在《近距离看GPU计算》系列第一篇里我们介绍了GPU的一些基础知识及其如何从图形加速设备演化到通用计算平台。本文我们会具体从处理单元设计和存储层次结构两个方面探讨GPU不同于CPU的特点,再次确认我们反复申明的GPU更重视整体的Throughput而CPU更在乎具体任务的Latency。CPU和GPU从一开始就是为不同的目标而设计,CPU虽然也可以同时执行多个线程,但其旨在高效地处理串行指令,通过许多复杂技术优化提高指令级并行以便可以尽快执行串行程序。而GPU却是生而为同时执行成千上万个线程,牺牲单个线程性能换取整体性能最大化。下图对CPU与GPU的抽象架构进行了比对,其中Control是控制器、Core是处理单元、Cache指的是各级缓存、DRAM就是内存。我们可以看到GPU设计者将更多的晶体管用作执行单元,而不是像CPU那样用作复杂的控制逻辑和缓存。
 在下面章节里,我们会具体讨论这两种设计面向带来的影响,在本文讨论里笔者尽量不拘泥具体产商的特定GPU产品,而是希望能给出一般的指引,但是因为文本材料的优势以及在通用计算领域明显的优势地位,我们大概还是不能脱离Nvidia GPU的语境, AMD GPU的处理单元设计细节与Nvidia有较大不同,以后我们可以专文讨论。
在下面章节里,我们会具体讨论这两种设计面向带来的影响,在本文讨论里笔者尽量不拘泥具体产商的特定GPU产品,而是希望能给出一般的指引,但是因为文本材料的优势以及在通用计算领域明显的优势地位,我们大概还是不能脱离Nvidia GPU的语境, AMD GPU的处理单元设计细节与Nvidia有较大不同,以后我们可以专文讨论。
一,SIMT和硬件多线程
根据计算机历史上有名的的费林分类法(Flynn's Taxonomy),如下图所示计算机体系架构可以简单分为四类,分别是:
单一指令流单一数据流计算机(SISD, Single Instruction Single Data)
单一指令流多数据流计算机(SIMD, Single Instruction Multiple Data)
多指令流单一数据流计算机(MISD, Multiple Instruction Single Data)
多指令流多数据流计算机(MIMD, Multiple Instruction Multiple Data)
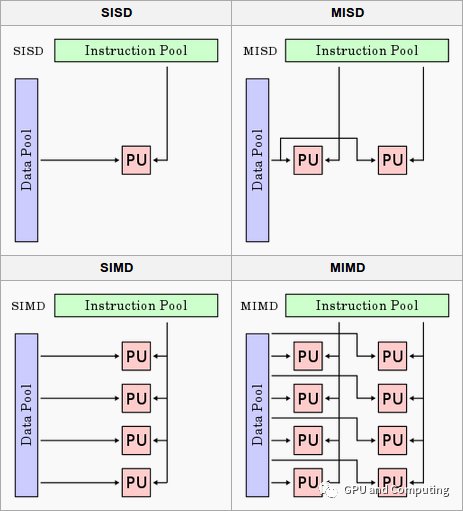
