1.图像超分辨率
1.1 什么是图像超分辨率?
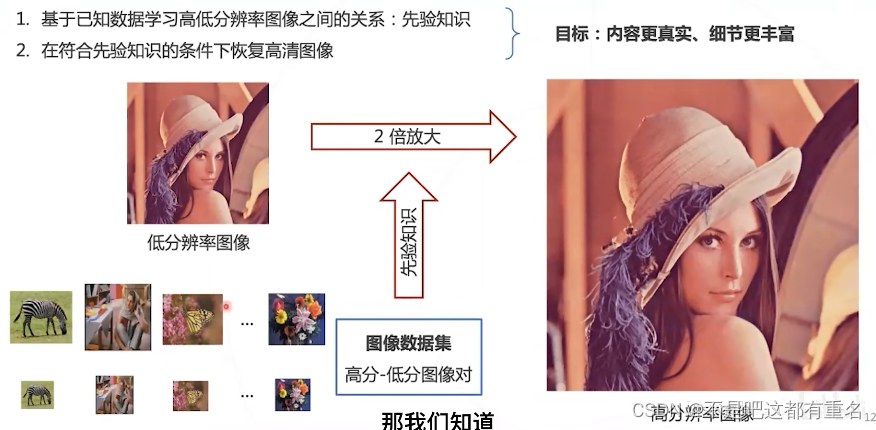
根据从低分辨率图像重构高分辨率图像
1.2 目标:
- 提高图像的分辨率
- 高分图像符合低分图像的内容
- 恢复图像的细节、产生真实的内容

1.3 应用:
- 经典游戏高清重制
- 动画高清重制
- 照片修复
- 节约传输高清图像的带宽
- 民生领域:医疗影像,卫星影像,监控系统,空中监察
1.4 类型

1.5 单图超分的解决思路
1.6 经典方法:稀疏编码 Sparse Coding
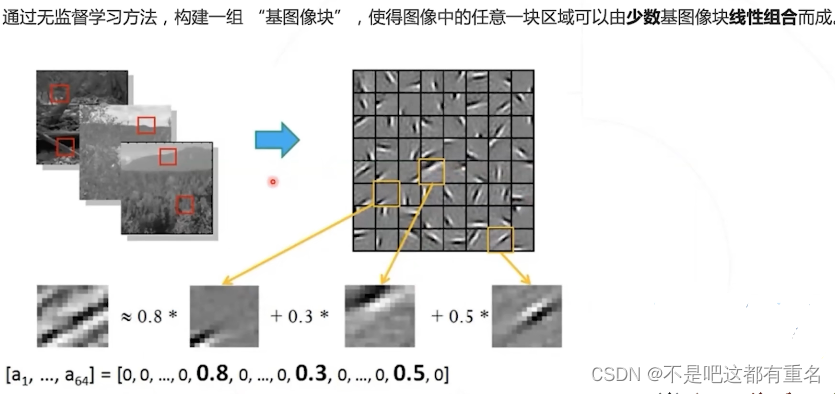
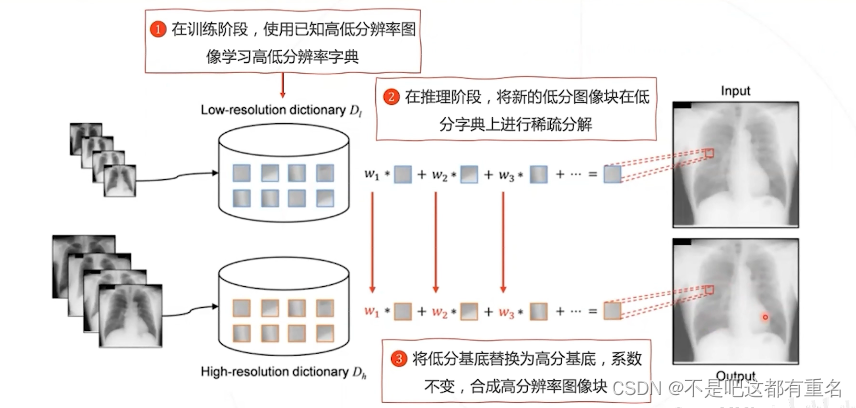
缺点:

