应付某人的毕设,研究过一段时间的人机象棋,现来谈谈详细的算法思路和流程。
注:本文没有任何干货源码,写过二层遍历、基本评价函数与所谓“深度学习”算法下的人机象棋,棋力之弱小,就不献丑了。
首先,程序需要囊括象棋的基本着法,比如马走“日”字,相飞“田”,实现人人象棋是进行人机象棋的第一步。
进入正题,试想如何实现象棋的AI?按着人的思路,很容易想到“博弈树”,所谓博弈树,就是一颗大树,根节点就是开局棋盘,第二层节点就是走了一步棋的棋盘,第三层棋盘就是在二层棋盘下对方走一步棋的棋
盘,以此类推。这颗树异常庞大,庞大到囊括了象棋所有的可能性,据统计,象棋每一步平均有50-70种走法,而平均30几回合决出胜负,所以一共大概有60的30次方种走法。大胆想象一下,如果计算机能完全模拟并
记忆这颗完全博弈树,那么无论什么棋局,计算机都能找到对应的节点,通过对节点后续所有走法的遍历,回推一个最佳走法,那么就能保证AI的绝对优势。
这里提到一个词,“遍历”,人机象棋的一个核心就是遍历算法,即从当前棋盘开始,模拟后续的走法,返回最优走法,但是现在的计算机一般能保证的也只是5-10层的遍历,也就是说只能预测接下来5-10步的发展
。
==>遍历算法的核心就是去模拟所有可能的情况,程序实现并不难,首先遍历每一个棋子,在遍历某一个棋子所有可能的走法,如果是多层,则是递归遍历,这是值得推敲的<==
遍历算法会产生博弈树,博弈树是可以进行剪枝处理的,比如最简单的剪枝对已经分出胜负的棋局不再遍历,就可以简化博弈树。更加优秀的方法是α-β剪枝等,有兴趣可以仔细推敲研究。
说完遍历,来聊聊评价函数,什么叫评价函数?对于一个棋盘,怎么判断这个棋盘对谁有利,这就需要评价函数了。通过评价函数对棋盘进行评分,分值越大越有利,棋局向分值大的方向发展。
评价函数分为4个部分:
1、棋子自身价值。自身价值不用多说,就是棋子越多局面越有利。且各棋子分值不一,比如车>炮,马>兵等,注意一般我们令将的分值极大,比如车是100分,将可以设置成10000或者100000等,这样做是为了让机器
足够重视将,及时其他所有棋子都没了,也要保留将。这种分数评估都是按照经验来的,我当时按照参考书推荐设置的是炮80,马70等
2、棋子的位置价值。每一种棋子都有位置矩阵,比如车在原位时位置价值为0,当其出动后,位置价值逐步提升,当车在对面半区尤其是中心位置时,位置得分较高。尤其是兵,当其未过河时,位置得分极低,当其
过河后位置得分突然变高,比棋子本身价值还要高。为什么要位置价值的原因就是在于不同位置的棋子重要度不一样。
3、棋子灵活性价值。灵活性指棋子可能的走法,比如兵未过河时只有一种走法,当其过河后就有最多3种走法,走法越多,棋子灵活性越好,得分也就越高。灵活性的计算即遍历每一个棋子,用走法数乘基本灵活性
价值,最后得到总和就是灵活性得分。灵活性价值的意义在于定义棋子是否有多种走法,是否可以创造多种可能,比如若某一棋子被卡死,那它的价值就非常低。
4、保护威胁价值。威胁价值指若有敌方棋子能吃到己方棋子,则认为这个棋子是受威胁的,平常下棋时这种情况就是快走开,或者用其他棋子保住,或者丢车保帅等,受威胁的棋子需要大量减分,甚至减棋子自身价
值相应的分数,这样做是为了让AI能够保护棋子。而保护价值指己方棋子对棋子的保护,比如连环马,如果走到连环马的位置上,将增加保护价值。保护威胁价值的意义在于在进行棋盘进行评价估分时会综合考虑其
他棋子的位置,敌方会有威胁,己方会有保护作用。
==>评价函数直接决定了棋力大小,定义的各个部分的评价分数不一样将直接导致棋力不一,重视度不一样<==
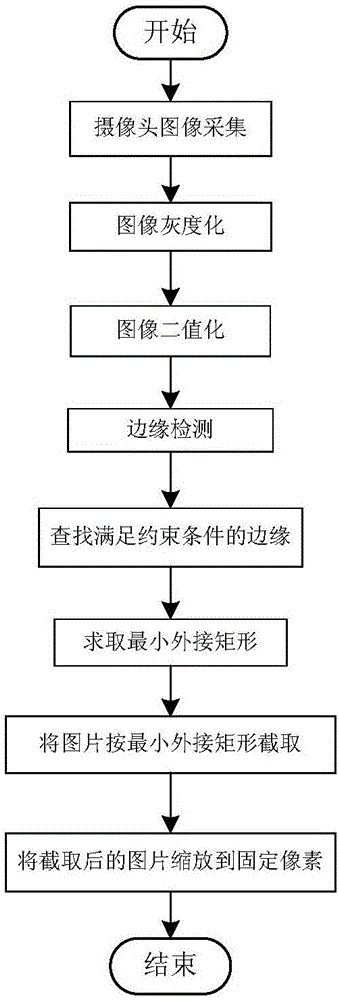
最后,提出“深度学习”算法,先上个流程图:
什么意思?先看虚线框外的内容,就是一个匹配的方法,就是在执行递归遍历和评价函数之前,先与大数据对比库进行匹配,如果库里有对应的数据,则直接用反馈回的走法进行走棋,就节省了遍历和评估的时间,极大加快速度。
那么大数据库怎么来,就需要用到机器学习方面的内容,遍历大量棋局,整合最佳走法,每一条对应一个棋局布局下的最佳走法。
OK,人机象棋介绍完毕,还想再说一句,博弈是AI中一个重要的部分,博弈蕴含很多思想,探究完人机象棋如何实现后,突然发现AI也就这样了!但是入门容易,优化很难!!!想提升一点速度都是一件不容易的事