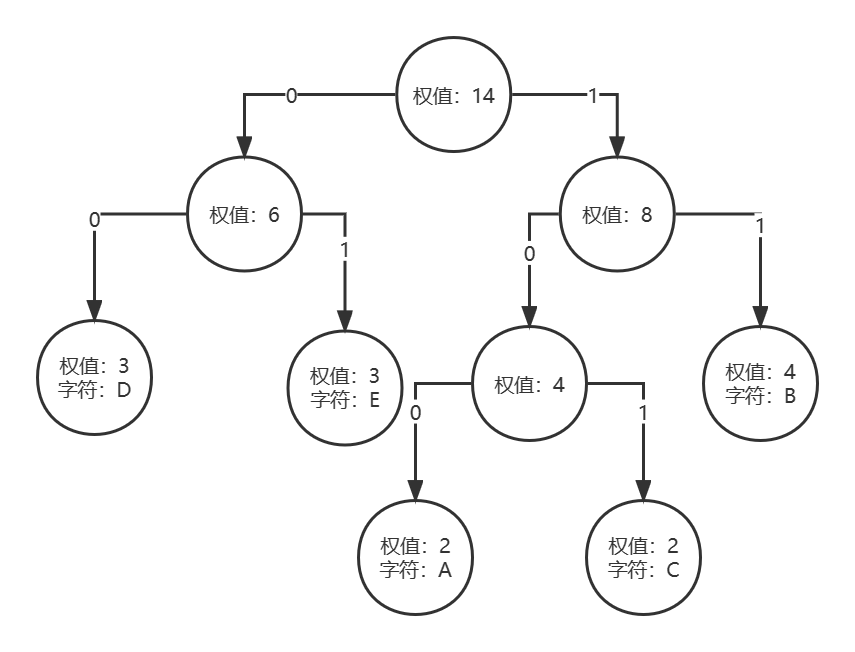
最近,在做行人检测任务时,对数据进行清洗后,存在一些空标签的样本,所以,想考虑这些空标签的样本对模型的性能究竟有什么样的影响。
一、概念定义
负样本:在目标检测任务中,数据集中部分图片没有出现目标,这些图片通常被称为负样本。
正样本:指包含目标的图像。
背景:背景是指整个图像中不包含目标的区域,它与负样本不同。负样本是针对整个图片而言,背景是针对边界框而言。
二、思考
1. 目标检测任务中,数据集中部分图片没有出现目标 (负样本较多),剔除和不剔除会怎么影响模型性能呢?
在目标检测任务中,剔除没有出现目标的图片可能会对模型的性能产生影响。具体来说,如果数据集中有大量没有目标的图片,而这些图片不被剔除,可能会导致模型学习到错误的特征,并且无法正确识别出目标物体。eg,ImageNet中存在大量负样本,并且有一些目标的标注错误,但是大模型都会有纠错的能力,可以通过大量的学习来弥补这个问题,可参考:移除ImageNet标签错误,模型排名发生大变化
另一方面,如果剔除了这些没有目标的图片,可能会导致数据集的规模减小,从而可能会影响模型的泛化能力。模型的泛化能力是指模型在遇到新的、未见过的数据时,能够正确地进行目标检测的能力。如果数据集规模变小,模型就可能无法学习到足够多的特征,从而降低了模型的泛化能力。
因此,需要根据具体情况进行权衡和选择。如果数据集中没有目标的图片比例很大,可以考虑剔除这些图片。如果没有目标的图片比例比较小,可以将这些图片保留在数据集中,并使用其他方法(例如数据增强)来提高模型的泛化能力。
问题是,这个是比例大概是多少需要剔除。一般来说,负样本占总数据集的比例小可以保留,负样本占总数据集的比例大,需要进行剔除,但剔除存在数据规模减少,并不是很好的方案,最优的方案应该是采用正负样本均衡的方法。
详细分析如下:
(1) 确定没有目标的图片比例是否可以接受,需要根据具体的情况来决定。一般来说,没有目标的图片比例比较小通常指在整个数据集中,没有目标的图片所占比例小于 10%。这个比例并不是一个硬性的规定,而是需要根据具体情况来考虑。如果数据集规模较小,或者目标物体比较难以识别,可能会有更高的没有目标的图片比例。
另外,即使没有目标的图片比例较小,也需要注意这些图片对模型的影响。如果没有目标的图片中存在与目标物体相似的背景或者场景,这些图片仍然可以提供一些有用的信息。在这种情况下,保留这些图片可能会有助于提高模型的泛化能力。
总的来说,确定是否保留没有目标的图片需要综合考虑数据集规模、目标物体难度、没有目标图片的相似度等因素。最终的决定应该基于实验和实践的结果。
(2) 如果模型的应用场景与测试集中的场景有重合,且测试集中的图片数量足够大,可以考虑保留这些没有目标的图片。这样做的好处是可以更好地评估模型在现实场景中的表现。但是,如果测试集中没有目标的图片过多,可能会导致模型的性能评估出现偏差,因为模型只学习了识别有目标的图片,而没有学习如何识别没有目标的图片。如果数据集中没有目标的图片过多,可能会导致模型过度拟合目标物体,从而影响模型的性能。在这种情况下,可以考虑剔除一部分没有目标的图片,以减少模型过度拟合的风险。
另一方面,如果模型的应用场景不包括测试集中没有目标的情况,或者测试集中没有目标的图片数量太少,剔除这些图片也是可以的。这样可以减少模型的学习难度,使模型更专注于识别目标物体。但是,需要注意的是,剔除这些图片可能会导致评估结果偏差,因为模型没有学习到如何识别没有目标的图片。
综上所述,是否剔除测试集中没有目标的图片,需要根据具体的场景和需求来决定,需要权衡不同的因素来做出决策。
2. 剔除测试集的负样本,评价指标变差。
理论分析:在目标检测任务中,剔除测试集中没有目标的样本后,测试指标反而变差,可能是因为剔除了这些样本后,测试集的分布与实际场景的分布存在差异,从而导致模型的泛化性能下降。
具体地说,如果测试集中没有目标的样本过多,而实际场景中的图片中又有很多没有目标的情况,那么剔除测试集中没有目标的样本会导致测试集的分布与实际场景的分布不一致,从而使模型在实际场景中的性能下降。
