点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达

作者丨孙裕道
编辑丨极市平台
导读
人脸识别的可解释性是深度学习领域中的一个很大挑战,当前的方法通常缺乏网络比较和量化可解释结果的真相。本文作者定义了一种新的评估方案,称为“修复游戏”,通过生成一个网络注意力图,为量化评价哪些图像区域有助于人脸匹配提供了基本事实。

论文标题:Explainable Face Recognition
论文链接:https://arxiv.org/abs/2008.00916
论文代码:https://github.com/stresearch/xfr
论文发表:ECCV2020
合作单位:剑桥Visym实验室
引言
众所周知,理解和解释深度学习模型是一个比较有挑战的事情,因为大规模训练的深度卷积网络被认为是黑盒系统,也许我们可以对训练的数据集和损失函数有一定的了解,但是对深度模型的学习过程以及生成的预测的理解确实很有限。自然深度学习中的很重要领域人脸识别的可解释性也是一个很大的挑战,当前在这方面探索的方法有网络注意力、网络解剖或综合语言解释,然而,缺乏网络比较和量化可解释结果的真相,尤其是在人脸识别中近亲或近亲之间的差异很微妙,解释并不明显。在该论文中作者定义了一种新的评估方案,称为“修复游戏”,其任务是生成一个网络注意力图,最好地解释图像中的哪些区域与匹配的图像匹配,这为量化哪些图像区域有助于人脸匹配提供了基本事实。
论文贡献
该论文的贡献可以归结为如下三点,分别如下所示
XFR baseline:作者基于五种网络注意力算法为XFR(人脸识别的可解释性)提供了baseline,并在三个用于人脸识别的公开深度卷积网络上进行了评估:LightCNN、VGGPFACE2和SNET-101。
图像修复游戏协议和数据集:作者提供标准化评估协议和数据集,用于细粒度的人脸识别可视化。这为客观地比较XFR系统提供了一个量化指标。
XFR评估:作者首次对图像修复协议的baseline算法进行了全面的评估,从而得出关于这些方法在真实图像上解释的实用性的结论。
模型介绍
人脸识别的可解释性(XFR)
该论文的创新点可能是从Facenet中得到一定的灵感。XFR的目的是解释人脸图像之间的匹配的内在关系。如下图所示,给定一个三元组(probe,mate,nonmate),XFR算法的任务是生成一个显著图(最大化probe图像与mate图像相似性和最小化probe图像与nonmate图像相似性)。先前的工作表明,面部之间的成对相似性主要受眼周区域和鼻子的影响。眼周区域和鼻子几乎总是用于面部分类,但这对于解释更精细的辨别水平没有太大帮助。作者的目标是突出probe中与假定mate更相似,同时与nonmate不太相似的区域。这个三元组(probe,mate,nonmate)为面部区域的相对重要性提供了一个比面部类别激活图更深层次的解释。

激励反向传播(EBP)
激励反向传播(EBP)将网络注意力建模为一个概率赢家通吃的传播过程。EBP计算穿越到卷积网络中给定节点的概率,概率是由正权重和非负权重激活得来。EBP的输出是一个显著图,它定位了图像中对于给定类别的区域。EBP的原始公式考虑了交叉熵损失,以优化训练集中的最大分类。在该论文中在作者提出了一个新的公式,给定一个mate(m)、nonmate(n)和probe(p)的三个编码向量,其中损失函数如下所示:
这里使用编码向量之间的欧几里德距离的平方来捕获相似性,使得当从probe到mate的距离小(相似性高)并且从probe到nonmate的距离大(相似性低)时,损失最小化,其中公式中具有余量项 。
子树EBP
在该论文中作者介绍了子树EBP算法,这是一种新的白盒的XFR方法。给定一个三元组(probe,mate,nonmate)图像,计算损失函数 相对于网络中每个节点 的梯度,其中mate编码向量和nonmate编码向量被假定为常数,并且相对于probe图像计算梯度。作者按 递减顺序对每个节点的梯度进行排序,并选择正梯度最大的前k个节点。从每个选择的内部节点构建k个EBP显著图 ,然后进行加权凸组合,其中权重为 ,则有如下公式:
其中权重由损失 梯度给出,并且归一化为和为1。这形成了最终的子树EBP显著图。
DISE
基于密度的解释输入采样(DISE)是该文介绍的第二种新的白盒XFR方法。DISE是随机输入抽样的一种扩展,使用先验密度来辅助抽样。先前的工作已经构建了与特定类别相关联的显著图,方法是通过掩模来随机扰动输入图像,然后使用黑盒系统对其进行评估。但是这些方法生成的掩模会均匀地遮挡输入图像,像这种采样过程是低效的。在该论文中作者通过引入先验分布来指导采样并进行改进,输入采样的先验密度是从具有三重损失的白盒EBP得到的,如下图所示显示了论文中该方法的概述,该方法利用灰色(即屏蔽像素)来遮挡probe图像中的小区域,利用EBP得到的先验密度并进行采样,并为给定(probe,mate,nonmate)计算三重损失的数值梯度,可以发现具有大数值梯度的掩模在累积显著性图中权重更大。

