文章目录
- 使用Pandas连接数据库
- 编码环境
- 依赖包
- read_sql_query()的使用
- read_sql_table()的使用
- read_sql() 函数的使用
- to_sql()写入数据库的操作
- 删除操作
- 更新操作
- 总结:

使用Pandas连接数据库
通过pandas实现数据库的读,写操作时,首先需要进行数据库的连接,然后通过调用pandas所提供的数据库读写函数与方法来实现数据库的读写操作。
Pandas提供了3个函数用于数据库的读操作
- read_sql_query() 可以实现对数据库的查询操作,但是不能直接读取数据库中的某个表,需要在sql语句中指定查询命令与数据表的名称
- read_sql_table() 只能读取数据库某一个表的内的数据,并且该函数需要sqlalchemy 模块的支持才能使用
- read_sql()函数,既可以读取数据库中某一个表的数据,也可以进行执行具体的查询操作。
Pandas提供了1个函数用于数据库的写操作
- to_sql()该函数用户实现数据的写入操作,通过DataFrame对象直接调用,和将DataFrame对象保存为其他类型的文件类似。
编码环境
Jupyter Notebook
依赖包
- pymysql
- sqlalchemy 该模块 是在使用read_sql_table() 函数时必须要用的模块
安装包
pip install pymysql
pip install sqlalchemy
read_sql_query()的使用
参数
pd.read_sql_query(sql, # 需要执行查询的sql语句con, # 数据库的连接index_col=None, 字符串或字符串列表,可选,默认值:无coerce_float: 'bool' = True, 尝试将非字符串,非数字对象(如decimal.Decimal)的值转换为浮点值params=None,parse_dates=None,chunksize: 'int | None' = None,dtype: 'DtypeArg | None' = None,
)
pd.read_sql_query() 函数返回的数据类型时DataFrame
案例与使用
import pandas as pd
import pymysql # 导入操作mysql的数据包
import sqlalchemy # 使用pymysql进行连接数据库
db = pymysql.connect(host='127.0.0.1',user='root',passwd='123456',port=3306,charset='utf8',database='comment_v1')
# user 用户名
# password 密码
# host 端口号
# database 数据库名
# charset 编码格式# 编写sql语句
sql = 'select * from user_comment'
# 通过read_sql_query函数进行查询
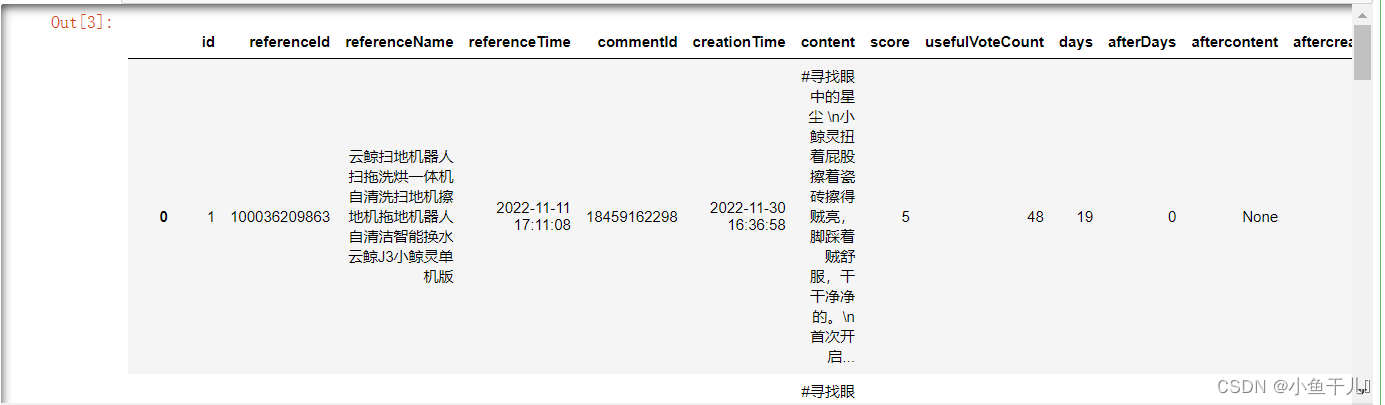
sql_query_data = pd.read_sql_query(sql=sql,con=db)
sql_query_data
read_sql_table()的使用
使用read_sql_table() 函数我们需要使用sqlalchemy 模块进行连接数据库,通过这个模块我们才可以对某一个表进行查询。
在使用其他的驱动程序的时候,会报NotImplementedError错误。
NotImplementedError: read_sql_table only supported for SQLAlchemy connectable.
