目录
一、哪三大阶段
二、产生信号
1、通过键盘产生信号
2、系统调用
3、软件条件产生信号
4、硬件异常产生信号
三、Term和core是什么
一、信号一生三大阶段
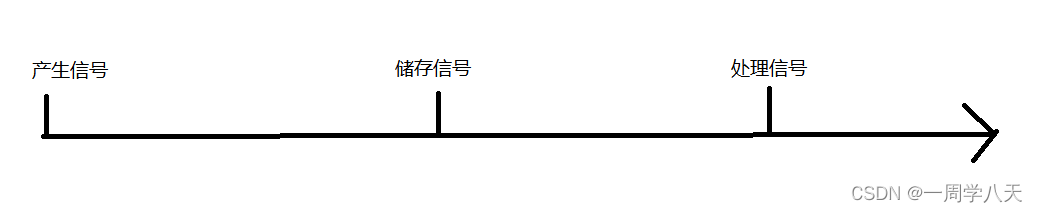
1、产生信号:由通过键盘、系统调用、软件条件、硬件异常产生这几种方法产生信号。
2、信号储存:信号发送到了进程,进程不一定马上处理,所以就需要一种数据结构对信号进行储存
3、处理信号:信号存在的最终目的就是为了相应的进程进行一些动作,也就是信号处理,比如:一个进程出现异常,操作系统发来一个信号希望这个进程终结自己。
二、产生信号
1、通过键盘产生信号
这是一个键盘:
这是一个cpu,上面有很多个引脚 :
这些引脚连接不同的硬件,其中就好引脚连接了我们的键盘:
