🐬 目录:
- 一、CNN概论
- 二、model分析
- LeNet5
- AlexNet
- VggNet
- GoogleNet
- ResNet
- 三、参考资料
一、CNN概论
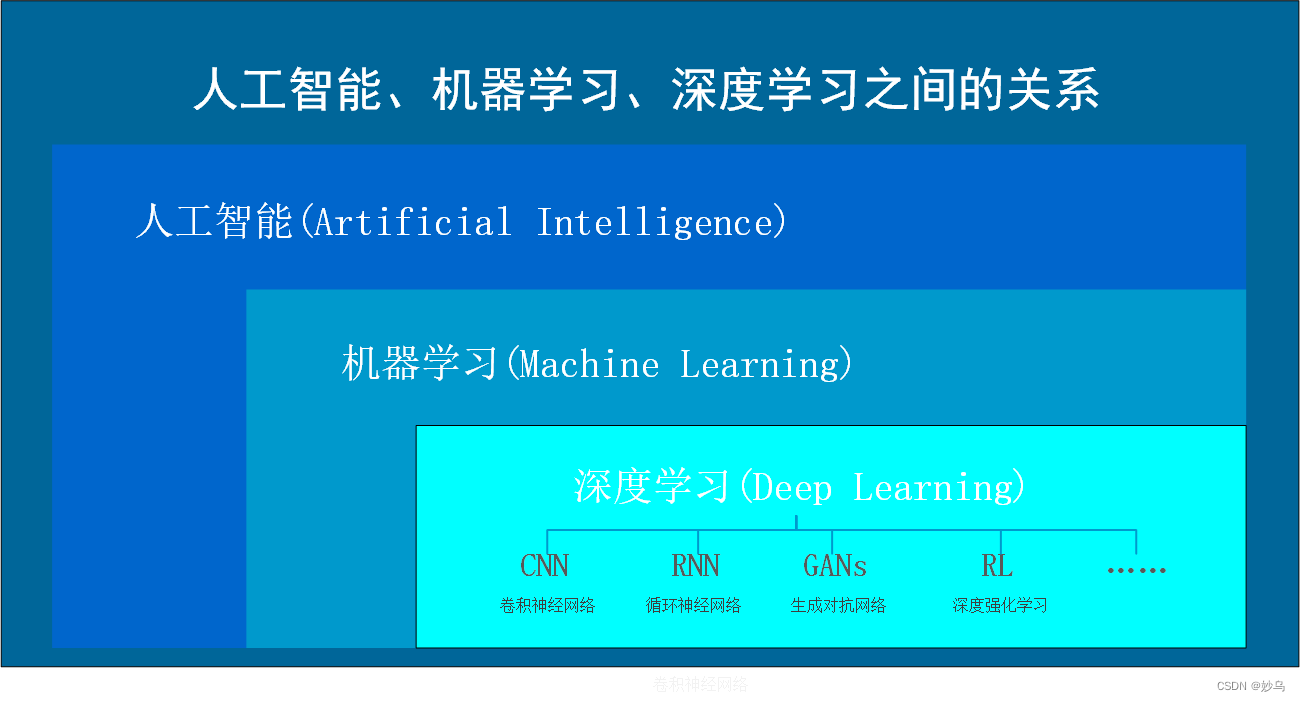
如图所示:人工智能最大,此概念也最先问世;然后是机器学习,出现的稍晚;最后才是深度学习。其中CNN,RNN,GANs,RL是深度学习中非常典型的算法,如下表所示:
| Algorithm | 简介 | 应用场景 |
|---|---|---|
| CNN | CNN擅长图片的处理 | 图片分类、目标定位监测、目标分割、人脸识别、骨骼识别 |
| RNN | RNN能有效处理序列数据 | 文本生成、语音识别、机器翻译、生成图像描述、视频标记 |
| GANs | 通过生成模型和判别模型“博弈”进行学习 | |
| RL | 通过强化高分策略进尝试学习 |
二、CNN的model分析
2.1 LeNet5
论文: 《Gradient-Based Learning Applied to Document Recognition》
🍀 简介:LeNet-5是一种经典的卷积神经网络结构,于1998年投入实际使用中。该网络最早应用于手写体字符识别应用中。
🍀 结构: LeNet5共包含7层,输入为32×32像素的图片,如下图所示:
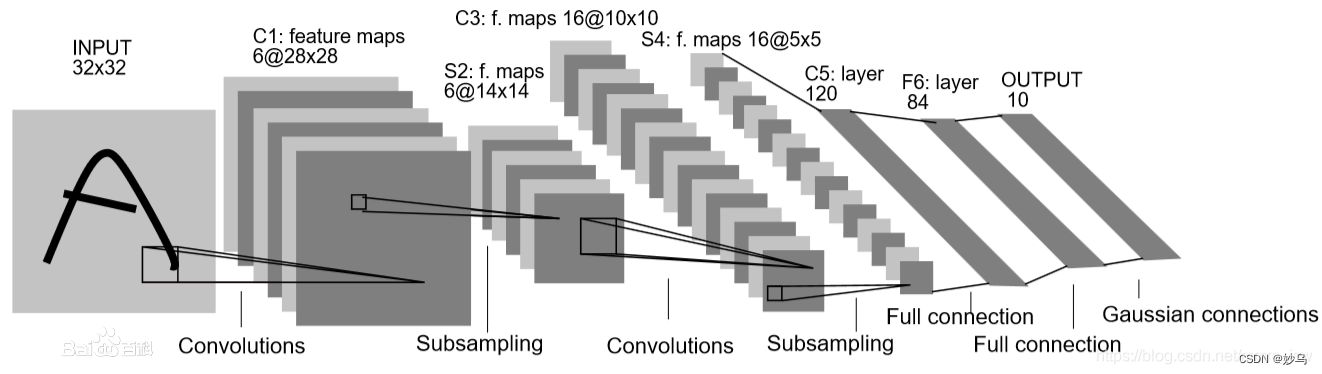
🍀 意义:普遍认为,卷积神经网络的出现开始于LeCun等提出的LeNet网络,可以说LeCun等是CNN的缔造者,而LeNet则是LeCun等创造的CNN经典之作。
2.2 AlexNet
论文: 《ImageNet Classification with Deep Convolutional Neural Networks》
🎄 简介:AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率从传统的70%提升到80%。它是由Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,深度学习开始迅速发展。
🎄 结构: AlexNet使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层