参数
pd.read_sql_table(table_name: 'str', # 数据库名称con, # 数据库连接schema: 'str | None' = None,index_col: 'str | Sequence[str] | None' = None,coerce_float: 'bool' = True,parse_dates=None,columns=None,chunksize: 'int | None' = None,
)
read_sql_table() 函数返回DataFrame类型
案例与使用
# 使用sqlalchemy连接数据库,依次设置
sql_query_db = sqlalchemy.create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/comment_v1")
# mysql+pymysql://root:123456@127.0.0.1:3306/comment_v1"
# mysql 连接的数据库类型
# pymysql 连接数据库的驱动
# root 用户名
# 123456 密码
# 127.0.0.1 数据库地址
# 3306端口号
# comment_v1连接的数据库名称# 通过read_sql_table
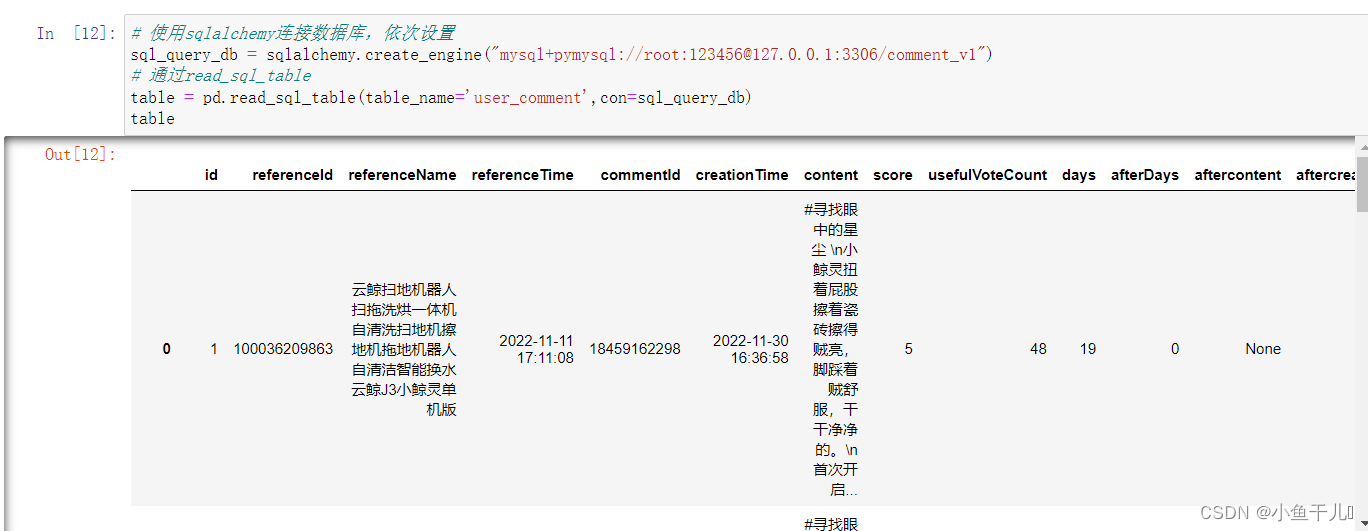
table = pd.read_sql_table(table_name='user_comment',con=sql_query_db)
table
read_sql() 函数的使用
read_sql()使用pymysql或者sqlalchemy对象都可以
参数
pd.read_sql(sql, # sql语句con, # 连接对象index_col: 'str | Sequence[str] | None' = None,coerce_float: 'bool' = True,params=None, parse_dates=None,columns=None,chunksize: 'int | None' = None,
)
案例与使用
# 通过read_sql函数读取数据库的信息
# 使用pymysql进行连接数据库
db = pymysql.connect(host='127.0.0.1',user='root',passwd='123456',port=3306,charset='utf8',database='comment_v1')
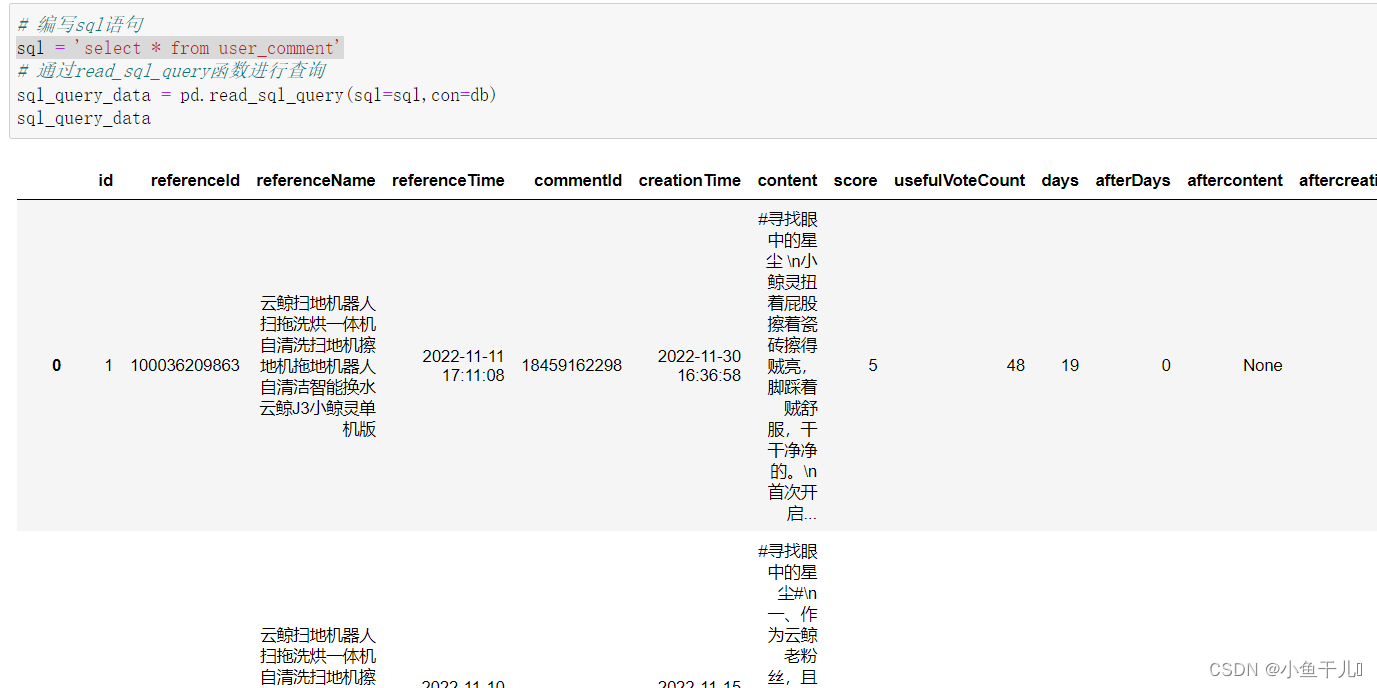
sql = 'select * from user_comment'