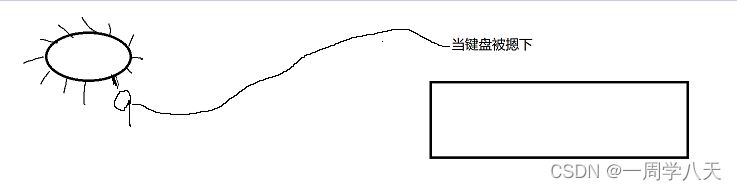
当键盘被摁下,cpu内部就会储存一个中断号,这里是9。
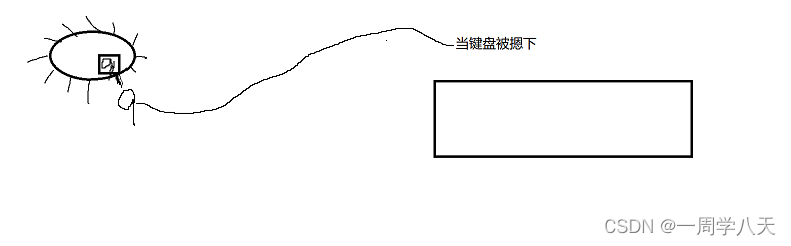
然后cpu就会从一个向量中断表(可以理解为一个数组)里去寻找一个下标为9的元素:
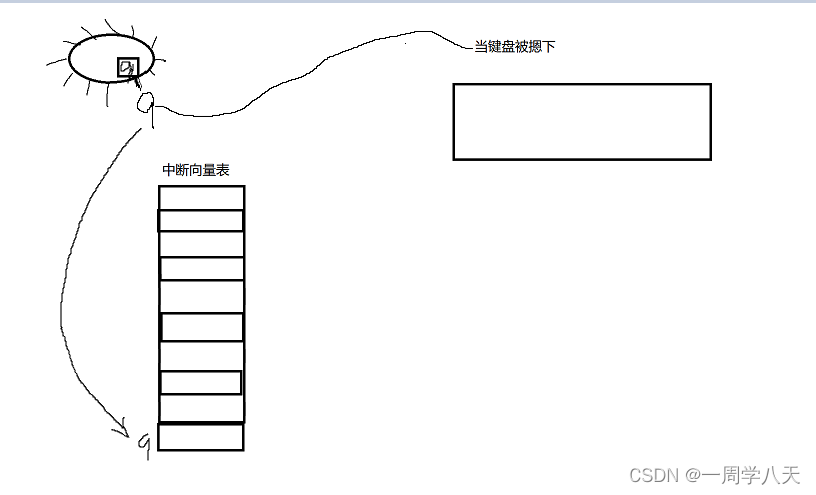
然后这个元素就会指向一个读取键盘的方法:
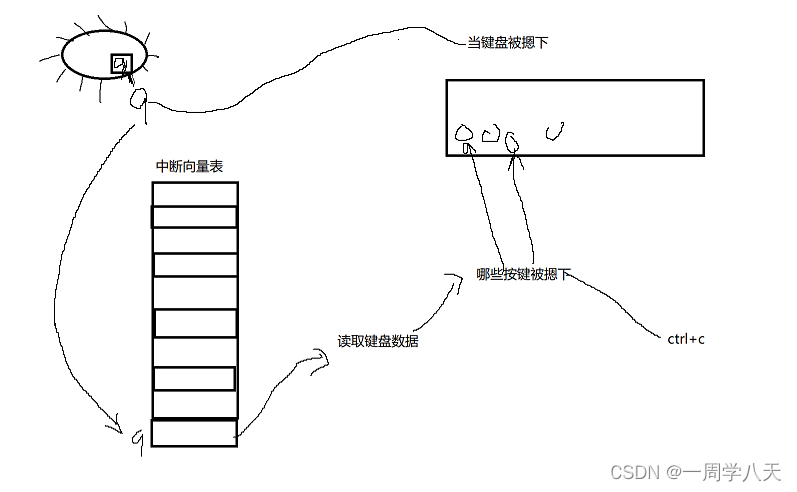
这样就读取到了一个ctrl+c的数据,然后将2号信号写入对应的进程就可以了。
2、系统调用
我们自己编写了一个死循环,在linux上跑:
#include<iostream>
