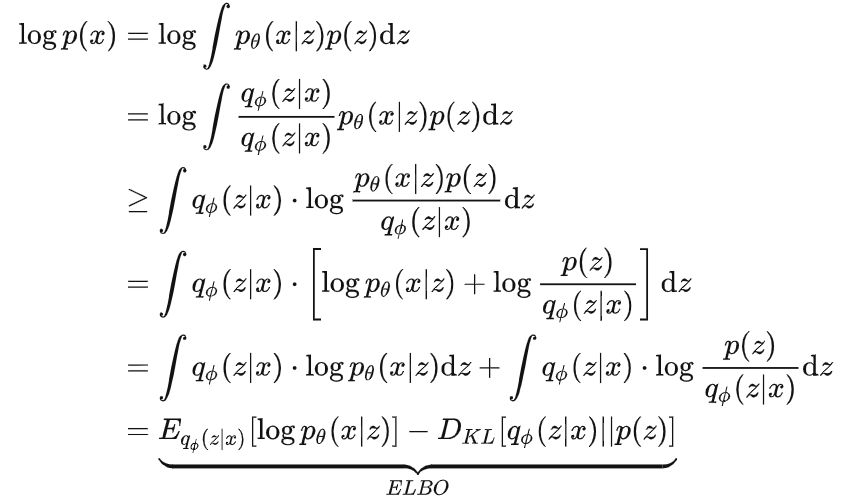💡 作者:韩信子@ShowMeAI
📘 深度学习实战系列:https://www.showmeai.tech/tutorials/42
📘 自然语言处理实战系列:https://www.showmeai.tech/tutorials/45
📘 计算机视觉实战系列:https://www.showmeai.tech/tutorials/46
📘 本文地址:https://www.showmeai.tech/article-detail/392
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏ShowMeAI查看更多精彩内容

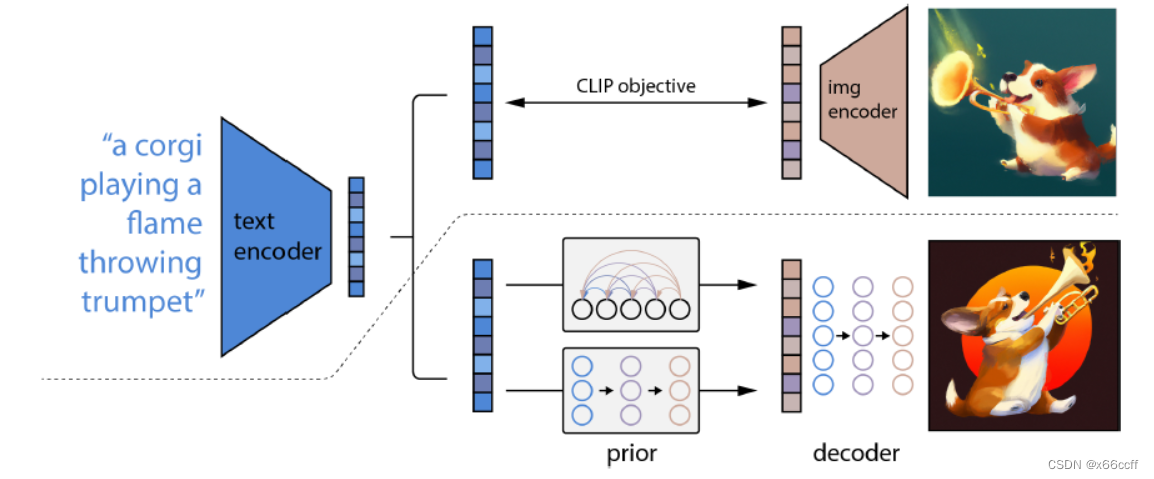
随着 Diffusion Model 的普及,大家可能注意到互联网上有着铺天盖地的人工智能 (AI) 生成的图像,这些图像都是使用『文本到图像』的生成模型生成的:只需要输入一个文本描述(prompt/提示),AI 模型就可以在几秒几分钟内生成一个或多个精准匹配提示的精美图像。
