比赛官网地址

赛题介绍
petfinder是马来西亚领先的动物福利平台宠物网站地址
- 该网站使用可爱指数来排名宠物照片。它分析了图片组成和其他因素,并与数千个宠物档案的表现进行了比较。
在这场比赛中,你将分析原始图像和元数据来预测宠物照片的“Pawpularity”。你将在PetFinder数据上训练和测试你的模型。
数据集介绍
在这场比赛中,你的任务是根据宠物的个人资料的照片预测该宠物的受欢迎程度。您还为每张照片提供了手工标记的元数据。因此,本次比赛的数据集包括图像和表格数据

- 训练数据
train/ -包含训练集照片的文件夹,格式为{id}.jpg,其中{id}是唯一的宠物档案id。
train.csv -训练集中每张照片的元数据以及目标(label),即照片的Pawpularity得分。Id列给出了照片的唯一Pet Profile Id,对应于照片的文件名。 - 测试数据
test/ -
包含随机生成的图像的文件夹,其格式类似于训练集照片。实际测试数据包括约6800张与训练集照片相似的宠物照片。
test.csv -随机生成的元数据,类似于训练集元数据。
sample_submission.csv -正确格式的示例提交文件。
图像的信息的csv数据
train.csv和test.csv文件分别包含训练集和测试集中照片的元数据。每张宠物照片都为以下每个特征标记了1(是)或0(否)的值:
train.csv. or test.csv
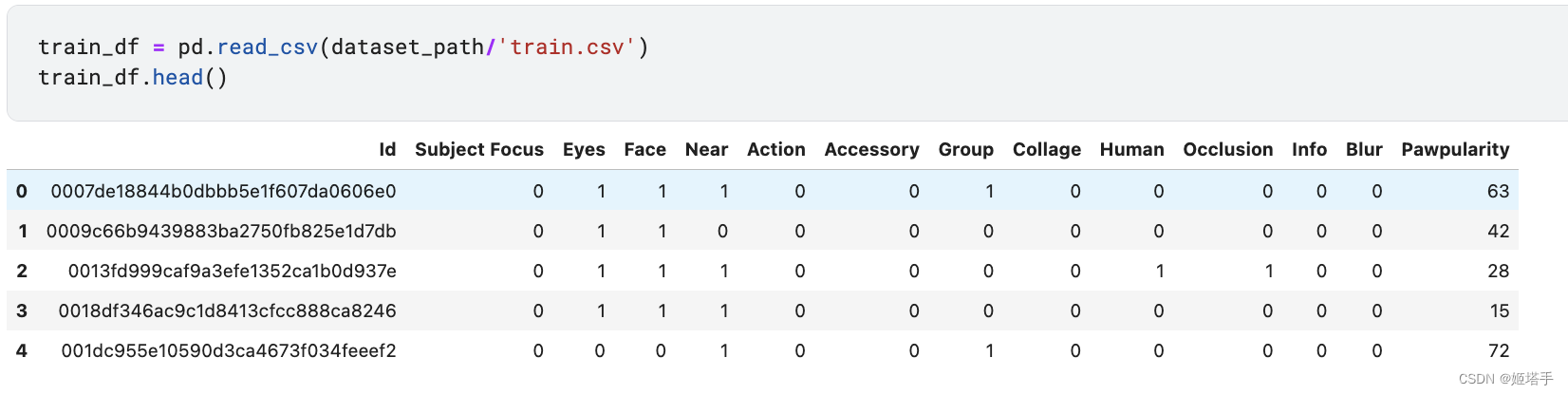
- id 每个宠物对应的图片ID
- Subject Focus 宠物在整洁的背景中脱颖而出,不会太近/太远。
- Eyes 双眼朝向前方或近前方,至少有一只眼睛/瞳孔清晰。
- Face 相当清晰的脸,面向前方或近前方。
- Near 单个宠物占据了照片的很大一部分(大约超过照片宽度或高度的50%)。
- Action 宠物在动作中(例如,跳跃)。
- Accessory 伴随的实物或数字配件/道具(即玩具、数字贴纸),不包括项圈和皮带。
- Group 照片中有多于1只宠物。
- Collage 数码修饰的照片(即与数码相框,多张照片的组合)。
- Human 照片中的人类。
Occlusion 特定的不受欢迎的物体挡住了宠物的一部分(即人,笼子或栅栏)。注意,并不是所有的阻塞对象都被认为是闭塞的。 - Info-自定义添加的文本或标签(即宠物名,描述)。
- Blur-明显的失焦或嘈杂,特别是宠物的眼睛和脸。对于Blur条目,“Eyes”列总是设置为0。
- Pawpularity. 比赛的teaget 宠物的受欢迎程度
数据分析
import sys