1.7 深度学习时代的超分辨率算法
(1)基于卷积网络和普通损失函数:
使用卷积神经网络,端到端从低分辨率图像恢复高分辨率图像
代表算法:SRCNN与FSRCNN
(2)使用生成对抗网络
采用生成对抗网络的策略,鼓励产生细节更为真实的高分辨率图像
代表算法:SRGAN 和ESRGAN
2.基于卷积网络的模型SRCNN与FSRCNN
2.1 SRCNN(2014)
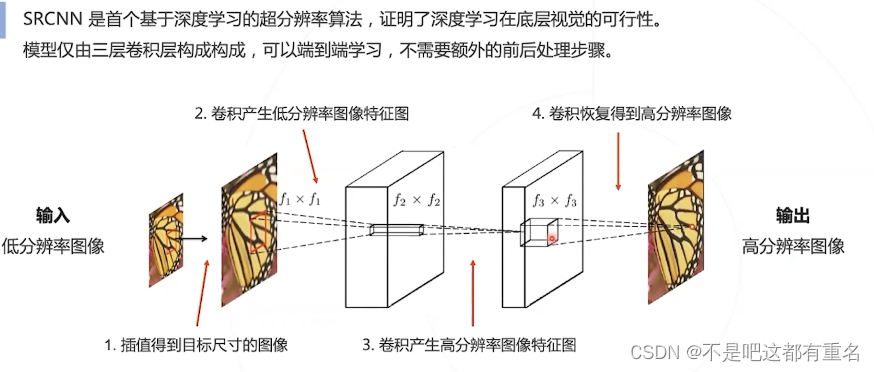
SRCNN模型功能的划分
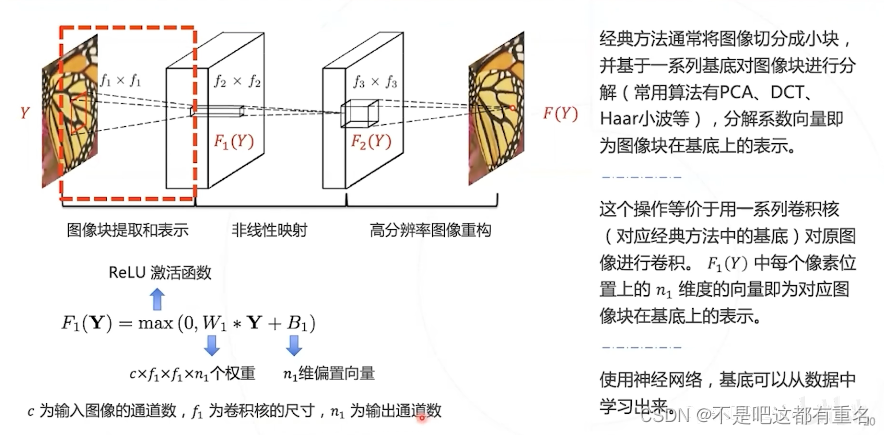
SRCNN的单个卷积层有明确的物理意义:
- 第一层:提取图像块的低层次局部特征;
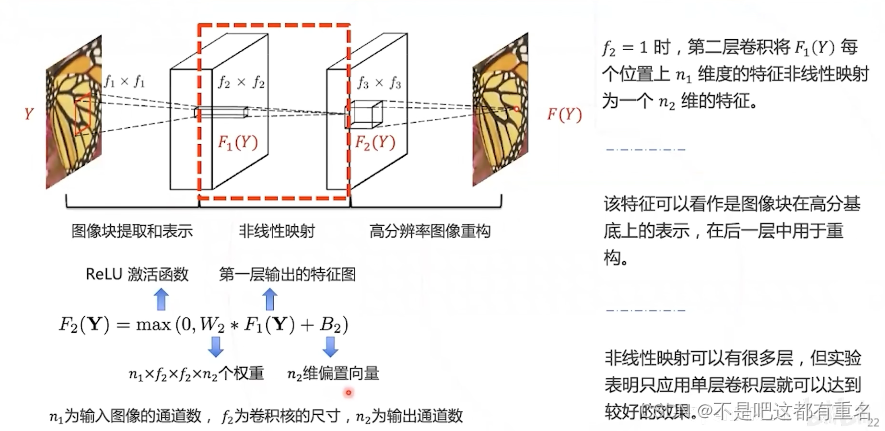
- 第二层:对低层次局部特征进行非线性变换,得到高层次特征;
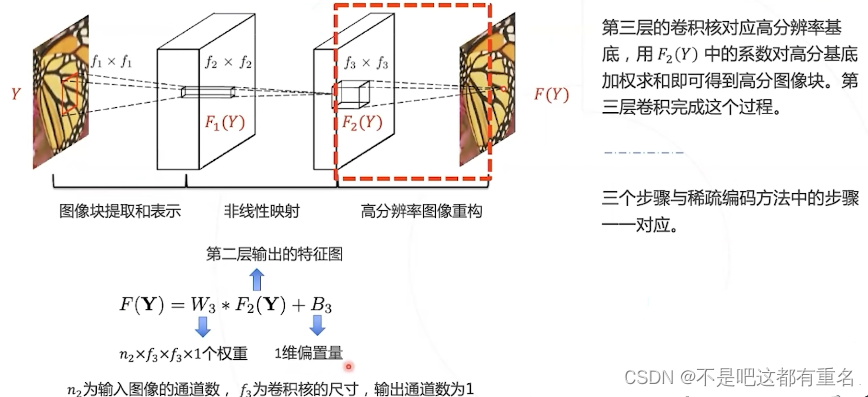
- 第三层:组合领域内的高层次特征,恢复高清图像
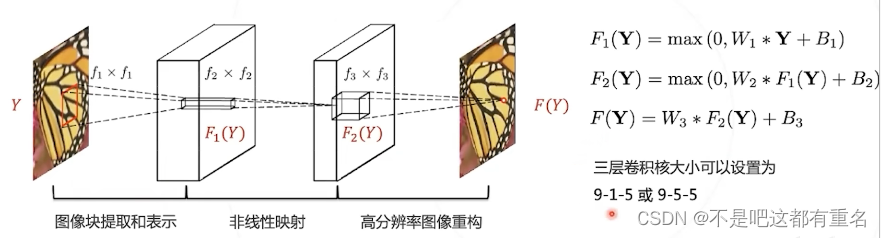
第一层:特征提取
第二层:非线性映射
第三层:图像重构
SRCNN的训练