#include<sys/types.h>
#include<unistd.h>int main()
{while(true){std::cout<<"我是进程:"<<getpid()<<std::endl;sleep(1);}return 0;
}这时候我们的写的这个代买就变成了前台进程:我们林外拖出一个控制窗口将他结束:
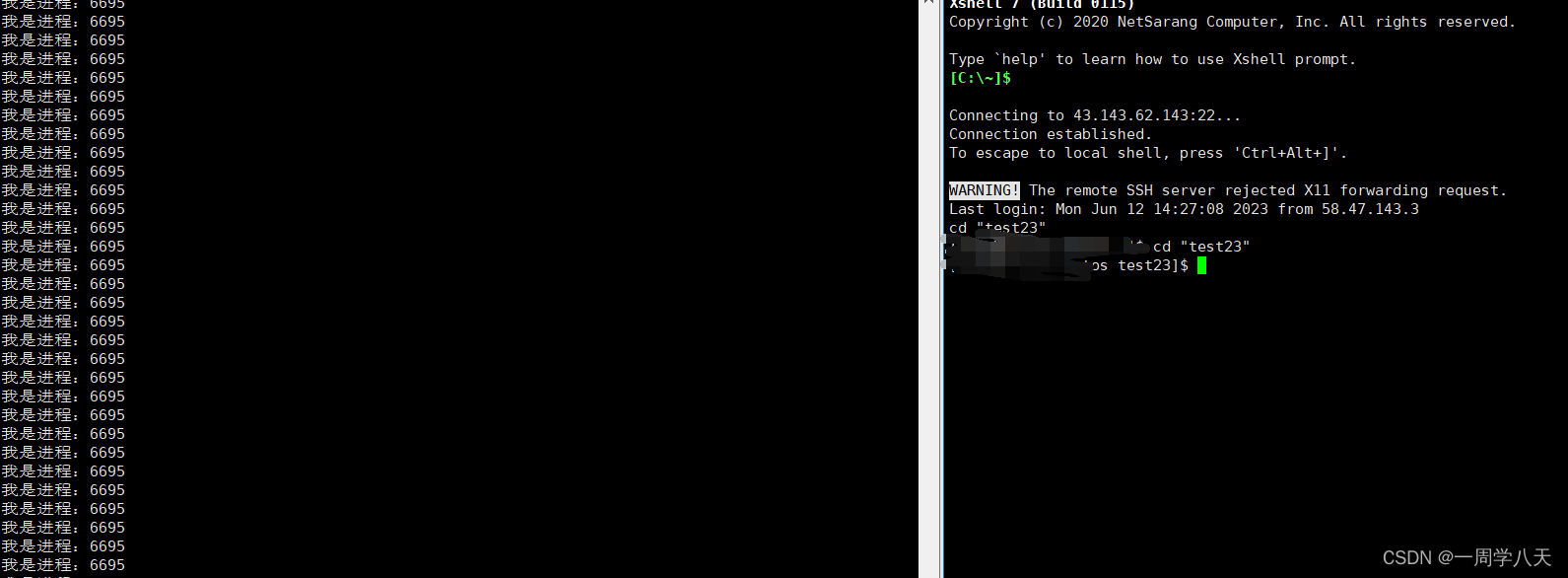
这里我们是调用了kil指令,对进程6695发送一个9号信号,结束进程的: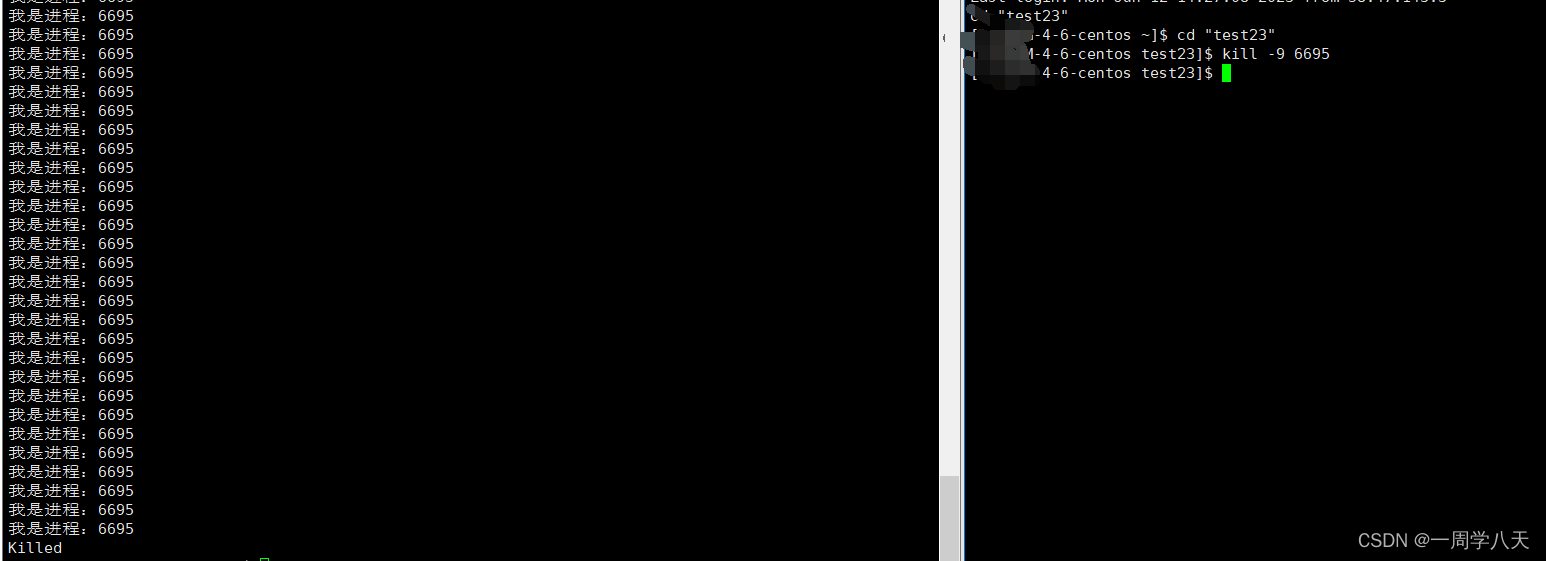
可以看到6695这个进程就被杀死了。
信号一览:
有同学会疑惑,你这个再怎么说也是使用指令发送信号呀,和系统调用有什么关系呢?
