点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转自 | AI科技评论

OpenAI在1月5日公布DALL-E模型以来,人们都惊艳于模型的语言想象力是如此丰富和细致。如今,我们终于等到了论文的公布,从而得以了解DALL-E天马行空创造力背后的奥秘。值得一提的是,OpenAI还开源了DALL-E的代码,然而,只包含了其中的一个非核心模块。
以下是DALL·E的几个演示案例。
文本提示:穿着芭蕾舞短裙的萝卜宝宝在遛狗。
AI生成的图像:

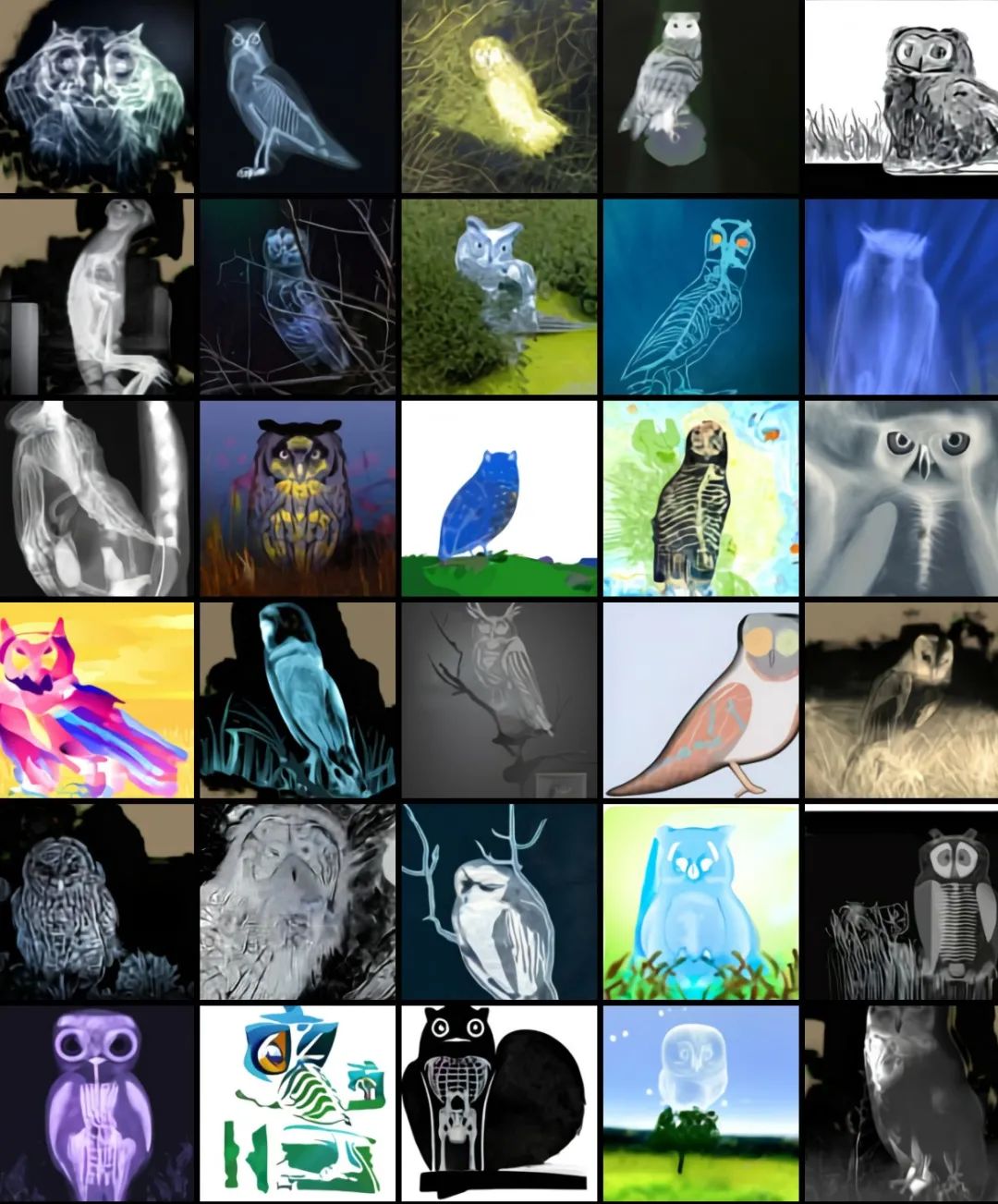
文本提示:一只X射线的猫头鹰:
AI生成的图像:
文本提示:孔雀橡皮
AI生成的图像:

文本+图像提示:参照上面的猫在下面生成草图
AI生成的图像:

更多示例请查看:
OpenAI祭出120亿参数魔法模型!从文本合成图像栩栩如生,仿佛拥有人类的语言想象力
以下是论文核心内容编译,具体细节还请参看原论文。

论文链接:https://arxiv.org/pdf/2102.12092.pdf
Blog:https://openai.com/blog/dall-e/
GitHub(VAE in DALL-E):https://github.com/openai/DALL-E
摘要
按照传统,文本到图像的生成一直专注于寻找更好的建模假设,以便能够在固定数据集上进行训练。这些假设可能涉及到复杂的架构、辅助损失或边信息(side information),比如训练过程中提供的物体部分标签或分割掩码。
我们基于transformer 描述了用于此任务的一种简单方法,该transformer 能够将文本和图像token自动回归建模为单个数据流。有了足够的数据和规模后,在零样本情况下进行评估时,我们的方法就可以与先前的特定领域建模(DSM)一争高下。
01. 引言
从文本到图像的现代机器学习合成方法始于Mansimov等人在2015年的研究工作,他们将Gregor 等人提出的用于生成图像标题的生成模型 DRAW 进行扩展,进一步生成新颖的视觉场景。2016年,Reed 等人证明,使用生成对抗网络(而不是使用递归可变自动编码器)可以提高图像逼真度。在同年的另一篇工作中,Reed 等人又证明,该系统不仅可以生成具有可识别属性的对象,还可以零样本泛化至留出(held-out)类别。
在接下来的几年里,研究人员又提出多种方法,推动了文本到图像生成领域的进展。比如,通过修改多尺度生成器来改进生成模型的架构;整合注意力和辅助损失;利用文本以外的其他条件信息资源。
在2017年,Nguyen等人提出了一种基于能量的条件图像生成框架。相对于现代方法,该框架在样本质量上取得了重大进步。他们的方法可以兼并预训练判别模型,并且证明,将其应用于在MS-COCO上预先训练的字幕模型时,模型能够执行文本到图像的生成。2020年,Cho等人还提出了一种方法,可以优化预训练跨模态掩码语言模型的输入。Manshimov等人在2015年的工作大幅提升了视觉逼真度,但样本仍然面临影响失真的“灾难”,例如物体变形、不合理的物体放置,或前景和背景元素的不自然混合。
由大规模生成模型驱动的最新进展表明了进一步改进上述问题的可能途径。具体来说,当计算、模型大小和数据进行仔细缩放时,自回归transformer(autoregressive transformer)在文本、图像和音频上能取得非常不错的效果。
相比之下,文本到图像的生成通常是在较小的数据集(例如MS-COCO和CUB-200)上进行评估。数据集大小和模型大小是否有可能成为限制当前方法发展的因素呢?在这项工作中,我们证明了,在从互联网上收集的2.5亿个图像文本对上训练一个包含120亿个参数的自回归transformer,能够得到一个可通过自然语言控制的灵活且逼真度高的图像生成模型。
同时,随之形成的系统无需使用任何训练标签,就可以在流行的 MS-COCO 数据集零样本泛化实现高质量的图像生成。它比先前由人类评估员在数据集上进行训练的工作节省了90%的工作时间。此外,它还能够执行复杂的任务,比如在基本级别上进行图像到图像的翻译。
02. 方法
我们的目标是训练一个transformer进行自动建模,即将文本以及图片的tokens转换为单一的数据流。然而,将像素直接作为图片token会占用大量的内存进行存储高分辨率图片。另外,似然目标(Likelihood objectives)倾向于对像素之间的近距离相关性进行建模,因此大部分内存会被用来捕捉高频细节上,忽略了能够在视觉上识别对象的低频结构。
基于以上问题,我们借用Oord和Razavi在2017和2019年的工作:两阶段训练法,进行尝试解决。
阶段1:训练一个离散变分自动编码器(DVAE),将每个256×256 RGB图像压缩成一个32×32的图像token网络,每个网格的每个元素可以取8192个可能的值。这一阶段会让transformer的上下文尺寸(context size)减少192倍,同时还不会大幅降低“视觉”质量。
阶段2:将256个BPE编码的文本token与32×32=1024 图片tokens连接起来,然后训练一个自回归 transformer对文本和图像的联合分布进行建模。