非均匀先验掩模
先前对面部识别的辨别特征的研究表明,面部最重要的区域通常位于眼睛和鼻子内和周围。如上图所示使用VGG-16网络作为白盒面部分类器为泰勒·斯威夫特的probe图像计算的该显著图的示例。使用这个显著图作为生成随机掩模的先验概率,允许对最显著的空间进行采样比在整个图像上假设均匀概率更有效地影响损失的掩模,这可以进一步有效地消除了掩模不重要的背景元素的可能性。
Numerical gradient
给定已经用从非均匀先验采样的稀疏掩模的probe图像,可以计算三重损失的数值梯度。设 为probe的编码向量, 为mate图像嵌向量, 为nonmate图像向量, 为掩模的probe向量。则三重损失的数值梯度可以近似为:
数值梯度是真实损失梯度的近似值,该损失梯度是通过用像素掩模来扰动输入,并计算三重损失的相应变化。当probe和nonmate之间相似性减少时,数值梯度会变大,显著性特征会得到累积。
实验结果
在该论文中,论文的目标是突出给定一个人脸图像相对于一个相似身份进行匹配的区域,作者把定量评估的整体策略称为图像修复游戏。
图像修复游戏
图像修复游戏评估的概述如下图所示。图像修复游戏使用四个(或更多)图像进行每次评估:probe图像、mate图像、修复的probe图像和修复的nonmate图像,其中面部固定区域(如眼睛、鼻子或嘴)的probe会有细微的不同。类似地,修复后的nonmate或mate形象有细微的不同。修复的probe 和修复的nonmate被约束为相同的新身份。对于每个三元组,XFR算法的任务是估计每个像素属于一个区域的可能性,该区域对于将probe匹配到mate 身份是有区别的,这些有区别的像素估计最终形成了显著图。通过应用阈值将每个像素分类,这就形成了二进制显著图。

人脸识别的修复数据集
构建图像修复数据集的一个关键挑战是要确修复后的图片与原图片表示的是不同的身份。大多数修复的图像在相似性上与特定网络的原始配对身份没有足够的差异。实验中需要能够使用最近匹配协议和验证协议来区分这些身份,以便将目标网络的验证匹配阈值校准在一个较低误报率中。每个三元组必须满足以下标准,才能包含在给定网络的数据集中:原始probe需要更类似于原始配对身份,并且在校准验证阈值处被正确验证为原始配对身份。如上所述为每个目标网络过滤修复数据集,产生特定于该目标网络的数据集。在该论文的实验中,对于基于ResNet-101的网络,最终过滤的数据集包括84个身份和543个三元组,这是从95个身份和3648个三元组中过滤下来。性能较低的网络通常比性能较高的网络具有更少的满足选择要求的三元组,因为它们不能辨别修复probe图像中的许多细微变化。
评估指标
XFR算法估计每一个像素属于一个区域的可能性,该区域对于将probe图像与mate的身份相匹配。这些有区别的像素估计形成显著图,其中最亮的像素被估计最有可能属于有区别的区域。下图显示出了两个阈值处的示例和显著性预测,其中显著性预测作为二进制掩模在不同的阈值处展示出来。在该论文中作者使用经典的ROC曲线来评估图像修复游戏。如下图所示,通过扫描像素显著性估计的阈值,并通过使用修复区域作为正/显著区域和未修复区域作为负/不显著区域来计算真实接受率和误报率,可以生成ROC曲线。另外在该论文中,作者使用平均非状态分类率来代替显著性分类的真阳性率。通过扫描显著性阈值被分类为显著的像素被来自“修复探针”的像素替换,该“修复探针”不被提供给显著性算法。然后,这些“混合探针”可以让被测试的网络分类为原始身份或修复的非原始身份。高性能的XFR算法将正确地为修补区域分配更多的显著性,这将改变混合探针的身份,而不会增加像素显著性分类的误报率。假阳性率是根据所有三元组的显著像素分类计算的,使用混合探针的基本真值掩码。平均非移动分类率由每个组中的三元组数量加权过滤数据集的面部区域,以避免子协议的偏差。度量的输出曲线示例如下图所示。

