变分推断 (Variational Inference)
变分推断属于对隐变量模型 (Latent Variable Model) 处理的一种技巧,其概率图如下所示

我们将 X={x1,...xN}X=\{ x_1,...x_N \}X={x1,...xN} 看作是每个样本可观测的一组数据,而将对应的 Z={z1,...,zN}Z=\{z_1,...,z_N\}Z={z1,...,zN} 看作是该组数据对应的高维空间下的对应样本点,例如使用 XXX 表示一个班同学的所有成绩,而将 ZZZ 看作是同学的学习能力。对于更复杂的一些情况,例如图像生成任务,使用 XXX 表示数据集中的每张图像,而使用 ZZZ 表示更高维的信息,例如基于类别/语义等控制信息。
对于生成任务,我们经常希望利用观测数据 XXX 建模随机变量 xxx 的真实分布 p(x)p(x)p(x),使用 zzz 来辅助概率推导,那么核心点在于计算两个条件概率分布 p(x∣z)p(x|z)p(x∣z) 与 p(z∣x)p(z|x)p(z∣x),通常可以使用一些先验知识假定 p(x∣z)p(x|z)p(x∣z) 服从某种概率分布(例如对于学习能力为 ggg 的同学成绩假定服从在 ggg 附近的高斯分布),但对于 p(z∣x)p(z|x)p(z∣x),注意到
p(z∣x)=p(z)p(x∣z)p(x)p(z|x) = \frac{p(z)p(x|z)}{p(x)} p(z∣x)=p(x)p(z)p(x∣z)
zzz 是辅助建模的变量,可以假定其服从某已知的分布,但对于归一化项 p(x)p(x)p(x),有
p(x)=∫zp(x,z)dz=∫zp(z)p(x∣z)dzp(x) = \int_z p(x,z)dz = \int_z p(z) p(x|z) dz p(x)=∫zp(x,z)dz=∫zp(z)p(x∣z)dz
由于 zzz 是一个非常高维的信息,p(x)p(x)p(x) 是很难直接计算积分进行处理的,所以 p(z∣x)p(z|x)p(z∣x) 也是很难处理的,我们通常使用优化的方法来拟合出概率分布 p(z∣x)p(z|x)p(z∣x)
首先,我们考虑随机变量 zzz 与 xxx 之间的关系,假定 p(x)p(x)p(x) 表示真实的数据分布,即我们观测到的数据 x∼p(x)x\sim p(x)x∼p(x),q(z∣x)q(z|x)q(z∣x) 为任一条件概率分布(通常是使用模型拟合出来的分布),有
logp(x)=logp(x,z)−logp(z∣x)=logp(x,z)q(z∣x)−logp(z∣x)q(z∣x)\begin{align} \log p(x) &= \log p(x,z) - \log p(z|x) \nonumber \\&=\log\frac{p(x,z)}{q(z|x)} - \log\frac{p(z|x)}{q(z|x)} \nonumber \end{align} logp(x)=logp(x,z)−logp(z∣x)=logq(z∣x)p(x,z)−logq(z∣x)p(z∣x)
对左右两式计算关于隐变量 zzz 的期望,有
left=Ez∼q(z∣x)[logp(x)]=logp(x)∫zq(z∣x)dz=logp(x)right=Ez∼q(z∣x)[logp(x,z)q(z∣x)−logp(z∣x)q(z∣x)]=∫zq(z∣x)logp(x,z)q(z∣x)dz+∫zq(z∣x)logq(z∣x)p(z∣x)dz=∫zq(z∣x)logp(x,z)q(z∣x)dz+KL(q(z∣x)∣∣p(z∣x))\begin{align} \text{left} &= \mathbb E_{z\sim q(z|x)}[\log p(x)] = \log p(x) \int_z q(z|x) dz = \log p(x) \nonumber \\\text{right} &= \mathbb E_{z\sim q(z|x)}[\log\frac{p(x,z)}{q(z|x)} - \log\frac{p(z|x)}{q(z|x)}] = \int_z q(z|x) \log\frac{p(x,z)}{q(z|x)} dz + \int_z q(z|x) \log\frac{q(z|x)}{p(z|x)} dz \nonumber \\ &= \int_z