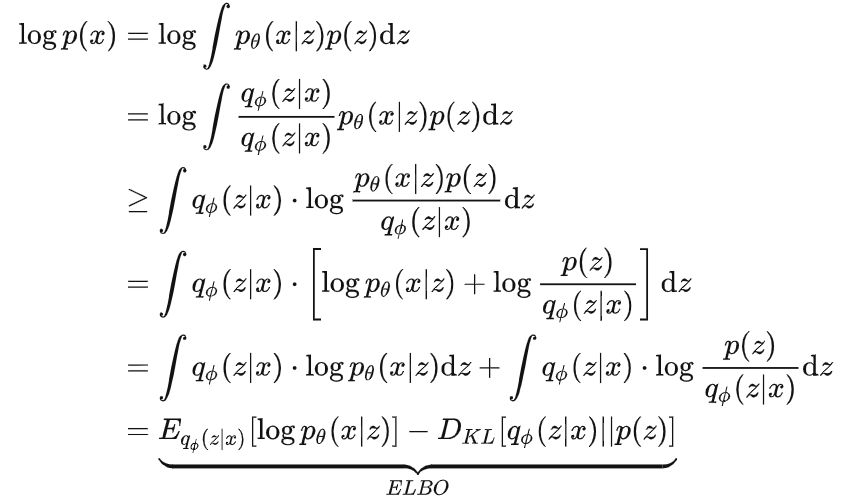Dall-e:从拟物文字到图片的创造
人类不断地从五种感官接收和整合信息,通过视觉、听觉、触觉、嗅觉和味觉等生物信息来理解文字和图片。然而文字和图片属于符号,Dall-e模型在理解符号的含义时并不能通过生物信息的传递。通过将对自然语言的理解与生成相应视觉表现的能力结合起来——换句话说,通过“读”和“看”的能力——DALL-E有力地展示了多模态AI的潜力。
DALL-E生成的图像未曾存在于世界上或任何人的想象中。它们不是对互联网上现有图像进行操作的结果——它们是新颖的效果图,有时因其聪明和独创性而令人惊叹。这些图像是DALL-E的人类创造者在很多情况下没有预料到的,也不可能预料到的。
功能一,创造拟人的器具
它不仅能够准确执行,而且能进行创造,举个例子(其结果的默认排序是越靠前越接近文本描述):

功能二,Dall-E能够很聪明地捕捉到每个事物的特性,并且合理地组织在了一起。
比如,“一个用长得像奇美拉的乌龟做的长颈鹿”

功能三,根据文本自动渲染真实场景图片,其仿真程度与真实照片十分接近。
举例,“一个写着open ai的广告牌”

功能四,根据文本指令改变和转换现有图片风格。
比如,“把这张照片里的猫转换成手绘草图”

不同于GAN(生成式对抗网络)的一点是,虽然GAN能够替换视频里的人脸,但其仅仅限制于人脸的范畴,而Dalle是将概念和概念之间做了关联,这在以往也是从未被实现过的。
应用前景设想
以服装设计为例,达利具备了细节属性操控能力,这一点是GAN(生成式对抗网络)所缺乏的能力,在模特图生成上,具备完全自动化属性。

再看室内设计,一个带有拱门和意大利元素且带壁炉的客厅,这样的要求描述不仅符合甲方的思路,而且在满足要求前提下,给出了非常多的合理布局设计。假如室内设计师已经穷尽了创意,用达利来寻找灵感也未尝不可。

对于不同物体之间的合理结合,在启发式设计上Dall-e也可以大开脑洞,将不同物体合理结合,帮助创意突破一般认知。
DALL-E的意义
DALL·E不是一个架空的作品,Openai在去年发布了GPT-3和Image GPT两个模型,各自分别能完成多种类的文本任务以及补全图像中的空缺部分。
DALL·E的模型在技术上来讲和GPT-3应该是大同小异的,同样采用了Transformer模型。它预示着一种被称为“多模态AI”的新型AI范式的到来,这种范式似乎注定了人工智能的未来。多模态AI系统能够在多种信息模态之间进行解释、综合和翻译——在DALL-E的例子中,是语言和图像。毫无疑问,DALL-E虽然并不是第一个多模态AI的例子,但它是迄今为止最有创造能力的。
面对无限的可能,我们只需充满期待。
本期内容来自品览上期「AI论技」直播。
【AI论技】系列直播是品览致力于为AI行业从业者打造的免费线上分享课,目前已经成功进行了6期,内容涵盖了目标检测模型、文本检测模型、3D视觉、目标跟踪、AI图像修复等业界经典模型教学,欢迎前往官网扫码加入品览AI交流群,免费看「AI论技」系列直播。
读完 DALL-E 论文,我们发现大型数据集也有平替版_HyperAI超神经的博客-CSDN博客
OpenAI的DALL·E迎来升级,不止文本生成图像,还可二次创作