前言
哲学提问镇贴:

不了解异步怎么使用的看官, 可阅:
SpringBoot 最简单的使用异步线程案例 @Async_小目标青年的博客-CSDN博客
Springboot Async异步扩展使用 结合 CompletableFuture_小目标青年的博客-CSDN博客
想了解更多关于批量list处理操作的看官,可阅:
Java List数据量大, 需要分片批次操作_小目标青年的博客-CSDN博客
Mybatis 批量插入 采用分批处理一次500条_小目标青年的博客-CSDN博客
Springboot 手动分页查询,分批批量插入数据_小目标青年的博客-CSDN博客
正文
话不多说,本篇核心介绍的是日常毕竟常遇到的一些处理点。
首先list数据量大,需要切割操作 :
//模拟拿到的数据量大的listList<Product> products = getBatchListTest();//直接用Lists.partition 按照100条一次切割List<List<Product>> allList = Lists.partition(products, 100);//循环分批处理切割的listfor (List<Product> batchProducts :allList){productService.batchDealList(batchProducts);}
但是往往有时候 数据量是真大,切割完循环处理 还嫌慢 。
是的,因为循环处理是串行的, 也就是,比如500条数据的list,切割成5个 batchList。
如果每次处理一个barchList要1秒钟,那么循环串行处理5次,就是 1X5=5 秒。
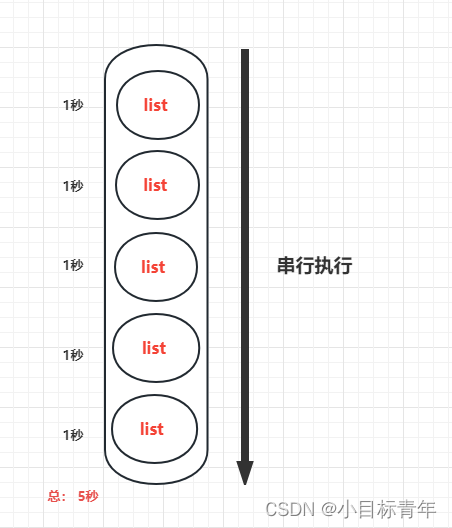
所以我们分批切割这样串行处理完,觉得慢, 如果业务场景合适,我们可以试着改 并行 处理。
开袋及食:
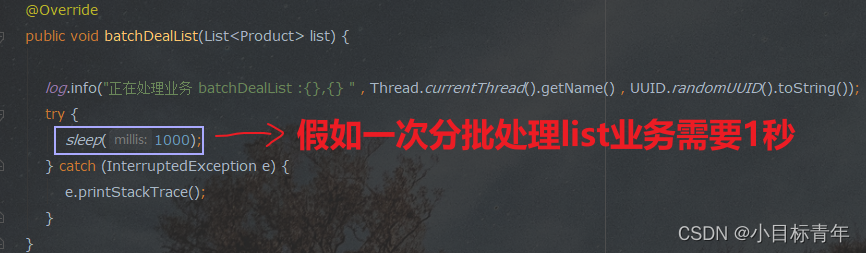
① 配置一个线程池,交给spring管理的 线程池,用起来才放心、安心:
ThreadConfig.java
import java.util.concurrent.Executor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;@Configuration
@EnableAsync
public class ThreadConfig {/*** 执行需要依赖线程池,这里就来配置一个线程池* @return*/// 当池子大小小于corePoolSize,就新建线程,并处理请求// 当池子大小等于corePoolSize,把请求放入workQueue(QueueCapacity)中,池子里的空闲线程就去workQueue中取任务并处理// 当workQueue放不下任务时,就新建线程入池,并处理请求,如果池子大小撑到了maximumPoolSize,就用RejectedExecutionHandler来做拒绝处理// 当池子的线程数大于corePoolSize时,多余的线程会等待keepAliveTime长时间,如果无请求可处理就自行销毁@Bean("MyExecutor")public Executor getExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();//设置核心线程数executor.setCorePoolSize(10);//设置最大线程数executor.setMaxPoolSize(100);//线程池所使用的缓冲队列executor.setQueueCapacity(250);//设置线程名executor.setThreadNamePrefix("JcTest-Async");//设置多余线程等待的时间,单位:秒//executor.setKeepAliveSeconds();// 初始化线程executor.initialize();return executor;}
}
看看我们并行的写法:
@AutowiredThreadConfig threadConfig;@PostMapping("doBatchParallelTes")public void doBatchParallelTes() {List<Product> products = getBatchListTest();List<List<Product>> allList = Lists.partition(products, 100);int batchNum = allList.size();StopWatch stopWatch = new StopWatch();stopWatch.start();Executor threadConfigExecutor = threadConfig.getExecutor();List<CompletableFuture> results = new ArrayList<>();for (List<Product> batchProducts :allList){CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {productService.batchDealList(batchProducts);return "";}, threadConfigExecutor);results.add(future);}CompletableFuture.allOf(results.toArray(results.toArray(new CompletableFuture[batchNum]))).join();stopWatch.stop();System.out.println("总用时"+stopWatch.getTotalTimeMillis()+"毫秒");}
代码简析: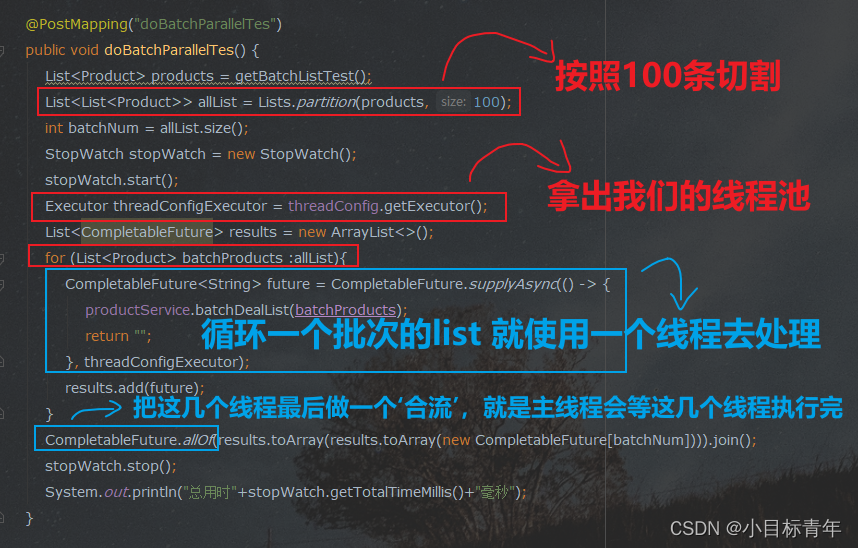
并行图解: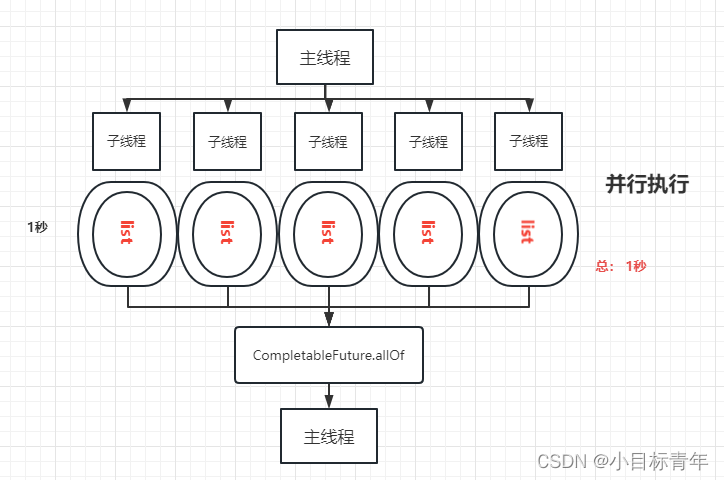
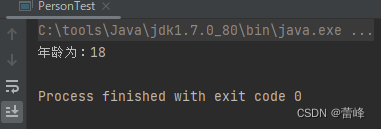
看看执行效果:
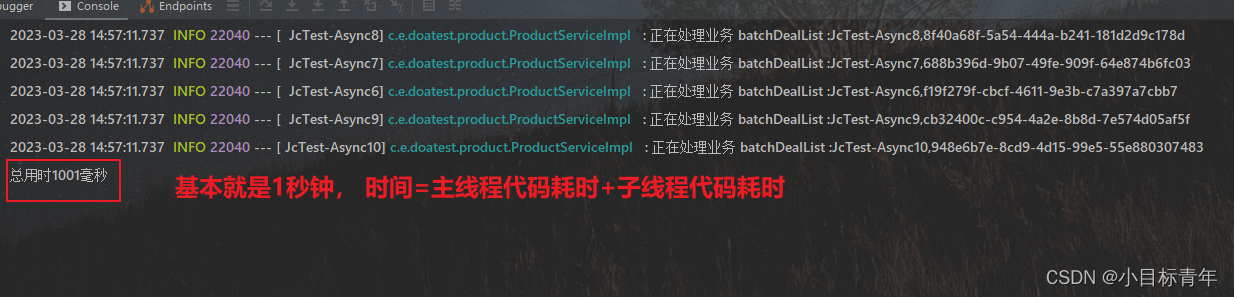
那么看到这里,大家一定注意到了那个 ‘合流’ , 是不是每个业务都需要这样所谓的‘合流’?
当然不是,如果说这批list处理完完事了,不需要考虑回到主线程去做其余操作,那么我们就不需要‘合流’操作。
不需要合流,主线程走主线程逻辑,子线程自己玩自己的:
@PostMapping("doBatchTestNew2")public void doBatchTestNew2() {List<Product> products = getBatchListTest();List<List<Product>> allList = Lists.partition(products, 100);StopWatch stopWatch = new StopWatch();stopWatch.start();Executor threadConfigExecutor = threadConfig.getExecutor();for (List<Product> batchProducts :allList){CompletableFuture.runAsync(() -> {productService.batchDealList(batchProducts);}, threadConfigExecutor);}stopWatch.stop();System.out.println("总用时"+stopWatch.getTotalTimeMillis()+"毫秒");}效果,其实就是异步执行:

那如果说是基于@Async 的方式去实现呢,当然也是可以的,示例:
基于@Async 就不多说了,这个在文章开头有介绍相关文章,之前写的,介绍过玩法,就是这两篇:
SpringBoot 最简单的使用异步线程案例 @Async_小目标青年的博客-CSDN博客
Springboot Async异步扩展使用 结合 CompletableFuture_小目标青年的博客-CSDN博客
好了,该篇就到这。