答案:我们使用的kill也是一个进程,这个进程底层还是通过调用kill函数来进行终结进程的。
口说无凭,我们来自己写一个mykill指令来实现这个功能。
先来学一下kill函数:
头文件:#include <sys/types.h>
#include <signal.h>原型:int kill(pid_t pid, int sig);
返回值:成功返回0,失败返回-1,并且设定一个错误值。
功能:向一个特定的进程发送一个信号,通过pid锁定。
#include<iostream>
#include<cstdlib>
#include<cstring>
#include<cerrno>
#include<cassert>
#include<string>
#include<unistd.h>
#include<sys/types.h>
#include<signal.h>
#include<stdlib.h>int main(int argc,char *argv[])
{//指令形式:mykill -signo 进程pidif(argc !=3){std::cout<<"按照:./mykill -signo 进程pid 的格式输入"<<std::endl;exit(1);}int target_pid=atoi(argv[2]);int signo=atoi(argv[1]);signo=abs(signo);int n=kill(target_pid,signo );if(n<0){std::cout<<"error:"<<strerror(errno)<<std::endl;exit(2);}return 0;
}接下来我们直接调用我们写的程序
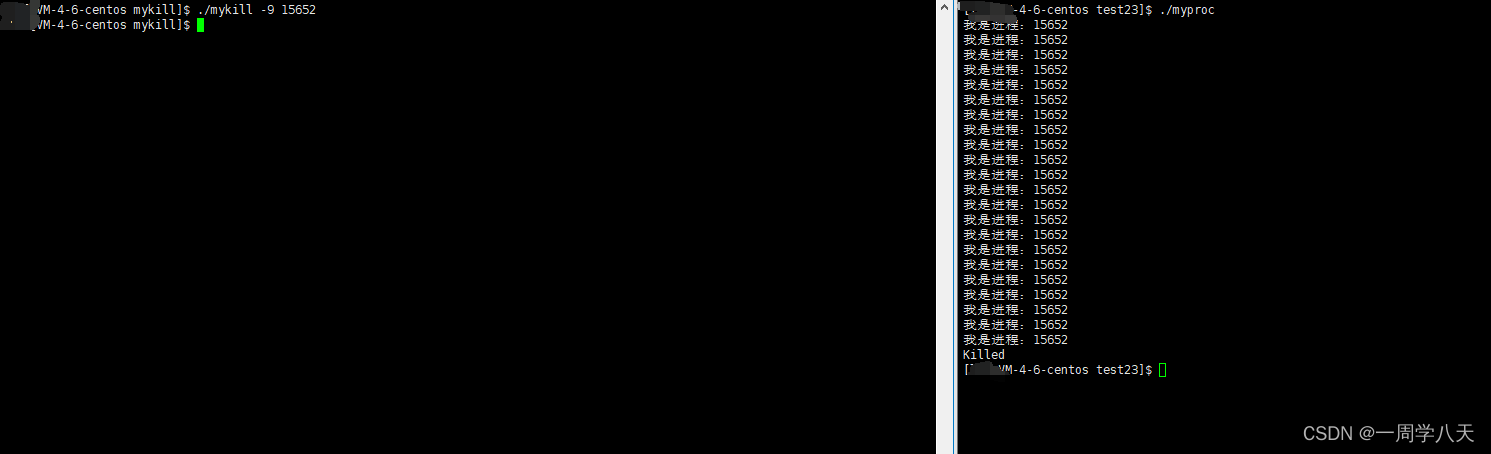
上面的argc和argv[]的意思分别是,调用这个程序的人给这个程序这是了几条指令、和分别是那些指令。也就是指令个数和一个指令数组的意思。
当然这些指令如何处理都是我们需要在程序里面提前设定的。就像信号一样,我们为什么认识信号,因为程序员在编写操作系统的时候就给出了处理信号的对应方案了,所以进程接受到信号就知道该做什么。
我们在这里讨论一个问题:是谁给被结束的那个进程发送的信号呢?
