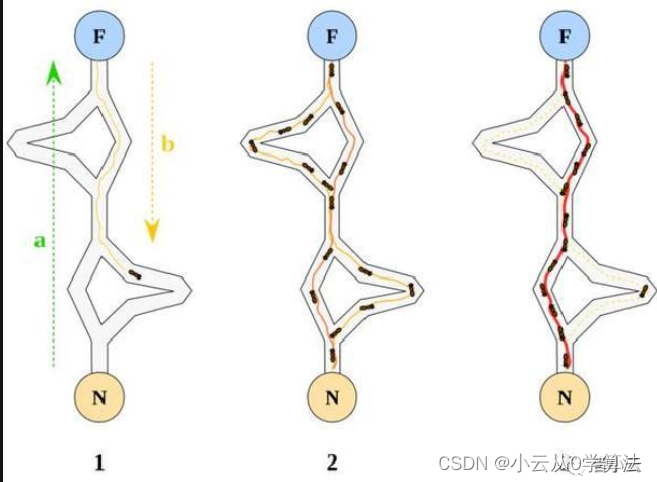
加上中心损失函数
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 设置随机种子,确保实验可重复性
torch.manual_seed(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False# 检查GPU是否可用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)# 定义数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# 加载数据集
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=4, shuffle=True)
testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=4, shuffle=False)# 定义模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)self.pool1 = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(32, 64, kernel_size=5, padding=2)self.pool2 = nn.MaxPool2d(kernel_size=2)self.fc1 = nn.Linear(7*7*64, 64)self.fc2 = nn.Linear(64, 10)self.relu = nn.ReLU(inplace=True)self.centers = nn.Parameter(torch.randn(10, 64))def forward(self, x):x = self.pool1(self.relu(self.conv1(x)))x = self.pool2(self.relu(self.conv2(x)))x = x.view(-1, 7*7*64)features = self.relu(self.fc1(x))centers = self.centersbatch_size = features.size(0)centers_batch = centers[labels]distance = features.unsqueeze(1) - centers_batch.unsqueeze(0)distance = distance.pow(2).sum(dim=2) / 2.0 / 1.0loss_center = distance.mean()logits = self.fc2(features)return logits, loss_center# 实例化模型和优化器
net = Net().to(device)
#net = nn.DataParallel(net.cuda(), device_ids=0,1, output_device=gpus[0])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)# 训练模型
num_epochs = 10
for epoch in range(num_epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs, loss_center = net(inputs)loss_cls = criterion(outputs, labels)loss = loss_cls + 0.1 * loss_centerloss.backward()optimizer.step()running_loss += loss.item()print('Epoch [%d/%d], Loss: %.4f' % (epoch+1, num_epochs, running_loss/(i+1)))# 测试模型
correct = 0
total = 0
with torch.no_grad():for data in testloader:images, labels = data[0].to(device), data[1].to(device)outputs, _ = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
Output
Using device: cuda
Epoch [1/10], Loss: 1.3335
Epoch [2/10], Loss: 0.2295
Epoch [3/10], Loss: 0.1399
Epoch [4/10], Loss: 0.1127
Epoch [5/10], Loss: 0.0963
Epoch [6/10], Loss: 0.0848
Epoch [7/10], Loss: 0.0764
Epoch [8/10], Loss: 0.0702
Epoch [9/10], Loss: 0.0651
Epoch [10/10], Loss: 0.0612
Accuracy of the network on the 10000 test images: 99 %
不加中心损失函数
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 设置随机种子,确保实验可重复性
torch.manual_seed(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False# 检查GPU是否可用
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('Using device:', device)# 定义数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# 加载数据集
trainset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=4, shuffle=True)
testset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=4, shuffle=False)# 定义模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)self.pool1 = nn.MaxPool2d(kernel_size=2)self.conv2 = nn.Conv2d(32, 64, kernel_size=5, padding=2)self.pool2 = nn.MaxPool2d(kernel_size=2)self.fc1 = nn.Linear(7*7*64, 64)self.fc2 = nn.Linear(64, 10)self.relu = nn.ReLU(inplace=True)#self.centers = nn.Parameter(torch.randn(10, 64))def forward(self, x):x = self.pool1(self.relu(self.conv1(x)))x = self.pool2(self.relu(self.conv2(x)))x = x.view(-1, 7*7*64)features = self.relu(self.fc1(x))#centers = self.centers#batch_size = features.size(0)#centers_batch = centers[labels]#distance = features.unsqueeze(1) - centers_batch.unsqueeze(0)#distance = distance.pow(2).sum(dim=2) / 2.0 / 1.0#loss_center = distance.mean()logits = self.fc2(features)return logits# 实例化模型和优化器
net = Net().to(device)
#net = nn.DataParallel(net.cuda(), device_ids=0,1, output_device=gpus[0])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)# 训练模型
num_epochs = 10
for epoch in range(num_epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(device), data[1].to(device)optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print('Epoch [%d/%d], Loss: %.4f' % (epoch+1, num_epochs, running_loss/(i+1)))# 测试模型
correct = 0
total = 0
with torch.no_grad():for data in testloader:images, labels = data[0].to(device), data[1].to(device)outputs, _ = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
Using device: cuda
Epoch [1/10], Loss: 0.1296
Epoch [2/10], Loss: 0.0405
Epoch [3/10], Loss: 0.0301
Epoch [4/10], Loss: 0.0210
Epoch [5/10], Loss: 0.0157
Epoch [6/10], Loss: 0.0116
Epoch [7/10], Loss: 0.0078
Epoch [8/10], Loss: 0.0061
Epoch [9/10], Loss: 0.0046
Epoch [10/10], Loss: 0.0045
Accuracy of the network on the 10000 test images: 99 %