read_sql = pd.read_sql(sql=sql,con=db)
read_sql
# 通过read_sql函数读取数据库的信息
# 使用pymysql进行连接数据库
sql_query_db = sqlalchemy.create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/comment_v1")
sql = 'select * from user_comment'
read_sql = pd.read_sql(sql=sql,con=sql_query_db )
read_sql
to_sql()写入数据库的操作
to_sql方法同样需要使用SQLAlchemy模块的支持
参数
df.to_sql(name: 'str', # 表名称con, # 数据库连接schema=None, if_exists: 'str' = 'fail', # fail如果表已经存在就不执行写入,replace 如果表存在就删除原来的表,再进行写入,append代表在原有数据表中添加数据index: 'bool_t' = True, # 是否将行索引写入数据库中index_label=None,chunksize=None,dtype: 'DtypeArg | None' = None,method=None,
)
案例与使用
# 使用sqlalchemy模块进行连接
sql_query_db = sqlalchemy.create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/atguigudb")
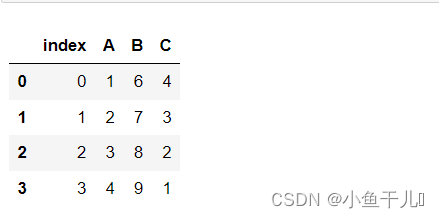
data = {"A":[1,2,3,4],"B":[6,7,8,9],"C":[4,3,2,1]
}
df = pd.DataFrame(data)
df.to_sql('to_sql_dome',con=sql_query_db,if_exists='append')
# 测试,查询
sql = "select * from to_sql_dome"
read_df = pd.read_sql(sql=sql,con=sql_query_db)
read_df
结果
如和删除和更新数据库中的数据,pandas官方并没有提供相应的函数,但是我们同样可以使用read_sql和read_sql_query来进行实现对数据的删除和修改(sql语句会执行,但是程序会报错),还可以通过原生python利用哦个pymysql中的execute()方法来执行对数据的删除和修改。
