本次分享主要建立在C2C市场背景下,以我的工作经历讲解两个抽象维度较高的重点,分别是feed流推荐服务框架演变和用户画像系统架构演变。
简单介绍一下C2C市场的情况,C2C市场是一个真·个人对个人的markplace,大家熟悉的淘宝现在已经算作B2C或者小B2C市场了,目前真正可以算作C2C市场的是闲鱼、转转这类个人对个人的闲置交易平台。二手C2C平台的意义主要是进行物品交易和技能交换。
公司去年做过的一个“超美陪玩女神”的活动,用户可以付出金钱购买女神的时间来陪你玩游戏,本质上这也是一种交换。大家总说万能的淘宝,其实有一些边角也是被淘宝所遗漏的,比如我之前遇到过有人在卖从中世纪欧洲到现在的烙铁。

C2C市场是一个个人交换市场,会伴随有一些它独有的特点和问题。首先就是个人发布的信息具有很大的随意性,比如卖手机可能就只写一句话的简介甚至完全不写;第二就是商品库存的随意性,比如你我同卖一种东西,库存就会变得难以统计;第三就是买家对买卖信息时效的敏感性较强,卖家的一个东西几十天没卖出去,大家往往会怀疑东西自身的质量是否出现了问题或者卖家是否诚心卖。
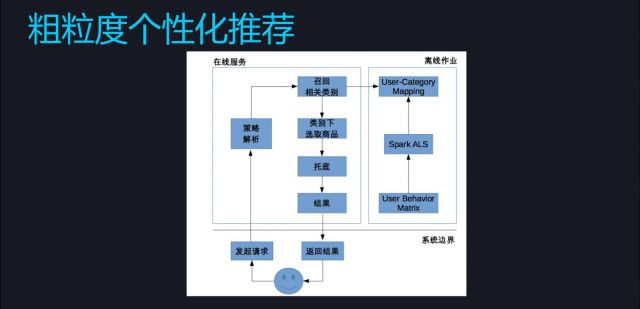
现在讲解一下Feed流架构的进化,我在这里简单把他们划分成几个时代来表示它们的进化过程,首先是原始的石器时代。石器时代的系统都比较简单,主要是两部分内容:一块是离线作业,另一块是在线服务。离线作业就是用来生成要推荐的原料;在线服务其实就是查表,查到该给用户推荐的内容然后推荐到前台。离线这部分本质上就是将用户的行为矩阵用spark矩阵分解。这里多说一句,spark上除了pipeline之外,它的算法并不是特别的好用,精度尚待提高。
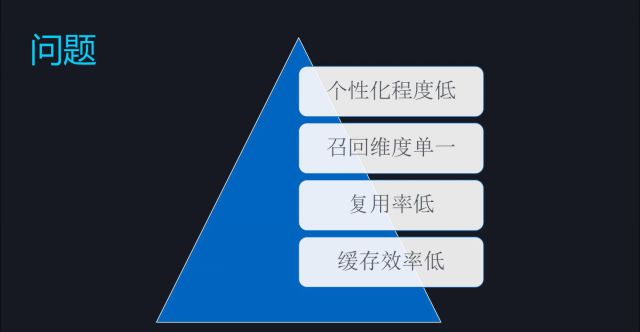
这个时代的做法仍存在较多的问题,例如个性化程度较低、召回维度单一、复用率低、缓存效率低等。
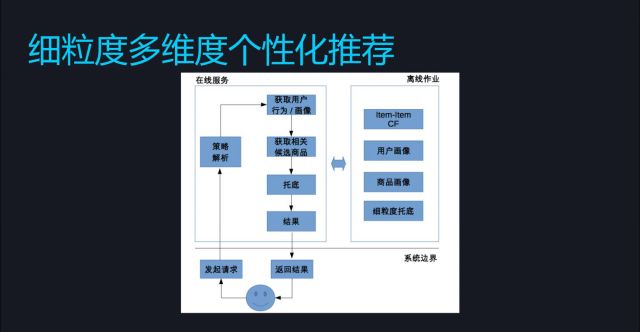
前面石器时代的框架work了一个多月,就进化到了下一代青铜时代。这一次系统进行了颗粒度的提升,从用户→类别变成了从用户→单品,同时引入了更多的维度及用户画像和商品画像,还完善了相关的托底数据。

