文章目录
- [2021] (QoMEX) Image Super-Resolution Quality Assessment:Structural Fidelity Versus Statistical Naturalness
- 摘要
- 引言
- 2D QUALITY ASSESSMENT OF SISR IMAGES
- FUSING 2D ASSESSMENT FOR 1D PREDICTION
- 结论
- [2022] ERQA: Edge-Restoration Quality Assessment for Video Super-Resolution
- 摘要
- 引言
- RELATED WORK
- PROPOSED METHOD
- Dataset
- Subjective Comparison
- Edge Restoration Quality Assessment Method
- EXPERIMENTAL VALIDATION
- Ablation Study
- Comparison with Other Metrics
- CONCLUSION AND FUTURE WORK
- [2019] Image Quality Assessment through Contour Detection
- 摘要
- 引言
- A C o u n t e r -b a s e d I n d e x
- 实验
- C o n c l u d i n g R e m a r k s
- [2021] (CVPR) Neural Side-By-Side: Predicting Human Preferences for No-Reference Super-Resolution Evaluation
- 摘要
- 视频评价[2022] Learning Generalized Spatial-Temporal Deep Feature Representation for No-Reference Video Quality Assessment
- Abstract
- INTRODUCTION
- RELATED WORKS
- THE PROPOSED SCHEME
- EXPERIMENTAL RESULTS
- CONCLUSION
- [2022] (CVPRW) Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
- 摘要
- 引言
- 相关工作
- Methodology
- 全参考注意力VTAMIQ: Transformers for Attention Modulated Image Quality Assessment
- 摘要
- Introduction
- VTAMIQ: Vision Transformer for IQA
- [2018] (CVPR)The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
- 摘要
- 结论
- 引言
- 数据集
- 感知相似性度量
- Deep Feature Spaces
- 自然数据集KonIQ10k: An Ecologically Valid Database for Deep Learning of Blind Image Quality Assessment
- 摘要
- 引言
- 数据库生成
- IV. SUBJECTIVE IMAGE QUALITY ASSESSMENT
- 美学图像[2018] NIMA: Neural Image Assessment
- 摘要
- 引言
- 贡献
- 数据集
- PROPOSED METHOD
- 夜间图像[2020] Blind Night-Time Image Quality Assessment:Subjective and Objective Approaches
- 摘要
- 引言
- NNID DATABASE
- THE PROPOSED BNBT METRIC
- Statistical Significance Comparison
- 夜间图像Blind quality assessment of night-time image
- 引言
- 方法
[2021] (QoMEX) Image Super-Resolution Quality Assessment:Structural Fidelity Versus Statistical Naturalness

摘要
-
单图像超分辨率(SISR)算法用低分辨率(LR)图像重建高分辨率(HR)图像。因此,有必要开发一种既能对SISR算法进行评价和比较,又能指导其未来发展的图像质量评估(IQA)方法。在本文中,我们评估了在结构保真度与统计自然度的二维空间(two-dimensional (2D) space)中,SISR生成的图像的质量。
-
这使我们能够观察到不同的SISR算法在二维空间中的折衷行为。具体来说,传统的SISR方法旨在实现高结构保真度,但往往牺牲了统计的自然性,而最近基于生成对抗网络(GAN)的算法倾向于创建更自然的结果,但在结构保真度上显著损失。此外,这种二维评价可以很容易地融合到标量质量预测中。有趣的是,我们发现,当使用公共主题评级的SISR图像数据集进行测试时,直接的局部结构保真度和全局统计自然度测量的简单线性组合产生了令人惊讶的准确的SISR图像质量预测
引言
-
单图像超分辨率(SISR)是在单幅低分辨率(LR)图像的基础上恢复高分辨率(HR)图像。从卫星成像、网页浏览到视频监控[1],SISR在广泛的应用中发挥着重要的作用。在过去的几十年里,人们提出了许多SISR算法,包括基于插值的[2]、[3]、基于字典的[4][6]和基于深度学习的[7][12]。当采用不同的SISR方法时,生成的图像的视觉外观( visual appearance)和质量会有很大的变化。然而,对于如何评估SISR生成的图像的质量,仍然没有达成共识。这是至关重要的,因为图像质量评估(IQA)方法不仅有助于评估和比较SISR算法,而且还指导未来的SISR方法的发展。
-
一般来说,最可靠的质量评价方法是人的主观评价[13][15]。但是主观测试通常是昂贵的、耗时的,并且很难集成到SISR优化框架中。因此,为SISR生成的图像设计有效的客观IQA模型是非常必要的。取决于可以采用原始图像,全参考(FR) IQA[16][22]和无参考(NR) IQA方法[23][27]。此外,由于许多SISR算法产生模糊的重建图像,图像清晰度评估(ISA)或模糊度量[28][30]也可以使用。
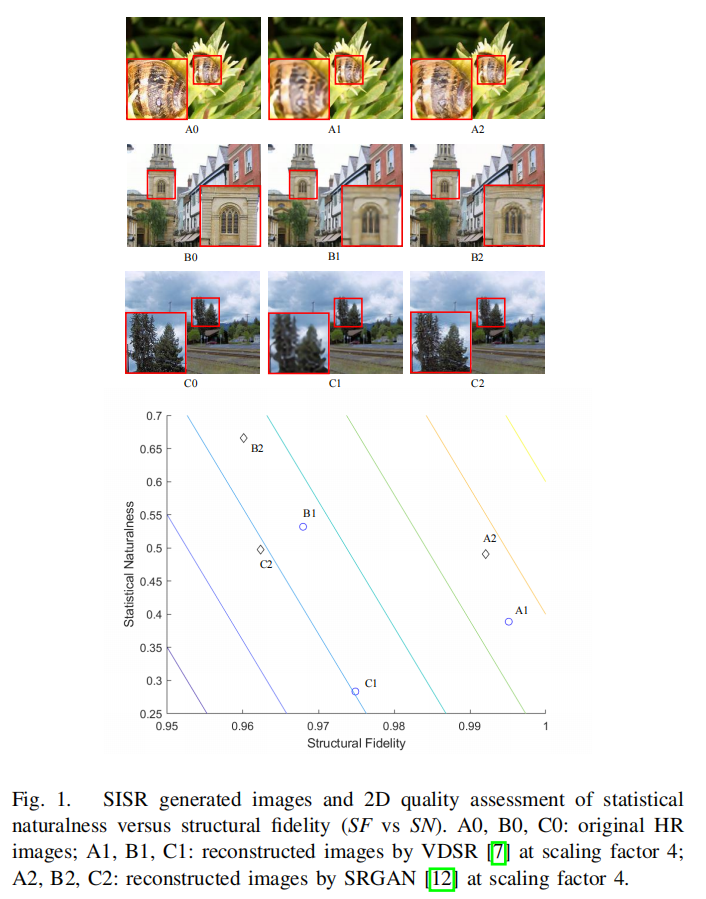
图1所示。SISR生成图像和统计自然度与结构保真度(SF vs SN)的2D质量评估。A0、B0、C0:原始HR图像;A1、B1、C1: VDSR[7]在比例因子为4时的重建图像;A2, B2, C2:采用SRGAN[12]对比例因子4的重建图像。 -
尽管在其他IQA应用中取得了成功,但现有的FR-IQA、NR-IQA和ISA方法在评估SISR生成图像的质量时往往存在不足。差距不仅存在于主观评分预测的准确性上,也存在于有效解释SISR图像中关键质量退化趋势的本质上。如图1所示,传统的SISR方法如VDSR[7]在实现高信噪比或结构相似性[16]方面是非常有效的,当与原始图像比较时,但最终的图像往往看起来是人造的。另一方面,最近提出的基于生成对抗网络(GAN)的方法,如SRGAN[12],在生成看起来自然的重建图像方面令人印象深刻,但它们的信号保真度指标明显较低。这些观察结果促使我们在结构保真度与统计自然度的二维(2D)空间中看待问题,如图1底部所示。
2D QUALITY ASSESSMENT OF SISR IMAGES
function [sf, sn] = compute_sf_sn(imgref, imgdis)[m, n] = size(imgdis);s = min(m, n);Orig_ref = imresize(imgref, [s, s]);%TransformOrig_T_ref = dct2(Orig_ref);%Split between high- and low-frequency in the spectrum在频谱中分成高频和低频cutoff = round(0.5 * s);High_T_ref = fliplr(tril(fliplr(Orig_T_ref), cutoff));Low_T_ref = Orig_T_ref - High_T_ref;%Transform backHigh_ref = idct2(High_T_ref);Low_ref = idct2(Low_T_ref);Orig = imresize(imgdis, [s, s]);%TransformOrig_T = dct2(Orig);%Split between high- and low-frequency in the spectrum (*)cutoff = round(0.5 * s);High_T = fliplr(tril(fliplr(Orig_T), cutoff));Low_T = Orig_T - High_T;%Transform backHigh = idct2(High_T);Low = idct2(Low_T);sf = msssim(uint8(Low_ref), uint8(Low));//低频->结构sn = entropy(uint8(High));//高频->纹理
end多尺度图像分解,如拉普拉斯和小波变换,已被证明是高效的特征,不仅局部感知退化,而且图像的统计自然性。因此,我们应用多尺度图像变换,并在变换域中构造局部结构保真度和全局统计自然度测度。给定原始HR图像x和SISR生成的测试图像y,灵感来自MS-SSIM[17]的成功,我们定义子带patch级结构保真测度为:
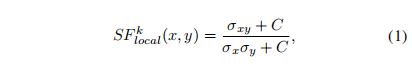
其中x、y分别表示从x、y的第k个子带提取的小块,σx、σy为它们的标准差,σxy表示x与y之间的协方差,C为正的稳定常数。然后通过空间池化计算尺度级结构保真度:
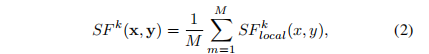
其中M为子带内局部patch的数量。最后,我们融合跨尺度,以获得x和y之间的整体结构保真度:

