大家好,今天和各位分享一下深度确定性策略梯度算法 (Deterministic Policy Gradient,DDPG)。并基于 OpenAI 的 gym 环境完成一个小游戏。完整代码在我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 基本原理
深度确定性策略梯度算法是结合确定性策略梯度算法的思想,对 DQN 的一种改进,是一种无模型的深度强化学习算法。
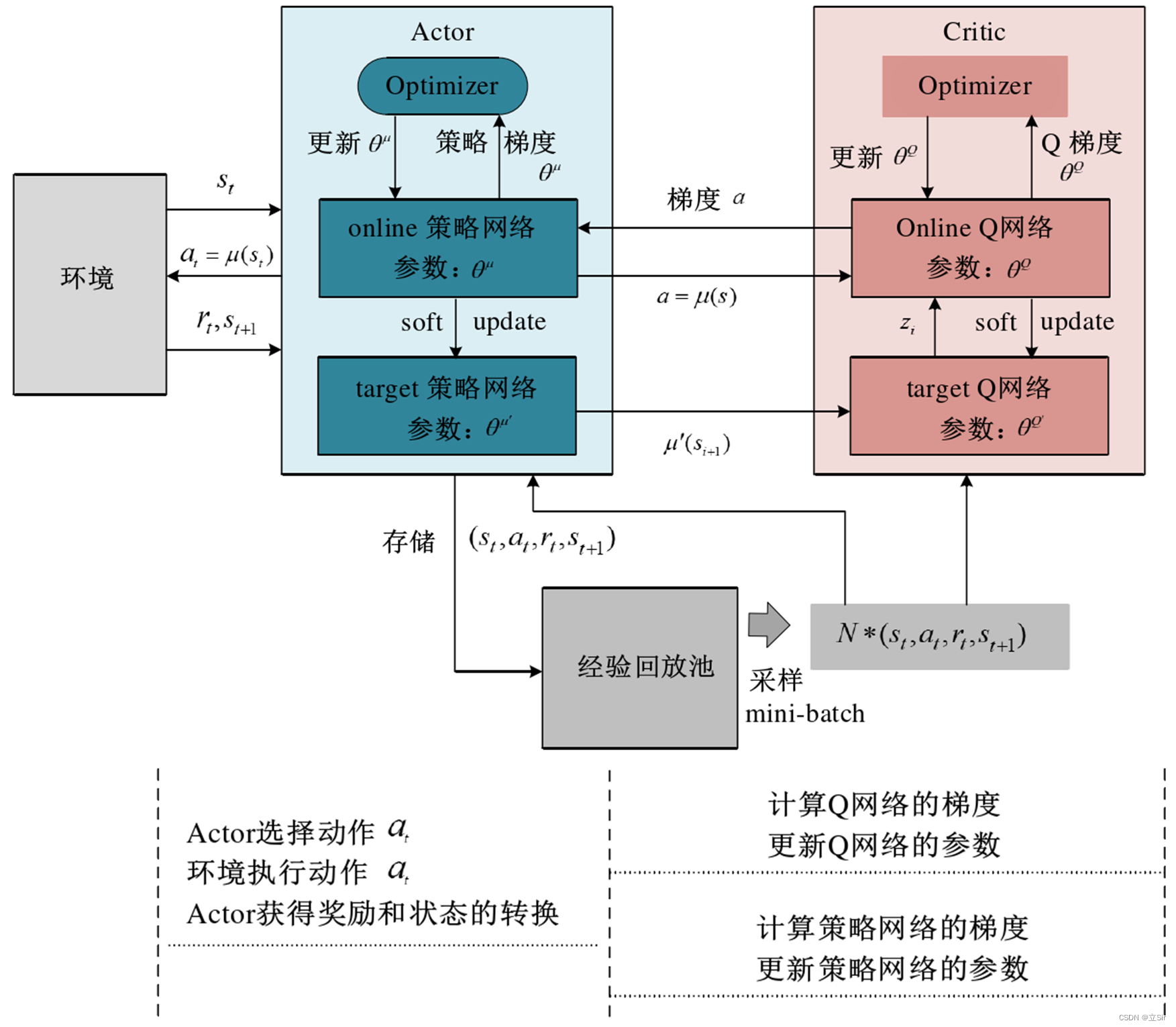
DDPG 算法使用演员-评论家(Actor-Critic)算法作为其基本框架,采用深度神经网络作为策略网络和动作值函数的近似,使用随机梯度法训练策略网络和价值网络模型中的参数。DDPG 算法的原理如下图所示。
DDPG 算法架构中使用双重神经网络架构,对于策略函数和价值函数均使用双重神经网络模型架构(即 Online 网络和 Target 网络),使得算法的学习过程更加稳定,收敛的速度加快。同时该算法引入经验回放机制,Actor 与环境交互生产生的经验数据样本存储到经验池中,抽取批量数据样本进行训练,即类似于 DQN 的经验回放机制,去除样本的相关性和依赖性,使得算法更加容易收敛。
2. 公式推导
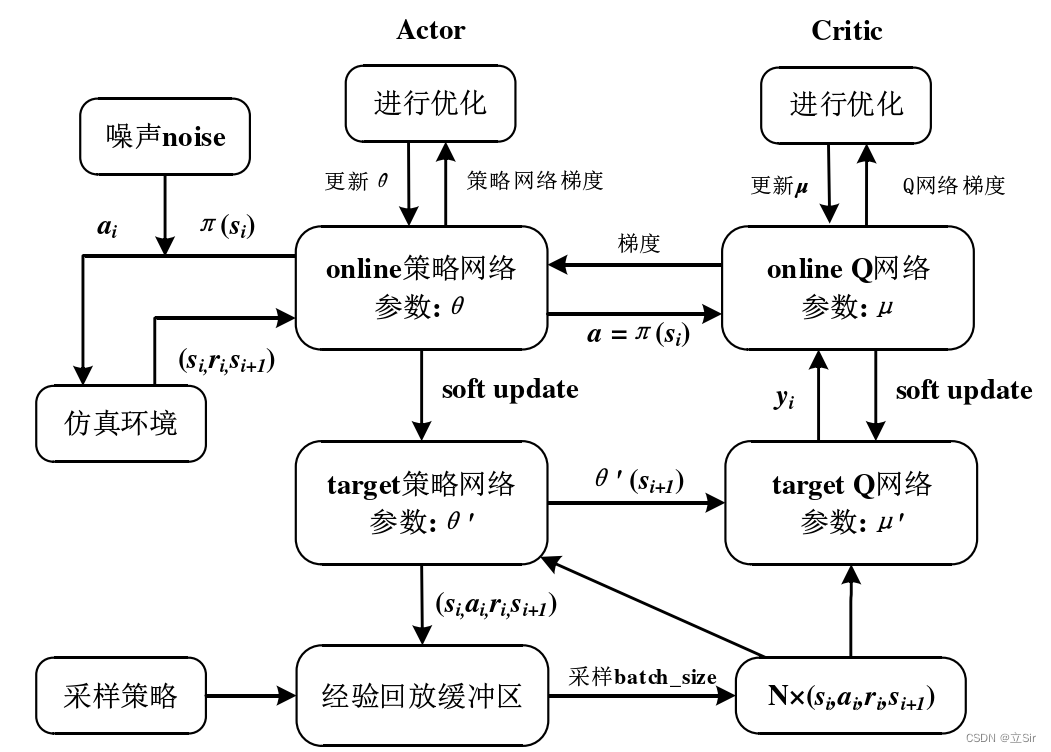
为了便于大家理解 DDPG 的推导过程,算法框架如下图所示:

DDPG 共包含 4 个神经网络,用于对 Q 值函数和策略的近似表示。Critic 目标网络用于近似估计下一时刻的状态-动作的 Q 值函数 ,其中,下一动作值是通过 Actor 目标网络近似估计得到的
。于是可以得到当前状态下 Q 值函数的目标值:
Critic 训练网络输出当前时刻状态-动作的 Q 值函数 ,用于对当前策略评价。为了增加智能体在环境中的探索,DDPG 在行为策略上添加了高斯噪声函数。Critic 网络的目标定义为:
通过最小化损失值(均方误差损失)来更新 Critic 网络的参数,Critic 网络更新时的损失函数为:
其中,,
代表行为策略上的探索噪声。
Actor 目标网络用于提供下一个状态的策略,Actor 训练网络则是提供当前状态的策略,结合 Critic 训练网络的 Q 值函数可以得到 Actor 在参数更新时的策略梯度:
对于目标网络参数 和
的更新,DDPG 通过软更新机制(每次 learn 的时候更新部分参数)保证参数可以缓慢更新,从而提高学习的稳定性:
DDPG 中既有基于价值函数的方法特征,也有基于策略的方法特征,使深度强化学习可以处理连续动作,并且具有一定的探索能力。
算法流程图如下:
3. 代码实现
DDPG 的伪代码如下:

模型代码如下:
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
import collections
import random# ------------------------------------- #
# 经验回放池
# ------------------------------------- #class ReplayBuffer:def __init__(self, capacity): # 经验池的最大容量# 创建一个队列,先进先出self.buffer = collections.deque(maxlen=capacity)# 在队列中添加数据def add(self, state, action, reward, next_state, done):# 以list类型保存self.buffer.append((state, action, reward, next_state, done))# 在队列中随机取样batch_size组数据def sample(self, batch_size):transitions = random.sample(self.buffer, batch_size)# 将数据集拆分开来state, action, reward, next_state, done = zip(*transitions)return np.array(state), action, reward, np.array(next_state), done# 测量当前时刻的队列长度def size(self):return len(self.buffer)# ------------------------------------- #
# 策略网络
# ------------------------------------- #class PolicyNet(nn.Module):def __init__(self, n_states, n_hiddens, n_actions, action_bound):super(PolicyNet, self).