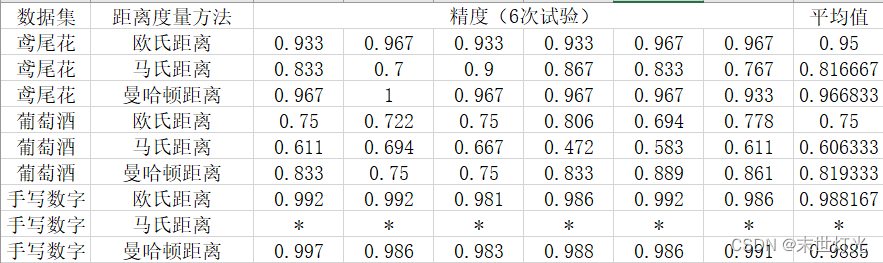
线程状态的解读
RUNNABLE
线程处于运行状态,不一定消耗CPU。例如,线程从网络读取数据,大多数时间是挂起的,只有数据到达时才会重新唤起进入执行状态。
只有Java代码显式调用sleep或wait方法时,虚拟机才可以精准获取到线程真正的状态。调用本地方法时,无法抓取本地代码的内部执行状态。
TIME_WAITING(on object monitor)
线程被挂起一段时间,正在执行obj.wait(int time)的方法。不消耗CPU。
TIME_WAITING(sleeping)
线程被挂起一段时间,正在执行Thread.sleep(int time)的方法。不消耗CPU。
TIME_WAITING(parking)
线程被挂起一段时间,正在执行lock()的方法。不消耗CPU。
WAINTING(on object monitor)
线程被挂起,执行执行obj.wait()的方法,只能通过notify或notifyAll方法唤醒。不消耗CPU。
死循环代码排查
如果两次间隔时间打出来的堆栈,排除掉wait和sleep状态的线程,存在相同的线程操作。需要怀疑是不是有死循环代码存在。
(1)使用了线程不安全的集合类,HashMap在多线程读写场景,主要指的jdk1.7及其以前。详细分析可见这篇文章https://blog.csdn.net/m0_46405589/article/details/109206432
(2)对共享变量没有做保护
(3)其他,借助top命令,输入1,看到每个核的cpu使用率
CPU使用率异常代码排查
可能原因:
Java代码中存在死循环代码
JNI代码中存在死循环代码
堆内存过小导致频繁的GC
在32位JDK中,由于堆内存设置过大造成的频繁GC?
系统不合理的设计,如不间断的轮循操作
JDK源码的死循环bug
分析手段:
top -p 进程号,输入H,查看进程下所有线程的统计情况。其中的PID与堆栈信息中nid对应,nid为16进制
kill -3 进程号,打印线程堆栈
pstack 线程号,打印本地线程堆栈
在第二步中的线程堆栈中找到最耗CPU的pid对应的nid号,如果是纯java代码,说明是java代码执行造成的,如果是正在执行native方法,说明问题代码在JNI代码中,需要去第三步中得到的本地线程堆栈中,根据最耗CPU的pid,定位代码。
如果在第4步找不到,可能是JNI调用中重现创建新线程来执行了,可能是虚拟机自身代码导致,如频繁Full GC操作。
对于耗时多的代码片段,通过多次打印堆栈的方式找到
资源不足导致性能下降代码分析
原因分析:
看到大量的线程处于WATING状态,表示等待资源释放,可能是资源配置太少,可能是资源长时间被占用没有释放,最终越来越慢。
线程不退出导致系统挂死
原因分析:线程挂死
分析方法:
获取第一次堆栈信息
等待一定时间,获取第二次堆栈信息
比较第一次和第二次堆栈信息,找出一直活跃的线程。如果没有发现活跃的线程,可能是其他原因。如果有,可能是:
(1)线程正在执行死循环代码
(2)资源不足或泄露,当前线程阻塞在锁对象,wait在锁对象状态
(3)与外部程序通信场景,外部程序通信阻塞
内存泄露代码分析
常见场景:
全局的集合类(如HashMap),在对象不再需要时,忘记从集合类中移除。特别是抛异常情况下,要确保remove操作能执行
Runnable对象,必须交给Thread运行,否则永远不会消亡,必须执行start函数
流打开函数,使用完需要用对应的关闭函数,否则会造成泄露,比如FileInputStream
是否存在堆内存泄露的判断依据:
找到GC日志,分析Full GC行,参数分别表示:GC前的堆内存大小,GC后的堆内存大小,堆最大值,耗时。
稳定运行一段时间后,排除掉系统设计了大量缓存的场景,如果GC后的堆内存大小是逐步增加,一直到Xmx,判断是发生了堆内存泄露。
分析方法:
借助MemoryAnalysis工具