其中K是尺度/子带的总数,αk是分配给第K个尺度的权重,如[17]。此外,自然纹理丰富的内容往往在变换域[31]具有更高的熵。因此,我们使用变换系数的全局熵作为统计自然度的度量
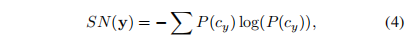
其中P(cy)表示测试图像y的子带系数的概率,可以用直方图来近似。
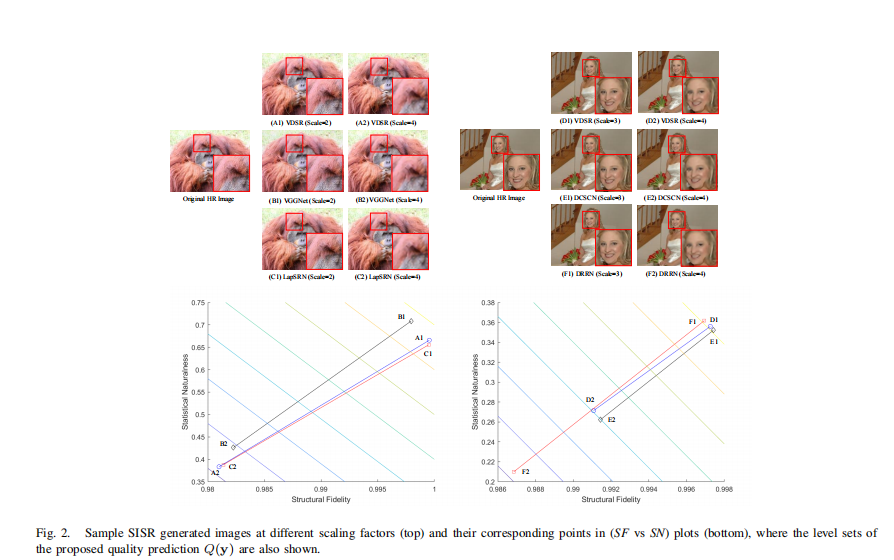
虽然提出的成对(SF, SN)测度相当简单,但它为SISR算法的行为提供了一个有意义的2D表示。图1为三幅原始HR图像及其对应的SISR图像,分别由VDSR[7]和SRGAN[12]生成。(SF vs. SN)图清楚地表明了VDSR在SF(结构)测量上相对于SRGAN的优势,而SRGAN在SN(纹理)测量上相对于VDSR的优势。
FUSING 2D ASSESSMENT FOR 1D PREDICTION
在实践中,通常希望获得一个单一的质量分数,以表明SISR生成的图像的整体质量。这可以通过将提出的二维测度压缩为标量质量预测来实现,例如,通过线性组合
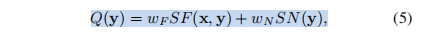
其中,加权因子wF和wN调整了两个度量的相对重要性,在当前的实现中,经验分别设置为0.9和0.1。我们将Q称为SFSN测度,它在2D空间中创建直线作为水平集,如图1和图2底部的图所示。这种标量质量预测可以通过与SISR生成的图像的主观评级进行比较来验证。
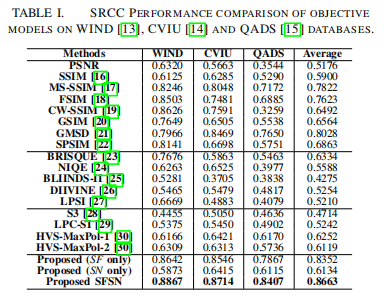
在WIND[13]、CVIU[14]和QADS[15]三个公开的SISR IQA数据库上验证了所提出的融合SFSN质量预测方法。WIND数据库考虑了缩放因子为2、4和8的8种插值算法。它包含312张SISR图像,对应13张参考图像。CVIU数据库由30张参考HR图像和1620张由9种算法生成的SISR图像组成,这些算法使用6对(缩放因子,核宽度)组合,其中缩放因子越大对应的模糊核宽度越大。QADS数据库包含20张原始HR图像和980张由21种SISR算法生成的图像,包括4张基于插值的模型、11张基于字典的模型和6张基于深度学习(DL)的模型,这些模型上采样因子分别为2、3和4。在这三个数据库中,每个SISR生成的图像都是主题评级和注释的平均意见分数(MOS)。我们与8个FR-IQA模型、5个NR-IQA模型和4个ISA模型进行了比较。斯皮尔曼秩序相关系数(SRCC)的比较结果报告在表1中,其中以粗体突出显示了最佳性能。其他常见的评估标准[32]也会产生类似的结果,但由于空间限制,没有包括在内。尽管SFSN的结构简单而直接,但与最先进的IQA和ISA模型相比,它取得了令人惊讶的竞争性能。
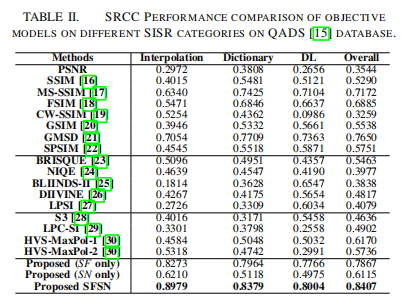
由于不同类别的SISR方法通常会产生截然不同的重建图像外观,因此研究IQA方法在不同类别的SISR中的表现是很有趣的。表II报告了在QADS[15]数据库上的结果,在表II中,所提出的方法在基于插值、基于字典和基于dl的SISR类别中,以及在同时评估这三种类别时,都具有优越的性能。消融试验也被用于评估仅采用SF或SN测量时的性能。结果见表一和表二。似乎SF和SN都做出了重要的贡献,但结合两者的SFSN模型的性能最好。
结论
在这项工作中,我们选择了二维方法来评估SISR生成图像的质量,作为结构保真度和统计自然度之间的权衡。这使我们能够更好地理解质量退化的本质,并更好地观察不同SISR算法的不同行为。我们还表明,局部结构保真度评估、全球统计自然度测量和两者的线性组合的一个相当直接的实施,导致了一个与MOS达到惊人的高相关性的SFSN模型。未来可能会发展出更好的结构保真度和统计自然度测度,以及更复杂的组合方法。二维评估的思想也可以整合到新的SISR算法中,旨在实现两个目标之间的最佳平衡。
[2022] ERQA: Edge-Restoration Quality Assessment for Video Super-Resolution