ShowMeAI在前序的文章中也做了一些相关的介绍:

📘 你给文字描述,AI艺术作画,精美无比!附源码,快来试试!

📘 使用Hugging Face发布的diffuser模型快速绘画
截止目前为止,三个最流行的AI作画产品是 📘Stable Diffusion、📘Midjourney和 📘DALL·E 2。
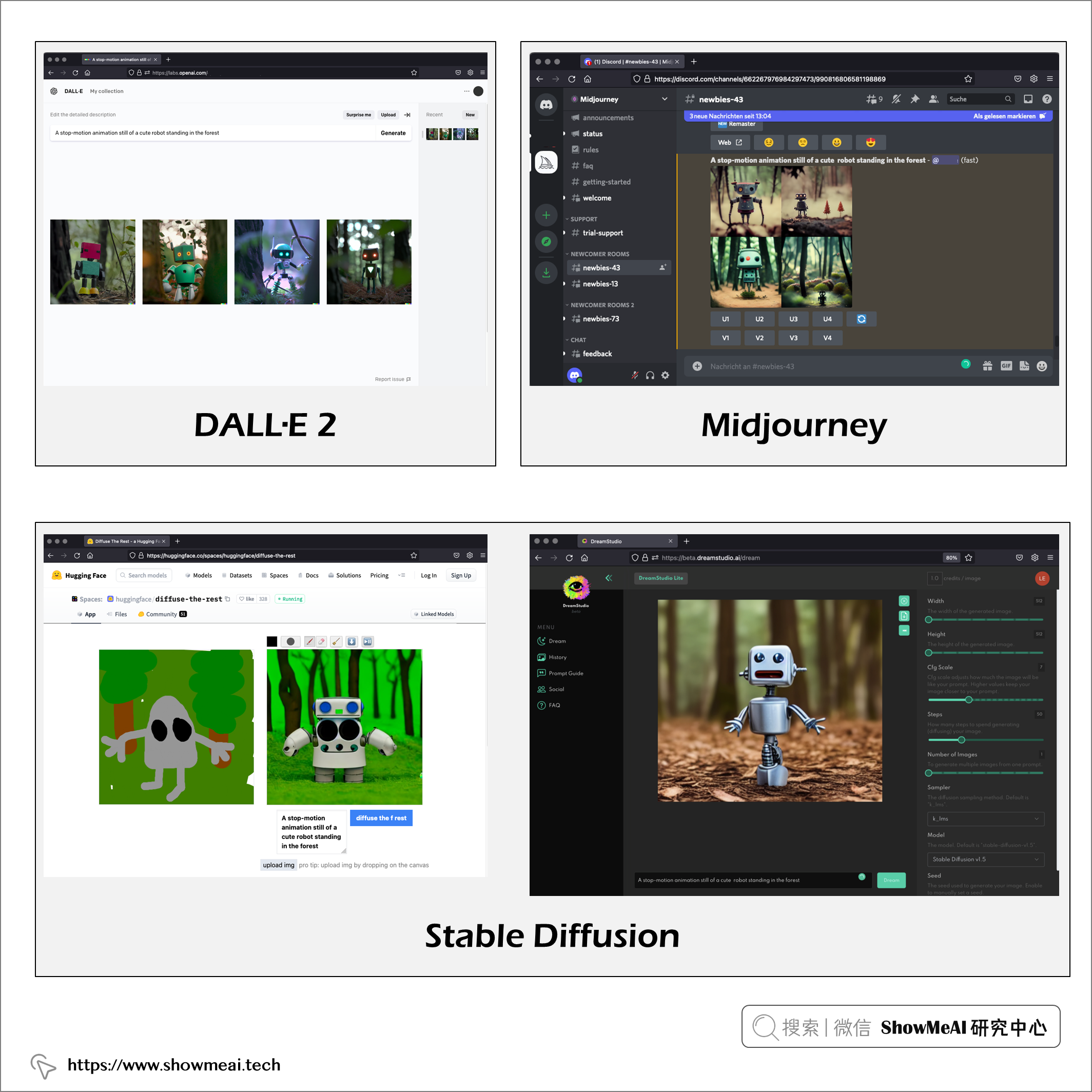
在本文中,ShowMeAI将对这3种模型进行比较,我们不会介绍这些 AI 模型后面的复杂数学原理,而聚焦在使用方法和效果对比。
💡 DALL·E2
📘DALL·E2由 📘OpenAI开发,目前产品版本处于 beta 阶段。
💦 如何使用
① 文本提示作图
在 DALL·E2 中,可以使用 『文本到图像』和『文本引导的图像到图像』生成算法生成图像。 使用『文本引导的图像到图像』生成算法,您可以上传图像,AI会以你上传的图像为初始图,根据提示来作图。
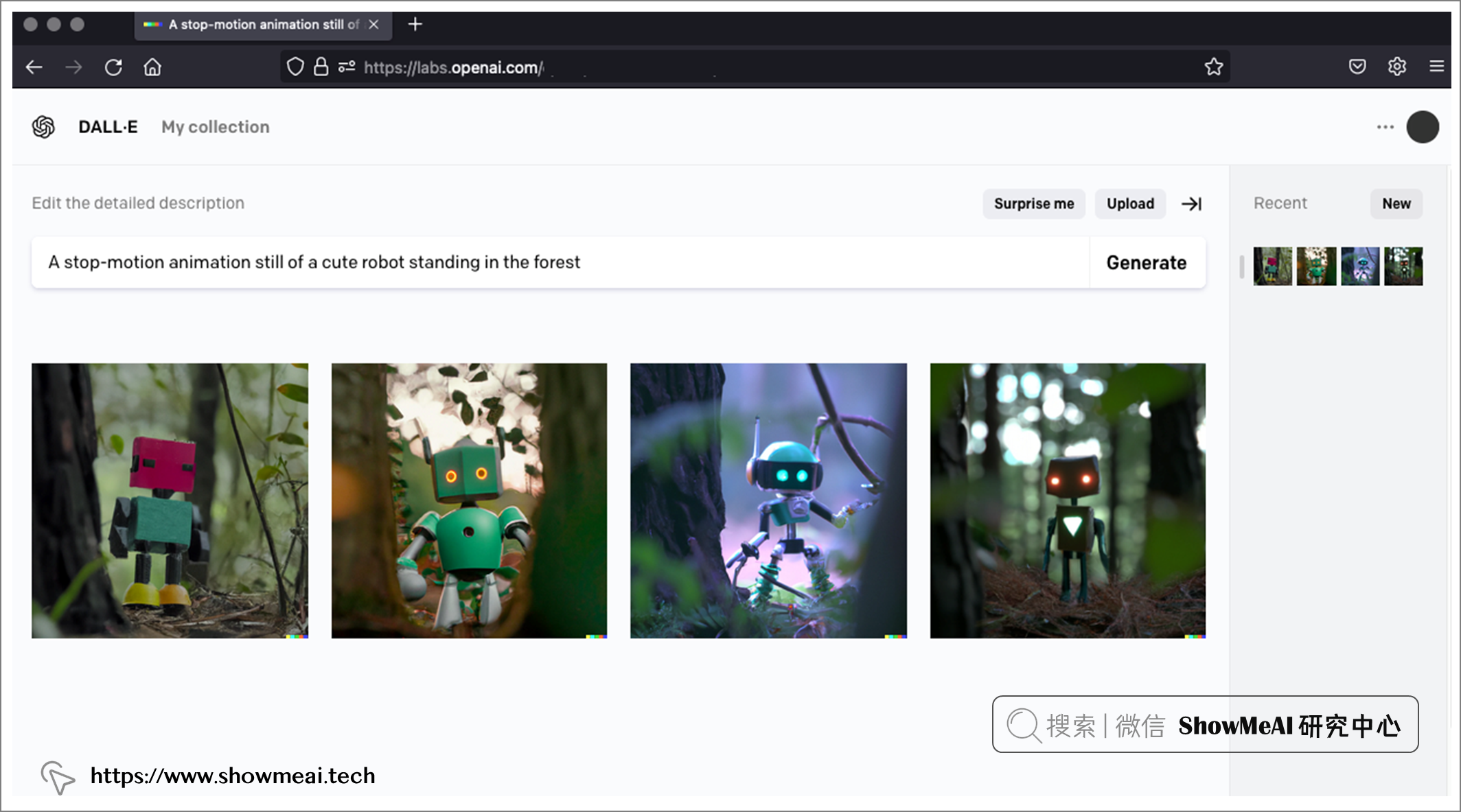
