今天在看半监督的时候,突然想起这个问题:
半监督用训好的模型去生成伪标签,再把伪标签当做真标签去训,但是模型能生成伪标签说明模型已经学到了这部分内容,把模型已经学会的内容加进去,让模型继续学,能学出什么新东西呢?
去知乎搜了一下,一张图简洁明了地解决了我的疑问,太有力了,所以记录一下。
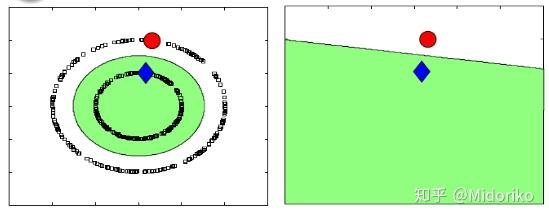
比如这张图展示的分布,如果我们一开始只有红蓝两个点是labelled,那么我们直接分,只能分出右边的情况。
但是使用半监督,我们不断地用已有的数据,给新的未标签的数据打标签,就可以变成左边这种分类器。
所以,半监督的意义是,在给未标注的数据打标签的过程中,我们实际上还是引入了新的信息:真实的数据分布。
如果某个场景里用半监督不能引入这个信息,那么在那个场景里半监督是无效的。
顺便记录一下查询过程中了解的直推式学习。
直推式学习不同于一般的归纳式学习,它是可以看到测试集的。
核心思想就是,我们常用的归纳型学习是通过在训练集上优化并学习,但是我们的最终目标是在数据集上做得好,并不是很在乎训练集上能有多少准确度。所以,可以把测试集的情况也拿进来看到,在这种前提下,去预测测试集的结果。(有点像半监督学习的作用对吧)
但是他的缺点在于,不同于归纳式学习学好了之后,如果有新的数据,直接塞进模型预测就好。直推式学习每引进一个新的测试数据,都要重新训练。