摘要
尽管视频超分辨率(VSR)越来越流行,仍然没有一个好的方法来评估在放大帧中恢复的细节的质量。一些VSR方法可能产生错误的手指或完全不同的脸。这种方法的结果是否可信,取决于它能否还原真实的细节。图像超分辨率可以利用自然分布来生成高分辨率的图像,它只与真实图像有几分相似。VSR能够探索相邻帧中的附加信息,从原始场景中恢复细节。本文提出的ERQA度量,旨在估计模型使用VSR恢复真实细节的能力。假设边缘对细节和字符识别很重要,我们选择边缘保真度作为这个度量的基础。实验验证我们的工作是基于MSU视频超分辨率基准,其中包括最困难的模式恢复细节,并验证从原始帧的细节保真度。
引言
超分辨率作为图像和视频处理的基础任务,一直是一个热门的研究课题。它有着广泛的应用,从低复杂度的编码到老胶片的修复和医学图像的增强。在放大的视频和图像的质量评估方面,倾向于结合保真度和统计自然度估计。但在某些任务中,复原保真度比统计自然度重要得多:例如闭路电视记录中的小物体识别(如车牌号码)、文本识别和医学图像重建。

图1:在缩放视频中改变上下文的例子:在视频缩放过程中,来自源帧(GT,最左边)的两个字符混合在一起产生一个新的字符。

图2:细节恢复质量不同的放大图像示例。最右边的图像在视觉上更自然,但最左边的图像细节的形状更接近原始图像。

随着基于深度学习方法的发展,许多超分辨率模型产生了视觉上自然的框架,但失去了重要的细节。例如,图2中最右边的图像,经TDAN (Tian et al., 2020)放大后,感知上优于最左边的RRN-10L (Isobe et al., 2020)放大后的图像,但左边闪亮的线的形状大多数图像更接近地面真实(GT,中心)。有时候,这种模型甚至可以改变图像中的背景,例如,在不减少传统度量值的情况下产生不正确的数字、字符甚至人脸。在图1中,RealESRGAN (Wang et al., 2021)混合了低分辨率图像中的两个字母,形成了一个完全不同的图像。在图4中,RPBN (harris等人,2019年)在右下角的字符上添加了水平线,但所有三个模型在传统指标上的得分相同。在图5中,Real-ESRGAN (Wang et al., 2021)和RealSR (Ji et al., 2020)产生了与源图像有很大差异的非自然人脸。
图1、2、4、5中的例子表明,图像和视频超分辨率细节恢复质量的评估是困难的。估计复原保真度的最佳方法是进行主观比较;这是最精确的方法,但费时且昂贵。另一种方法涉及参考质量指标。传统的相似性度量如PSNR和SSIM (Wang et al., 2004)经常被用于评价超分辨率模型,但它们产生的结果很差,在处理位移和其他常见的超分辨率工件时不稳定。LPIPS (Zhang et al., 2018)在这一任务中越来越受欢迎,但它最初的目的是评估感知相似性( perceptual similarity),而不是逼真度( fidelity)。新的DISTS (Ding等人,2020a)指标是对LPIPS的改进,但它也关注于感知相似性。
我们的研究重点是分析超分辨率算法,特别是其恢复保真度。当我们开始为视频超分辨率的基准工作时,包括恢复质量评估的测试,我们发现现有的指标对于其他测试(恢复自然性和美感)工作良好,但与主观细节质量评估的相关性较低。因此,本文提出了一种新的信息保真度评价方法。实验表明,我们的度量在评估细节恢复方面优于其他超分辨率质量度量。
我们的工作主要贡献如下:1。视频超分辨率基准基于包含最困难的细节恢复模式的新数据集。2. 一种主观的比较,检验原始帧细节的保真度(the fidelity of details from the original frame),而不是传统的统计自然美(traditional statistical naturalness and beauty)。3.一种评价视频超分辨率细节恢复质量的新指标。
RELATED WORK
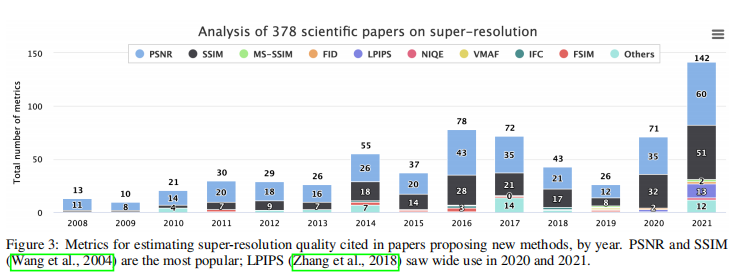
图3:提出新方法的论文中估计超分辨率质量的指标,按年划分。PSNR和SSIM (Wang et al., 2004)是最常用的;LPIPS (Zhang et al., 2018)在2020年和2021年得到广泛应用。
-
PSNR和SSIM (Wang et al., 2004)是评价超分辨率质量的常用指标。我们分析了378篇提出超分辨率方法的论文,发现自2008年以来,PSNR和SSIM仍然是最受欢迎的指标。但两者都显示出与主观得分的低相关性。LPIPS (Zhang et al., 2018)在过去两年中越来越受欢迎;其他指标仍然不太流行(图3)。
-
一些评估超分辨率视觉质量的全参考指标已经出现。(2018)使用4个特征(梯度大小、相位一致性、各向异性和方向复杂性)计算了放大和原始高分辨率帧的感知结构度量(PFSM)。将相似函数应用于PFSMs,在其数据集的视觉感知方面比以往的方法显示出更一致的结果。(Zhou et al., 2021)计算结构保真度和统计自然度,将这些系数融合为加权和,并在QADS图像数据库上获得良好的相关性(Zhou et al., 2019)。
-
另一种流行的方法是从LR和缩放(SR)图像中提取结构或纹理特征,分别比较它们,并融合得到的相似指数(Yeganeh et al., 2015;Fang等,2019)。基于该思想的度量在各种数据集上达到了0.69 ~ 0.85的斯皮尔曼等级相关系数(SRCC)。(Yang等人,2019年)使用从LR和SR图像提取的统计特征训练了一个回归模型,获得了类似于数据集上其他顶级指标的相关性(Ma等人,2017年)。(Shi等人,2019)提出了另一种 reduced-reference assessment的方法,使用视觉内容预测模型来衡量参考和SR图像的结构。这种方法在SISRSet数据集上优于以往的方法(Shi等人,2019年)。
-
一些无参考指标也用于视频超分辨率。(Ma et al., 2017)根据从放大帧提取的统计特征训练回归模型,在其数据集上实现高值的SRCC。(Zhang等人,2021年)提出了一种无参考指标,基于使用预先训练的神经网络VGGNet提取的特征。(Wang et al., 2018)使用提取的特征训练SVM,得到与其他指标相似的结果。(Greeshma和Bindu, 2020)提出了SRQC指标,该指标估计结构变化和质量感知特征。这个度量显示了良好的结果,但是他们只考虑了少量的图像和测试数据集的四种SR方法。
-
边缘对人类的视觉系统有很强的影响。此外,边缘保真度是评价细节恢复质量的基本准则。因此,几种方法将边缘特征作为质量评估的基础。一些算法计算边缘特征,包括数量、长度、方向、强度、对比度和宽度,并使用相似性度量对它们进行比较,以估计图像或视频质量(Attar等人,2016;Ni等人,2017)。然而,这些指标在其数据集上实现的相关性几乎与传统的PSNR和SSIM相同。在(Xue and Mou, 2011)中,作者检测参考图像和畸变图像中的边缘,并通过计算召回率进行比较。(Chen et al., 2011)采用直方图分析进行边缘比较。这些指标提供了比PSNR和SSIM稍大的相关性。Liu等人(Liu et al., 2019)建议使用F1分数评估边缘保真度,但他们拒绝与其他指标进行比较,并对代码保密。我们的方法基于相同的边缘比较思想,但它对局部和全局的边缘偏移具有鲁棒性,这些边缘偏移在超分辨率时出现,但对细节识别是不必要的。它产生了比其他质量评估方法更好的结果。