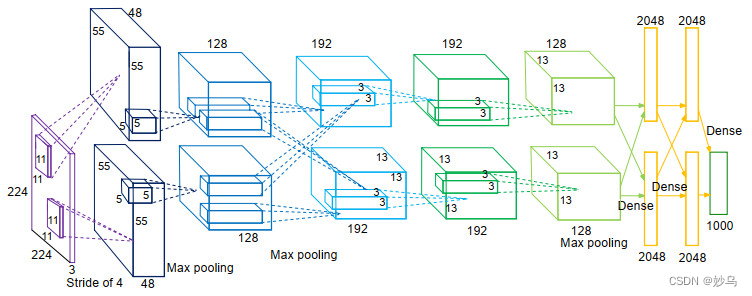
上图包含了GPU通信的部分。由于当时GPU内存的限制,作者使用两块GPU进行计算,因此分为了上下两部分。但是,以目前GPU的处理能力,单GPU足够了,因此其结构图可以如下所示。
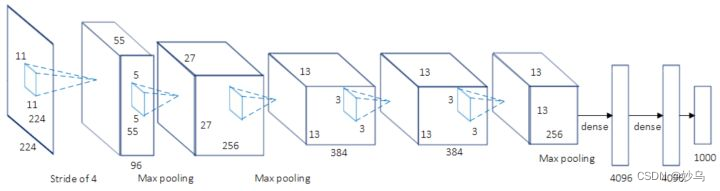
🎄 意义:
(1)首次利用GPU进行网络加速训练。
(2)使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数。
(3)使用LRN(Local Response Normalization)局部响应归一化。
(4)在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合。
2.3 VggNet
论文: 《Very deep convolutional networks for large-scale image recognition》
🌿 简介: VGG在2014年由牛津大学著名研究组VGG(Visual Geometry Group)提出,斩获改年ImageNet竞赛中Localization Task第一名和Classification Task第二名。
🌿 结构: VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooing分开,所有隐层的激活函数都采用ReLU函数。VGG的作者认为两个3 × 3的卷积堆叠获得的感受野大小,相当一个5 × 5的卷积;而三个3 * 3卷积的堆叠获取的感受野相当于7 * 7的卷积。
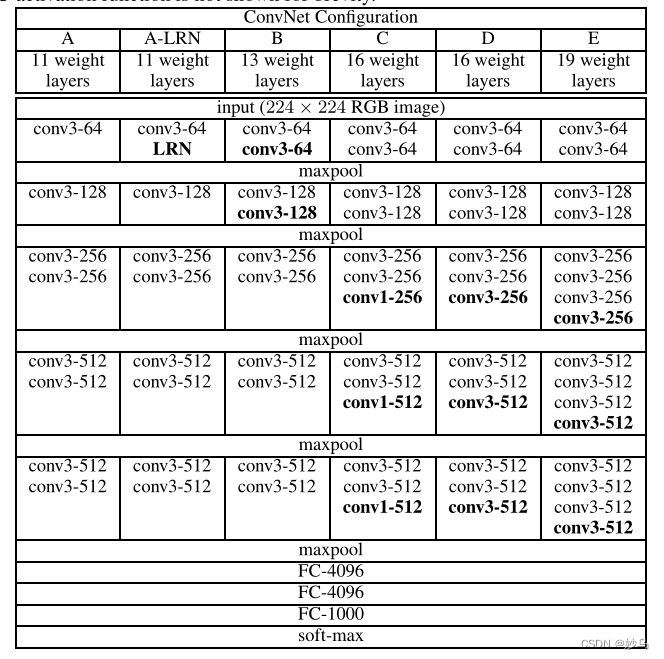
通常采用VGG - 16作为实验的主网络,其结构如下图所示:
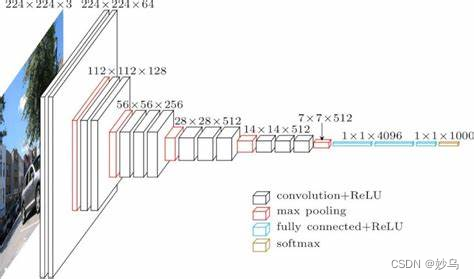
🌿 意义:
(1)通过堆叠多个3 × 3的卷积核替代大尺度卷积核(减少所需参数)
(2)证明了增加网络的深度能够在一定程度上影响网络的最终性能
2.4 GoogleNet
论文: 《Going deeper with convolutions》
