每日一歌,分享好心情: 你莫走
关于nvidia计算能力的一切,看完这篇文章足够用了…
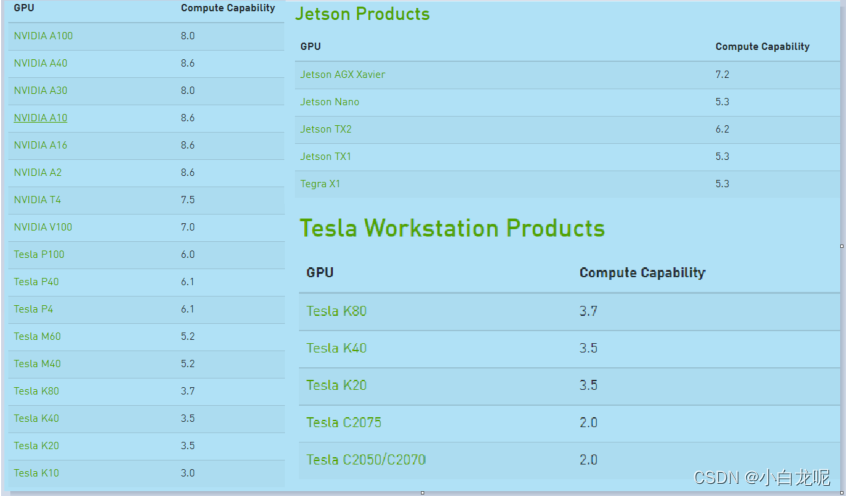
一、常见gpu卡计算能力查询
https://developer.nvidia.com/cuda-gpus#compute
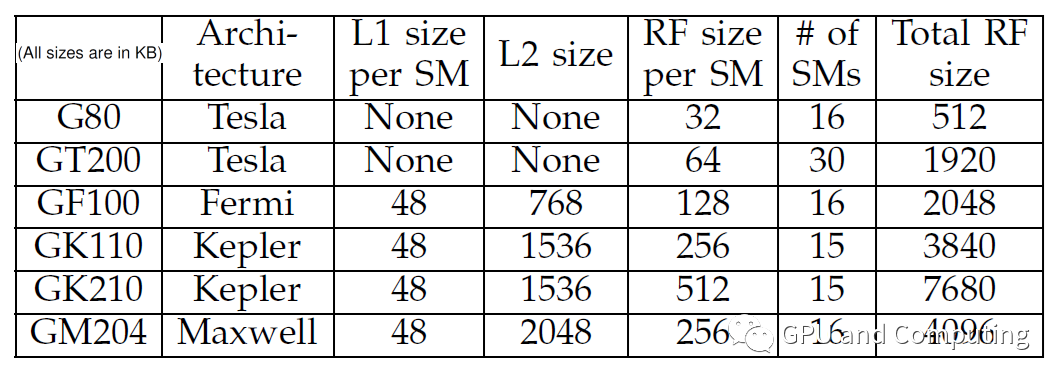
部分gpu计算能力:
二、计算能力是什么东东
- 计算能力(Compute Capability)并不是指gpu的计算性能
- nvidia发明计算能力这个概念是为了标识设备的核心架构、gpu硬件支持的功能和指令,因此计算能力也被称为“SM version"。
计算能力包括主修订号X和次修订号Y来表示, 主修订号标明核心架构,次修订号标识在此核心架构上的增量更新。 - 计算能力版本号与CUDA版本号(例如CUDA7.5、CUDA8等)不能混淆,cuda是一个软件平台,新版本的cuda通过增加默认支持的计算能力进而支持nv新推出的gpu硬件。
下图是来自英伟达官方说明:

三、编译常见后端时怎么设置计算能力(亲测有效)
在编译caffe/pytorch…这些后端时都有默认的计算能力,但通常不满足我们的使用要求,需要自己设置计算能力以达到最好的性能。
- 编译tensorflow c++接口设置计算能力
在 《Tensoflow c++ so编译 基于bazel》 中有说明,不再赘述。 - 编译pytorch c++接口设置计算能力
pytorch源码: https://github.com/pytorch/pytorch
pytorch在编译过程中使用了环境变量TORCH_CUDA_ARCH_LIST,在编译前设置此变量即可
例如:
export TORCH_CUDA_ARCH_LIST="7.0;7.5;8.6" #设置计算能力
python3 ../tools/build_libtorch.py #开始编译
在Readme.md中有关于这个变量的说明,值得注意的是pytorch默认支持gpu

详情请查阅源码 中的setup.py 文件。
- 编译TensorRT c++接口设置计算能力
增加编译选项 GPU_ARCHS
export TRT_RELEASE=/TensorRT-8.2.1.8 #设置TRT未开源包地址,需要提前下载
cmake .. -DTRT_LIB_DIR=$TRT_RELEASE/lib -DTRT_OUT_DIR=`pwd`/out -DBUILD_PLUGINS=ON -DBUILD_PARSERS=ON -DGPU_ARCHS="70 75 80 86"
make -j
- 编译caffe c++接口设置计算能力
caffe源码: https://github.com/BVLC/caffe/blob/master/cmake/Cuda.cmake
在caffe 源码目录下的 cmake/Cuda.cmake文件中设置计算能力:

我们可以在编译之前设置
export CUDA_ARCH_NAME=All
#然后再修改./cmake/Cuda.cmake文件中的Caffe_known_gpu_archs变量即可
四、进阶
编译时设置的计算能力列表是怎么起作用的?
在计算能力为7.5的编译计算机上是怎么编译出能够支持计算能力为8.6的软件程序的?
是交叉编译吗?
这个问题涉及到了cuda编程模型,咱们后文详谈…
今天就到这儿,干饭,走起~