-
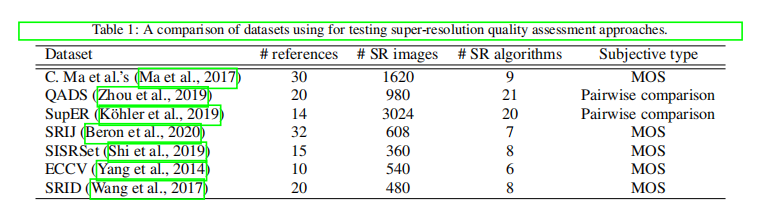
许多数据集被用于测试超分辨率质量评估(表1),但不用于细节恢复,因为它们缺少如图6(文本、数字、QR码、面孔、复杂纹理)所示的困难模式。因此,我们构建了一个用于评估超分辨率质量的数据集,其中包括用于细节恢复的最具挑战性的内容。
-
总结上述分析,很少有指标旨在评估和比较细节恢复质量。一些使用边缘特征的技术已经出现,但没有人将其用于涉及特殊伪影的超分辨率。因此,重要的是获得一个客观的指标,高度相关的人类细节恢复质量估计,并允许比较超分辨率模型,不仅是自然的,而且信息保真度。
PROPOSED METHOD
Dataset

为了分析VSR模型恢复真实细节的能力,我们构建了一个包含难以恢复的模式的测试台(图6)。为了计算特定内容类型的度量,并验证模型如何使用不同的输入来工作,我们通过检测叉将每个输出帧划分为部分:
第一部分“板”包括一些小物体和人脸的照片3。我们的目标是获得在纹理上运行的模型的结果。条纹织物和纱线球可产生摩尔色图案(图7)。人脸的恢复对视频监测很重要。
第2部分“QR”由多个不同大小的二维码组成;其目的是在模型的输出帧中找到最小的可识别码的大小。一个低分辨率的框架可能混合二维码模式,因此模型可能有不同的恢复它们。
第三部分“文本”包括两种类型:手写和打印。将所有这些困难的元素打包到训练数据集中是一个挑战,因此当模型试图恢复它们时,它们都是新的。
第4部分“金属纸”包含了被强烈揉皱的锡纸。这是一个有趣的例子,因为反射会在帧之间周期性地变化。
第5部分“彩色线”是一个带有许多细色条纹的印刷图像。这张图像是困难的,因为相似颜色的细线最终在低分辨率的帧中混合。
第6部分“车牌号码”由一套来自不同数量的不同大小的汽车车牌组成
我们使用佳能EOS 7D相机捕捉数据集。我们快速地拍摄了一系列100张照片,并将它们用作视频序列。这些镜头是在没有三脚架的情况下从一个固定的点拍摄的,所以视频中包含了少量的随机运动。我们将视频存储为从JPG转换而来的PNG格式的帧序列。相机的ISO设置为4000,光圈为400,分辨率为5184 3456。
源视频的分辨率也为5184 3456,并存储在sRGB颜色空间。我们使用双三次插值对其进行降级,生成分辨率为1920 1280的地面真值。这一步是必要的,因为许多开源模型缺乏处理大型框架的代码;处理大帧也很耗时。我们再次使用双三次插值,将输入视频从真实值进一步降低到480 320,以测试模型的4次升级。每个模型的输出也是一个帧序列,我们将其与地面真实序列进行比较,以验证模型的性能。
Subjective Comparison
我们在质量评估中使用了21种超分辨率算法。我们还添加了一个非常真实的视频,所以实验验证包括22个视频。我们将序列切割为30帧,并将其转换为每秒8帧(fps)。这个长度允许受试者很容易地考虑细节,并决定哪个视频更好。然后,我们从每个视频中裁剪出10段涵盖最困难的恢复模式,并使用Sujejtiff.us服务进行成对的主观评估,可以进行众包比较。
为了估计信息的保真度,我们要求参与者在主观比较中避免选择最漂亮的视频,而是选择一个显示更好的细节恢复的视频。参与者不是这一领域的专家,因此他们没有专业偏见。每个参与者都被展示了25对视频,在每种情况下都必须选择最好的视频(“无法区分”也是一个选择)。每对视频片段被展示给10-15名参与者,直到证据间隔停止改变。每个参与者有三对是为了验证,所以最终的结果排除了他们的答案。来自1400名成功参与者的所有其他回答都被用来预测使用布拉德利-特里的主观分数(布拉德利和特里,1952年)。
Edge Restoration Quality Assessment Method
基于边缘对细节恢复具有重要意义的假设,我们开发了边缘恢复质量评估(ERQA)度量,该度量估计了模型在高分辨率框架中恢复边缘的效果。我们的度量补偿了小的全局和局部边缘位移,假设它们不会使细节识别复杂化。