sys.path.append('../input/timm-pytorch-image-models/pytorch-image-models-master')
from timm import create_model
from fastai.vision.all import *
set_seed(999, reproducible=True)
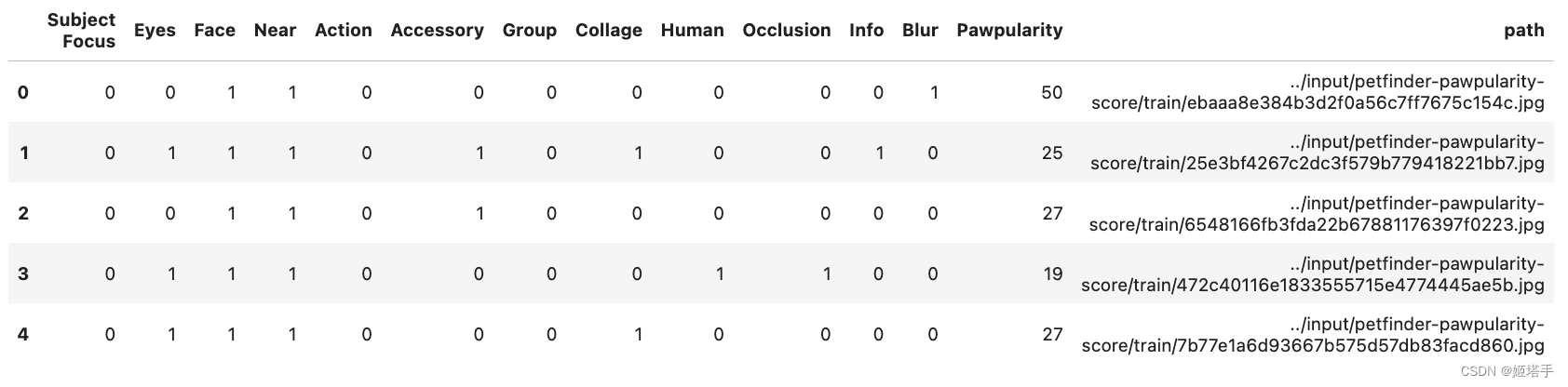
生成图像的路径
train_df['path'] = train_df['Id'].map(lambda x:str(dataset_path/'train'/x)+'.jpg')
train_df = train_df.drop(columns=['Id'])
train_df = train_df.sample(frac=1).reset_index(drop=True) #shuffle dataframe
train_df.head()
- 查看训练集的图像数量
len_df = len(train_df)
print(f"There are {len_df} images")
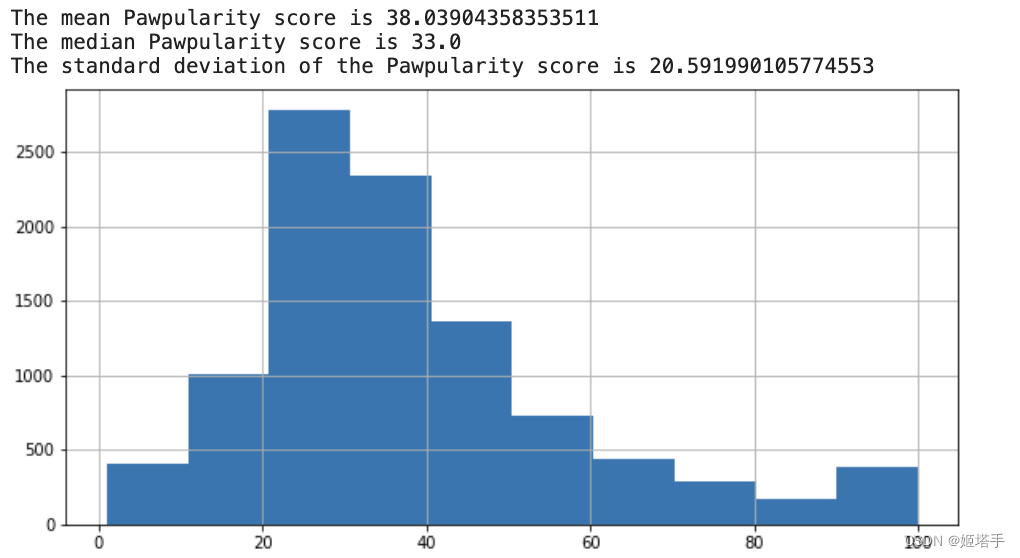
- 统计标签的分布情况
train_df['Pawpularity'].hist(figsize = (10, 5))
print(f"The mean Pawpularity score is {train_df['Pawpularity'].mean()}")
print(f"The median Pawpularity score is {train_df['Pawpularity'].median()}")
print(f"The standard deviation of the Pawpularity score is {train_df['Pawpularity'].std()}")
- 统计标签的数量
print(f"There are {len(train_df['Pawpularity'].unique())} unique values of Pawpularity score")

标签总共有100个,于是后面模型训练的时候可以考虑归一化,然后转换为回归问题
- 标签归一化
train_df['norm_score'] = train_df['Pawpularity']/100
train_df['norm_score']
- 查看图片大小
im = Image.open(train_df['path'][1])
width, height = im.size
print(width,height)##960,960- 修狗图片
im