q(z|x) \log\frac{p(x,z)}{q(z|x)} dz + \text{KL}(q(z|x)||p(z|x)) \nonumber \end{align} leftright=Ez∼q(z∣x)[logp(x)]=logp(x)∫zq(z∣x)dz=logp(x)=Ez∼q(z∣x)[logq(z∣x)p(x,z)−logq(z∣x)p(z∣x)]=∫zq(z∣x)logq(z∣x)p(x,z)dz+∫zq(z∣x)logp(z∣x)q(z∣x)dz=∫zq(z∣x)logq(z∣x)p(x,z)dz+KL(q(z∣x)∣∣p(z∣x))
其中 ∫zq(z∣x)logp(x,z)q(z∣x)dz\int_z q(z|x) \log\frac{p(x,z)}{q(z|x)} dz∫zq(z∣x)logq(z∣x)p(x,z)dz 被称作是信心下界 (Evidence Lower Bound),简单记作 ELBO,名字来源是由于KL散度满足恒大于等于0的性质,因此有 logp(x)≥ELBO\log p(x)\geq \text{ELBO}logp(x)≥ELBO,当 q(z∣x)=p(z∣x)q(z|x) = p(z|x)q(z∣x)=p(z∣x) 时取等,因此我们有如下公式
logp(x)=ELBO+KL(q(z∣x)∣∣p(z∣x))≥ELBO\begin{align} \log p(x) = \text{ELBO}+\text{KL}(q(z|x)||p(z|x)) \geq \text{ELBO} \end{align} logp(x)=ELBO+KL(q(z∣x)∣∣p(z∣x))≥ELBO
如果我们希望 q(z∣x)q(z|x)q(z∣x) 逼近真实条件概率分布 p(z∣x)p(z|x)p(z∣x),在观测数据 xxx 给定的情况下,最小化KL散度等价于最大化ELBO
假定 q(z∣x)q(z|x)q(z∣x) 表示的概率分布由参数 ϕ\phiϕ 决定(例如使用神经网络表示 qϕq_\phiqϕ,我们一般不改变网络结构,而只针对参数进行优化),那么该拟合问题的优化目标如下所示
ϕ^=argmaxϕELBO\hat{\phi} = \arg\max_\phi \text{ELBO} ϕ^=argϕmaxELBO
如果我们采用随机梯度下降法来进行优化 (Stochastic Gradient Varational Inference),首先要计算 ϕ\phiϕ 的导数
▽ϕELBO=▽ϕ∫zqϕ(z∣x)logp(x,z)qϕ(z∣x)dz=∫z▽ϕqϕ(z∣x)logp(x,z)qϕ(z∣x)dz+∫zqϕ(z∣x)▽ϕlogp(x,z)qϕ(z∣x)dz\begin{align} \triangledown_\phi \text{ELBO} &= \triangledown_\phi \int_z q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \\ &= \int_z \triangledown_\phi q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz + \int_z q_\phi(z|x) \triangledown_\phi \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \end{align} ▽ϕELBO=▽ϕ∫zqϕ(z∣x)logqϕ(z∣x)p(x,z)dz=∫z▽ϕqϕ(z∣x)logqϕ(z∣x)p(x,z)dz+∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)p(x,z)dz
注意到,对于第二项,有
