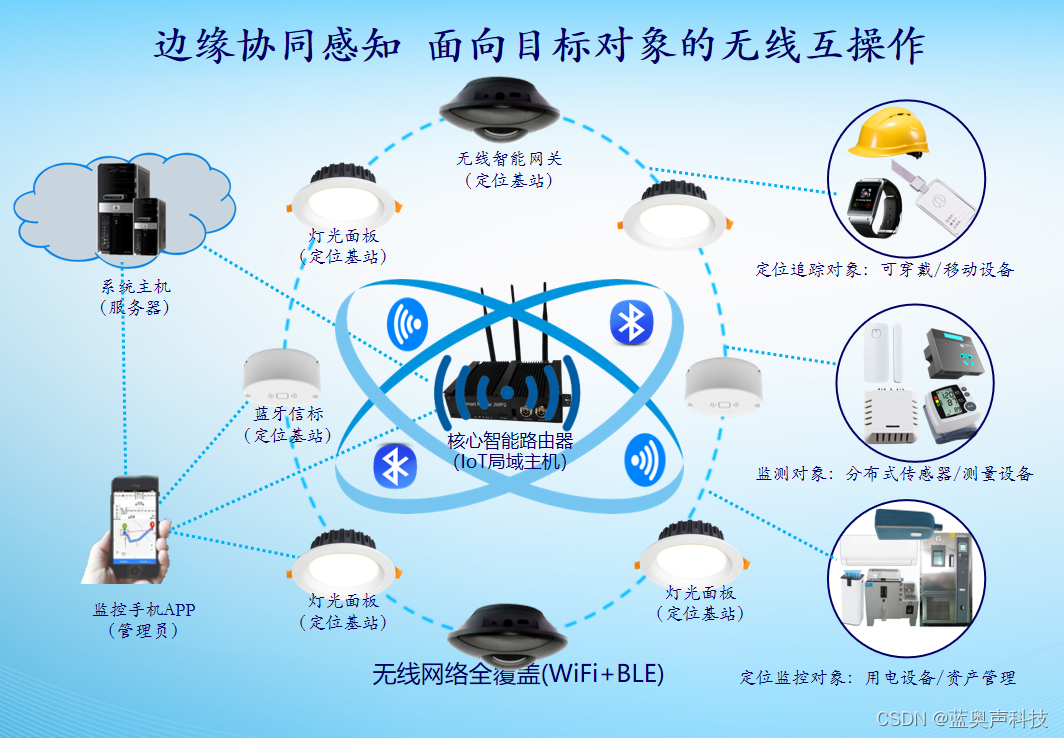
视频监控系统智能识别分析通过Python基于YOLOv7对现场画面中人员行为以及物体的状态检测。目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种 one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
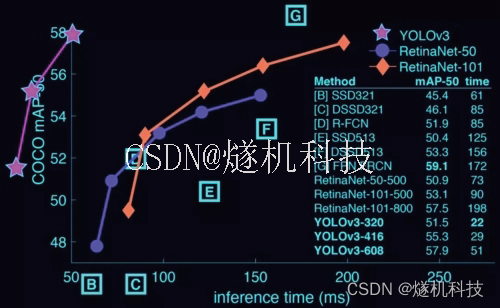
YOLOv7 在 5 FPS 到 160 FPS 范围内,速度和精度都超过了所有已知的目标检测器。并在V100 上,30 FPS 的情况下达到实时目标检测器的最高精度 56.8% AP。YOLOv7 是在 MS COCO 数据集上从头开始训练的,不使用任何其他数据集或预训练权重。
相对于其他类型的工具,YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于 transformer 的检测器 SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)速度上高出 509%,精度高出 2%,比基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度高出 551%,精度高出 0.7%。
Adapter接口定义了如下方法:
public abstract void registerDataSetObserver (DataSetObserver observer)
Adapter表示一个数据源,这个数据源是有可能发生变化的,比如增加了数据、删除了数据、修改了数据,当数据发生变化的时候,它要通知相应的AdapterView做出相应的改变。为了实现这个功能,Adapter使用了观察者模式,Adapter本身相当于被观察的对象,AdapterView相当于观察者,通过调用registerDataSetObserver方法,给Adapter注册观察者。
public abstract void unregisterDataSetObserver (DataSetObserver observer)
通过调用unregisterDataSetObserver方法,反注册观察者。
public abstract int getCount ()
返回Adapter中数据的数量。
public abstract Object getItem (int position)
Adapter中的数据类似于数组,里面每一项就是对应一条数据,每条数据都有一个索引位置,即position,根据position可以获取Adapter中对应的数据项。