图8:从GT帧裁剪的内容部分板(左),以及该帧的边缘,用Canny算法(Canny, 1986)和选定的参数(右)突出显示。
首先,我们在输出帧和基本真值帧中都找到边。我们的方法使用了Canny算法的OpenCV实现5(Canny,1986)。初始识别强边的阈值为200,连接强边的阈值为100。这些系数允许我们突出所有对象的边缘,即使是小对象,而跳过不重要的线(图8)。
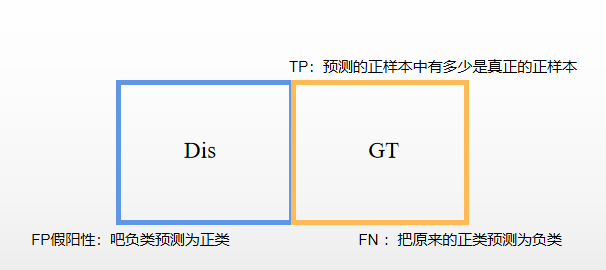
在找到地面真实和扭曲帧的边缘作为二进制掩模后,我们使用F1分数对它们进行比较:

其中TP(真阳性True Positive)是同时在GT帧和失真帧中检测到边缘的像素数,FP(假阳性)是仅在失真帧中检测到边缘的像素数,FN(假阴性)是仅在GT帧中检测到边缘的像素数(图9)。
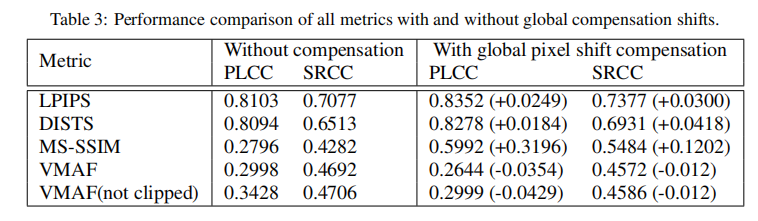
有些模型可以生成相对于ground truth有全局像素偏移的帧,因此我们检查整型像素沿两个轴的偏移[-3,3],并选择PSNR值最大的那一个。对这种全局变化的补偿大大有助于我们的度量(表4)。


图9:从升级比例upscaled frame的框架裁剪(左),从源框架裁剪(右)和ERQA度量的可视化(中心)。白色=真阳性,蓝色=假阴性,红色=假阳性。
在升级过程中,模型也可能在局部移动边缘像素,在许多情况下,这对人类对信息的感知无关紧要。为了补偿局部单像素边缘偏移,我们考虑输出边缘上的任何像素为真阳性,这些像素不在GT边缘上,但与GT的边缘接近(在一个像素的差值上)。
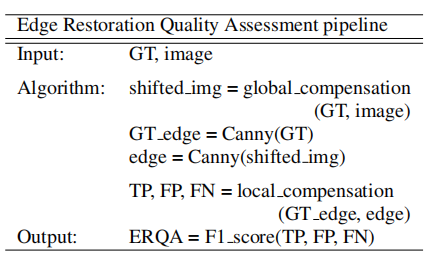
然后我们注意到,与地面真相相比,一些模型产生了更宽的边,并且我们的局部补偿方法(ERQAv1.0)将这些边标记为完全真阳性。为了纠正这个缺点,ERQAv1.1认为GT值边上的每个点只对应于真阳性一次。边缘修复质量评价方法的总体管线:
EXPERIMENTAL VALIDATION
Ablation Study
为了验证全局和局部的移位补偿的重要性,我们进行了基本的无补偿边缘比较,只有全局补偿,全局补偿,全局和局部补偿(v1.0),宽边补偿(v1.1)。所有药物均持续增加了PLCC和SRCC(表4)。
我们还与索贝尔、罗伯特(罗伯茨,1963年)和普雷威特(普威特,1970年)的运营商一起尝试了我们的补偿方案。虽然也有一些例外,但一般来说,ERQA在使用Canny算子时显示出更好的相关性。Canny算法的不同阈值给出了彼此之间具有高度相关性的指标。因此,为了避免过拟合,我们根据经验选择了其中的100和200,只突出重要的边缘。
我们还在QADS数据集上验证了我们的度量(Zhou等人,2019年)。尽管平均相关性低于其他一些指标,原因是这个数据集是为另一个测试用例(视觉感知)开发的。在某些情况下,低视觉感知的图像比高视觉感知的图像看起来更像原始图像。同时,使用更接近于我们的测试用例ERQA的图像会产生良好的结果。
Comparison with Other Metrics
我们对现有的视频质量评估指标进行了研究,发现有些指标在自然性和美感方面很好,但没有一个在修复方面很好。我们计算几个著名的指标一个新的数据集:PSNR, SSIM(王et al ., 2004), MS-SSIM(王et al ., 2003), VMAF6,最近开发了LPIPS (Zhang et al ., 2018),显示良好的结果在评估超分辨率成像,其改善区域(丁et al ., 2020 b)和SR评估指标(Ma et al ., 2017)。
我们的指标在PLCC和SRCC中都优于所有其他指标。LPIPS是第二。在这种情况下,视频质量评估的流行度量VMAF甚至比传统的SSIM表现出更差的结果。多尺度结构相似度(Multiscale structural similarity, MSSSIM)通常比简单结构相似度(simple structure similarity, SSIM)效果更好,在超分辨率上排名最后。
我们尝试了我们的全局移位补偿方案,试图改善这些指标的性能。结果几乎所有指标(除了VMAF)都更好(表3)。
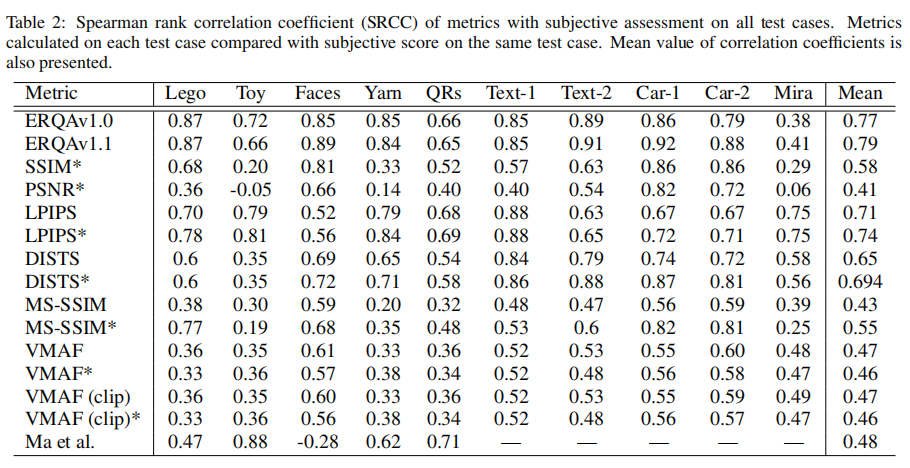
由于度量在不同的内容类型上有不同的作用,我们分别考虑度量值与对所有crops的主观评估的相关性,然后计算平均相关性。尽管它的结构简单而直接,但ERQA提供了与主观评估更一致的结果,并且在评估信息保真度时,在PLCC和SRCC(表2)系数中都优于所有其他指标。
CONCLUSION AND FUTURE WORK
在本文中,我们提出了一种新的全参考ERQA指标,用于评估视频超分辨率细节恢复。它比较了参考和目标视频中的边缘,分析了VSR模型恢复源结构和细节的效果如何。我们还创建了一个用于评估VSR质量的特殊数据集,并使用它通过主观比较来分析我们的指标。ERQA显示了与人类细节感知的高度相关性,与传统以及最先进的VQA方法相比,总体效果更好。结果表明,边缘恢复对人类细节感知恢复具有重要意义。我们的指标背后的概念允许它服务于类似的恢复任务,如去模糊、去交错和去噪。
[2019] Image Quality Assessment through Contour Detection

