- 下面的代码都是在tensorflow版本 1.8 运行的
- Tensorflow 使用GPU训练的时候一个小说明
1. tensorflow 默认占满所有可用GPU
2. 如果一台机器上有多个GPU,那么默认只会有第一块GPU参与计算,其余的会白白浪费掉
- 单机单卡
常规操作,省略
-
单机多卡
- 各卡执行不同模型训练任务
# 只需要在代码开头导入os,并指定使用第几块GPU,默认重0开始 import os os.environ["CUDA_VISIBLE_DEVICES"]="0" # 指定GPU就好了# 如果想查看可用的GPU,可以使用下面的代码 def get_available_gpus():"""获取可用的GPU设备 --> ['/device:GPU:0', '/device:GPU:1', '/device:GPU:2']"""from tensorflow.python.client import device_lib as _device_liblocal_device_protos = _device_lib.list_local_devices()return [x.name for x in local_device_protos if x.device_type == 'GPU']# 等会用到的代码 def average_gradients(tower_grads):"""这个代码没变过,都是官网给的"""average_grads = []for grad_and_vars in zip(*tower_grads):grads = []for g, _ in grad_and_vars:expend_g = tf.expand_dims(g, 0)grads.append(expend_g)grad = tf.concat(grads, 0)grad = tf.reduce_mean(grad, 0)v = grad_and_vars[0][1]grad_and_var = (grad, v)average_grads.append(grad_and_var)return average_grads- 各卡协同执行训练同一模型任务
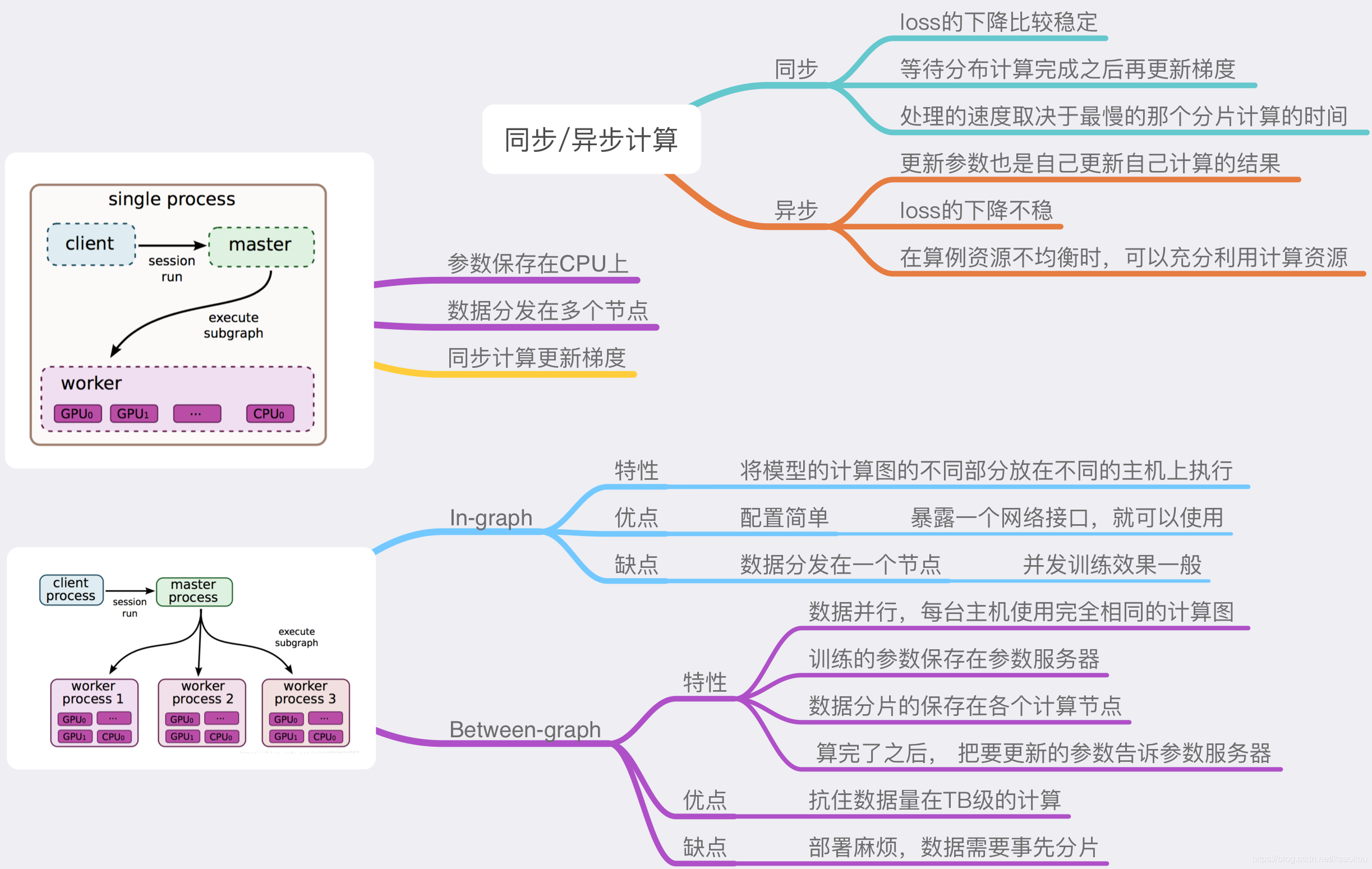
- 异步
'''异步计算介绍 1. 多卡计算的时候各自都有权限更新参数 2. 会导致loss下降不稳定 '''import os os.environ["CUDA_VISIBLE_DEVICES"]="0,1" # 指定使用前两块GPUdef multi_train():"""异步GPU代码"""with tf.device("/cpu:0"):# 定义输入的占位符X = tf.placeholder(tf.float32, [None, num_input])Y = tf.placeholder(tf.float32, [None, num_classes])opt = tf.train.AdamOptimizer(learning_rate)num_gpu = len(get_available_gpus())tower_grads = []with tf.variable_scope(tf.get_variable_scope()):for i in range(2):with tf.device("/gpu:%d" % i):with tf.name_scope("tower_%d" % i):# step1.划分数据_x = X[i * batch_size:(i + 1) * batch_size]_y = Y[i * batch_size:(i + 1) * batch_size]logits = build_model(_x) # 调用自己写的构建模型,返回logitstf.get_variable_scope().reuse_variables() # 重用变量# step2. 计算loss以及gradsloss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=_y, logits=logits))grads = opt.compute_gradients(loss) tower_grads.append(grads)grads = average_gradients(tower_grads)# 这个情况时异步执行train_op = opt.apply_gradients(grads)# 后面的就是一样的代码的了with tf.Session() as sess:sess.run(tf.global_variables_initializer())for step in range(1, num_steps + 1):batch_x, batch_y = mnist.train.next_batch(batch_size * num_gpus)sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})- 同步