是调用kill函数的进程吗?是操作系统,因为操作系统是软硬件的管理者,他有将信号写入进程的能力,而且kill只是一个系统调用,最终是靠操作系统实现的。
与kill类似的系统调用还有两个:
#include<signal.h>
int raise(int signo);
功能:向调用这个函数的进程,也就是自己这个进程发送信号
#include<stdlib.h>
void abort(void);
功能:终止自己进程
和exit一样,最后一定会调用成功,所以不需要返回值。
这三个函数可以观察出他们的功能一步步缩小。
反正,最终我们得出来一个结论:向进程发送信号的手段之一就是通过系统调用
3、软件条件产生信号
这里我们先介绍一个函数:alarm
#include<unistd.h>
unsigned int alarm(unsigned int seconds);
调用alarm函数,会在seconds秒后向当前进程发送一个SIGALRM信号,该信号默认醋栗动作是终止当前进程。
也就是14信号
它有个特性:该函数的返回值是0,或者是之前设定的闹钟还剩下的秒数。为什么会剩下秒数呢?
打个比方:某人要睡一觉,设置了一个30分钟的闹钟,但是二十分钟后被别人吵醒了,然后就再设置了一个闹钟取代之前的闹钟,设定这个闹钟的时候alarm函数会返回上一个alarm函数的剩余时间也就是10十分钟。
下面是我在其他地方搜索到的:
alarm函数在成功时返回先前设置的闹钟剩余时间,如果没有先前设置的闹钟,它将返回0。如果发生错误,它将返回-1,并设置errno变量。实际上,alarm函数仅仅是设置了内核中的一个计时器,在计时器到达时间时会向进程发送一个SIGALRM信号,所以返回值仅仅是告诉我们在调用alarm函数之前是否有闹钟被设置了,并没有其它的实际意义。此外,当进程接收到SIGALRM信号时,将会执行相应的信号处理函数,但是这并不涉及到alarm函数的返回值。
做一个小实验——一秒到底能进行多少次++操作:
#include<iostream>