单核CPU可以归类为SISD,多核CPU属于MIMD。我们重点关注的SIMD指的是采用一个控制器来控制多个处理单元,同时对一组数据的元素分别执行相同的操作从而实现空间上并行的技术。传统CPU的指令扩展SSE和NEON都属于典型的SIMD。现代GPU在SIMD基础上发展出SIMT(Single Instruction Multiple Thread)的执行架构。传统SIMD是一个线程调用向量处理单元(Vector ALU)执行向量指令来操作向量寄存器完成运算,而SIMT往往由一组标量处理单元(Scalar ALU)构成,每个处理单元对应一个硬件线程,所有处理单元共享指令预取/译码模块并接收同一指令共同完成SIMD类型运算,运行其上的线程可以有自己的寄存器堆,独立的内存访问寻址以及执行分支。我们以Nvida CUDA为例来介绍SIMT是如何运作的。下图是有关分发CUDA的计算任务到GPU硬件上执行,展示了软硬件视角各个层级的对应关系。
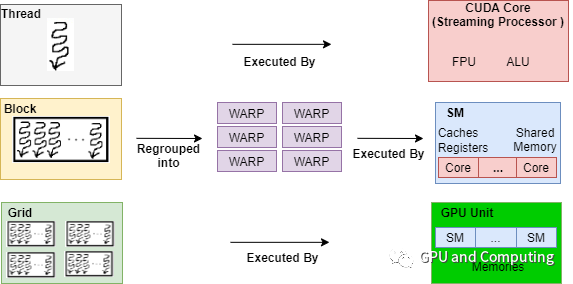
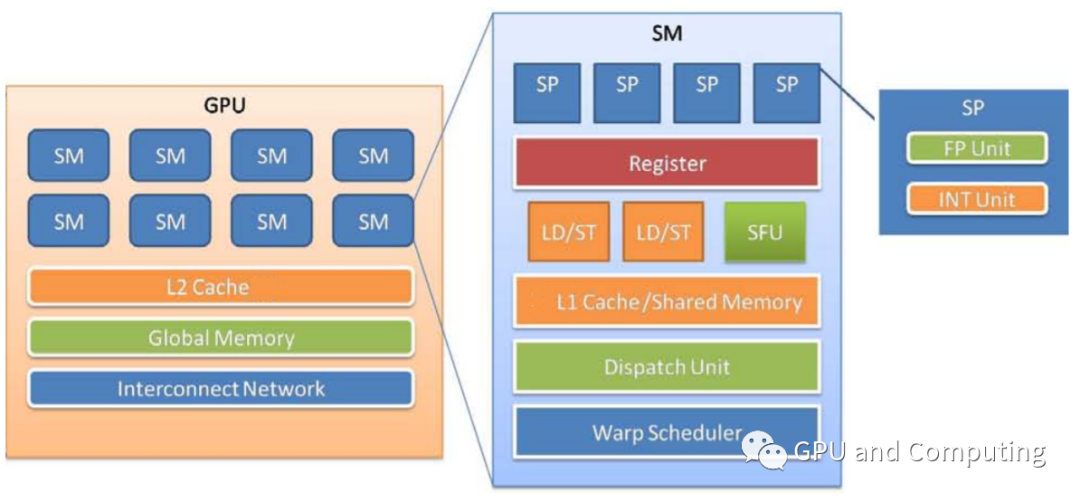
我们先介绍层级图右面的GPU硬件层次,CUDA的GPU有很多SM(Streaming Multiprocesso)组成。一个SM又有很多SP(Streaming Processor)构成,SP是每个线程具体执行指令所在,SP也采用流水线设计以提高指令级并行,但它一般都是顺序执行,很少使用分支预测、动态执行等复杂技术。
在GPU通用计算语境下GPU设备上执行的程序被称为Kernel,针对某个Kernel分发的所有线程都执行相同的程序,这些线程被组织成一系列层次结构,也就是Grid和Block,如层级图左边所示。Grid规定各个维度Block的数量,Block规定各个维度线程的数量,它们的尺寸大小都是在CUDA程序中分发Kernel时指定。下图程序中vecAdd就是Kernel程序,Kernel的分发是由<<<...>>>语法定义,其中规定了要分发的Kernel程序,Grid和Block的尺寸,以及Kernel程序的参数。
|

在实际执行过程中,GPU会以Block为单位,把相同Block的线程分配给同一个SM进行运算,Block中的线程可以通过Shared Memory交换数据(注:Shared Memory访问性能类似L1,与Cache由硬件控制对软件透明不同,Shared Memory由软件显式移动数据),并支持相互同步操作。