原始图像(上图)和离散VAE重建图像(下图)的比较
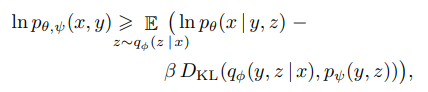
建模公式如上图所示,整体可以看成联合分布的似然函数,x代表图像,y代表图像的标题,z代表token,使用因式分解p_θψ(x,y,z)=p_θ(x|y,z)pψ(y,z)对该分布进行建模,得到下界。其中:
q_φ表示在给定RGB图像x2的情况下,由DVAE编码器生成的32×32图像token上的分布
p_θ表示由DVAE解码器在给定图像token的情况下生成的RGB图像上的分布
p_ψ表示文本和图像token在transformer建模中得到的联合分布。
值得一提的是,这个界(bound)只在β=1时成立,实际上,使用更大的β值非常有好处。
阶段1:学习视觉编码
在阶段1的训练中,针对φ和θ最大化ELB(evidence lower bound),这相当于在图像上训练DVAE。一开始将p_ψ设置为K=8192个向量上的均匀分类分布,q_φ为编码器输出的32×32网格中同一空间位置上的8192个 logits参数化的分类分布。
但ELB难以优化:因为q_ψ是一个离散分布,不能使用重参数化技巧进行最大化。有人使用在线聚类分配程序加上直通估计器来解决这个问题。我们还使用Gumbel-Softmax技巧转换q_φ。此外,条件放松的ELB使用Adam与指数加权迭代平均法进行最大化。其中,在编码器的末端和解码器的开始使用1×1卷积;将编码器和解码器重分块的输出激活乘以一个小常量等是非常重要的技巧和参数。
阶段2:学习先验
在第二阶段,修正了φ和θ,并通过最大化关于ψ的ELB来学习文本和图像token的先验分布,其中p_ψ由含有120亿个参数的稀疏transformer进行表示。
给定一个文本-图像对,最多使用256个词汇大小(vocabulary size)为16384的tokens对小写标题进行BPE编码,并使用32×32=1024个词汇大小为8192的tokens对图像进行编码。图像 token是通过使用 argmax 采样从 DVAE 编码器获得的,没有添加任何 gumbel 噪声。最后,文本和图像token进行连接,并作为一个单一的数据流进行自回归建模。
我们通过一堆数据中各个种类的总数,对文本-图像 token 的交叉熵损失进行了归一化。因为我们主要对图像建模感兴趣,因此我们将文本的交叉熵损失乘以1/8,将图像的交叉熵损失乘以7/8。目标则通过使用Adam算法,以指数加权的迭代平均法进行了优化。我们大概用了 606,000 张图像用于验证,但在收敛时没有发现过度拟合现象。
数据收集
我们在一个包含330万个文本-图像对的数据集 Conceptual Captions 上对模型进行了高达12亿参数的初步实验。
为了扩展到120亿个参数,我们从互联网上收集了2.5亿个文本-图像对,创建了一个与JFT-300M规模相当的数据集。该数据集不包括 MS-COCO,但包含了 Conceptual Captions 数据集和 YFCC100M 的一个过滤子集。由于MS-COCO是基于 YFCC100M 创建的,我们的训练数据还包含了一部分 MS-COCO 验证图像(但没有caption部分)。
混合精度训练
为了节省GPU内存并提高吞吐量,大多数参数、Adam 矩和激活都以16位精度存储。我们还使用激活checkpointing ,并在向后传递期间重新计算resblock中的激活。我们还使模型以16位精度对10亿个参数进行无差异训练,这是该项目最具挑战性的部分。
分布式优化
当以16位精度存储时,我们的120亿参数模型需要消耗约24 GB的显存,这超过了NVIDIA V100 16 GB的显存。我们使用参数分片(parameter sharding)来解决这个问题。
如图5所示,参数分片允许我们通过将其与计算密集型操作重叠,从而几乎可以完全忽略机器内通信的延迟。
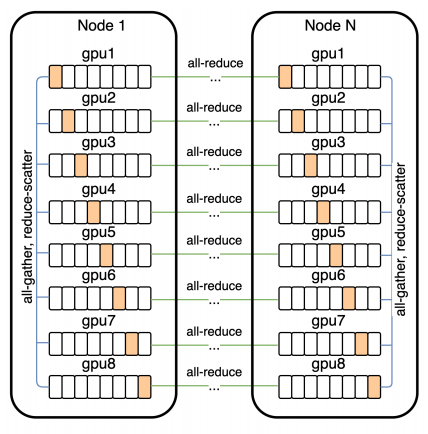
用于分布式训练的通信模式
样本生成
我们使用预训练的对比模型(Radford et al., 2021)对从transformer提取的样本进行重新排序。给定字幕和候选图像后,对比模型会根据图像与字幕的匹配程度来分配分数。图6显示了增加样本数量N的效果,我们从中选择了前k个图像。这个过程可以看作是一种语言指导的搜索(Andreas et al., 2017),也类似于辅助文本-图像匹配损失(Xu et al.,2018)。
除非另有说明,否则所有用于定性和定量结果的样品都无需降温即可获得(即t = 1),并使用N = 512进行重新排序。

增加图像数量对MS-COCO字幕对比重排序程序的影响
03. 结论
我们研究了一种简单的基于 autoregressive transformer 的文本-图像生成方法。我们发现,无论是在相对于以前特定领域方法的零样本性能方面,还是在单个生成模型的能力范围方面,规模都可以导致泛化性能的提升(所以这是官方承认大力出奇迹吗 )。
)。

点个在看 paper不断!