#include<sys/types.h>
#include<unistd.h>
#include<signal.h>int count=0;int main()
{alarm(1);while(true){std::cout<<count<<count++<<std::endl;}return 0;
}现在我将这份代码放在linux下跑:
这是第一次运行结果:
这是第二次:
这是第三次:
我们发现每次运行结果都不一样,这其实受很多因素影响,导致每次结果不唯一,比如我用的是云服务器——网速原因,或者同时有多个用户用这台服务器——服务器性能消耗原因等等,但是我想说的是,这台服务器的算力远比这个强。
这是我写的第二份代码:
#include<iostream>
#include<sys/types.h>
#include<unistd.h>
#include<signal.h>int count=0;void myhandler(int signo)
{std::cout<<"get a signal:"<<signo<<std::endl;std::cout<<"count:"<<count<<std::endl;exit(3);}int main()
{alarm(1);while(true){count++;}return 0;
}与第一份的区别是:我不会在每次++都输出一遍了,我一秒后++完了我才打印一次。
运行结果:
![]()
看吧,完全不是一个量级的。
顺带一提:alarm其实就是设置了一个内核中的计时器,我们大胆猜测,一个服务器不一定只跑一个进程,那么对应的,计时器也不一定只有一个进程设立了。如果这样的话,内核很有可能同时存在大量的计时器,那我们的内核是怎么管理这些计时器的呢,有如何准确的找到对应的进程呢?说到底其实还是先描述再组织——通过一个结构体将它封装起来,以便在计时结束后被操作系统找到对应的进程,结构体封装之后,就会有一个堆结构将这个结构体组织起来,这样操作系统在每次遍历这个结构时都能保证最前面的数据就是马上要到时间的那个计时器。