SRCNN的性能

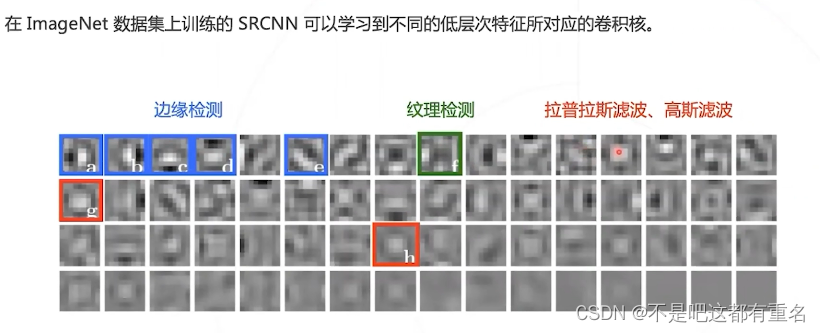
SRCNN在性能和速度上全面超越深度学习前的算法
SRCNN的速度问题
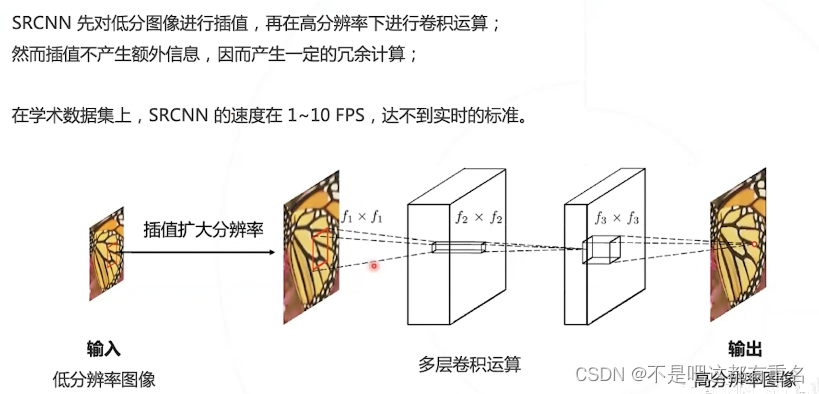
2.2 Fast SRCNN(2016)
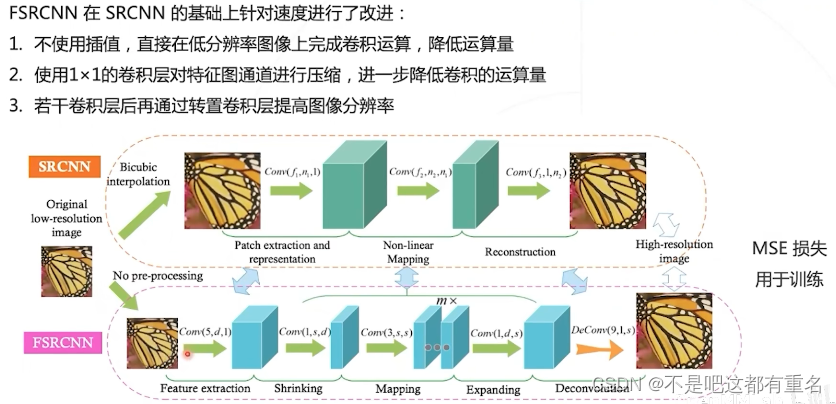
缩小层和放大层
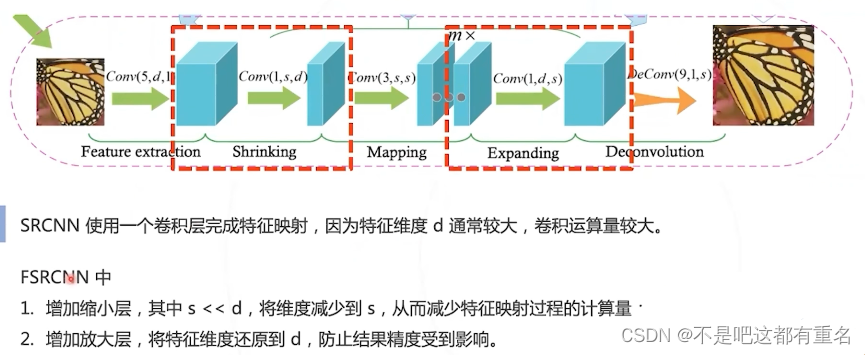
FSRCNN的优势

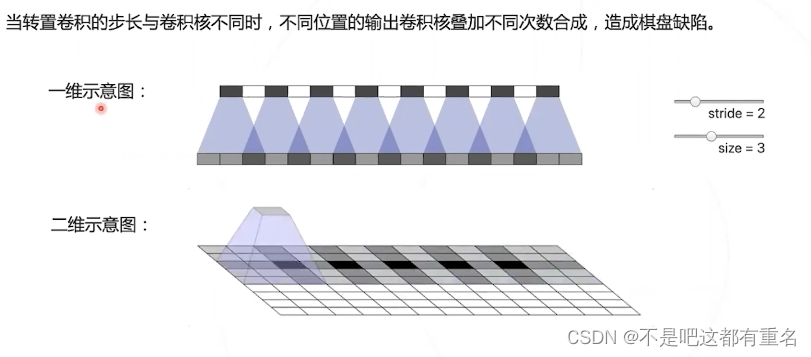
转置卷积的缺陷
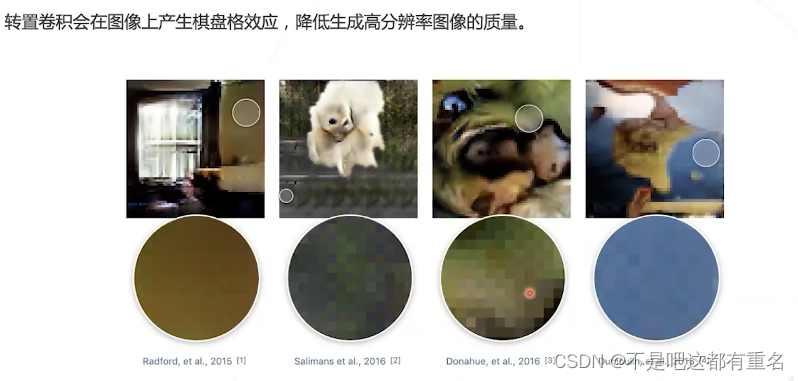
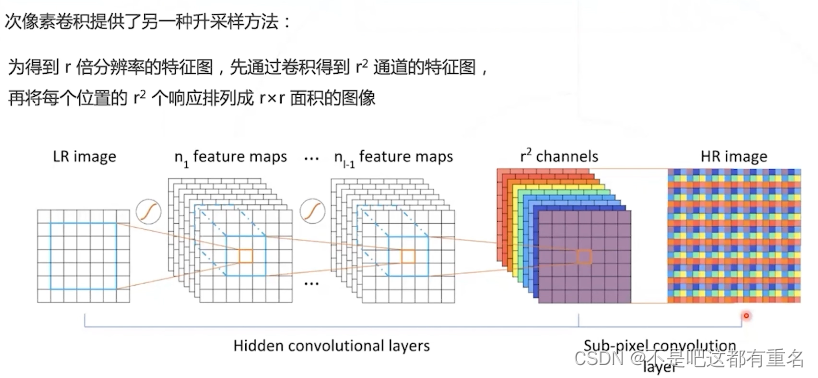
改进:次像素卷积 Subpixel convolution
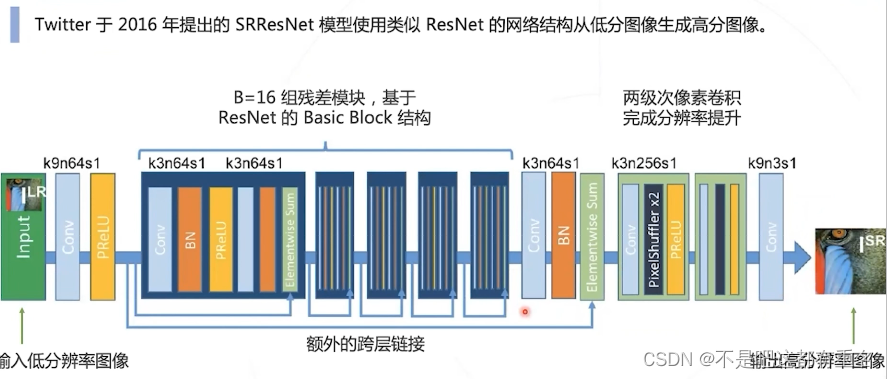
2.3 SRResNet(2016)
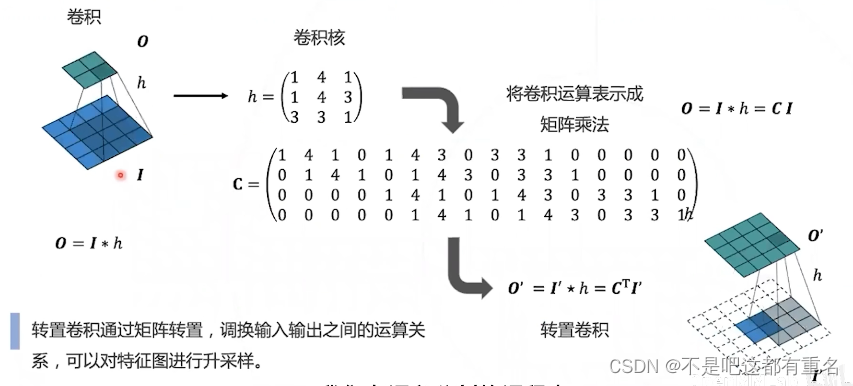
2.4 补充知识
转置卷积
3.图像超分辨率中的常用损失函数
3.1 均方误差

