一、Flink中Time的三种类型:
Stream数据中的Time(时间)分为以下3种:
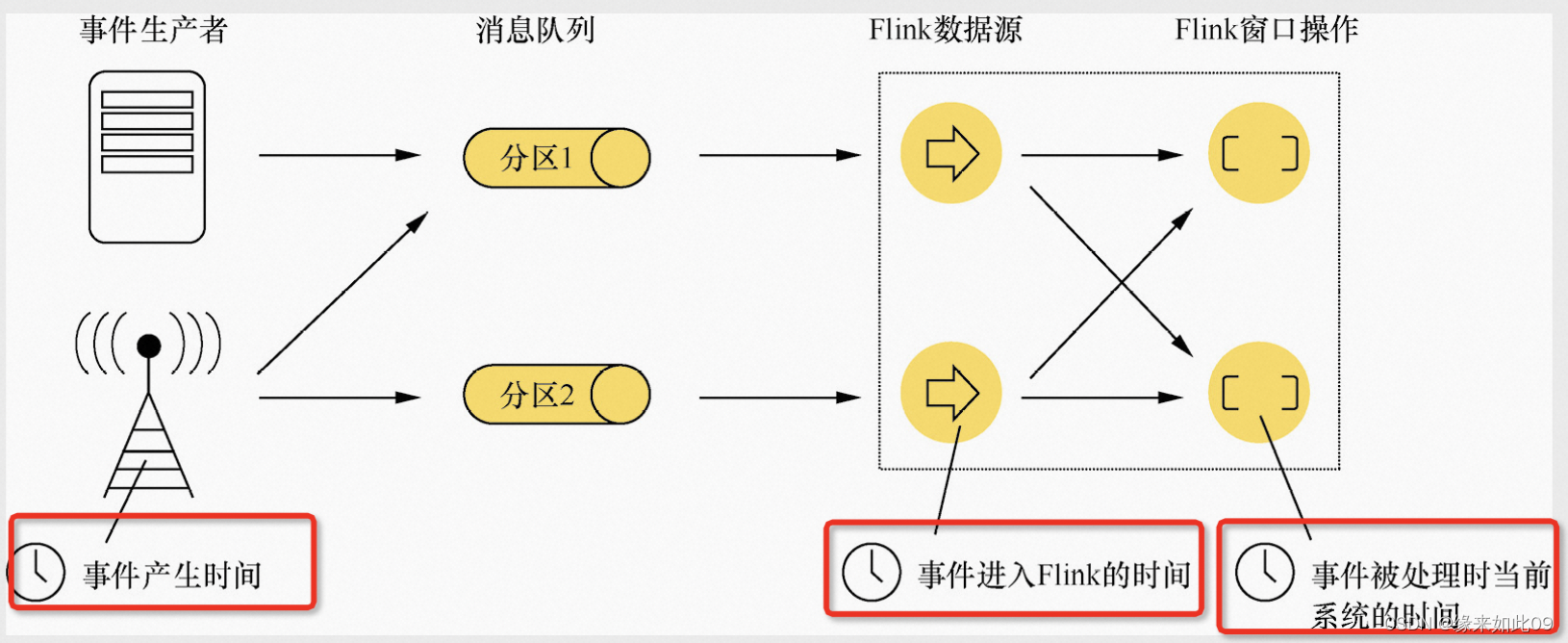
1.Event Time(事件产生的时间):
事件的时间戳,通常是生成事件的时间。Event time 是事件本身的时间,可以表现出事件发生的顺序,可以应对一些不规则数据、乱序数据等情况。在使用 Event time时,需要通过引入 Watermark 的概念来处理乱序数据,保证正确性。
2.Ingestion time(事件进入Flink的时间)
数据进入 Flink 的时间戳,即数据到达 Flink 的时间。Ingestion time 可以实现低延迟的数据处理,同时又能够确保数据的时间顺序。Ingestion time 可以通过在数据源端添加时间戳的方式实现,但是由于存在网络传输等因素,与 Event time 的时间戳可能存在一定的时间差。
3.Processing time(事件被处理时当前系统的时间)
数据处理的时间戳,即 Flink 处理数据的当前时间。Processing time 可以实现低延迟的数据处理,但是无法保证数据的时间顺序,因此在一些需要按时间窗口进行分组、聚合等操作时,需要使用 Event time 或 Ingestion time。
二、Flink如何处理乱序数据
在使用EventTime处理Stream数据的时候会遇到数据乱序的问题,流处理从Event(事件)产生,流经Source,再到Operator,这中间需要一定的时间。虽然大部分情况下,传输到Operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络延迟等原因而导致乱序的产生,特别是使用Kafka的时候,多个分区之间的数据无法保证有序。因此,在进行Window计算的时候,不能无限期地等下去,必须要有个机制来保证在特定的时间后,必须触发Window进行计算,这个特别的机制就是Watermark。Watermark是用于处理乱序事件的。
1.Watermark是什么?