摘要
本文从图像分割的角度对客观图像质量评价进行了研究。而不是建模的图像失真或退化过程,评估是实现从最终用户的视角,即如何通过分割操作解释图像。 通过比较输入图像和参考图像的轮廓来评估图像中具有一定退化程度的信息特征的可及性。在等高线映射测度框架中,利用 F-measure 定义了一种新的质量指标。演示实验说明了该索引对所制备图像的工作原理,初步结果证明了所提方法的有效性
引言
客观评价视频和图像的质量对现代多媒体通信和应用具有重要意义。到目前为止,已经提出了许多图像质量指标,并将其集成以提高性能[1]。基本上,质量指标可以分为基于参考的方法和非基于参考的方法。基于参考的方法可以采用完整的参考模型或简化的参考模型进行质量评估[2]。其中最主要的质量指标是由Wang等人提出的结构相似度(SSIM)测度,该测度考虑了图像局部亮度、对比度和结构[3]、[4],该方法在各种应用中都证明了其有效性和效率。基于这一思想,人们提出了质量指标,但图像的退化是多种多样的,通用的指标在量化各种退化时往往存在局限性[5]。
图像质量对最终用户的直接影响是如何解释和理解图像。图像的糟糕表现会使识别和解释潜在的信息特征变得困难。计算机图像表示与人类图像理解[6]之间还存在着很大的差距。然而,文献[7][9]报道了通过量化信息特征进行质量评价的研究。有证据表明人类与基于算法的图像分割之间存在联系,基于算法的图像分割是一种低级的视觉操作,将图像分割为具有语义意义的区域[10]。显然,质量越好的图像分割结果越好,这意味着对图像[11],[12]的解释和理解越好。
在本文中,我们建议使用图像分割来量化图像中受一定退化影响的信息特征的可访问性。假设有完整的参考图像(ground truth image),在等高线映射度量(CMM)[13]框架下,对输入图像和参考图像进行分割,比较得到的等高线地图。利用CMM的精度和召回率定义新的质量指标S。
A C o u n t e r -b a s e d I n d e x
该算法利用图像局部亮度、颜色和纹理的差异来预测图像边界。它实际上实现了一个多尺度的线索组合过程,以获得每个像素的边界强度的度量。

Precision和recall框架被广泛用于评价分割算法的性能。对于算法边界A和ground-truth边界B,精确度§和召回率®分别定义为

其中CM(-)表示匹配两个边界上的点的方法,|.|表示边界的大小。
由于CM是一个相对值,因此定义索引是不合适的。因此,一旦得到P和R值,质量指标S可以简单地定义为 F-measure
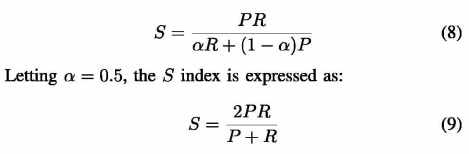
实验
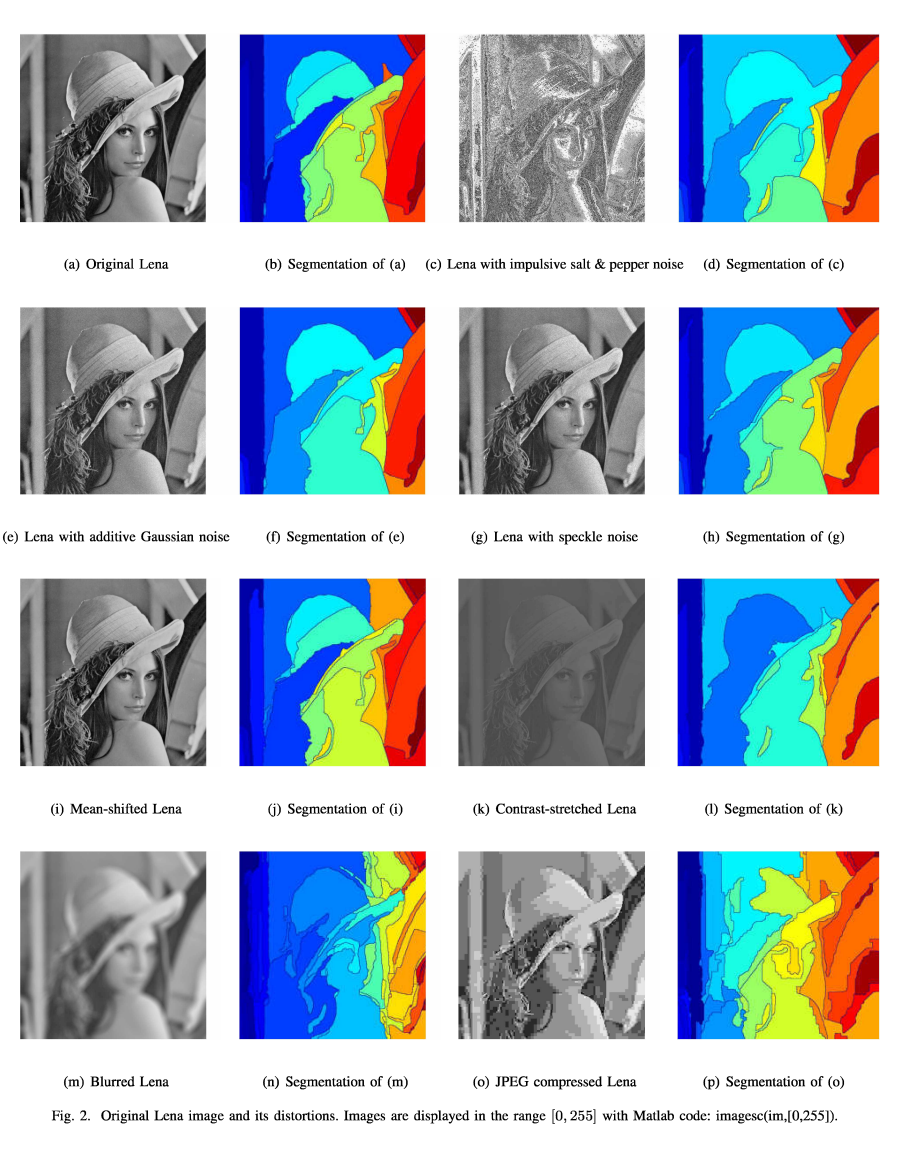
在实验中,我们考虑了退化的Lena图像,如图2所示。失真类型包括:脉冲椒盐噪声、加性高斯噪声、乘性散斑噪声、均值漂移、对比度拉伸、模糊和JPEG压缩。除图2(i)外的退化图像都准备具有相似的SSIM值。均值偏移仍在区间[0,255]内。因此,SSIM索引识别出与原始Lena图像质量相似的图像。按照II步骤,计算等高线映射量和S指标,列于表I。