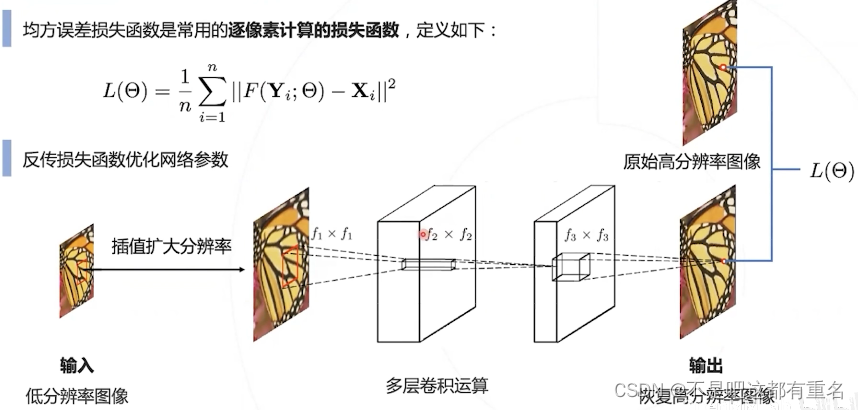
效果:

3.2感知损失函数

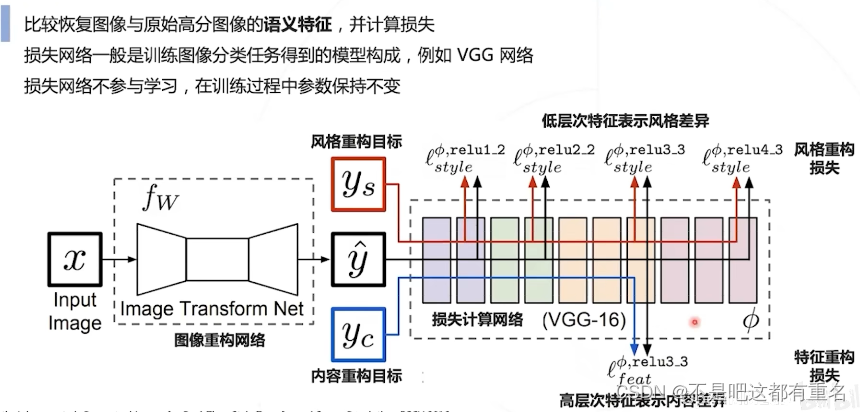

效果

4.对抗生成网络GAN简介
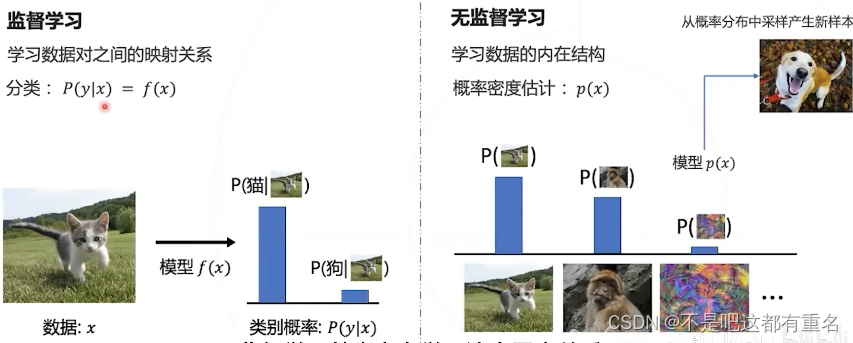
4.1什么是对抗生成网络?
对抗生成网络是一种基于神经网络的无监督学习模型,可以建模数据的分布,并通过采样生成新数据。
4.2应用
使用GAN生成图像