Watermark 是一种插入到数据流中的特殊元素,用于表示数据流中的事件时间进展情况。Watermark代表一段时间范围内的最大 Event time,可以作为 Event time 的一个约束,强制 Flink 在这个时间之前的数据已经全部到达。Flink 在执行窗口操作时,可以根据 Watermark 来判断数据是否已经到达,进而触发窗口计算
watermark还可以处理延迟到达的数据,可以通过设置延迟时间来控制Watermark的生成,从而正确地处理延迟数据。
例如,如果设置延迟时间为5秒,那么在Event time为T时,Watermark的值为T -5,这样可以保证在Watermark到达之前的5秒内到达的数据也可以被处理。
2.Flink Watermark的使用场景:
(1)处理实时数据流时,需要对数据进行窗口统计。在统计过程中,需要对每个窗口内的事件按照时间戳进行排序,并根据Watermark的信息来确定窗口的边界。
(2)处理流式数据时,需要进行基于时间的聚合操作,例如计算每分钟或每小时的平均值、最大值等。在进行聚合操作时,需要使用Watermark来确定数据的时间范围,以便准确计算结果。
(3)在进行基于时间的数据分析时,需要根据时间戳来识别和分析数据。例如,对某个时间段内的用户行为进行分析,需要使用Watermark来纠正数据的延迟,以便准确分析数据。
(4)通过Flink进行数据清洗和过滤,需要根据事件时间来进行过滤和清洗。在进行过滤和清洗操作时,需要使用Watermark来确定数据的时间范围,以便准确过滤和清洗数据。
总之,Watermark是处理事件时间的关键工具,在流处理中有着广泛的应用场景,能够帮助我们处理数据延迟和乱序等问题,从而提高流处理的准确性和可靠性。
3.Flink Watermark如何与窗口进行联动:
对于窗口而言它是有生命周期的,只要属于此窗口的第一个元素到达,就会创建一个窗口,当时间(事件或处理时间)超过其结束时间戳加上用户指定的允许延迟时,窗口将被完全删除。
例如:使用基于事件时间的窗口策略,每5分钟创建一个不重叠(或翻滚)的窗口并允许延迟1分钟。
假定目前是12:00。
当具有落入该间隔的时间戳的第一个元素到达时,Flink将为12:00到12:05之间的间隔创建一个新窗口,当水位线(watermark)到12:06时间戳时将删除它
而窗口使用的时间就是Watermark,水位线表明着早于它的事件不应该再出现,但是接收到水位线以前的的消息是不可避免的,这就是所谓的迟到事件。实际上迟到事件是乱序事件的特例,和一般乱序事件不同的是它们的乱序程度超出了水位线的预计,导致窗口在它们到达之前已经关闭。所以一般会给Watermark加上延迟时间,这样即便有延迟时间,也不会导致窗口计算错误
三、其他解决窗口中数据乱序方法
除了Watermark,flink中还有两种解决数据乱序的方法
1.allowedLateness
allowedLateness是指允许数据延迟到达一定时间窗口后继续进行处理,这个时间窗口称为“允许延迟时间”(allowed lateness)。当窗口关闭后,还可以继续接收一段时间内到达的数据,直到允许延迟时间过期后才真正关闭窗口。
在使用allowedLateness时,需要在窗口分配器(Window Assigner)中设置allowedLateness参数
2.sideOutputLateData
sideOutputLateData是指将延迟数据输出到侧输出流中,可以使用侧输出流对延迟数据进行处理,不影响正常的数据流处理。
在使用sideOutputLateData时,需要在窗口函数(Window Function)中调用context.sideOutput()方法将延迟数据输出到侧输出流中,