🌵 简介: GoogleNet在2014年由Google团队提出,斩获当前ImageNet竞赛中Classification Task第一名。在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。与VGGNet模型相比较,GoogleNet模型的网络深度已经达到22层(如果只计算有参数的层,GoogleNet网络有22层,算上池化层有27层)。
,而且在网络架构中引入了Inception单元,从而进一步提升模型整体的性能。虽然深度达到22层,但大小却比AlexNet和VGG小很多。
🌵结构:
(一)Inception结构
(1)Inception module:naive version
Inception Module基本组成结构有四个成分:1 × 1卷积、3 × 3卷积、5 × 5卷积、3 × 3最大池化,最后对四个成分运算结果进行通道上组合,这就是Naive Inception的核心思想:利用不同大小的卷积核实现不同尺度的感知,最后进行融合,可以得到图像更好的表征。
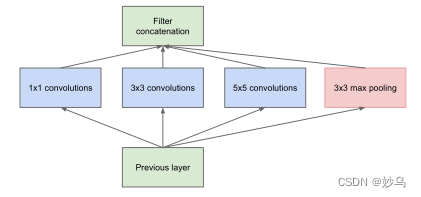
但是Naive Inception有两个非常严重的问题:
◆ 所有卷积层直接和前一层输入的数据对接,所以卷积层中的计算量会很大
◆ 在模块中使用的最大池化层保留了输入数据的特征图的深度,导致在最后进行合并的时候输出增加
(2) Inception module with dimension reductions
人们在Naive Inception基础上,为了减少参数量来减少计算量,开发了在GoogleNet模型中使用的Inception单元(Inception V1), 这种方法可以看作是一个额外的1 × 1卷积层再加上一个ReLU层。 如下所示:
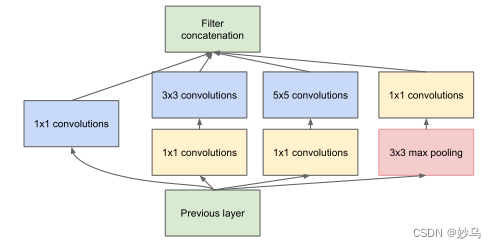
这里使用1 × 1的卷积主要目的是压缩降维,减少参数量,从而让网络更深、更宽,更好的提取特征,这种思想也称为Pointwise Conv,简称PW。本质上是减少卷积核的层数,然后与输入进行卷积操作,最后用 1 × 1 的卷积扩充到所需维度。论文中提及依赖的原理为:
judiciously reducing dimension wherever the compu-
tational requirements would increase too much otherwise.