这个例子得出两个结论:
1、软件条件是信号产生的方式之一。
2、oi其实效率非常低下。
3、alarm产生的计时器也需要被组织起来。
4、硬件异常产生信号
模拟一下这个代码:
int main()
{int a=10;a/=0;std::coout<<a<<std::endl;return 0;
}将它放在linux系统下跑:
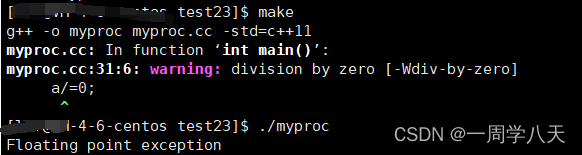
这里我们可以看出,它只是在编译时进行了警报,但是还是编译下去了。Floating point exception的意思是浮点数异常。
但是我一运行这个程序,就直接报错了。这个报错原理其实也是操作系统向该进程写入了一个信号,结合报错文字,我们可以发现就是8号——SIGFPE信号。
接下来我通过硬件来详细解释一下这个的底层原理:
在执行代码的过程中,CPU会不断地从内存中读取指令,解析指令并执行相应的操作。
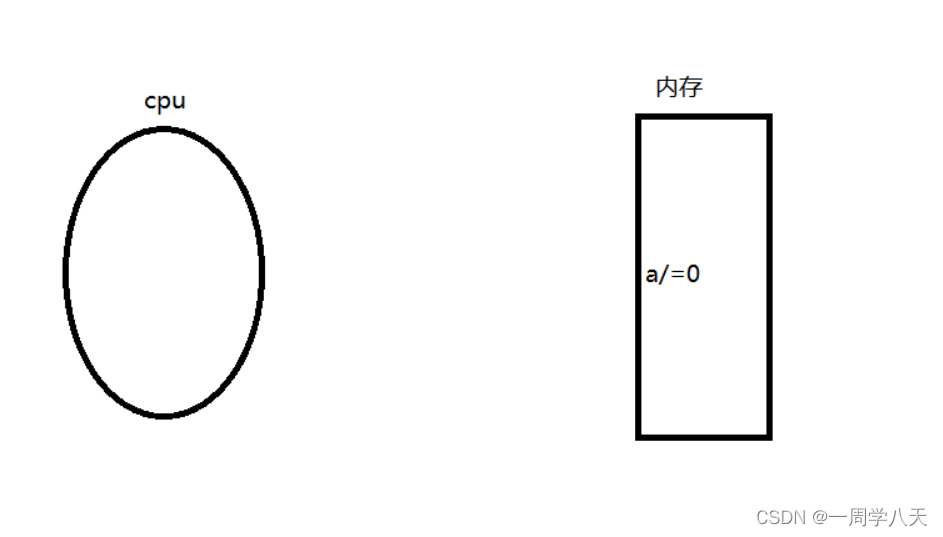
cpu里面有很多个寄存器来帮助它处理这些指令,如图一个存放a,一个存放0:
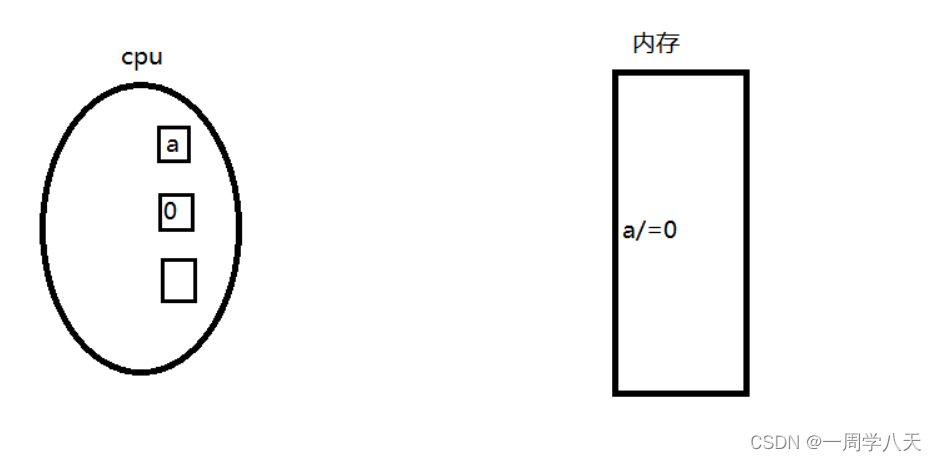
这里还有一个寄存器被称为状态寄存器,如果上面的计算出现了异常,就会置1:
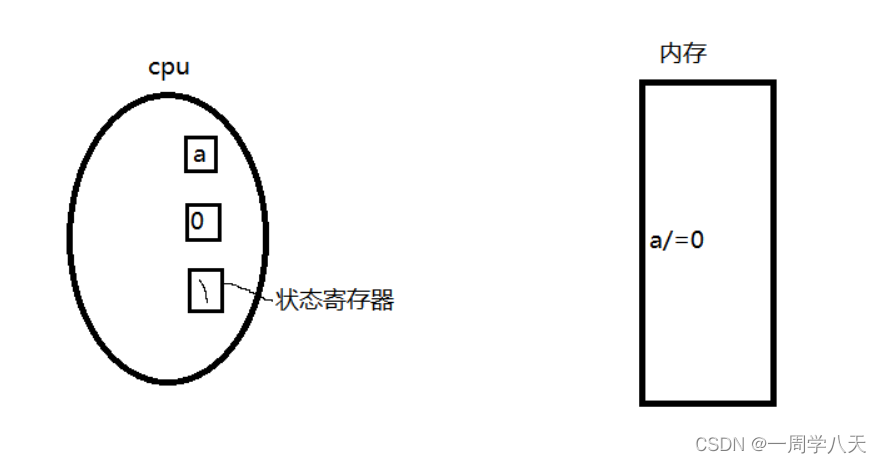
操作系统看到了就会对这个进程写入SIGFPE信号,操作系统是如何找到这个进程的呢——有一个寄存器记录了当前被执行进程的pcd,因此操作系统可以直接找到该进程:
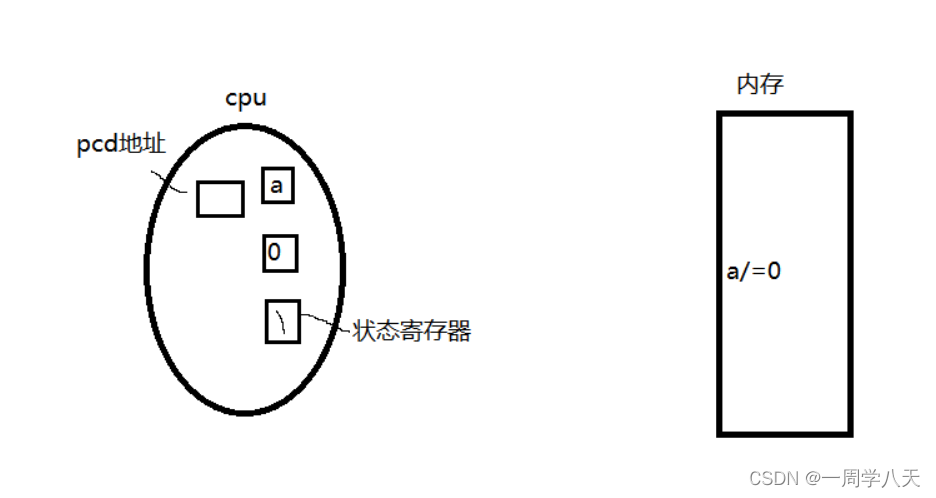
这就是一个进程运行异常产生信号这一过程的原理。这个在linux下跑是这样的结果,如果在vs编译器下跑这份代码就是我们常见的崩溃。
三、Term和core是什么
如梭我不讲,很多朋友一个都不知道这是啥,其实就是信号量一种分类吧,可以理解为。
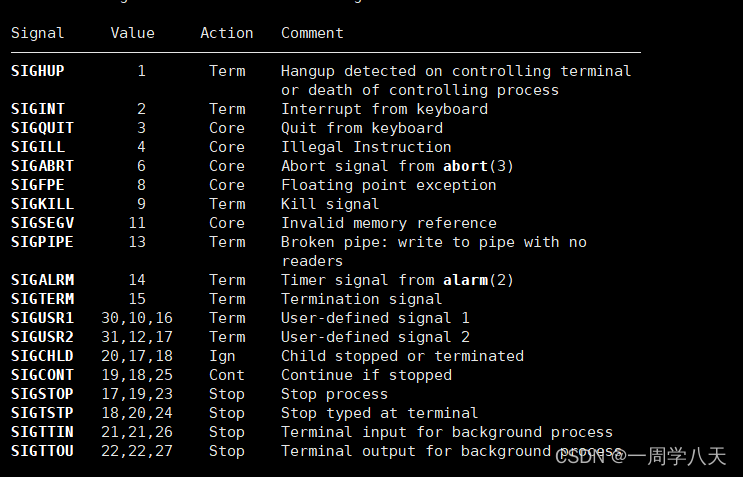