使用GAN转译图像

GAN应用于超分辨率

4.3 GAN的基本思想
图像数据在高纬空间的分布
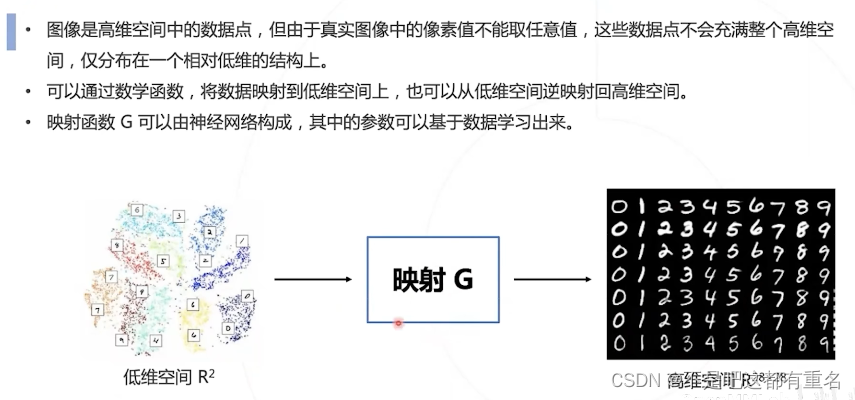
用神经网络表示数据分布

如何学习生成器网络
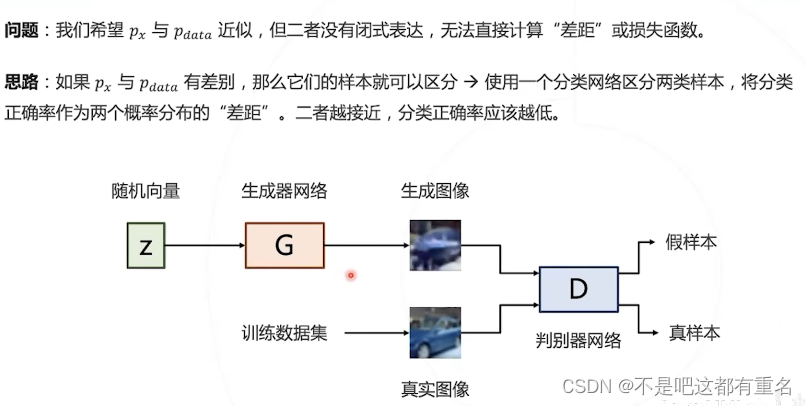
对抗训练
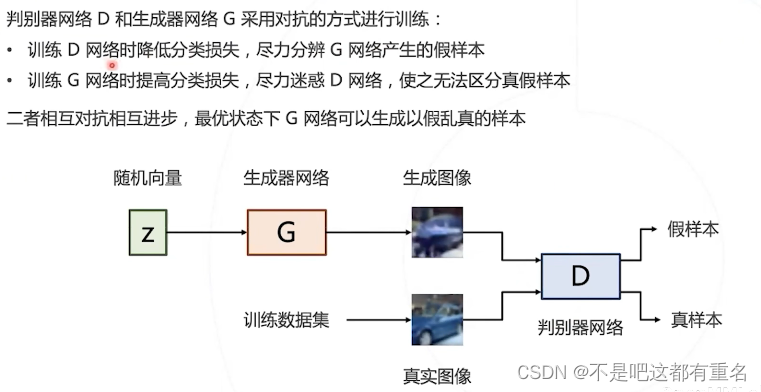
GAN的优化目标

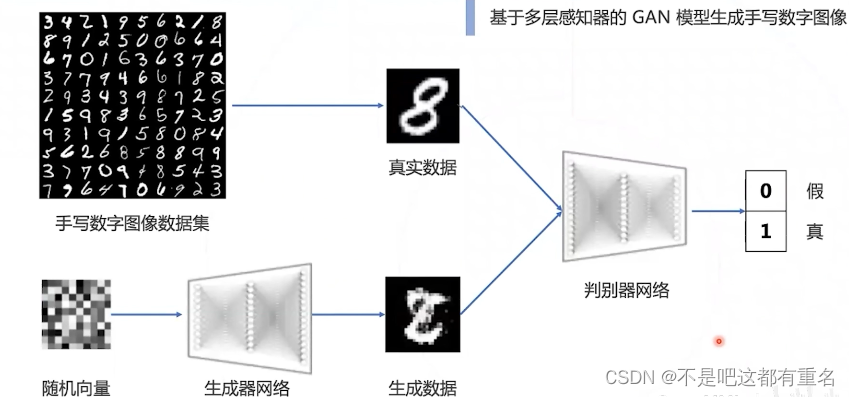
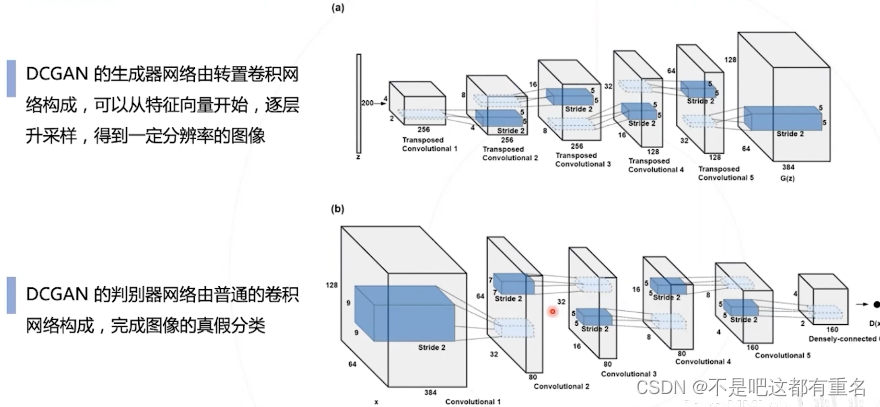
4.4 GAN模型
基于多层感知器的GAN模型
Deep Convolutional GAN ,DCGAN
4.5 GAN应用于图像超分辨率
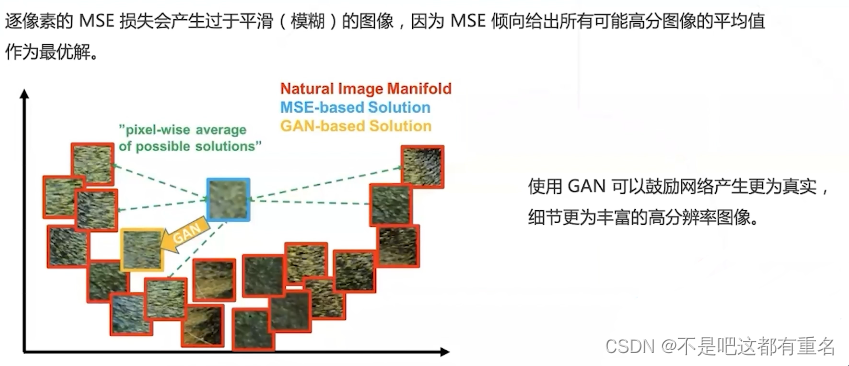
5.基于GAN的模型SRGAN与ESRGAN
5.1 SRGAN 2017
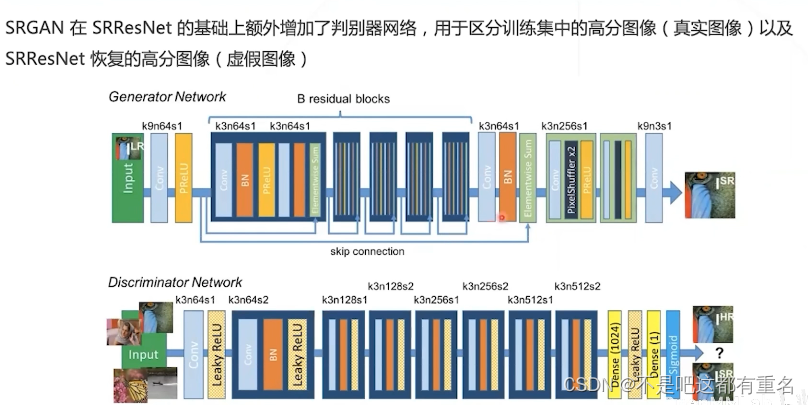
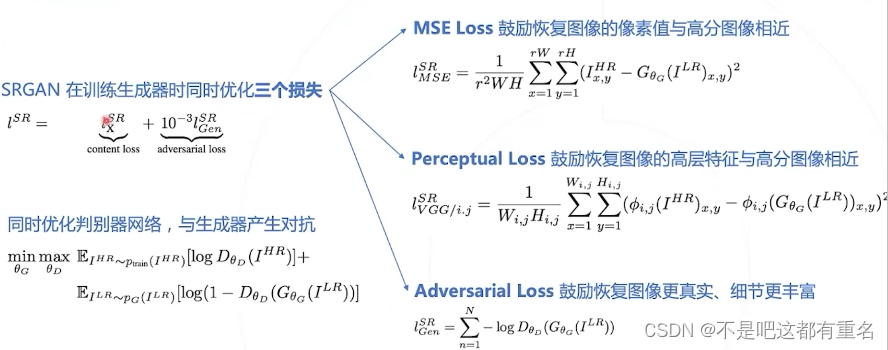
SRGAN的训练
5.2 Enhanced SRGAN 2018