我们在这个节点内做了如下改进:首先是细粒度的个性化提升,从类别级精细度做到了单品级的精细度;其次我们使用了CF+画像增加召回维度。CF非常好用,它可以拆出很多用法来,例如通过行为数据和购买数据都可以进行计算并且还有一定的调整空间;最后,我们在工程上增强了数据的复用性。这里有一个重点,也是一个非常重要的思想,就是我们把用户→商品这个过程拆分成了用户→X,X→商品。体现这类思想最有名的一类例子就是LDA这类矩阵分解,将一篇文章到一个词变成了一篇文章到一个topic,再从一个topic到一个词。再比如说一个人有好多个微信群,可以理解为一个人有多个兴趣,每个兴趣下包含数个群。这一大类思想普遍适用于原始数据维度很高的情况下。
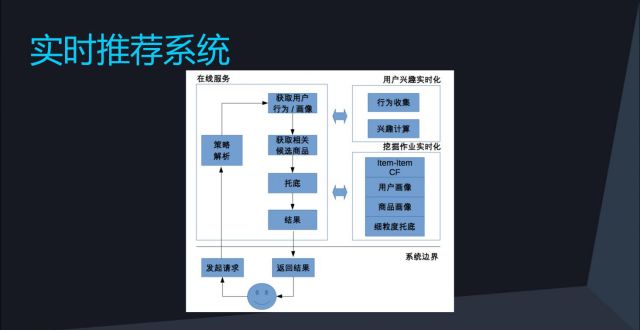

下一步就进入了工业革命第I时期,这里的重点是实时推荐系统,其中实时化是核心。我们在这里主要做了两部分的实时化 ,分别是离线挖掘的实时化和用户兴趣的实时化,诸如商品画像、CF关系等做到了实时化,兴趣也实现了实时化的计算。经过实时化这一步,我们系统的转化率提升8-9成,需要注意的是实时化并不是一时的工作,而是可以进行持续的改进。

终于进入到了机器学习的时代,我们要知道机器学习是一种驱动力。这里简略讲一下机器学习的推荐系统架构。
首先底层需要构建一套机器学习的pipeline,这个东西至关重要。pipeline构建好以后会形成一个机器学习的数据仓库,我这里使用的pipeline主要是指特征生成相关的。其实不只是推荐系统,包括计算广告系统等都需要这样的一套平台去支持。实时服务这块架构的实现逻辑是先发送请求、解析、召回、排序、业务处理、取数据。从客观上来说,大多数的公司将时间投入在平台构建这些工程化的东西上可以获得最大的收益。
大家在做机器学习前首先要问一个为什么,为什么要用机器学习做排序?因为机器学习的优化目标明确并且可量化,模型有一个很明确的优化点。Amazon在提出CF协同过滤系统的论文里并没有提出一个优化的标准,购买率高就意味着推荐的东西会买吗?点击率高就以为着这个东西真的应该被推荐吗?我记得reddit(国外贴吧)在早期的时候采用的排序就是堆公式,一堆公式堆进去,但却并没有对齐任何一个业务目标,而机器学习可以对齐业务目标。做机器学习中第一层召回质量至关重要,可以在第一层使用简化方式处理,将CF作为候选集。

机器学习模型不只是能做排序 ,还可以做召回模型和用户兴趣模型。机器学习效果很好,做好了转化率可以翻倍。但同时大家需要知道机器学习和实时化是一个持续的事情,这两者并不矛盾,可以并行运行。最理想的状态是拥有机器学习系统,同时实现模型实时更新、特征实时获取、排序实时计算。
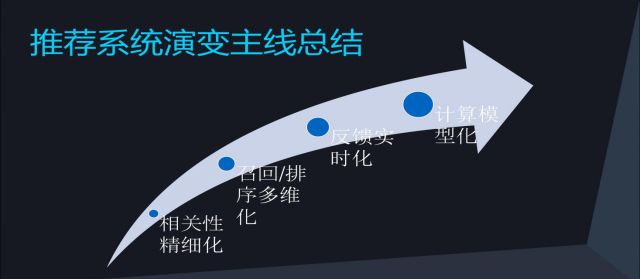
推荐系统演变主线总结:
a. 相关性精细化,比如说最早的用户画像划分到用户性别,然后你继续把他细化到更细的东西;
b. 召回/排序多维化,比如最早只有行为召回,到了后面有了用户画像召回等等多维度的召回;
c. 反馈实时化,就是你用户的行为不管是隐性的还是显示的,你能越快的反馈到你的系统里来,效果是越好的;
d. 计算模型化,当你想做的时候,你都要先想一下,这个东西是否能够模型化,能不能科学的去计算,如果可以的话,用模型来做效果肯定比直接做要好。
大家沿着这个思路去做推荐系统,一般是不会跑偏的,这四个方向每个方向的优化都会带来整体的提升。
下面再重点讲一讲用户画像,用户画像是推荐系统的一个重要环节。
为什么要做用户画像?新手容易陷入一个误区,就是还不知道为什么要做就做了,导致的问题是脱离了业务,只提出画像但业务用不上。程序员切忌把时间精力花费在只有高难度却没有高产出的事情上。