This is based on the success of embeddings: even low di-
mensional embeddings might contain a lot of information
about a relatively large image patch.
(二)辅助分类器
根据实验数据,发现神经网络的中间层也具有很强的识别能力,为了利用中间层抽象的特征,在某中间层中添加含有多层的分类器。如下图所示:
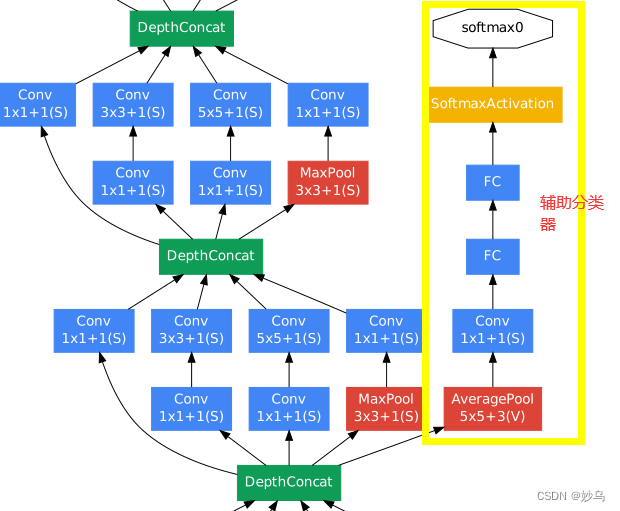
GoogleNet中共添加了两个辅助的softmax分支,作用有两点:
1.为了避免梯度消失,向前传导梯度
2.将中间某一层输出用作分类,起到模型融合作用
最后的损失函数为:
loss = loss_2 + 0.3 × loss_1 + 0.3 × loss_0
(三)GoogleNet模型
GoogleNet网络有22层深(包含pool层,有27层深),结构如下图所示:
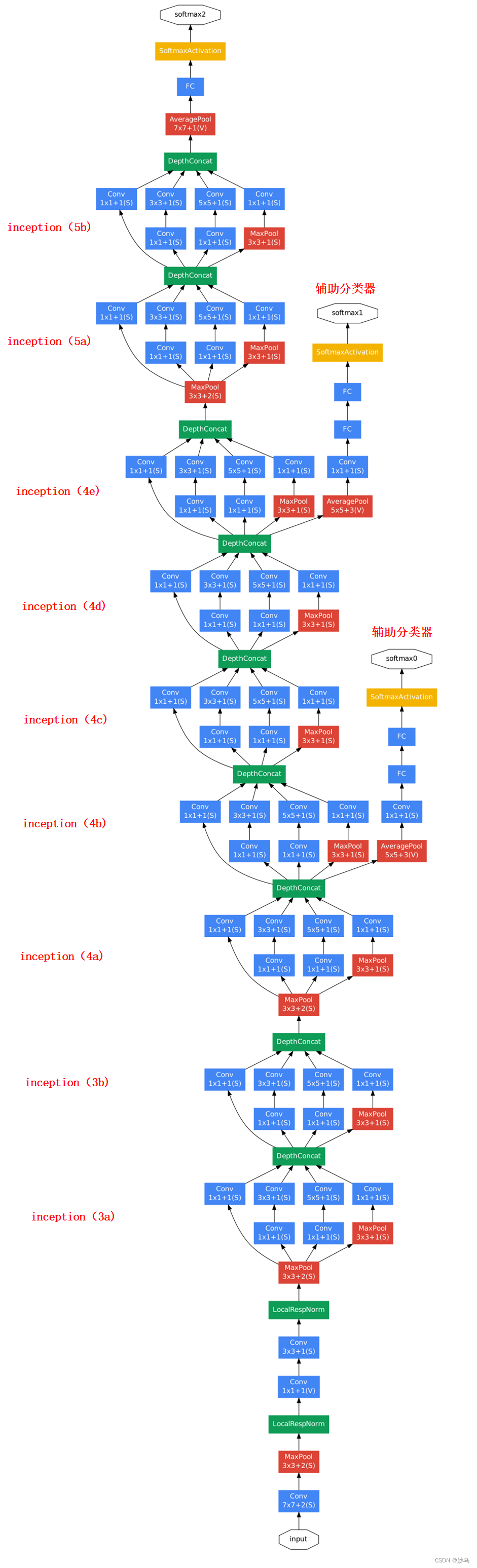
如上图所示,在分类器之前采用《Network in Network》中用AveragePool来代替全连接思想。
🌵意义:
(1)引用Inception结构(融合不同尺度的特征信息)
(2)使用1 × 1的卷积核进行降维以及映射处理
(3)添加两个辅助分类器帮助训练
(4)丢弃全连接层,使用平均池化层(大大减少模型参数)
2.5 ResNet
论文:《Deep Residual Learning for Image Recognition》