上图 DALL·E 作画提示词:A stop-motion animation still of a cute robot standing in the forest (一个可爱的机器人站在森林里的定格动画)。
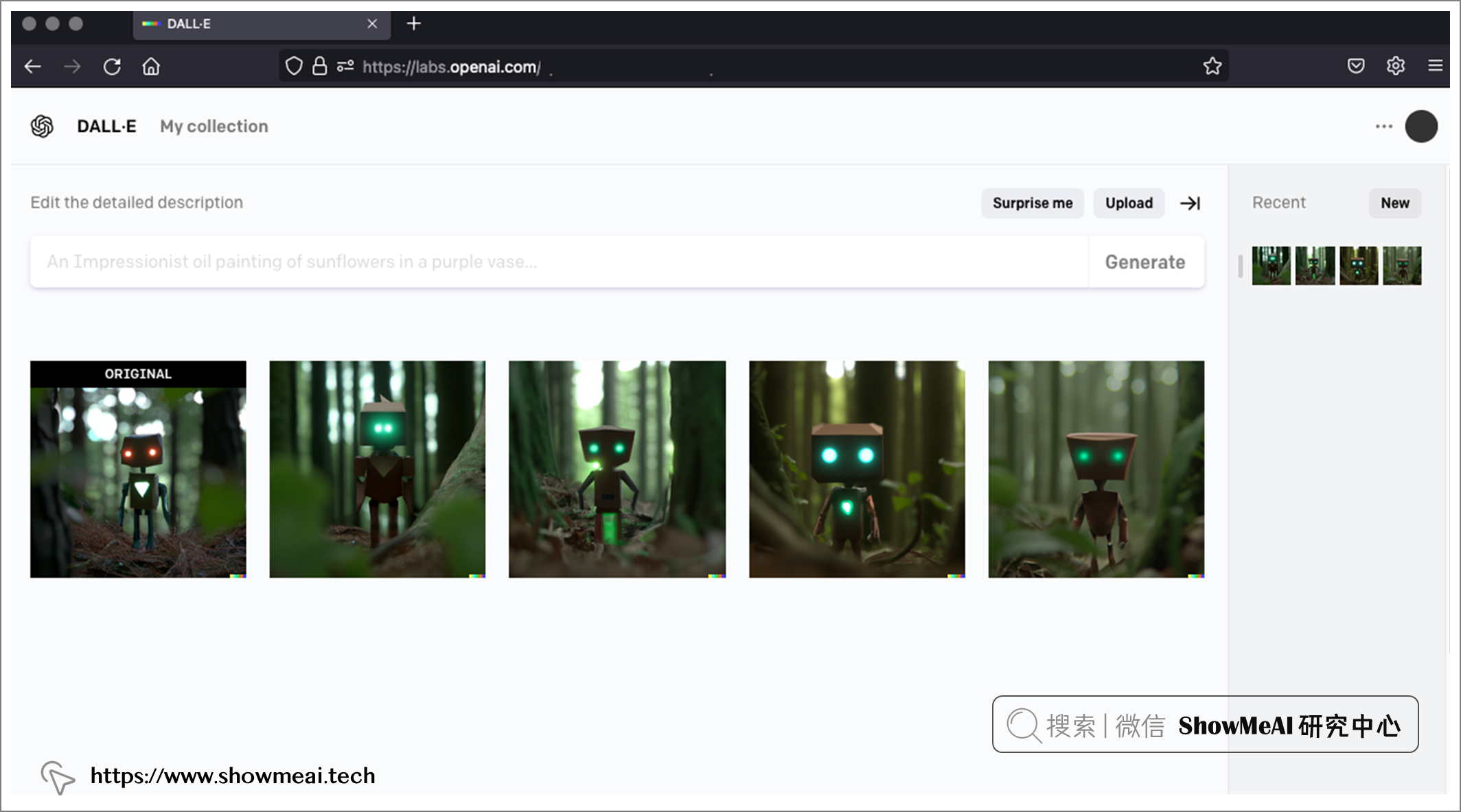
② 文本提示的图到图
它还有『编辑生成的图像』功能,使用『文本引导图像到图像』生成算法,我们可以在已生成的图像之上生成另一个图像来扩展生成的图像,或者对有遮蔽的图像进行补全创作。
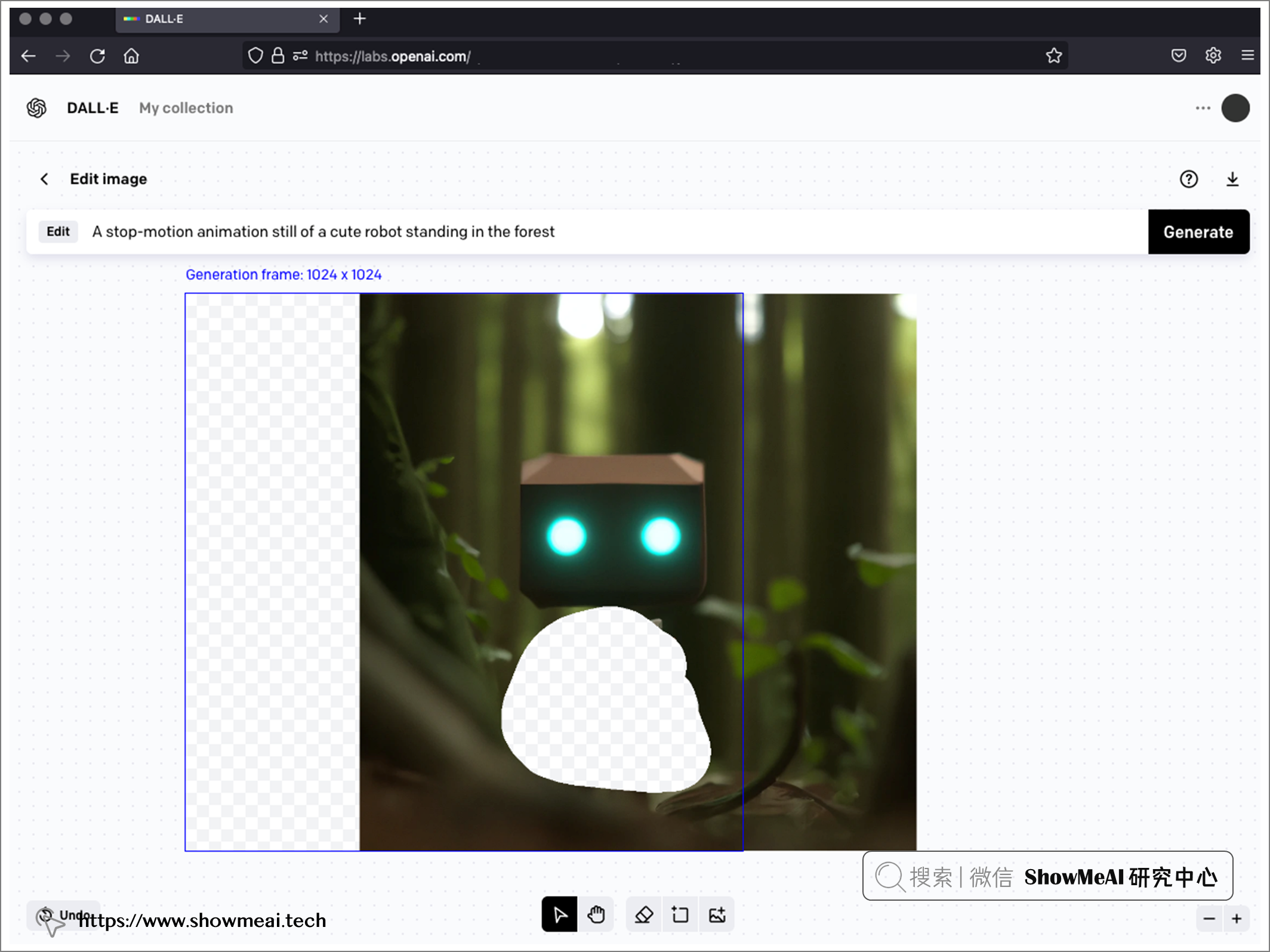
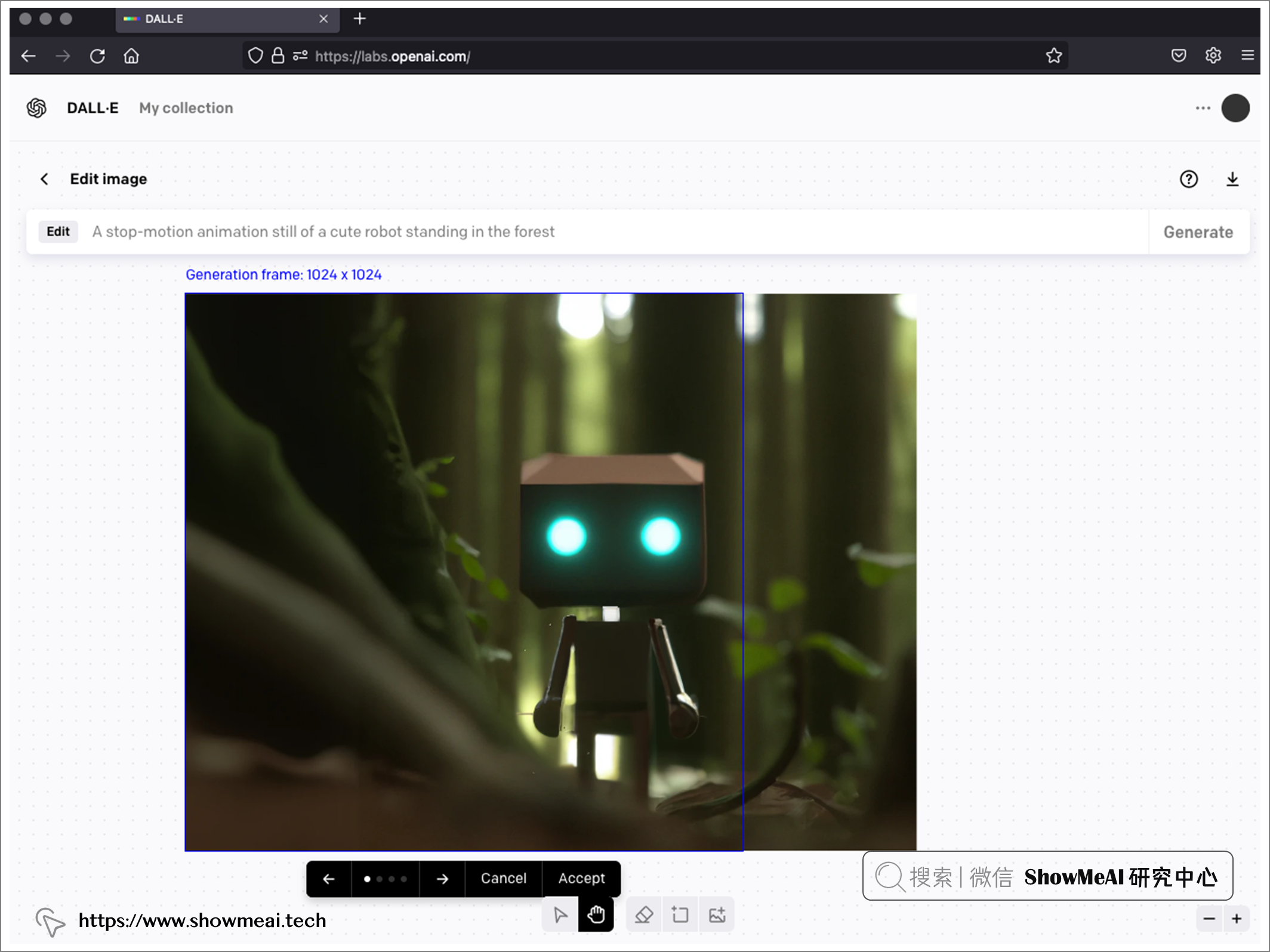
③ 分辨率和格式
在 DALL·E2 中,所有生成的图像都具有 1024 x 1024 的固定图像大小 。
💦 使用注意事项
首次访问 DALL·E 可以获得 50 个免✦费积分(要求在第一个月内用完)。 在接下来的每个月中,都会获得 15 个免✦费积分(对,同样的道理,免✦费积分不会累加)。每1个提示默认会创建4个图像,消耗大约1个积分,你也可以付费花 15 美元购买 115 次作图。
