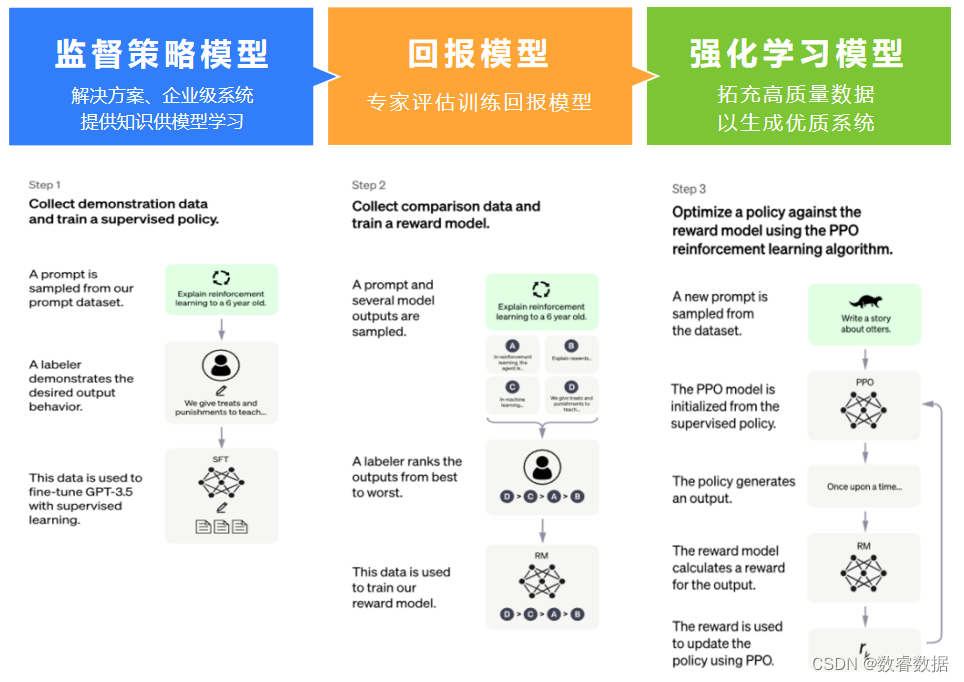
深度优先搜索(Depth-First Search,DFS)是一种经典的图形搜索算法,用于在图或树中遍历所有节点。它是一种递归算法,它通过深入到树或图的最深层来遍历节点,并且在回溯时继续搜索其他分支。
深度优先搜索的核心思想是递归和回溯。该算法的基本思路是从根节点开始遍历,深入到树或图的最深层,然后回溯并搜索其他分支。当访问到一个节点时,它会被标记为已访问,然后遍历它的相邻节点。该过程会一直进行,直到找到目标节点或遍历完所有节点。
深度优先搜索可以使用递归或栈实现。在递归实现中,搜索过程通过调用函数来实现,每次递归调用都会将当前节点的相邻节点添加到调用栈中。在栈实现中,搜索过程使用一个栈来存储未访问的节点,并且在访问每个节点时将其弹出并将其相邻节点推入栈中。
下面是一个使用递归实现深度优先搜索的示例代码:
# 定义节点类
class Node:def __init__(self, value):self.value = valueself.visited = Falseself.neighbors = []def add_neighbor(self, node):self.neighbors.append(node)# 定义深度优先搜索函数
def dfs(node):node.visited = Trueprint(node.value)for neighbor in node.neighbors:if not neighbor.visited:dfs(neighbor)# 创建节点并添加邻居
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node4 = Node(4)node1.add_neighbor(node2)
node1.add_neighbor(node3)
node2.add_neighbor(node4)
node3.add_neighbor(node4)# 调用深度优先搜索函数
dfs(node1)
在上面的示例中,我们首先定义了一个节点类来表示图中的节点。节点包括值、访问标志和相邻节点。然后我们定义了一个深度优先搜索函数dfs,它采用递归方式实现。该函数首先将当前节点标记为已访问并输出其值。然后它遍历节点的相邻节点,如果它们没有被访问过,就递归调用dfs函数来访问它们。
深度优先搜索的应用非常广泛,包括图论、人工智能、自然语言处理等领域。在图论中,深度优先搜索常用于寻找图中的环、连通分量、拓扑排序等问题。在人工智能和自然语言处理中,深度优先搜索被广泛应用于语义分析、机器翻译、语音识别等任务中。
除了递归和栈,深度优先搜索还可以使用迭代加深搜索(Iterative Deepening Depth-First Search,IDDFS)实现。IDDFS是一种迭代算法,它使用深度限制来控制深度优先搜索的深度。它从深度为1的搜索开始,逐步增加搜索深度,直到找到目标节点或搜索完整个图。
下面是一个使用迭代加深搜索实现深度优先搜索的示例代码:
# 定义节点类
class Node:def __init__(self, value):self.value = valueself.visited = Falseself.neighbors = []def add_neighbor(self, node):self.neighbors.append(node)# 定义深度优先搜索函数
def dfs(node, depth, target):if depth == 0 and node.value == target:return Trueif depth > 0:node.visited = Trueprint(node.value)for neighbor in node.neighbors:if not neighbor.visited and dfs(neighbor, depth-1, target):return Truenode.visited = Falsereturn False# 定义迭代加深搜索函数
def iddfs(start, target):depth = 0while True:if dfs(start, depth, target):return Truedepth += 1reset_visited(start)# 重置所有节点的访问标志