在硬件内部,Block进一步会被为分组成Warp,Warp是GPU硬件最小调度单位,Warp内的线程被分配给SP按照SIMD的模式工作,也就是这些线程共享同样的PC(程序计数器),以锁步(Lockstep)的方式执行指令。目前支持CUDA的GPU其Warp大小都是32,SM中SP的数量可能只有8或者16,在这种情况下,一条指令Warp需要跨几个时钟分批执行。我们再来看下GPU硬件可以支持的线程数量,以Fermi GF100为例,该GPU一共有16个SM,每个SM最多可以容纳48个Warp,也就是1536个线程,整个GPU可以支持24576 个线程同时在线。我们可以与CPU对照下,消费级CPU一般有2~8个核,就算打开Hyperthreading,一共也就支持十几个硬件线程同时在线。为了避免一些高延迟指令引起处理单元流水线停顿,CPU和GPU采取了完全不同的做法。
CPU的做法是一方面穷尽所能充分挖掘指令级并行来规避,另一方面通过各级Cache来掩盖访问内存延迟,万不得已CPU才会切换到别的硬件线程执行。硬件线程数量太多切换太频繁即使有助于整体吞吐却恶化单个线程的延迟对CPU设计来说也是不可接受的,所以我们可以看到Hyperthread的数目一般都比较少。
GPU的做法是另外一种思路,大规模数据并行带来海量的可执行线程,GPU完全可以通过切换到别的线程Warp来规避指令延迟带来处理单元的停顿。这种切换会非常频繁,需要在很短时间完成(比如一个时钟),所以无论每个线程执行需要的的寄存器堆还是Block之内线程的Shared Memory从一开始就要分配妥当,切换过程中线程上下文一直驻留,直到线程或者整个Block执行结束才能释放。所以相比CPU,GPU的Register File大小非常惊人,而其处理单元的设计却可以异常简单。
二,GPU的Memory Hierarchy
根据我们先前文章《多线程计算平台的性能模型》的观察,一方面GPU通过同时运行很多简单的线程,不使用或者只利用相对较小的Cache,而主要通过线程间的并行来隐藏内存访问延迟。另一方面显存带宽对整体计算吞吐又有重要意义,直接关系到GPU性能伸缩能力。所以如下图所示,GPU存储层次设计的时候,相比Latency,更重视Throughput,而且各级存储容量相对偏小。
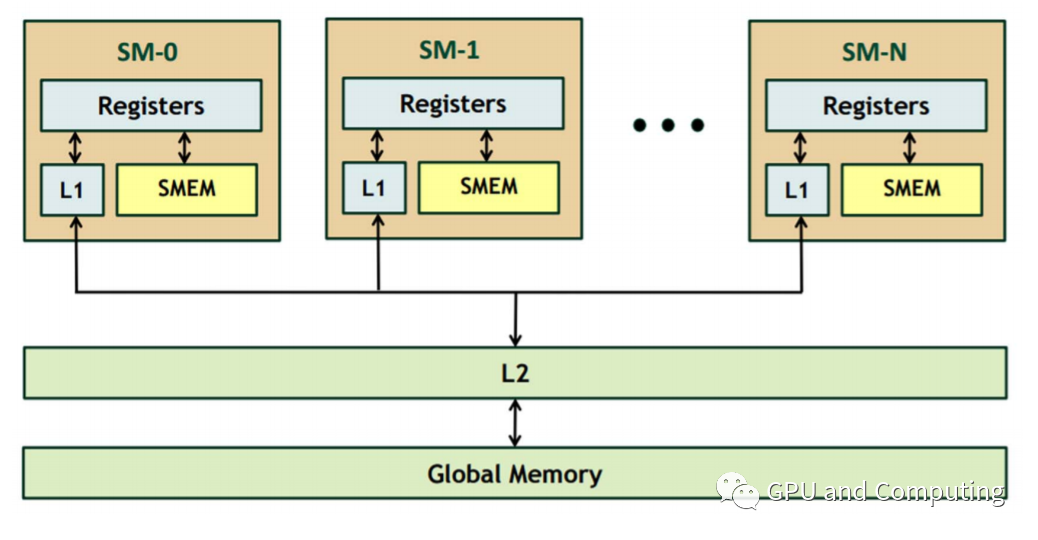
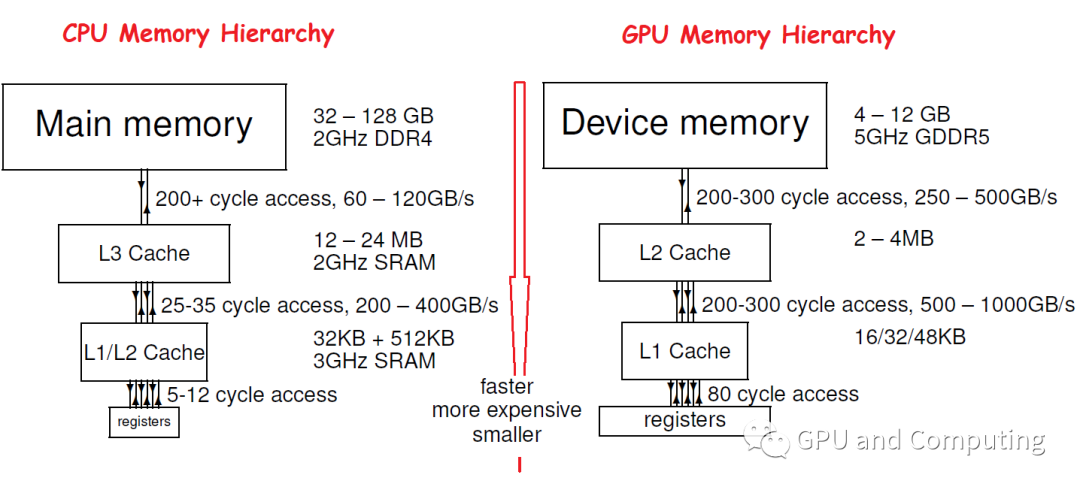 以Fermi GF100 GPU为例,下图是其存储层次结构,Fermi GPU是CUDA GPU第一次添加L1和L2的支持,其中L1和Shared Memory共享同一块片上内存,每个SM各64K大小,可以根据要求以48K/16K或者16K/48K在L1和Shared Memory之间分配。