DALL·E2 生成的图像可以用于任何合法目的,包括商✦业用途。
💡 Midjourney
📘Midjourney 由同名研究实验室开发,目前处于公测阶段。
💦 如何使用
生成图像 Midjourney ,您可以使用 📘Midjourney Discord 服务器。
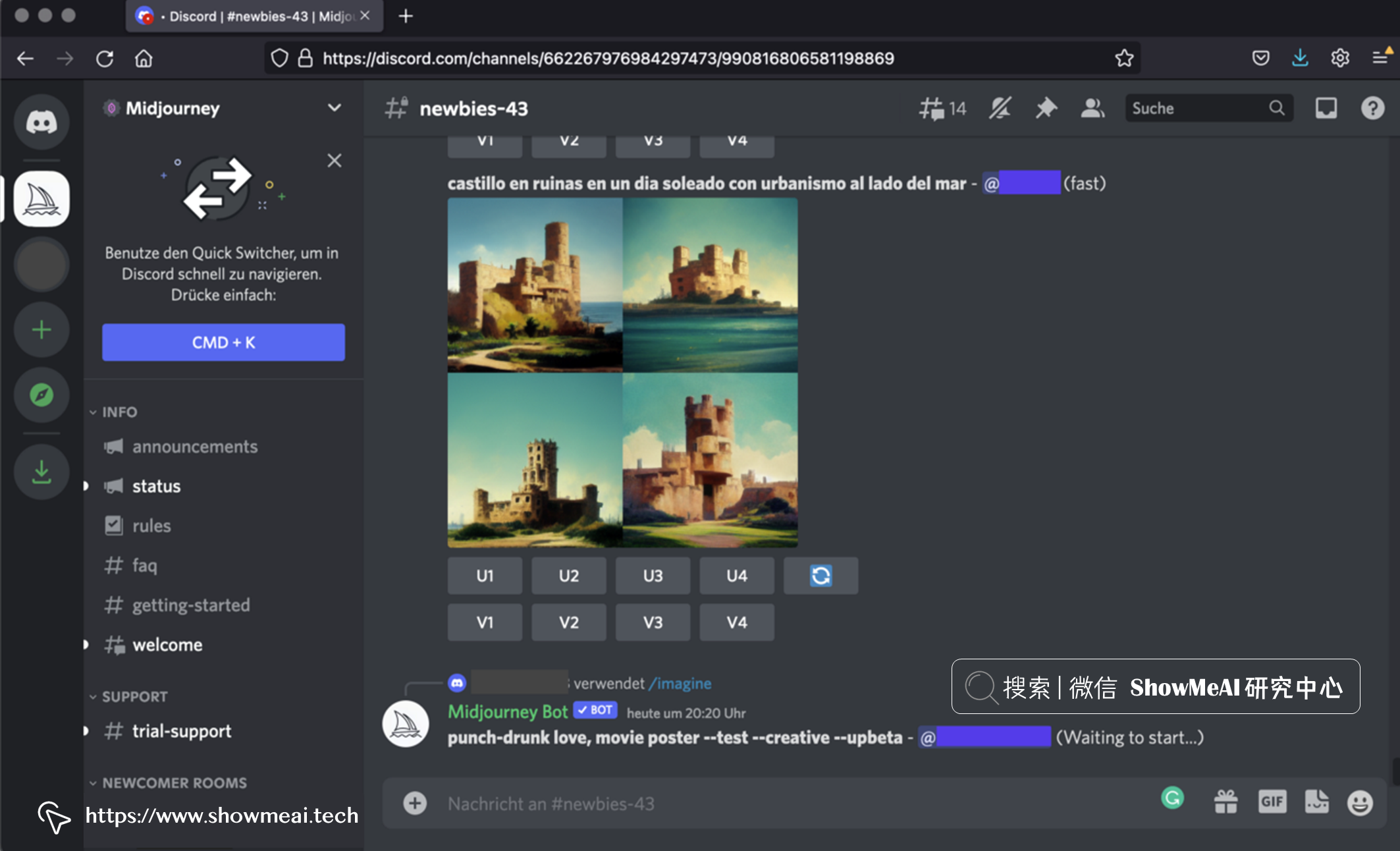
① 文本提示作图
Midjourney的『文本提示做图』也非常简单,也同样是提交提示文本,就可以生成对应的结果。
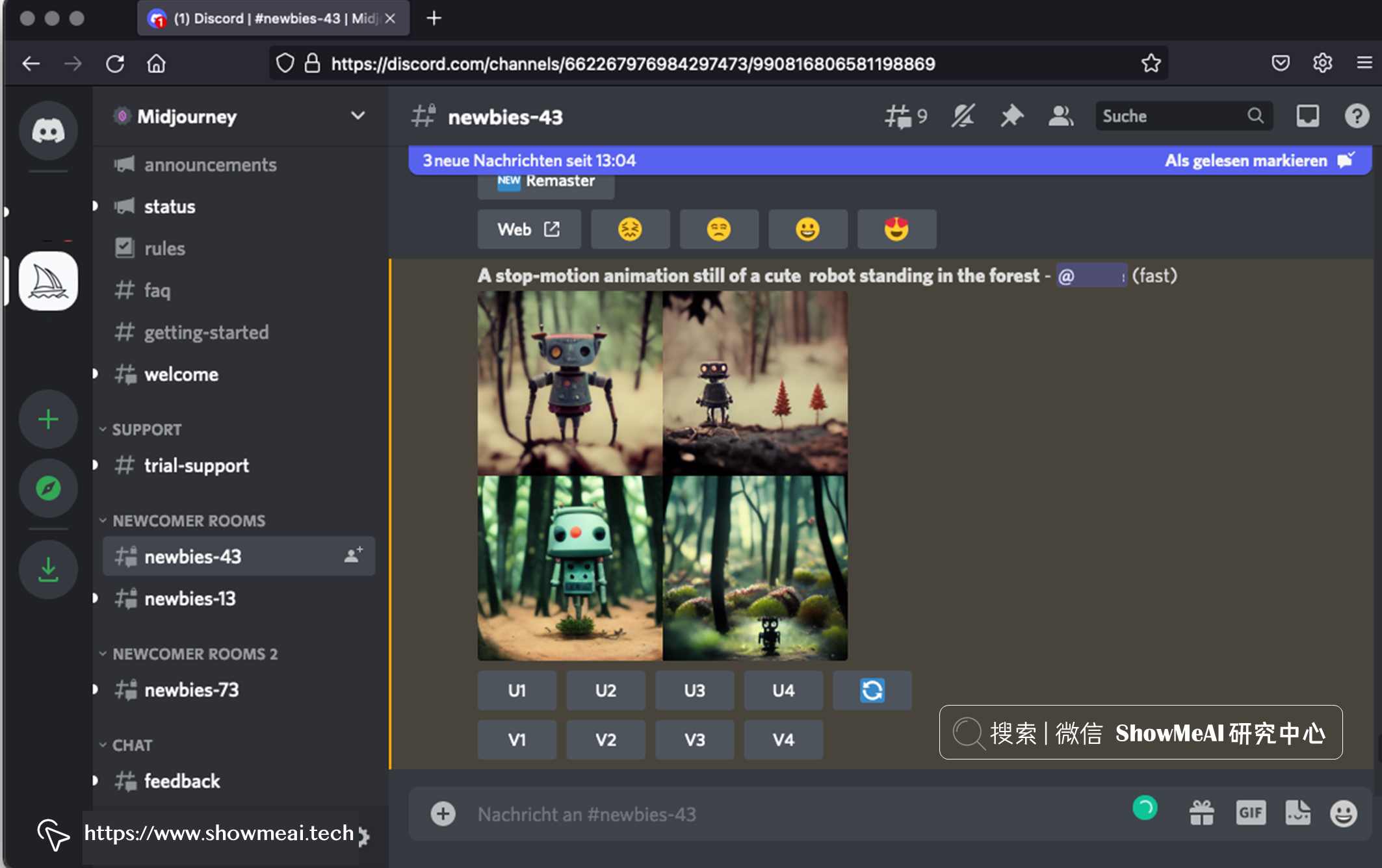
上面的截图,是在 Midjourney Discord Server 上提交提示 A stop-motion animation still of a cute robot standing in the forest (一个可爱的机器人站在森林里的定格动画) 的运行结果。
② 图像变体&高分辨率
此外,您可以创建生成图像的其他变体或将生成的图像放大到更高分辨率。
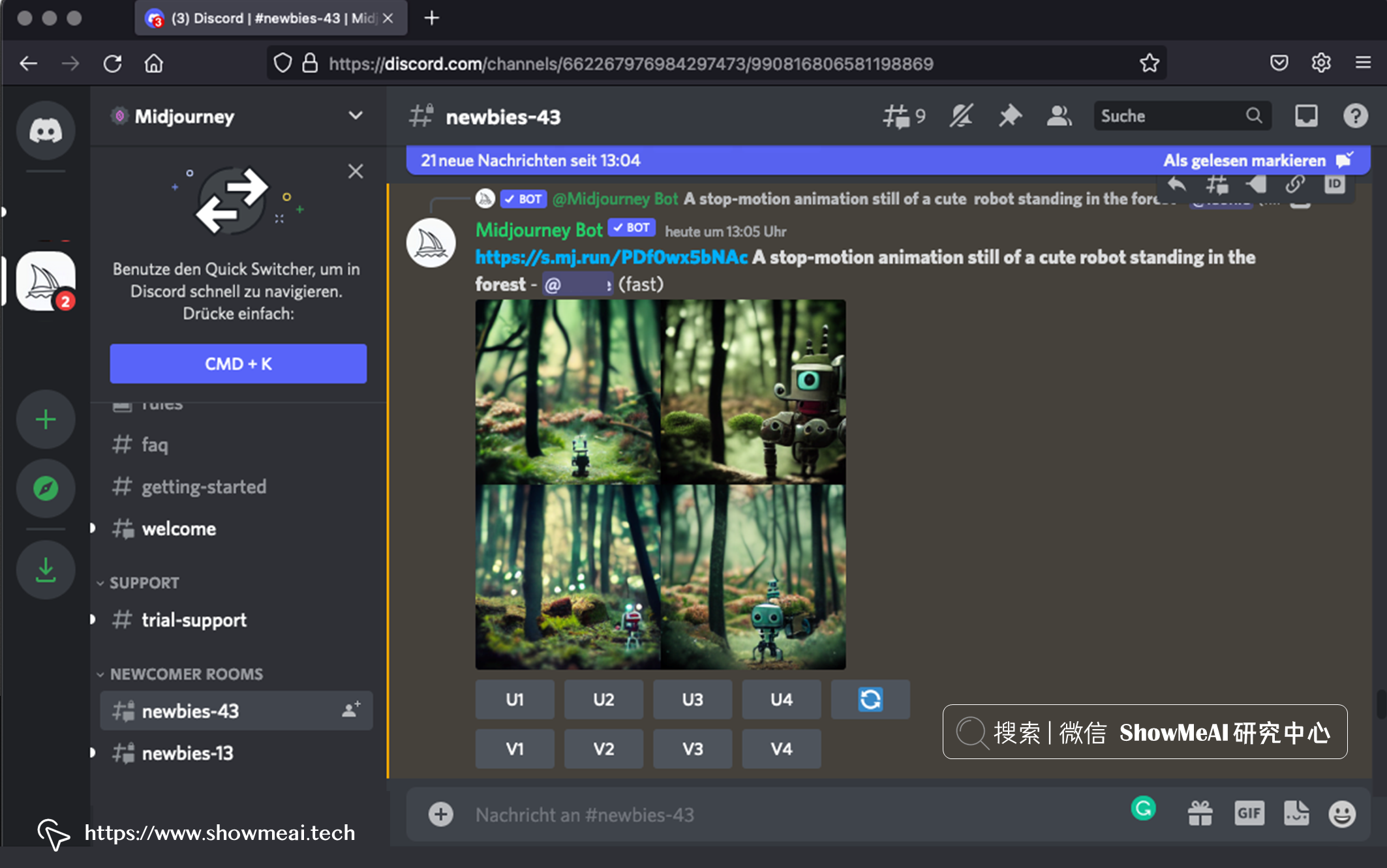
