文章目录
- 底层数据结构:
- HashMap有什么特点?
- HashMap 1.7 是如何解决Hash冲突的?
- HashMap 1.7 是如何降低Hash冲突概率的?
- HashMap 的长度为什么是2的幂次方?
- HashMap 容量应该如何设置?
- 高并发下如何使用HashMap?
- HashMap在高并发下为什么不安全?
- 总结的put()和get()方法的流程图
底层数据结构:
数组+链表数组特点:根据下标定位,一般情况下查询、修改快于链表。链表特点:连接元素通过指针,新增和删除只需变更指针连接即可,所以一般情况下增删快,查询因需要遍历链表,所以查询效率一般慢于数组。
HashMap有什么特点?
无序,散列存放,遍历结果与存储顺序不一定一致。
如果需要有序存放,可以使用LinkedHashMap来存放元素。
HashMap 1.7 是如何解决Hash冲突的?
采用链地址法来存储发生Hash冲突的元素。
HashMap 1.7 是如何降低Hash冲突概率的?
- 使用2的幂次方作为容量,计算时使用len-1与key的hash做与运算,减少hash冲突的概率。
- 高16位做异或运算,(h = key.hashCode()) ^ (h >>> 16)。
HashMap 的长度为什么是2的幂次方?
- 为了减少Hash碰撞,使Hash计算结果更均匀。
- 做与运算时,我们需要取数组长度-1,比如使用默认长度16,那么参与与运算的值为15,15的二进制为0000 1111,此时,参与与运算后得到的key的位置还是key本身,这样可以使key分布的更均匀。
HashMap 容量应该如何设置?
- 參考阿里巴巴开发手册,集合初始化时,应该指定初始值大小。
- initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即loader factor)默认为0.75, 如果暂时无法确定初始值大小,请设置为16(即默认值)。
- 如果存储1W个key,那么按照公式:i = 10000/0.75 +1 =13334个。如果不设置初始容量,则需要扩容10次左右,影响效率。
高并发下如何使用HashMap?
- 线程安全的集合类主要包括了三大类:
- 遗留的线程集合类如Hashtable、Vector;性能较低
- Collections修饰的线程安全集合类如synchronizedMap;使用synchronized修饰来保证线程安全。
- JUC包下的安全类。
- 高并发下推荐使用ConcurrentHashMap来保证线程安全。
HashMap在高并发下为什么不安全?
-
数据覆盖问题
- 高并发下两个线程同时做put操作,当key相等时,第二个线程可能会覆盖第一个线程的值。
-
循环链表问题
-
此问题主要发生于扩容时。链表使用了头插法,在扩容时可能会导致原有的链表顺序逆转。
举例:比如原先链表为a-b-c-null,此时需要扩容,有两个线程同时扩容,第一个线程执行一半因为某种原因卡住了,此时线程2开始执行,执行完成后,c又指向了a,此时线程1恢复执行,本来线程1执行到c后,下一个元素为null,就会停止执行,但是受到线程2的影响此时c指向了a,所以继续执行,就构成了循环链表。
-
导致的问题:在put或get方法时,会遍历链表,但此时链表构成了循环,所以会一直遍历,导致死循环,逐渐CPU占用会达到100%居高不下。
-
-
数据get()为null的情况
- 当并发操作时,此时有两个线程,一个执行get方法,一个执行put方法,此时执行put方法导致了扩容,会创建一个新数组,引用会赋给新数组,此时可能数据还没有移动到新数组,如果此时执行get方法,那么取到的值可能为空。
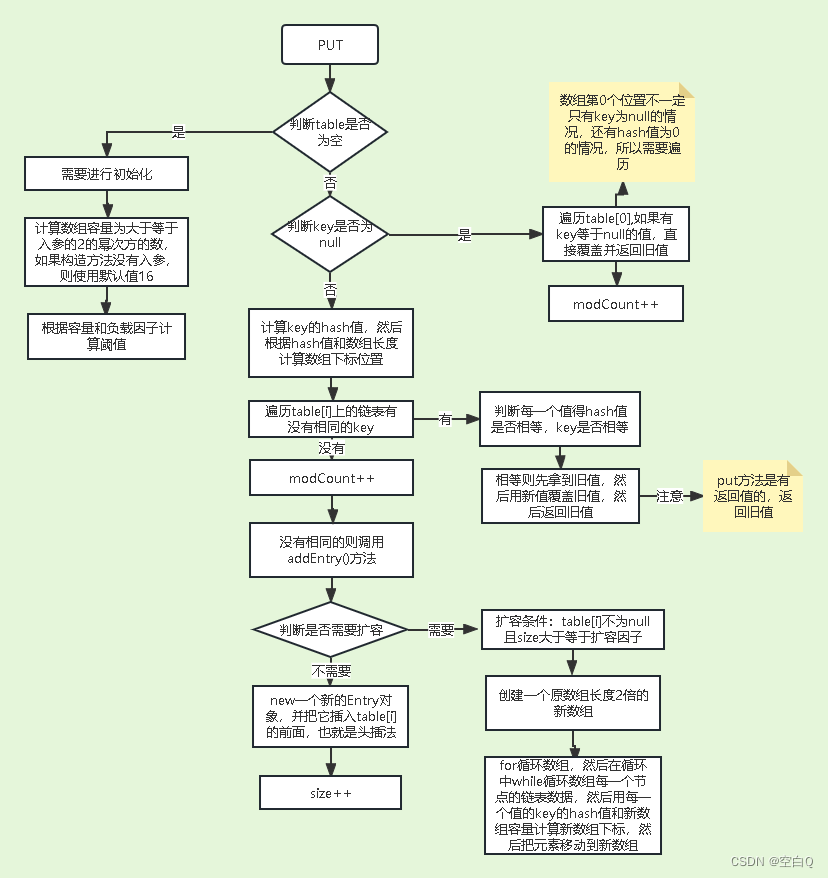
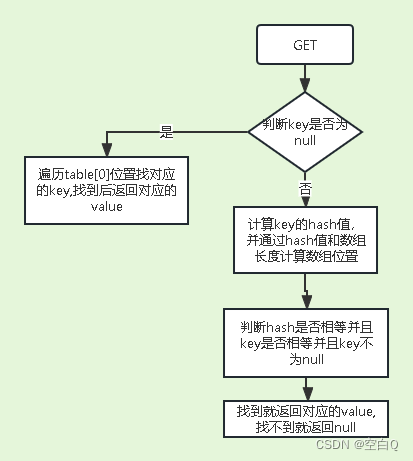
总结的put()和get()方法的流程图
- PUT方法:
- GET方法:


![[刷题]背包问题](https://img-blog.csdnimg.cn/62c4c146493f4b858ccf30d736ae60d9.png#pic_center)
![[入门必看]数据结构2.3:线性表的链式表示](https://img-blog.csdnimg.cn/a328d24baf92460e87dd84a46bd9ccfb.png#pic_center)