'''同步计算介绍 1. 由CPU调度,等待所有GPU计算之后的平均grads更新参数 2. loss下降稳定,但是效率取决于最慢的那个GPU注意:同步计算,如果初始化不恰到或者初始学习率设置过大,梯度很容易爆炸 注意:如果查看loss会发现会出一个nan,然后之后loss一直在一个固定的数值 ''' import os os.environ["CUDA_VISIBLE_DEVICES"]="0,1" # 指定使用前两块GPUdef multi_train():"""同步GPU代码"""with tf.device("/cpu:0"):# 定义输入的占位符X = tf.placeholder(tf.float32, [None, num_input])Y = tf.placeholder(tf.float32, [None, num_classes])opt = tf.train.AdamOptimizer(learning_rate)num_gpu = len(get_available_gpus())tower_grads = []with tf.variable_scope(tf.get_variable_scope()):for i in range(2):with tf.device("/gpu:%d" % i):with tf.name_scope("tower_%d" % i):# step1.划分数据_x = X[i * batch_size:(i + 1) * batch_size]_y = Y[i * batch_size:(i + 1) * batch_size]logits = build_model(_x) # 调用自己写的构建模型,返回logitstf.get_variable_scope().reuse_variables() # 重用变量# step2. 计算loss以及gradsloss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=_y, logits=logits))grads = opt.compute_gradients(loss) tower_grads.append(grads)grads = average_gradients(tower_grads)# 同步代码global_step = global_step=tf.train.get_or_create_global_step()update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)with tf.control_dependencies(update_ops):train_op = opt.apply_gradients(avg_grads, global_step=global_step # 这样子是同步# 后面的就是一样的代码的了with tf.Session() as sess:sess.run(tf.global_variables_initializer())for step in range(1, num_steps + 1):batch_x, batch_y = mnist.train.next_batch(batch_size * num_gpus)sess.run(train_op, feed_dict={X: batch_x, Y: batch_y}) -
多机单卡
目前查到了一个例子,不过还没有调试过,如果确认能够运行再贴上来
- 多机多卡
同多机单卡,多机单卡成功之后,无非是py文件换成单机多卡的py文件而已
- 参考链接
https://www.tensorflow.org/tutorials/images/deep_cnn - 最后,如果大家有什么说的话可以在下方留言,一起学习探讨