提出的S指数表明,均值平移图像(mean-shifted image)的质量是最好的,我们将在后面讨论这一点。对于右侧的伴生图像,我们可以大致看到轮廓和退化图像的分割方法。质量指数S反映了退化对分割过程的影响。对于斑点,盐和amp;辣椒噪声和加性高斯噪声时,SSIM值在0.0003和0.0005处存在一些不易察觉的差异。然而,等高线映射度量(CMM)和S指数都突出了这种差异。CMM值未归一化,不宜作为指标,但为支持质量指标S提供了证据,对应的S值差值分别为0.232和0.0380。相比之下,S指数对对比度拉伸、模糊和压缩操作更加敏感。相对于模糊和压缩,当SSIM对它们几乎同等对待时,它更倾向于对比度的拉伸。我们还观察到压缩后的图像在索引S上比模糊图像有更好的质量。
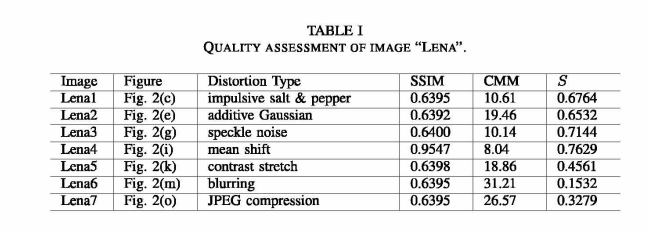
从图3的precision-recall图中可以看出,高的precision对应低的误报率,高的recall对应低的假阳率(false positive)。对于斑点,盐和amp;胡椒和加性高斯噪声时,检测到的轮廓具有可比较的召回值,但其精度会发生变化,即假阳性,从而导致S (F)值的最终差异。该图显示了经过其余三次操作的Lena图像之间的明显差异。
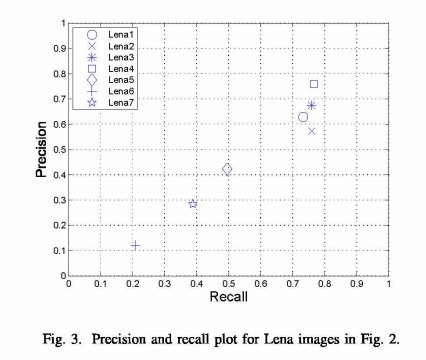
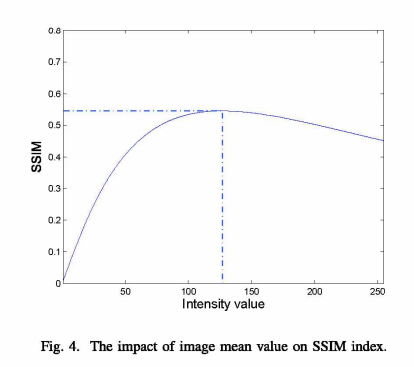
图2(i)中经过平移后的图像,其均值为99,而原始Lena图像的均值为122。为了观察均值的影响,我们计算了SSIM指数在1 - 255范围内,Lena与强度值一致的图像,即无任何内容的平面图像之间。SSIM曲线如图4所示。图中显示,当平均值为127时,达到最大SSIM值0.5450。均值122对应的SSIM值为0.5447,接近最大值。然而,这些值对于图像质量是没有意义的。SSIM指数不起作用,但我们可以看到平均值如何影响SSIM指数
回顾[4]中的Lena图像,再次应用S索引,得到表2中的结果。我们注意到[4]中所有的Lena图像都具有相同的均方误差(MSE),而SSIM指数可以区分这些差异。S指数对噪声污染图像的判断是一致的,但对其他类型的退化图像的判断是不同的。它更喜欢JPEG压缩,而不是模糊操作。同样,这种差异也反映在图5的精确回忆图中。均值偏移图像和对比度拉伸图像在精度和召回值方面具有相似的质量。
C o n c l u d i n g R e m a r k s
提出了一种基于图像分割和轮廓映射的图像质量指标。与传统的SSIM指标相比,该指标为图像质量评价提供了不同的视角。本研究采用gPb-ucm算法获取输入图像的边缘强度图。在精确召回框架中使用强度映射来定义图像质量索引。初步结果证明了新指标的有效性。将进行广泛的实验,以进一步验证所提出的索引与目前可用于图像质量评估研究的主要数据集。此外,边缘强度图可以直接用于未来工作中的相似度评估。
目前,所有索引都使用单个值来表示图像质量。然而,图像质量评价实际上是一种多属性现象。**虽然一个整体的质量指数是方便的,它仍然是值得怀疑的两个图像经过不同的退化相同的质量。**因此,建议采用多通道或多属性评价,而综合/融合指标可以对所有通道或属性进行综合。未来的研究还可以考虑在图像质量评估中识别和评估退化过程。详细的信息将有利于最终用户对图像质量进行索引。
[2021] (CVPR) Neural Side-By-Side: Predicting Human Preferences for No-Reference Super-Resolution Evaluation