网络结构部分:使用RRDB模块替换残差模块
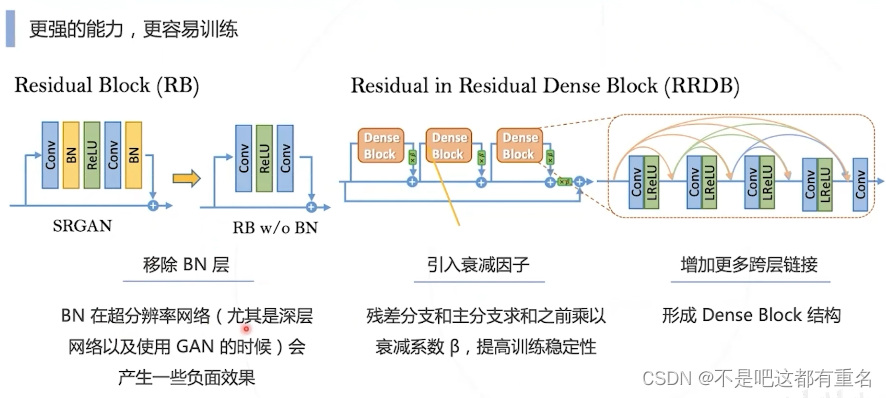
判别器部分:使用RaGAN替换GAN
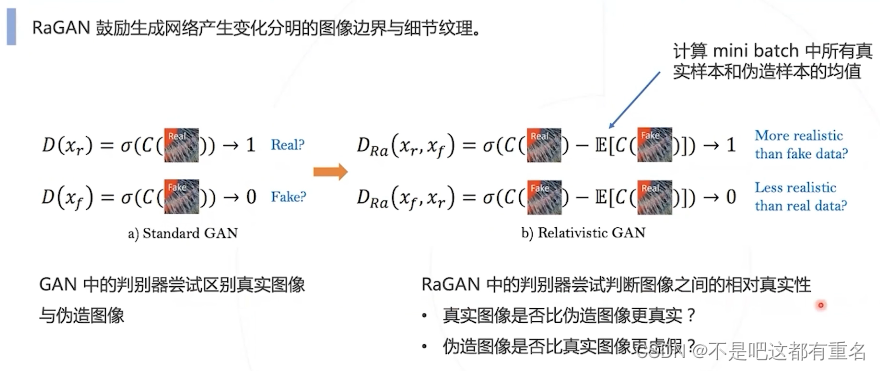
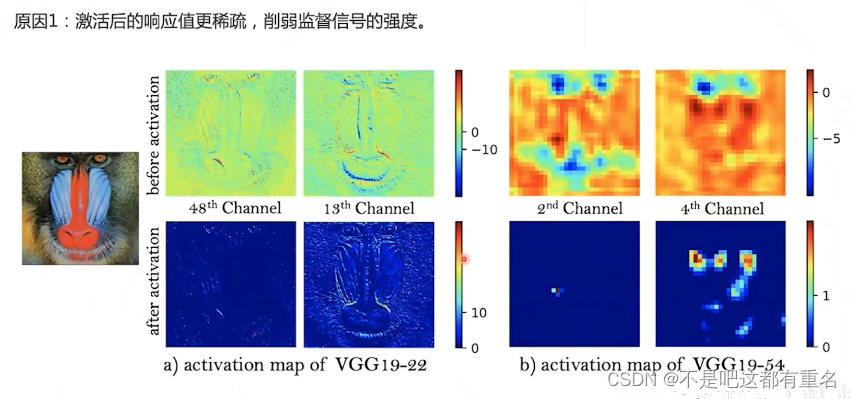
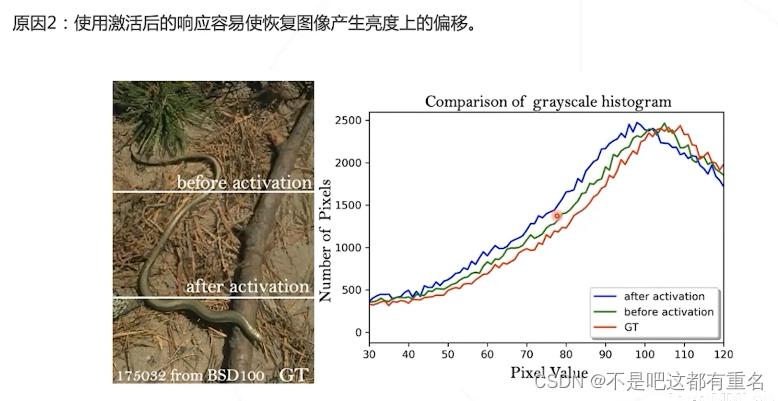
损失部分:使用非线性激活前的响应计算感知损失