∫zqϕ(z∣x)▽ϕlogp(x,z)qϕ(z∣x)dz=−∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)dz=−∫z▽ϕqϕ(z∣x)dz=−▽ϕ∫zqϕ(z∣x)dz=0\int_z q_\phi(z|x) \triangledown_\phi \log\frac{p(x,z)}{q_\phi(z|x)} dz = - \int_z q_\phi(z|x) \triangledown_\phi \log q_\phi(z|x) dz = - \int_z \triangledown_\phi q_\phi(z|x) dz = - \triangledown_\phi \int_z q_\phi(z|x) dz = 0 ∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)p(x,z)dz=−∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)dz=−∫z▽ϕqϕ(z∣x)dz=−▽ϕ∫zqϕ(z∣x)dz=0
因此,有如下等式
▽ϕELBO=∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)logp(x,z)qϕ(z∣x)dz=Ez∼qϕ(z∣x)[▽ϕlogqϕ(z∣x)logp(x,z)qϕ(z∣x)]\begin{align} \triangledown_\phi \text{ELBO} &= \int_z q_\phi(z|x) \triangledown_\phi \log q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \\ &= \mathbb E_{z\sim q_\phi(z|x)}[\triangledown_\phi \log q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)}] \end{align} \nonumber ▽ϕELBO=∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)logqϕ(z∣x)p(x,z)dz=Ez∼qϕ(z∣x)[▽ϕlogqϕ(z∣x)logqϕ(z∣x)p(x,z)]
使用 Monto-Carlo 采样方法计算期望,即 zi∼qϕ(z∣x)(i=1...L)z_i \sim q_\phi(z|x) \;\;(i=1...L)zi∼qϕ(z∣x)(i=1...L)
▽ϕELBO≈1L∑i=1L▽ϕlogqϕ(zi∣x)logp(x,zi)qϕ(zi∣x)\triangledown_\phi \text{ELBO} \approx \frac{1}{L} \sum_{i=1}^L \triangledown_\phi \log q_\phi(z_i|x) \log\frac{p(x,z_i)}{q_\phi(z_i|x)} ▽ϕELBO≈L1i=1∑L▽ϕlogqϕ(zi∣x)logqϕ(zi∣x)p(x,zi)
注意到,式子中包含 ▽ϕlogqϕ(zi∣x)\triangledown_\phi \log q_\phi(z_i|x)▽ϕlogqϕ(zi∣x),以下为 y=log(x)y=\log(x)y=log(x) 的函数图像

在 xxx 较小时值的变化范围很大,因此直观上来看 ▽ϕlogqϕ(zi∣x)logp(x,zi)qϕ(zi∣x)\triangledown_\phi \log q_\phi(z_i|x) \log\frac{p(x,z_i)}{q_\phi(z_i|x)}▽ϕlogqϕ(zi∣x)logqϕ(zi∣x)p(x,zi) 方差较大,对于每个 xxx 都需要大量采样 zzz 才能得到一个较为准确的期望值,实际应用时存在较大困难,因此引入如下重参数化技巧 (Re-parameterization)
重参数化技巧:我们希望解耦随机变量 zzz 中的随机性与 ϕ\phiϕ 之间的关系,使得计算期望时随机变量服从的概率分布 z∼qϕ(z∣x)z\sim q_\phi(z|x)z∼qϕ(z∣x) 转变为某个已知的概率分布,我们假定存在某随机变量 ϵ∼pϵ(ϵ)\epsilon \sim p_\epsilon(\epsilon)ϵ∼pϵ(ϵ),满足 z=gϕ(ϵ,x)z = g_\phi(\epsilon, x)z=gϕ(ϵ,x),我们有 ∣qϕ(z∣x)dz∣=∣pϵ(ϵ)dϵ∣\left | q_{\phi }(z|x)dz \right |=\left | p_\epsilon(\epsilon )d\epsilon \right |∣qϕ(z∣x)dz∣=∣pϵ(ϵ)dϵ∣,因此,有下式