用户画像要遵循的第一原则便是做有用的用户画像。
首先是要做有效的连接。一端是用户,另一端是item,其间一定要有连接,只连上一边是无用的。这里分享点电商行业的小经验,性别画像有点用,但年龄和职业在电商行业用的较少,就拿淘宝来说,你给一个刚买过剃须刀的人一直在推荐剃须刀的作用就不会很大,因为人家刚买过这个东西,你拿规则还一直在推荐就显得不那么准。
其次是刻画要细致。比如电子产品,只知道某一个用户喜欢电子产品,这个范围太大太模糊,手机、电脑、相机、Go Pro、甚至玩客云这些都算电子产品,要通过统计方法来判别是否刻画仔细。
第三是要寻求差异,比如你能知道用户需要单反相机还是卡片相机 ,但是可能在商品一端却无法区分。

接下来,第一次做用户画像会追求多维度用户画像,比如电商里会有性别、偏好、或者一些embedding的东西出来,这时,因为初期不会提别讲究架构,更多的是你要有这个东西,去做用户召回等。

下面说一说多维度用户画像会遇到的问题,现实工作中会有不同组在做不同的部分。这里就涉及到一个生效时间的问题,一天只有24h,什么时候生效会影响推荐系统的效果,也会影响到小组配合;
第二是画像给推荐系统使用,会由下游来调用,但调用方式有多种,例如一个组使用redis、另一个组习惯elasticsearch,这些都需要协调;
第三是管理升级不统一,当你对用户画像上游调用系统做升级,你会发现你调用这么多次,还要单独去改,付出的代价会很大。
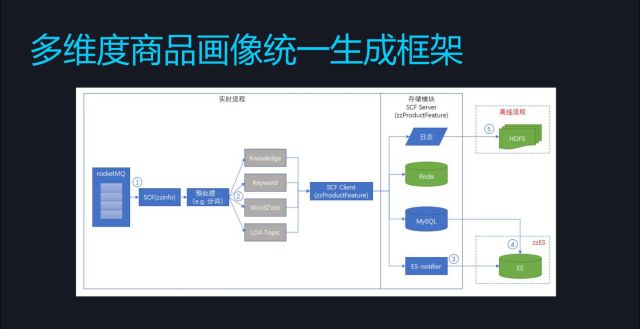
所以他的解决办法就是一个多维度商品画像统一生成的逻辑框架。重点就是中间这几个维度的用户画像,除此之外流程都是一样的,比如说接收一个数据源、做etl处理、生成是不一样、存储,然后再去解决实时化等问题,不一样的地方就是中间的用户画像。

如何更好的预测用户兴趣?老方法就是基于规则:a. 不同时间发生的不同行为赋予不同权重;b. 将权重做累加计算。这样做会遇到俩个问题,一个是拍脑袋规则量化不准确,一个是无法合理利用负反馈。

所以还是用了一个方法就是用机器学习驱动的用户兴趣模型去预测,基于你的历史反馈,正反馈和负反馈,提取你的特征来,然后走机器学习,去预测你的相关性,能量化的就用模型量化,不要堆砌规则,因为当你的场景发生变化时,机器学习模型可以随时去更新,而不需要去再改规则。

机器学习的优势在于更好的利用负反馈、规则的量化和有更大的探索性扩展性,可以通过机器学习来预测。大家可以在网上了解一下信息茧房这个概念,做机器学习要突破这个结界。
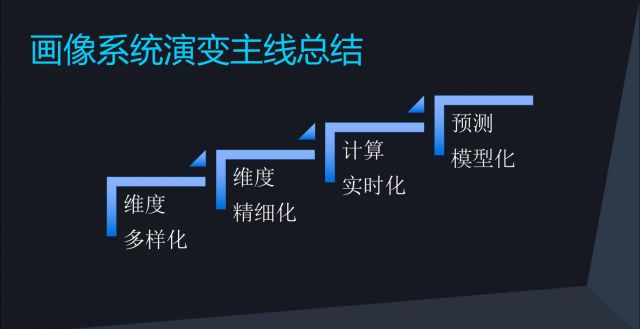
这是画像系统的演变主线总结:
a. 维度多样化。像盲人摸象一样发散思维、补充维度。
b. 维度精细化。太粗了效果不佳,但是一个数码产品比如手机,品牌是苹果,具体型号是什么,太细了反而也会不好,这里有个度需要把握。
c. 计算实时化 。这里当然是反馈越快越好,一个数天前的数据时效性就会大打折扣。
d. 模型预测化。建立了机器学习的系统要尽可能多的去尝试不同模型,优化效果。




](https://img-blog.csdnimg.cn/cdfda253123349fc897c5c405407e58c.png)