def reset_visited(node):node.visited = Falsefor neighbor in node.neighbors:if neighbor.visited:reset_visited(neighbor)# 创建节点并添加邻居
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node4 = Node(4)node1.add_neighbor(node2)
node1.add_neighbor(node3)
node2.add_neighbor(node4)
node3.add_neighbor(node4)# 调用迭代加深搜索函数
iddfs(node1, 4)
在上面的示例中,我们首先定义了一个节点类来表示图中的节点。然后我们定义了一个深度优先搜索函数dfs和一个迭代加深搜索函数iddfs。dfs函数使用递归方式实现深度优先搜索,而iddfs函数使用深度限制来控制搜索深度,并在搜索完整个图后返回False。
我们还定义了一个辅助函数reset_visited来重置所有节点的访问标志,以便在搜索完整个图后重新开始搜索。
最后,我们创建了一个简单的图,并使用dfs函数来遍历图中的节点。当我们找到目标节点时,dfs函数返回True,并停止搜索。如果搜索完整个图后仍未找到目标节点,则返回False。
下面是一个使用迭代加深搜索算法实现深度优先搜索的示例代码:
# 定义节点类
class Node:def __init__(self, value):self.value = valueself.visited = Falseself.neighbors = []def add_neighbor(self, node):self.neighbors.append(node)# 定义深度优先搜索函数
def dfs(node, target):if node.value == target:return Truenode.visited = Trueprint(node.value)for neighbor in node.neighbors:if not neighbor.visited and dfs(neighbor, target):return Truenode.visited = Falsereturn False# 定义迭代加深搜索函数
def iddfs(root, target):depth = 0while True:if dfs_limit_depth(root, target, depth):return Truedepth += 1# 定义有深度限制的深度优先搜索函数
def dfs_limit_depth(node, target, depth):if depth == 0 and node.value == target:return Trueif depth > 0:node.visited = Truefor neighbor in node.neighbors:if not neighbor.visited and dfs_limit_depth(neighbor, target, depth - 1):return Truenode.visited = Falsereturn False# 创建节点并添加邻居
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node4 = Node(4)node1.add_neighbor(node2)
node1.add_neighbor(node3)
node2.add_neighbor(node4)
node3.add_neighbor(node4)# 调用迭代加深搜索函数
iddfs(node1, 4)
在上面的示例中,我们首先定义了一个节点类来表示图中的节点。然后我们定义了一个深度优先搜索函数dfs,它使用回溯算法实现深度优先搜索。接着我们定义了一个迭代加深搜索函数iddfs,它使用dfs_limit_depth函数实现有深度限制的深度优先搜索。
我们创建了一个简单的图,并使用iddfs函数来遍历图中的节点。当我们找到目标节点时,iddfs函数返回True,并停止搜索。如果搜索完整个图后仍未找到目标节点,则返回False。
在深度优先搜索中,迭代加深搜索算法是一种非常有用的算法。它可以帮助我们在搜索过程中逐步增加深度限制,并避免在无限深度的情况下陷入死循环。这样可以提高搜索效率,并节省搜索时间和空间。