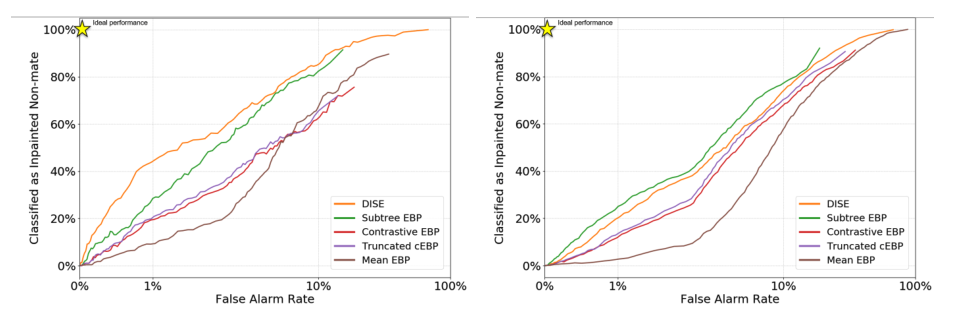
实验数据
作者使用三个目标网络在修复数据集上运行修复游戏评估协议分别是LightCNN,VGGFace2。
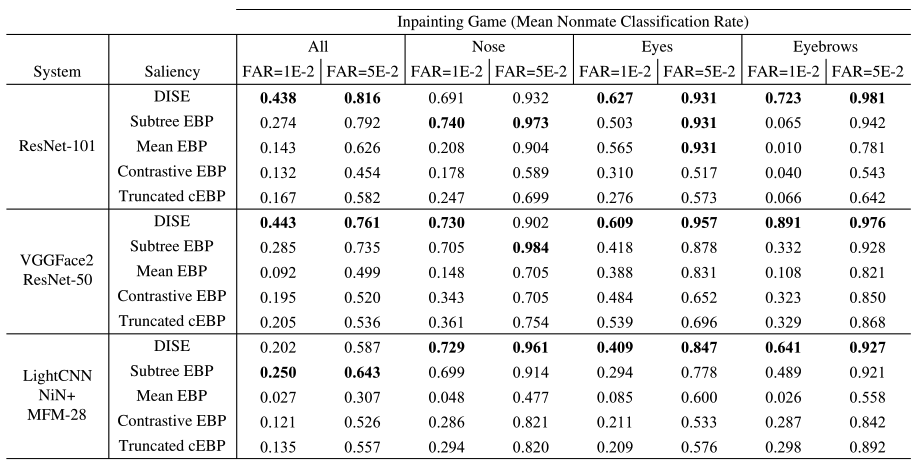
ResNet-50和一个定制训练的ResNet-101。评估结果如下表所示:显示了网络和XFR算法的每种组合,整个协议和三个子协议(仅眼睛、鼻子和眉毛)的两种误报率。显示了网络和XFR算法的每种组合,整个协议和三个子协议(仅眼睛、鼻子和眉毛)的两种误报率。论文中的补充材料中的附加结果显示了各个面部区域的结果。总的来说,结果显示对于更深的网络(ResNet-101,ResNet-50),性能最好的XFR算法是DISE。然而,对于较浅的网络,表现最好的算法是子树EBP算法。这两种新的方法都远远超过了最先进的方法。所以可知DISE的表现优于子树EBP,因为子树EBP不能定位图像区域比底层网络更好地代表面部。考虑补充材料中的眉毛子协议结果,这表明子树EBP不能独立于眼睛表示眉毛。DISE可以独立于底层目标网络掩蔽图像区域,并正确定位眉毛效果。
◎作者档案
作者:孙裕道
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 