此外,剔除测试集中没有目标的样本还可能导致模型在测试集上的表现出现偏差。因为模型在训练过程中并没有学习到如何处理没有目标的情况,如果测试集中没有目标的样本被剔除,模型就无法被正确地评估在这些情况下的表现。
因此,如果测试集中没有目标的样本过多,我们应该考虑如何解决模型在这些情况下的性能问题,而不是剔除这些样本。例如,可以考虑使用数据增强方法,增加一些没有目标的样本,以使模型能够更好地学习到这些情况下的特征。
指标分析:通过对评价指标进行梳理,发现负样本的剔除会改变图片总数,涉及到一些和图片总数的计算指标会受到影响,比如FPPI指标。
三、正负样本平衡的方法
(1) 重采样(Resampling):通过增加少数类样本或者减少多数类样本的方式来平衡正负样本的数量。具体地,可以采用欠采样(Undersampling)和过采样(Oversampling)等方法。
(2) 类别加权(Class Weighting):将不同类别的样本赋予不同的权重,使得模型在训练时更关注罕见类别的学习。具体地,可以采用样本加权(Sample Weighting)和损失函数加权(Loss Weighting)等方法。
(3) 数据增强(Data Augmentation):通过对训练集中的样本进行各种变换(例如旋转、翻转、缩放、裁剪等)来扩充样本集,从而平衡正负样本的数量和类别分布。具体地,可以采用随机缩放(Random Scaling)、随机裁剪(Random Cropping)和随机旋转(Random Rotation)等方法。
(4) 生成式对抗网络(Generative Adversarial Networks,GANs):通过生成一些虚拟的少数类别样本,使得模型可以更好地学习少数类别的特征。具体地,可以采用条件生成对抗网络(Conditional GANs)等方法。
(5) 算法层面调整:对于一些算法,如Faster R-CNN等,可以调整RPN网络的阈值、nms的阈值等超参数来平衡正负样本。
重点关注方法角度,这里展示的不太全,可以先简单看看(后续更新持续更新):
Oksuz等人在一篇综述文章中详细介绍了目标检测中不平衡问题,并将其分为四类:空间不平衡、目标不平衡、类别不平衡和尺度不平衡。空间不平衡和目标不平衡主要关注边界框的空间属性和多个损失函数,而类别不平衡则是由于训练数据中不同类别之间的显著不平等所导致的。Park, K., Kim, S., Sohn, K.: Uni ed multi-spectral pedestrian detection based on probabilistic fusion networks. Pattern Recognition 80, 143{155 (2018)
RetinaNet通过调整标准交叉熵损失来解决类别不平衡问题,以避免大量简单的负样本压倒检测器。
AP-Loss和DR Loss也提供了设计损失函数来解决类别不平衡问题的思路。Chen, K., Li, J., Lin, W., See, J., Wang, J., Duan, L., Chen, Z., He, C., Zou, J.:Towards accurate one-stage object detection with ap-loss. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5119{5127 (2019)
尺度不平衡发生在网络中某些大小的目标边界框被过度表示的情况下。例如,SSD从不同层的特征中进行独立预测。由于不同层的信息抽象程度不同,因此直接从不同层的骨干网中进行预测是不可靠的。FPN利用额外的自上而下的路径,以便从不同尺度的特征中获得平衡的特征混合。FPN可以通过整合和完善金字塔特征映射来进一步增强。
除了平衡不同层级之外,两流网络中应该平衡整合不同模态的特征。换句话说,应该充分整合和表示不同模态的特征,以实现平衡的模态优化训练。
个人的拙劣理解,大家可以评论区讨论交流。