我们也可以输入一个或多个图像的 URL,以其作为初始,配以提示文本引导作图。
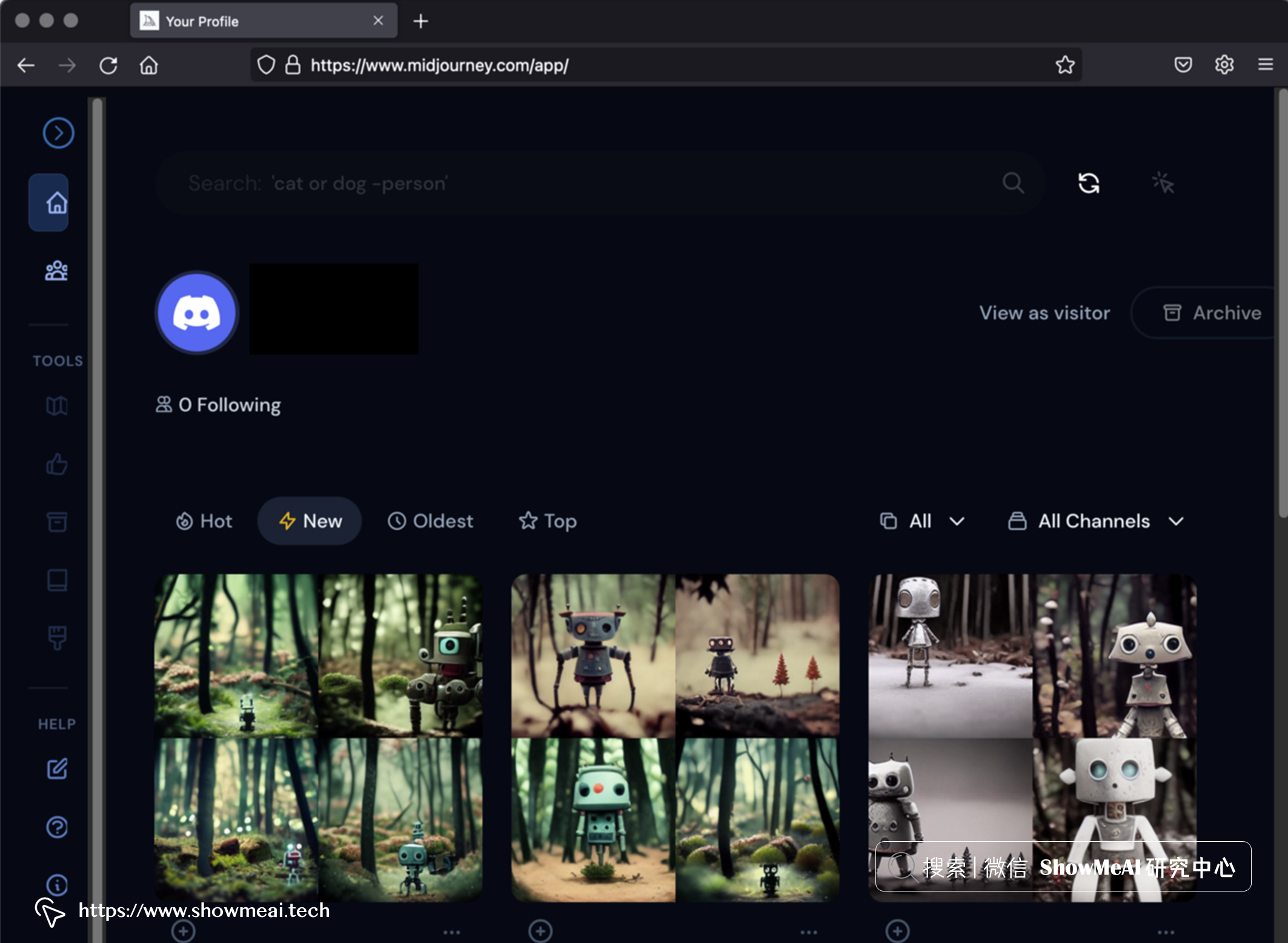
③ 分辨率和格式
Midjourney支持创建各种格式的图像,图像分辨率高达 2048 x 2048 。
💦 使用注意事项
首次加入 Midjourney Discord 服务器,我们可以获得 25 分钟的免✦费 GPU 时间,大致可以支撑 25 次免✦费生成(1次生成大概需要1 GPU 分钟)。单次请求将根据提示生成4个候选画作。
Midjourney允许付费会员将 Midjourney 生成的图像用于商✦业用途。
💡 Stable Diffusion
Stable Diffusion 由 📘CompVis、 📘Stability AI和 📘LAION开源,于 2022 年 8 月发布,大家都可以使用(但需要一些服务器计算资源支撑)。
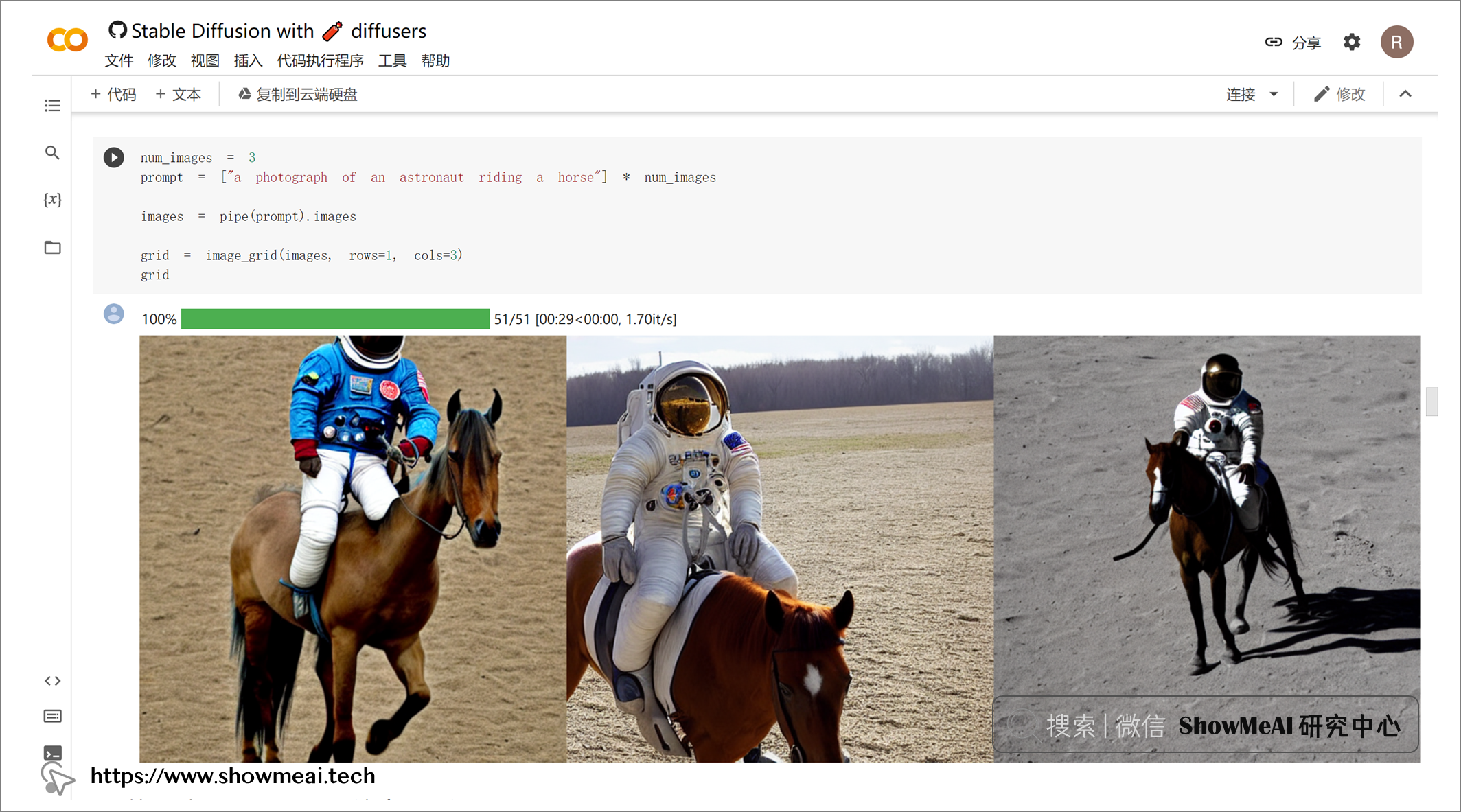
💦 如何使用
如果要本地运行 Stable Diffusion,至少需要 10GB VRAM 的 GPU。 Huggingface 提供了有关如何使用 📘Stable Diffusion 教程。