__init__()# 环境可以接受的动作最大值self.action_bound = action_bound# 只包含一个隐含层self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_actions)# 前向传播def forward(self, x):x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = F.relu(x)x = self.fc2(x) # [b,n_hiddens]-->[b,n_actions]x= torch.tanh(x) # 将数值调整到 [-1,1]x = x * self.action_bound # 缩放到 [-action_bound, action_bound]return x# ------------------------------------- #
# 价值网络
# ------------------------------------- #class QValueNet(nn.Module):def __init__(self, n_states, n_hiddens, n_actions):super(QValueNet, self).__init__()# self.fc1 = nn.Linear(n_states + n_actions, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_hiddens)self.fc3 = nn.Linear(n_hiddens, 1)# 前向传播def forward(self, x, a):# 拼接状态和动作cat = torch.cat([x, a], dim=1) # [b, n_states + n_actions]x = self.fc1(cat) # -->[b, n_hiddens]x = F.relu(x)x = self.fc2(x) # -->[b, n_hiddens]x = F.relu(x)x = self.fc3(x) # -->[b, 1]return x# ------------------------------------- #
# 算法主体
# ------------------------------------- #class DDPG:def __init__(self, n_states, n_hiddens, n_actions, action_bound,sigma, actor_lr, critic_lr, tau, gamma, device):# 策略网络--训练self.actor = PolicyNet(n_states, n_hiddens, n_actions, action_bound).to(device)# 价值网络--训练self.critic = QValueNet(n_states, n_hiddens, n_actions).to(device)# 策略网络--目标self.target_actor = PolicyNet(n_states, n_hiddens, n_actions, action_bound).to(device)# 价值网络--目标self.target_critic = QValueNet(n_states, n_hiddens, n_actions).to(device)# 初始化价值网络的参数,两个价值网络的参数相同self.target_critic.load_state_dict(self.critic.state_dict())# 初始化策略网络的参数,两个策略网络的参数相同self.target_actor.load_state_dict(self.actor.state_dict())# 策略网络的优化器self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)# 价值网络的优化器self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)# 属性分配self.gamma = gamma # 折扣因子self.sigma = sigma # 高斯噪声的标准差,均值设为0self.tau = tau # 目标网络的软更新参数self.n_actions = n_actionsself.device = device# 动作选择def take_action(self, state):# 维度变换 list[n_states]-->tensor[1,n_states]-->gpustate = torch.tensor(state, dtype=torch.float).view(1,-1).to(self.device)# 策略网络计算出当前状态下的动作价值 [1,n_states]-->[1,1]-->intaction = self.actor(state).item()# 给动作添加噪声,增加搜索action = action + self.sigma * np.random.randn(self.n_actions)return action# 软更新, 意思是每次learn的时候更新部分参数def soft_update(self, net, target_net):# 获取训练网络和目标网络需要更新的参数for param_target, param in zip(target_net.parameters(), net.parameters()):# 训练网络的参数更新要综合考虑目标网络和训练网络param_target.data.copy_(param_target.data*(1-self.tau) + param.data*self.tau)# 训练def update(self, transition_dict):# 从训练集中取出数据states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device) # [b,n_states]actions = torch.tensor(transition_dict['actions'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device) # [b,next_states]dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]# 价值目标网络获取下一时刻的动作[b,n_states]-->[b,n_actors]next_q_values = self.target_actor(next_states)# 策略目标网络获取下一时刻状态选出的动作价值 [b,n_states+n_actions]-->[b,1]next_q_values = self.target_critic(next_states, next_q_values)# 当前时刻的动作价值的目标值 [b,1]q_targets = rewards + self.gamma * next_q_values * (1-dones)# 当前时刻动作价值的预测值 [b,n_states+n_actions]-->[b,1]q_values = self.critic(states, actions)# 预测值和目标值之间的均方差损失critic_loss = torch.mean(F.mse_loss(q_values, q_targets))# 价值网络梯度self.critic_optimizer.zero_grad()critic_loss.backward()self.critic_optimizer.step()# 当前状态的每个动作的价值 [b, n_actions]actor_q_values = self.actor(states)# 当前状态选出的动作价值 [b,1]score = self.critic(states, actor_q_values)# 计算损失actor_loss = -torch.mean(score)# 策略网络梯度self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()# 软更新策略网络的参数 self.soft_update(self.actor, self.target_actor)# 软更新价值网络的参数self.soft_update(self.critic, self.target_critic)4. 案例演示
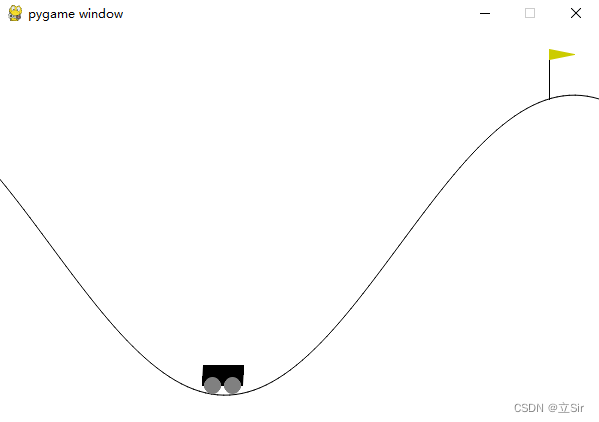
基于 OpenAI 的 gym 环境完成一个推车游戏,目标是将小车推到山顶旗子处。动作维度为1,属于连续值;状态维度为 2,分别是 x 坐标和小车速度。

代码如下:
import numpy as np
import torch
import matplotlib.pyplot as plt
import gym
from parsers import args
from RL_brain import ReplayBuffer, DDPG
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')# -------------------------------------- #