▽ϕELBO=▽ϕ∫zqϕ(z∣x)logp(x,z)qϕ(z∣x)dz=▽ϕ∫zlogp(x,z)qϕ(z∣x)pϵ(ϵ)dϵ=∫z▽ϕlogp(x,z)qϕ(z∣x)pϵ(ϵ)dϵ=Eϵ∼pϵ[▽ϕlogp(x,z)qϕ(z∣x)]=Eϵ∼pϵ[▽zlogp(x,z)qϕ(z∣x)▽ϕgϕ(ϵ,x)]\begin{align} \triangledown_\phi \text{ELBO} &= \triangledown_\phi \int_z q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \\ &= \triangledown_\phi \int_z \log\frac{p(x,z)}{q_\phi(z|x)} p_\epsilon(\epsilon) d\epsilon \nonumber \\ &= \int_z \triangledown_\phi \log\frac{p(x,z)}{q_\phi(z|x)} p_\epsilon(\epsilon) d\epsilon \nonumber \\ &= \mathbb E_{\epsilon\sim p_\epsilon}[ \triangledown_\phi\log\frac{p(x,z)}{q_\phi(z|x)}] \nonumber \\ &= \mathbb E_{\epsilon\sim p_\epsilon}[ \triangledown_z\log\frac{p(x,z)}{q_\phi(z|x)} \triangledown_\phi g_\phi(\epsilon,x)] \nonumber \end{align} ▽ϕELBO=▽ϕ∫zqϕ(z∣x)logqϕ(z∣x)p(x,z)dz=▽ϕ∫zlogqϕ(z∣x)p(x,z)pϵ(ϵ)dϵ=∫z▽ϕlogqϕ(z∣x)p(x,z)pϵ(ϵ)dϵ=Eϵ∼pϵ[▽ϕlogqϕ(z∣x)p(x,z)]=Eϵ∼pϵ[▽zlogqϕ(z∣x)p(x,z)▽ϕgϕ(ϵ,x)]
变分自动编码器 (Variational AutoEncoder)
变分自编码器是变分推断与自编码器的一种组合,首先来简单介绍一下自编码器,经验可知,对于图像 x∈RH×W×3x\in \R^{H\times W\times 3}x∈RH×W×3 等真实数据的高维数据,它们通常在空间中是稀疏分布的,大致分布在高维空间的某个流形上面,因此,我们希望将其投影到某个稠密分布的空间上,使其满足某些性质(例如,在该稠密空间上采样的任一一个点,投影回原始图像空间都能得到一个接近真实的图像),我们使用神经网络来执行不同表示空间的转换操作,如下所示

AE主要有encoder和decoder两个部分组成,其中encoder和decoder都是神经网络。其中encoder负责将高维输入转换为低维的隐变量,decoder负责将低维的隐变量转换为高维的图像输出,其中输出要跟输入尽可能的相似
通常情况下,网络的拟合能力要强于训练数据的多样性,假如 Autoencoders 中的 encoder 和 decoder 都具有无限的拟合能力,那么理论上我们就可以无损地把任何高维数据都压缩至维度为 1,无损的数据压缩往往会使得隐空间缺乏可解释性。在大多数情况下,空间转化不仅仅是为了降低数据维度,而是在降低数据维度的同时还能在隐空间中保留数据的主要结构信息。我们目前的损失函数只对每个样本点处进行约束,而并没有整个隐空间上给出约束信息,这使得该网络不能在样本点与样本点之间得到较好的插值结果

上图所示三种颜色表示三个样本点在隐空间上的位置,如果不引入额外的约束,只在样本点的某个小邻域内可以得到合理的图像结果,但大部分位置 Decoder 不能给出一个合理的图像生成结果。我们希望,对隐空间的样本点施加一个噪声的情况下,依旧约束 Decoder 重建出一张与原始图像相似的图片,整体流程如下所示

注意到对于上述流程中,采样这一步是无法进行反向传播的,采用重参数化技巧解耦 zzz 的随机性和与参数 ϕ\phiϕ 之间的关系。通常假定 z∣x∼N(μ(x),σ2(x)I)z|x \sim \mathcal N (\mu(x), \sigma^2(x)I)z∣x∼N(μ(x),σ2(x)I),那么有