信号大部分都是退出,但是即使他们大部分都一斤是退出了,我们的操作系统还是把2他们的退出模式分了两种,term和core。
term模式就是直接退出进程,不做多余的操作。
core模式就是系统在发现异常时,在退出进程的同时还要对进程进行一次核心转储,将内存中的相关数据(也就是相关代码)dump到磁盘中。生成了一个核心转储文件(在linux终端下对应文件就生成在该程序同级目录下)。
上面说到的相关代码就是生成错误的代码。它存放这些代码的意义就是方便我们进行的调试,我们不需要一点点去看代码哪里出现了错误。
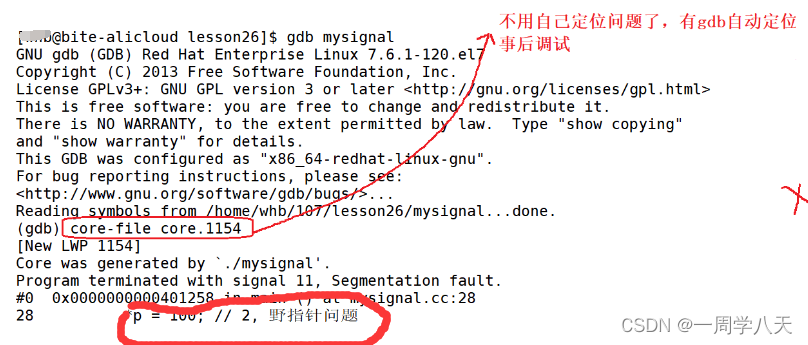
就像上面这里,用gdb进行调试的时候会将核心转储文件中的数据调用出来,方便我们调试。
但是核心转储这个功能在云服务器上一般是关闭的,这就涉及到了另一个问题:
我们一般接触到的环境有:开发环境、测试环境、生产环境。
简单理解就是写代码、调试、对外界提供服务的三种环境,我们学习的时候一般都是将云服务器作为开发测试环境使用的,但在公司里,云服务器严格来说更倾向于生产环境————也就是对外提供服务的环境。
举个例子:默认核心转储功能是开启的,我在一个公司里面工作,然后晚上回家睡觉去了。突然一个本来正常运行的项目突然出现异常,还没人去解决或者停止这个项目,它就一直重复生成一个核心转储文件(偏偏这个文件一般还不小,这个例子里一个文件应该有几十兆),本来是一个进程一直在报错,结果没人管直接就把服务器磁盘给干出问题了。
这个例子在早些年云计算还不是很成熟的时候一些大厂都会遇到的问题,你想想一个服务器停运一天都有可能带来大量的经济损失,这个问题是非常重大的了。
后来技术成熟了,一般云服务器都是默认将这个功能关闭的,不过你要是测试代码的话也可以把它打开就是了。
另外很多同学都很好奇为什么有这么多信号,而且功能还都是一样的:就像我们活着一样,没有人会追究我们是怎么活着的,但是我们如果去世了,警察叔叔一定会追究我们的死因。一样的道理,我们需要知道一个进程出现异常的原因。