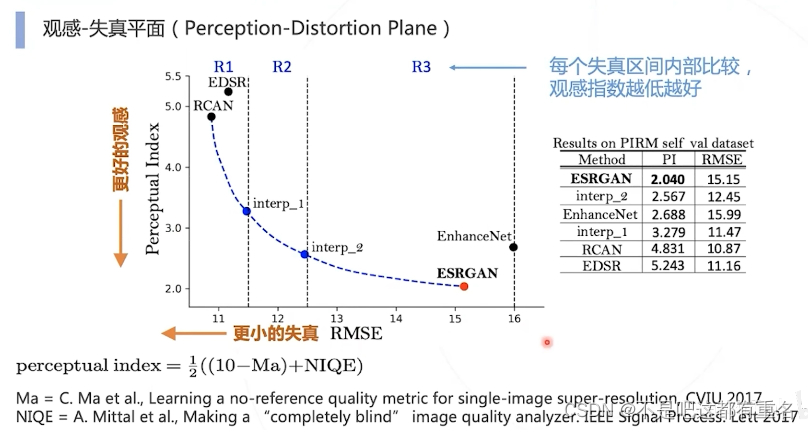
ESRGAN的性能比较
6.视频超分辨率介绍

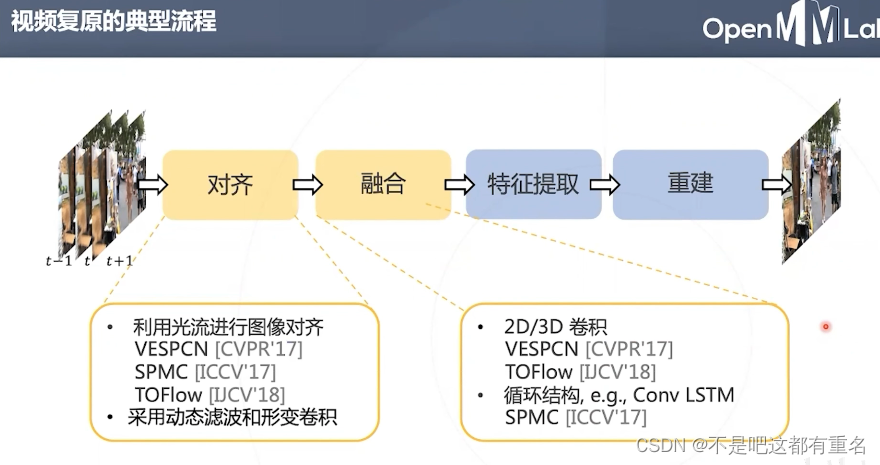
6.1 EDVR
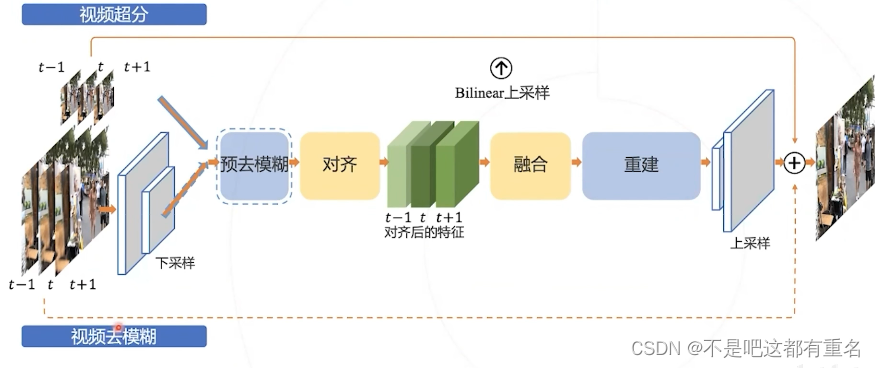
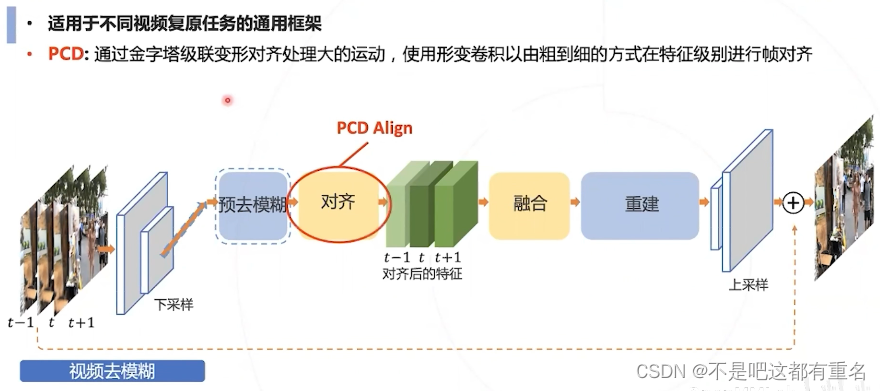
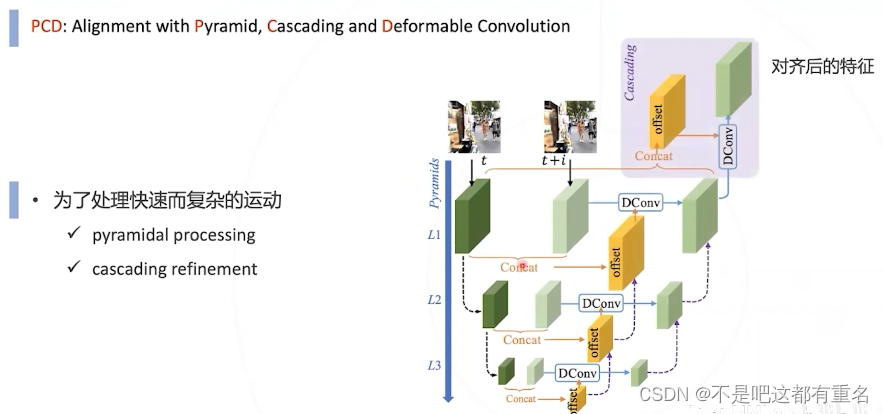
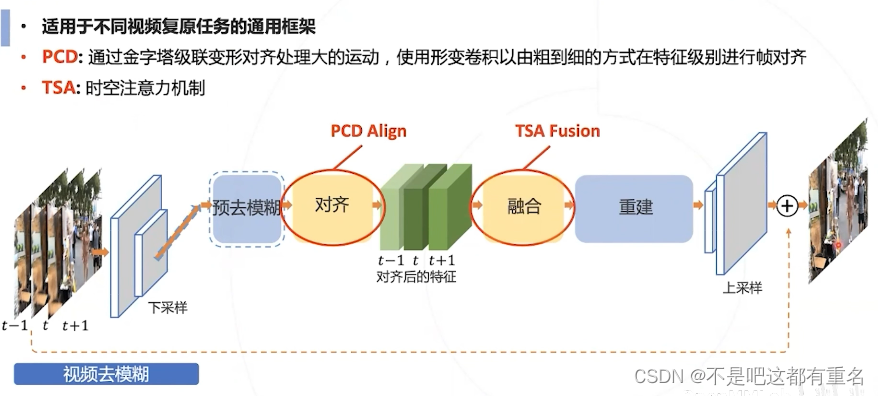
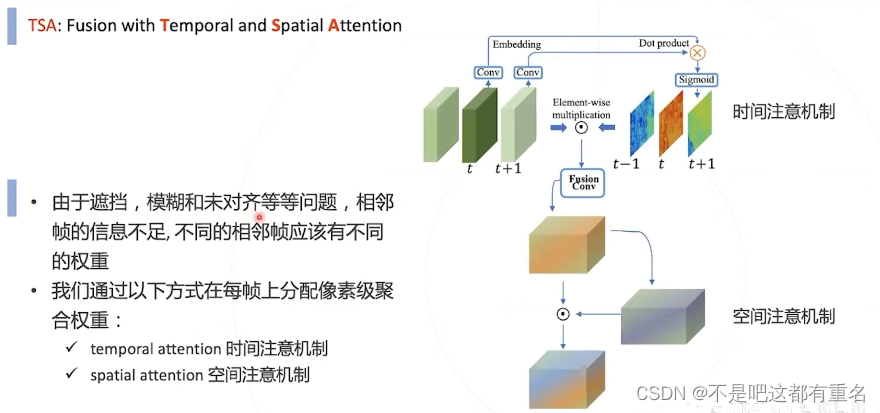
效果