如果您不想编写和触碰任何代码,也可以使用 📘Dream Studio Web 应用程序,只需要注册一个帐户即可。
① 文本提示做图
Dream Studio 提供 『文本到图像』,它具有各种选项,例如设置生成图像的步骤数或设置随机种子,可以设置单次生成的图像数量(1 到 9 之间)。
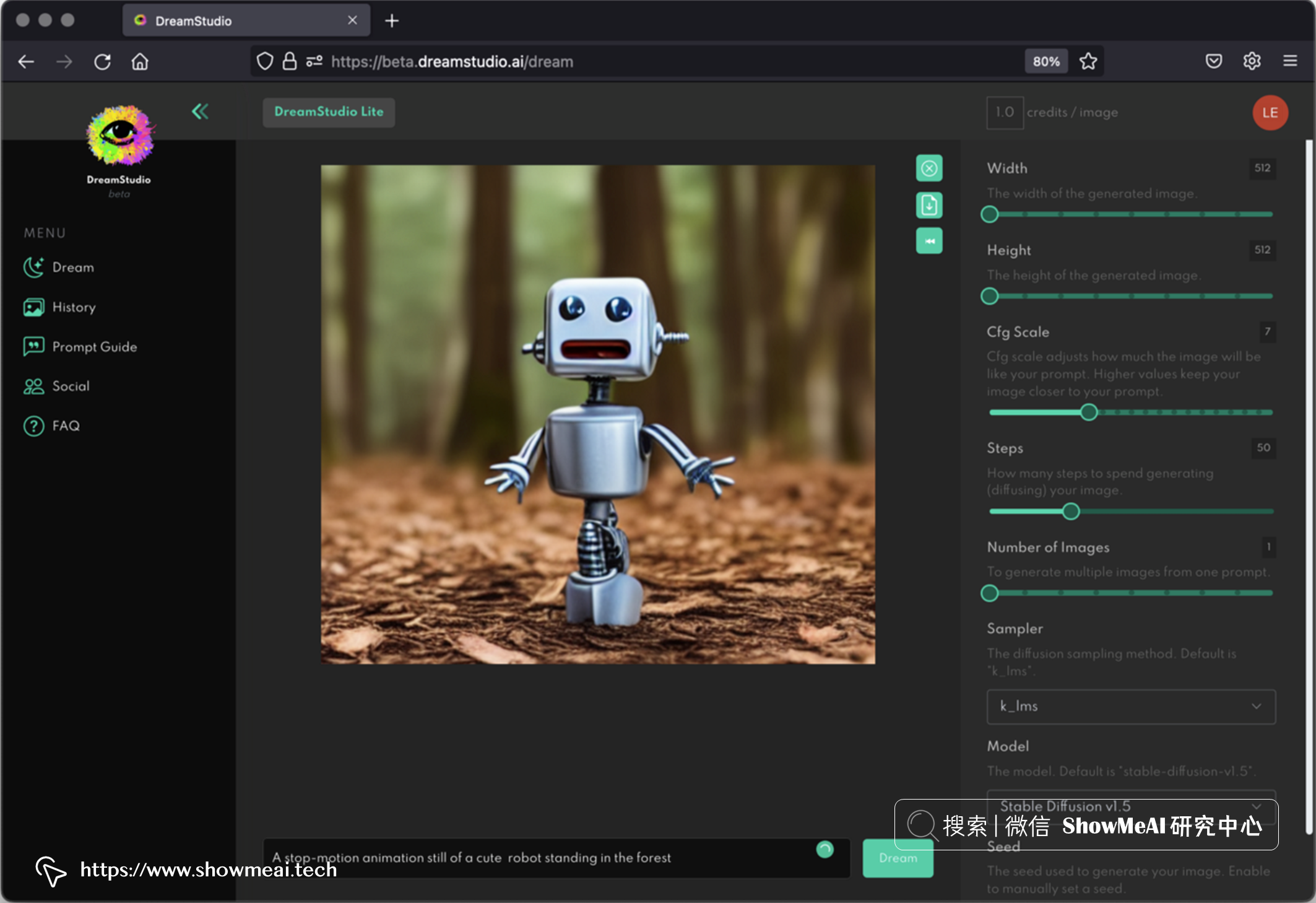
上图为 Dream Studio 提示词 A stop-motion animation still of a cute robot standing in the forest (一个可爱的机器人站在森林里的定格动画) 的运行结果。
一个快捷尝试的方式是在 📘HuggingFace的 📘Diffuse the Rest应用里尝试,如下图所示:
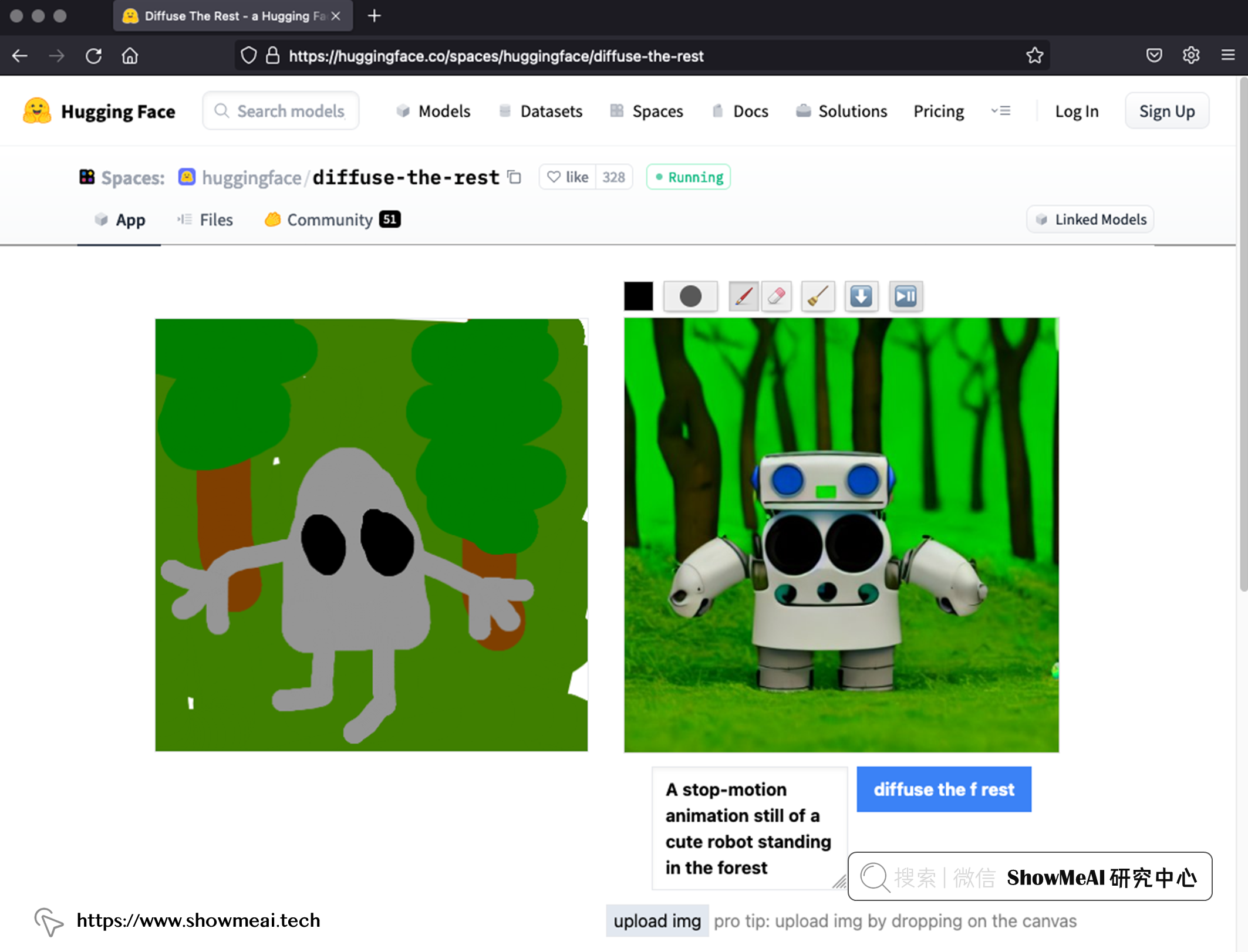
② 分辨率和格式
使用 Stable Diffusion,您可以创建各种格式的图像,图像分辨率高达 1024 x 1024。
💦 使用注意事项