# 环境加载
# -------------------------------------- #env_name = "MountainCarContinuous-v0" # 连续型动作
env = gym.make(env_name, render_mode="human")
n_states = env.observation_space.shape[0] # 状态数 2
n_actions = env.action_space.shape[0] # 动作数 1
action_bound = env.action_space.high[0] # 动作的最大值 1.0# -------------------------------------- #
# 模型构建
# -------------------------------------- ## 经验回放池实例化
replay_buffer = ReplayBuffer(capacity=args.buffer_size)
# 模型实例化
agent = DDPG(n_states = n_states, # 状态数n_hiddens = args.n_hiddens, # 隐含层数n_actions = n_actions, # 动作数action_bound = action_bound, # 动作最大值sigma = args.sigma, # 高斯噪声actor_lr = args.actor_lr, # 策略网络学习率critic_lr = args.critic_lr, # 价值网络学习率tau = args.tau, # 软更新系数gamma = args.gamma, # 折扣因子device = device)# -------------------------------------- #
# 模型训练
# -------------------------------------- #return_list = [] # 记录每个回合的return
mean_return_list = [] # 记录每个回合的return均值for i in range(10): # 迭代10回合episode_return = 0 # 累计每条链上的rewardstate = env.reset()[0] # 初始时的状态done = False # 回合结束标记while not done:# 获取当前状态对应的动作action = agent.take_action(state)# 环境更新next_state, reward, done, _, _ = env.step(action)# 更新经验回放池replay_buffer.add(state, action, reward, next_state, done)# 状态更新state = next_state# 累计每一步的rewardepisode_return += reward# 如果经验池超过容量,开始训练if replay_buffer.size() > args.min_size:# 经验池随机采样batch_size组s, a, r, ns, d = replay_buffer.sample(args.batch_size)# 构造数据集transition_dict = {'states': s,'actions': a,'rewards': r,'next_states': ns,'dones': d,}# 模型训练agent.update(transition_dict)# 保存每一个回合的回报return_list.append(episode_return)mean_return_list.append(np.mean(return_list[-10:])) # 平滑# 打印回合信息print(f'iter:{i}, return:{episode_return}, mean_return:{np.mean(return_list[-10:])}')# 关闭动画窗格
env.close()# -------------------------------------- #
# 绘图
# -------------------------------------- #x_range = list(range(len(return_list)))plt.subplot(121)
plt.plot(x_range, return_list) # 每个回合return
plt.xlabel('episode')
plt.ylabel('return')
plt.subplot(122)
plt.plot(x_range, mean_return_list) # 每回合return均值
plt.xlabel('episode')
plt.ylabel('mean_return')