以Fermi GF100 GPU为例,下图是其存储层次结构,Fermi GPU是CUDA GPU第一次添加L1和L2的支持,其中L1和Shared Memory共享同一块片上内存,每个SM各64K大小,可以根据要求以48K/16K或者16K/48K在L1和Shared Memory之间分配。
下面表格是几代CUDA GPU的L1、L2和Register File大小配置。我们可以看到最早的CUDA GPU也就是G80都没有通用的L1和L2,只有16K的Shared Memory。至于为什么添加Cache的支持,主要是考虑到对某些应用来说可能没有足够的数据并行来掩藏访存延迟,而对另外一些应用其数据重用模式不可预测无法有效利用软件控制的Shared Memory,总之是为了让GPU变得更通用,能够兼容更多的计算范式。
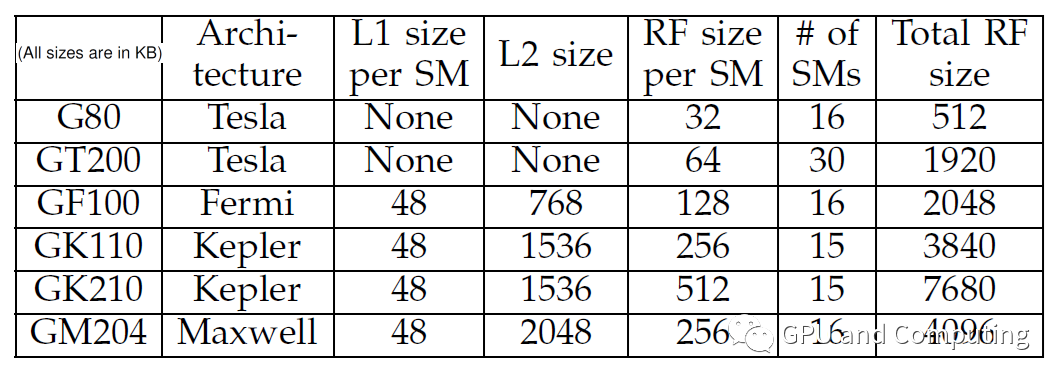
饶有趣味的是,对GF100,RF大小总共为2048K,L1为48x16=768K,L2也是768K,RF反而比L1和L2都要大,而L1和L2差不多,其它GPU也有类似现象,这好像大大颠覆了我们之前在《衡量计算效能的正确姿势(3)》了解的CPU存储层次类似金字塔型的结构,不知道读者们有何感想?
夏日炎炎不是读书天,这篇文章拖了好长时间,实在无法忍受才终于出炉,文章内容都是纸上功夫,请各位看官抱将信将疑的态度,如果有明显错误,欢迎后台留言纠正。下篇不知又要到什么时候,这次就先不预告内容了。
主要参考资料:
Many-core vs many-thread machines: Stay away from the valley
Cuda C Programming Guide
CUDA Warps and Occupancy
SIMD < SIMT < SMT: parallelism in NVIDIA GPUs
The Top 10 Innovations in the New NVIDIA Fermi Architecture, and the Top 3 Next Challenges
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果觉着内容有帮助,请帮忙关注、点赞、在看并分享给更多的朋友。谢谢!