z=μ(x)+σ(x)ϵz = \mu(x) + \sigma(x) \epsilon z=μ(x)+σ(x)ϵ
其中 ϵ∼N(0,I)\epsilon \sim \mathcal{N}(0,I)ϵ∼N(0,I),网络结构如下所示
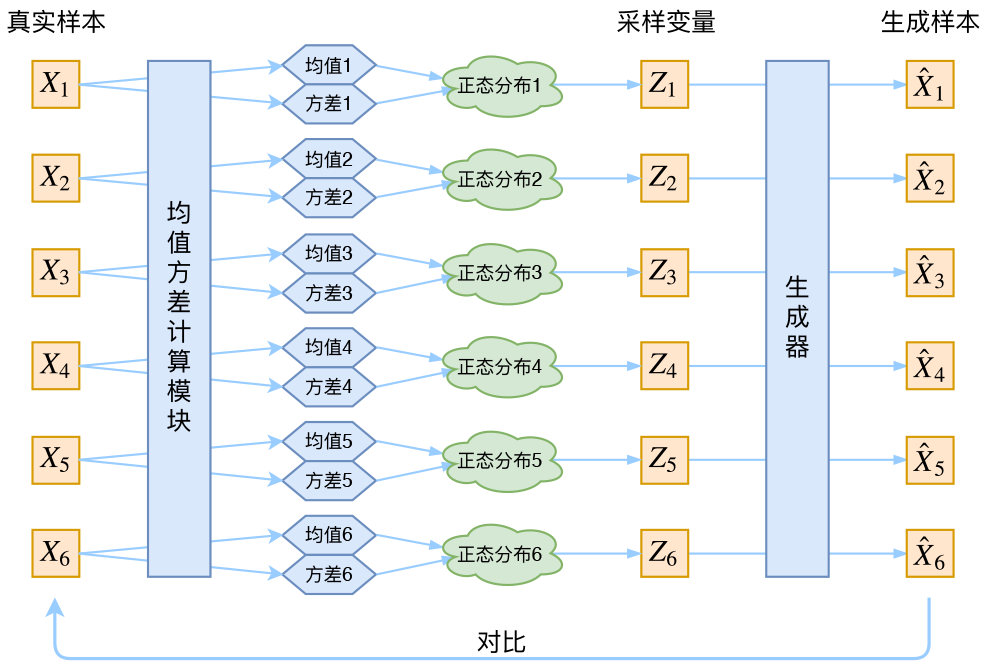
对于以上网络结构,显然噪声会增加重构的难度,其中噪声强度(方差)通过一个神经网络算出来的,如果不施加额外的约束,网络会倾向于让方差为0,模型会慢慢退化成普通的AutoEncoder,噪声不再起作用。
因此,为了避免模型退化,同时保证有意义的 p(z)p(z)p(z) 分布(方便图像的生成任务),VAE让所有的 p(z∣x)p(z|x)p(z∣x) 向标准正态分布看齐,如果所有的 p(z∣x)p(z|x)p(z∣x) 都很接近标准正态分布 N(0,1)\mathcal{N}(0,1)N(0,1),那么有
p(z)=∫xp(z∣x)p(x)dx=∫xN(0,1)p(x)dx=N(0,1)p(z) = \int_x p(z|x) p(x) dx = \int_x \mathcal{N}(0,1) p(x) dx = \mathcal{N}(0,1) p(z)=∫xp(z∣x)p(x)dx=∫xN(0,1)p(x)dx=N(0,1)
然后我们就可以从 N(0,1)\mathcal{N}(0,1)N(0,1) 中采样来生成图像
约束项由 KL 散度给出,有如下结论:对于一维高斯分布 p∼N(μ1,σ12)p~\sim \mathcal{N}(\mu_1,\sigma_1^2)p ∼N(μ1,σ12) 和 q∼N(μ2,σ22)q~\sim \mathcal{N}(\mu_2,\sigma_2^2)q ∼N(μ2,σ22),满足
KL(p∣∣q)=logσ2σ1+σ12+(μ1−μ2)22σ22−12\text{KL}(p||q) = \log\frac{\sigma_2}{\sigma_1} + \frac{\sigma_1^2+(\mu_1-\mu_2)^2}{2\sigma_2^2} - \frac{1}{2} KL(p∣∣q)=logσ1σ2+2σ22σ12+(μ1−μ2)2−21
具体细节可见 高斯分布的KL散度,进一步,假定隐变量各维度是相互独立的,可以给出如下损失函数约束项(对于第 i 个分量)
KL(N(μ(i)(x),σ(i)(x)),N(0,1))=12(μ(i)(x)2+σ(i)(x)2−2logσ(i)(x)−1)\text{KL}(\mathcal{N}(\mu^{(i)}(x),\sigma^{(i)}(x)), \mathcal{N}(0,1)) = \frac{1}{2}(\mu^{(i)}(x)^2+\sigma^{(i)}(x)^2−2\log\sigma^{(i)}(x)−1) KL(N(μ(i)(x),σ(i)(x)),N(0,1))=21(μ(i)(x)2+σ(i)(x)2−2logσ(i)(x)−1)
从数学角度来说,该优化问题可表示为
θ^,ϕ^=argminθ,ϕKL(qϕ(z∣x)∣∣pθ(z∣x))=argmaxθ,ϕELBO=argmaxθ,ϕEz∼qϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣pθ(z∣x))\begin{align} \hat{\theta}, \hat{\phi} &= \arg \min_{\theta,\phi} \text{KL}(q_\phi(z|x)||p_\theta(z|x)) \\&= \arg \max_{\theta,\phi} \text{ELBO} \\&= \arg \max_{\theta,\phi} \mathbb{E}_{z\sim q_\phi(z|x)} [\log p_\theta(x|z)] - \text{KL}(q_\phi(z|x)||p_\theta(z|x)) \end{align} θ^,ϕ^=argθ,ϕminKL(qϕ(z∣x)∣∣pθ(z∣x))=argθ,ϕmaxELBO=argθ,ϕmaxEz∼qϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣pθ(z∣x))
参考资料
白板推导机器学习