首次注册 DreamStudio beta 将获得价值 2 英镑的积分。 这大约相当于 200 次单张图免✦费生成的额度。 免✦费试用后可以按 10 英镑的增量购买额外的积分。
随意使用来自 DreamStudio Beta 和 Stable Diffusion beta Discord 服务的图像用于任何用途, 包括商✦业目的 。
💡 总结
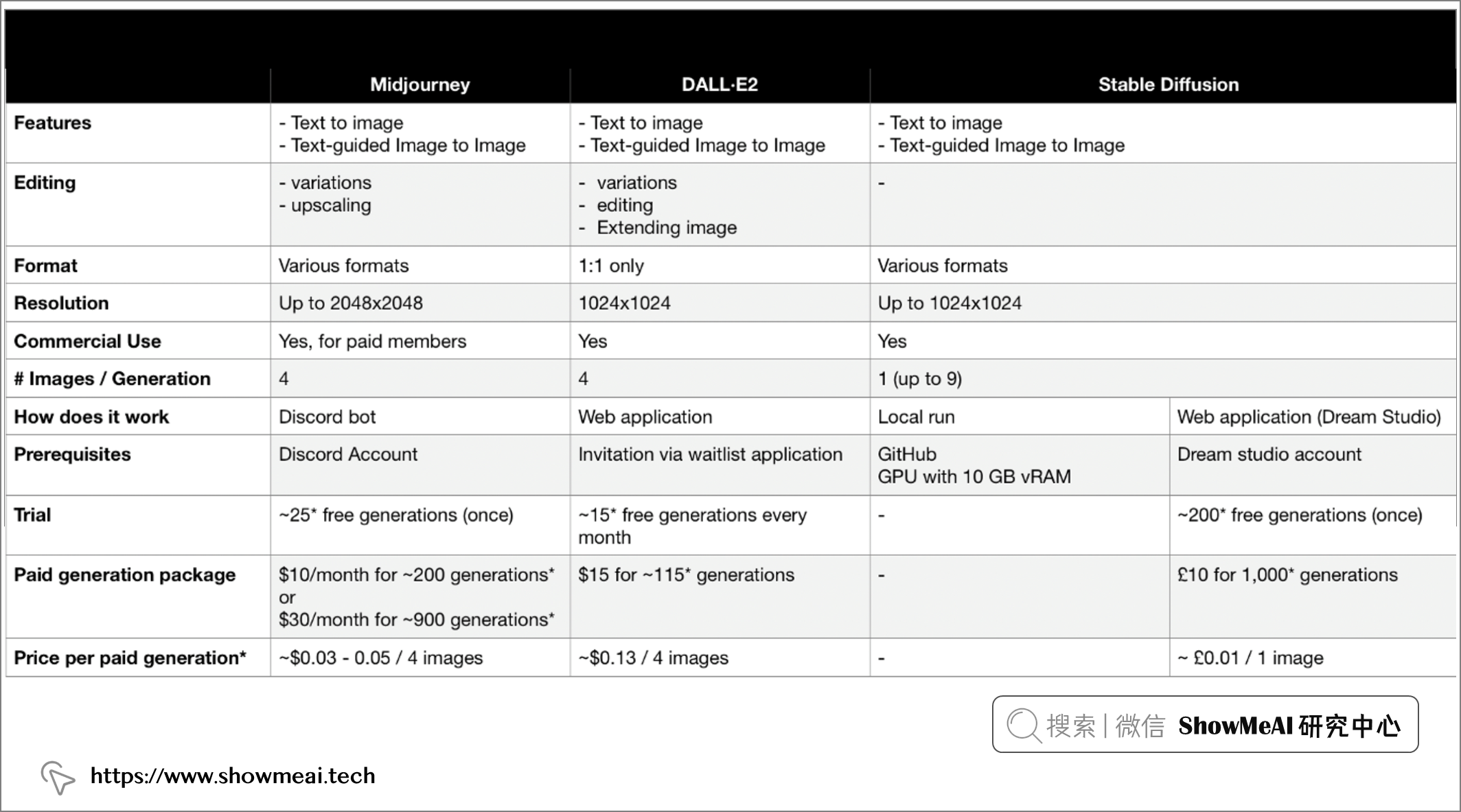
在本文中,我们比较了目前最流行的3个图像生成平台 DALL·E2、Midjourney、Stable Diffusion。对比的结果汇总如下表:
不过请大家注意,下表可能会发生变化,因为这三个模型正在积极开发中,功能也在不断完善。下方的信息来源时间点为2022年9月。
参考资料
- 📘 你给文字描述, AI 艺术作画,精美无比!附源码,快来试试!:https://www.showmeai.tech/article-detail/313
- 📘 使用Hugging Face发布的diffuser模型快速绘画:https://www.showmeai.tech/article-detail/312
- 📘 DALL·E2:https://openai.com/dall-e-2/
- 📘 OpenAI:https://openai.com/
- 📘 Midjourney:https://www.midjourney.com/
- 📘 Midjourney Discord 服务器:https://discord.gg/midjourney
- 📘 Stable Diffusion:https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb
- 📘 CompVis:https://github.com/CompVis
- 📘 Stability AI:https://stability.ai/
- 📘 LAION:https://laion.ai/
- 📘 Dream Studio Web 应用程序:https://beta.dreamstudio.ai/
- 📘 Diffuse the Rest:https://huggingface.co/spaces/huggingface/diffuse-the-rest