🌷 简介: 对浅层网络逐渐叠加layers,模型在训练集和测试集上的性能会变好,因为模型复杂度更高了,表达能力更强了。“退化”指的是,给网络叠加更多的layer后,性能却快速下降的情况,ResNet的提出旨在解决layer增加后,性能退化的问题。ResNet在2015年由微软实验室提出,斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名。获得COCO数据集中目标检测第一名,图像分割第一名。
🌷 结构:
如果将深层网络的后面若干层学习成恒等映射h(x) = x,那么模型就退化成浅层网络。但是直接去学习这个恒等映射是很困难的,那么就换一种方式,把网络设计成:
H(x) = F(x) + x
只要F(x) = 0就构成了一个恒等映射H(x) = x,这里F(x)为残差。
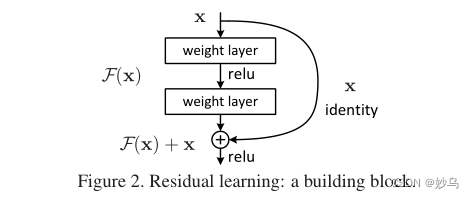
Resnet提供了两种方式来解决退化问题:identity mapping以及residual mapping。identity mapping指的是图中“弯线”的剩余部分。如果网络已经达到最优,继续加深网络,residual mapping将被push为0,只剩下identity mapping,这样理论上网络一直处于最优状态了,网络的性能也就不会随着深度增加而降低了。
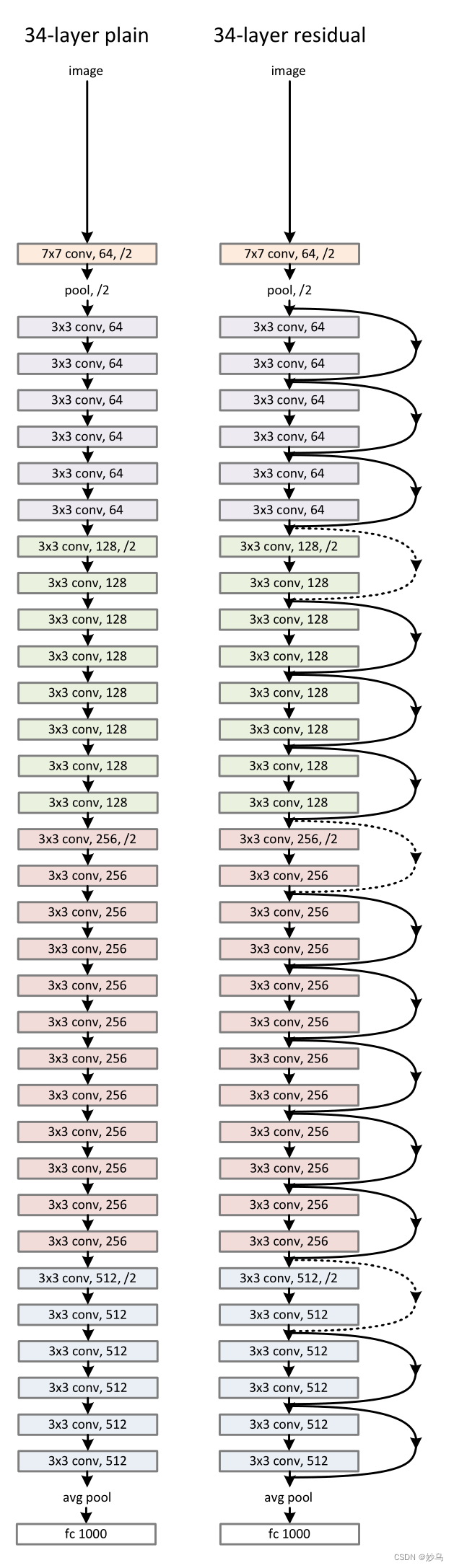
🌷 意义:
(1)提出了超深的网络结构(突破1000层)
(2)提出residual模块
(3)使用Batch Normalization加速训练(丢弃dropout)
三、参考资料
一篇文章看懂人工智能、机器学习和深度学习
你不得不了解的深度学习知识(一)