6.2 BasicVSR 2021
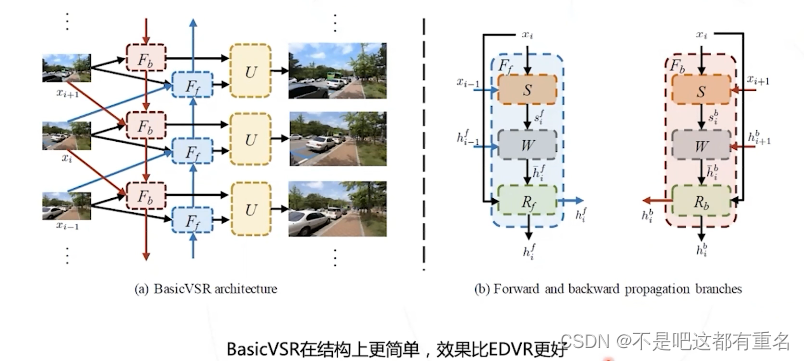
6.3 补充知识
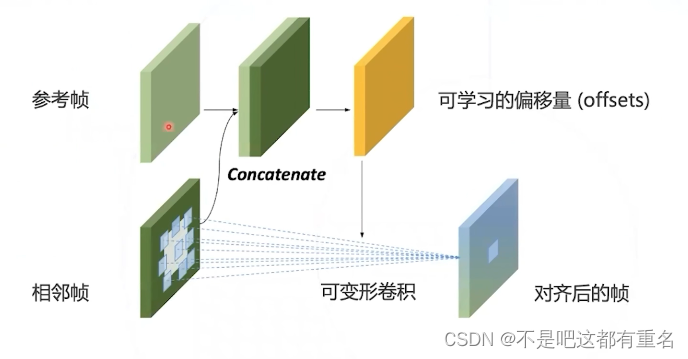
形变卷积
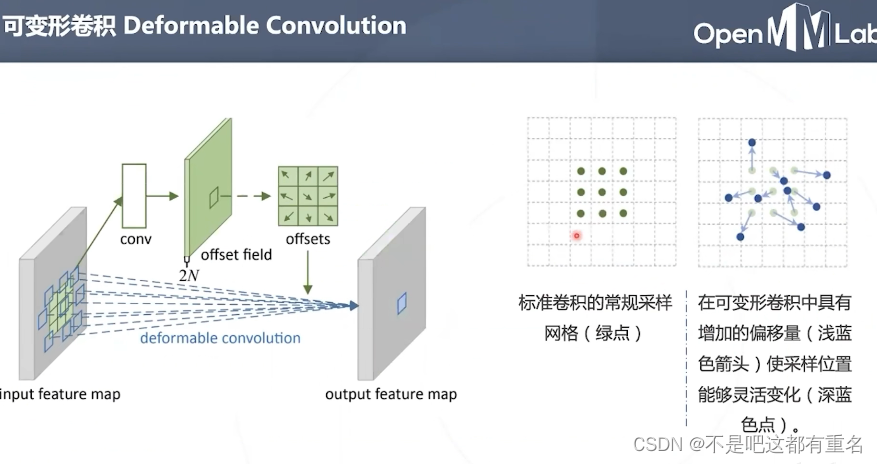
用于对齐的可形变卷积