在实际生产过程中并不建议这样操作,因为在实际过程中数据对公司是非常重要的,作为一个数据分析师我们并不会拿到删除和更新操作的权限,数据分析也不会修改原数据,在进行分析和建模的所拿到的数据都是复制数据库的数据。
删除操作
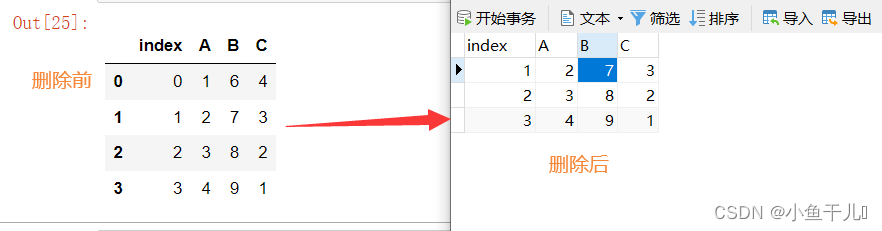
删除to_sql_dome 表中A = 1的一行数据
sql = "DELETE FROM to_sql_dome WHERE A = 1;"
read_df = pd.read_sql(sql=sql,con=sql_query_db)
执行上面的代码以后会报错 使用pymsql和sqlalchemy两种的报错不一样
sqlalchemy:ResourceClosedError: This result object does not return rows. It has been closed automatically.
pymsql:TypeError: 'NoneType' object is not iterable
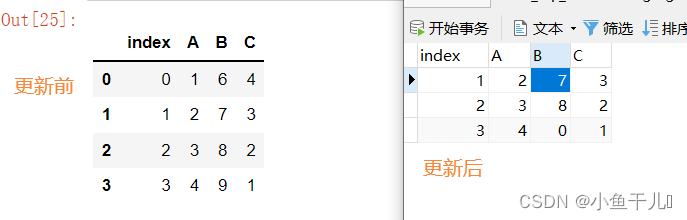
更新操作
sql = "update to_sql_dome set B=2 where A = 4"
read_df = pd.read_sql(sql=sql,con=db)
执行后同样也会报错,使用pymsql和sqlalchemy两种的报错不一样
sqlalchemy:ResourceClosedError: This result object does not return rows. It has been closed automatically.
pymsql:TypeError: 'NoneType' object is not iterable
```rceClosedError: This result object does not return rows. It has been closed automatically.
最后在强调一下,pandas并不推荐使用read_sql和read_sql_query来进行实现对数据的删除和更新,如果想对数据进行操作,可以使用原生的python利用pymysql进行操作。
总结:
通过上面的四个方法我们发现Pandas操作数据库还是很方便的:
- read_sql()和read_sql_query()都是通过执行sql来进行查询的操作,在查询数据时更重要的是对sql语句的掌握。
- read_sql_table() 是通过指定表名进行查询整个表的数据
- to_sql()写入数据库,可以根据if_exists三个参数的不同来控制保存的数据表是删除重新保存还是追加或者是不进行操作。

![[测试]性能测试](/images/no-images.jpg)