摘要
基于深度卷积网络的超分辨率算法目前受到学术界和产业界的广泛关注。但是,由于缺乏适当的评价措施,很难对各种方法进行比较,阻碍了该领域的进展。传统的测量方法,如PSNR或SSIM,与人类对图像质量的感知相关性很差。因此,在现有的作品中,常见的做法也是报告人类对超分辨率图像的评价结果Mean-Opinion-Score (MOS)。不幸的是,不同论文的MOS值并不能直接进行比较,因为评价者的数量不同,他们的主观性等原因。在本文中,我们引入了神经并行(Neural Side-By-Side)这一新的度量方法,允许超分辨率模型自动进行比较,有效地逼近人类偏好。即,我们收集了一个由不同的超分辨率模型产生的对齐图像对的大数据集。然后,每对作品都由几位评价者进行注释,评价者被要求选择一张视觉上更吸引人的图片。在给定数据集和标签的情况下,我们训练了一个CNN模型,该模型获得了一对图像,并且对每一张图像预测出比对应图像更可取的概率。在这项工作中,我们表明,神经并排泛化跨越新模型和新数据。因此,它可以作为人类偏好的自然近似,可以用于比较模型或在没有评分者帮助的情况下调优超参数。我们开放数据集和预训练模型1,并期望它将成为研究人员和实践者的方便工具。
视频评价[2022] Learning Generalized Spatial-Temporal Deep Feature Representation for No-Reference Video Quality Assessment
Abstract
在这项工作中,我们提出了一种无参考的视频质量评估方法,旨在实现跨内容、分辨率和帧率质量预测的高泛化能力。特别地,我们通过学习在时空域的有效特征表示来评估视频的质量。在空间领域,为了解决分辨率和内容的变化,我们对质量特征施加高斯分布约束。统一的分布可以显著减少不同视频样本之间的域差距,从而得到更广义的质量特征表示。在时间维度上,受视觉感知机制的启发,我们提出了一个包含短时记忆和长时记忆的金字塔时间聚合模块来聚合帧级质量。实验表明,我们的方法在跨数据集设置上优于最新的方法,在数据集内配置上也取得了相当的性能,证明了本文方法的高泛化能力。
INTRODUCTION
-
随着视频数据的指数增长,对准确预测视频质量的需求越来越大。在视频大数据背景下,单纯依靠人类视觉系统进行及时的质量评估变得极其困难和昂贵。因此,客观视频质量评估(VQA)的目标是设计自动的计算模型而准确预测感知到的视频质量,已经变得越来越突出。根据原始参考视频可用性的应用场景,视频质量评估可分为全参考VQA (FR-VQA)、缩减参考VQA (RR-VQA)和无参考VQA (NR-VQA)。尽管取得了显著的进展,但现实世界视频的NR-VQA,由于其高度的实用性而受到极大的关注,仍然是非常具有挑战性的,特别是当视频需要使用不同的设备、环境和算法进行获取、处理和压缩时。
-
对于NR-VQA,文献中已经提出了很多方法,其中大部分都是基于带标记数据的质量预测模型训练的机器学习流水线。基于手工特征[1][4]和深度学习特征[5][8]的方法已经开发出来,假设训练和测试数据来自紧密对齐的特征空间。然而,人们普遍认为,训练数据和测试数据的不同分布会产生泛化能力差的风险,因此,与训练集中的数据相比,统计数据差异很大的视频可能会得到不准确的预测。提出的VQA方法的基本设计原则是学习具有高泛化能力的特征,这样模型就能够提供高质量的视频预测精度,而不是从训练数据的领域采样。当测试数据未知时,该很好的符合实际应用场景。为了验证我们的方法的性能,我们使用可用的数据库在四种跨数据集设置上进行实验,包括KoNViD-1k[9]、LIVE-Qualcomm[10]、LIVE-VQC[11]和CVD2014[12]。实验结果表明,我们的方法比现有的最先进的模型具有显著的优势。本文的主要贡献如下:
-
我们提出了一个客观的NR-VQA模型,能够自动访问由不同的采集、处理和压缩技术产生的视频的感知质量。所提出的模型由专门表征质量的学习特征驱动,能够为与训练数据相比具有显著不同特征的视频提供较高的预测精度
-
在空间领域,我们开发了一种多尺度特征提取方案,探索不同尺度的质量特征,并进一步加入注意模块,自适应加权特征的重要性。我们进一步统一每一帧的质量特征与高斯分布,其中分布的均值和方差是可学习的。因此,通过归一化操作,可以进一步减小不同视频样本由于内容类型和失真类型造成的域间隙。
-
在时间域,提出了金字塔时间池化层来解决时间域内的质量聚集问题。金字塔时态池化可以使时间池化独立于输入视频的帧数,并以金字塔的方式聚合视频的短期和长期质量水平,进一步增强了所提模型的泛化能力。
RELATED WORKS
No-Reference Video Quality Assessment
最近,大量的工作致力于VQA,特别是量化压缩和传输伪影。Manasa等人[31]基于光流统计量开发了NR-VQA模型。特别地,为了捕捉失真对光流的影响,量化了光流在patch级和帧级的统计不规则性,并进一步结合SVR来预测感知视频质量。Li等[32]开发了一种结合3D shearlet变换和深度学习的NR-VQA来汇集质量分数。视频多任务端到端优化神经网络(V-MEON)[5]是一种基于三维卷积层特征提取的NR-VQA技术。这种时空特征可以带来更好的预测性能。Korhonen等人[33]从全视频序列中提取提取了低复杂度特征(LCF),从关键帧中提取高复杂度特征(HCF),然后使用SVR预测视频得分。Vega等人[34]重点研究了视频流设置的丢包效应,并在视频服务器(离线)和客户端(实时)使用了一种基于无监督学习的模型。在[35]中,Li等人将内容和时间记忆结合到nrvqa模型中,并使用门控循环单元(GRU)进行长期时间特征提取。为了将运动感知融入到VQA任务中,[36]中提出了一种递归网络(RIRNet)。在RIRNet中,可以有效地融合来自不同时间频率的运动信息。You等[37]使用3D卷积网络从视频中的小片段中提取局部时空特征。这不仅解决了训练数据不足的问题,而且可以有效地捕获感知质量特征,最后输入LSTM网络预测感知视频质量。
== Domain Generalization==
VQA问题还存在标注训练数据(源域)与未标注测试数据(目标域)之间的域差距,导致标注数据中的训练模型难以很好地泛化到未标注数据上。这些特征差距可能源于不同的分辨率、场景、采集设备/条件和处理/压缩工件。在过去的几年里,人们通过学习域不变表示[38][43]来解决域泛化问题,并取得了很好的结果。在[44]中,提出了典型相关分析(Canonical Correlation Analysis, CCA)来学习域之间的共享信息。Muandet等人[38]提出利用域不变成分分析(DICA)来最小化域之间的分布不匹配。在[45]中,Carlucci等人通过对图像补丁进行洗牌来学习广义表示,[46]进一步扩展了这一思想,将跨多个源域的样本进行混合,用于异构域的泛化任务。对抗性训练的泛化[47]、[48]也得到了广泛的研究。例如,Li等人[49]提出了MMD- aae模型,该模型通过施加最大平均偏差(MMD)措施来调整不同域之间的分布,扩展了对抗式自动编码器。在我们的工作中,由于样本复杂度[50]和不受控条件(场景、失真类型、运动、分辨率等),我们没有训练领域分类器,而是通过对抗性训练进一步规范学习到的特征,使其遵循高斯分布,缩小学习到的跨领域特征不匹配。
THE PROPOSED SCHEME
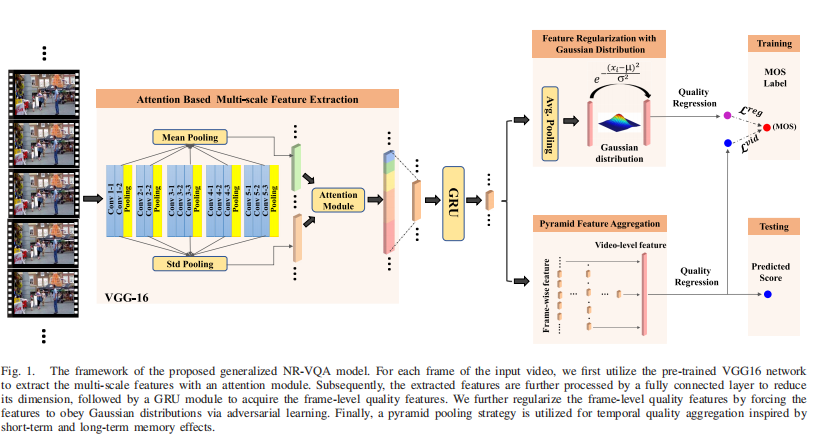
图1所示。提出的广义NR-VQA模型的框架。对于输入视频的每一帧,我们首先利用预先训练好的VGG16网络,利用注意力模块提取多尺度特征。然后通过全连通层对提取的特征进行降维处理,再通过GRU模块获取帧级质量特征。我们通过对抗性学习迫使特征服从高斯分布来进一步规范帧级质量特征。最后,利用金字塔池化策略进行由短期和长期记忆效应引起的时间质量聚集。
我们的目标是学习一个具有高泛化能力的NR-VQA模型,用于实际应用。一般来说,控制VQA泛化能力的三个内在属性是:空间分辨率、帧率和视频内容(如捕获的场景和失真类型)。如图1所示,我们首先利用预训练的VGG16模型[51]提取帧级质量特征,这是因为反复证明这些特征能够可靠地反映视觉质量[25],[35],[52],[53]。将对不同空间分辨率的泛化能力编码为特征表示,利用统计池化矩,将五个卷积阶段(从顶层到底层)的特征结合通道注意力进行聚合。为了进一步增强对不可见域的泛化能力,通过将学习到的质量特征规整为一个统一的分布,盲目(blindly)补偿源和目标域之间较大的分布差距。在时间域,进一步提出了金字塔聚合模块,最终得到质量特征用于质量预测。
== A. Attention Based Multi-Scale Feature Extraction==
本文基于预训练的VGG ConvNets,获得了对单帧空间分辨率具有较强泛化能力的特征表示。众所周知,池化矩决定了特征的可鉴别性,我们采用了公认的基于均值和标准差的池化策略。特别是对于第i帧,假设第s阶段(s{1,2,3,4,5})输出特征的平均池化和std池化结果分别为M_si和D_si,将每一阶段的池化特征进行级联,即可得到多尺度质量表征:
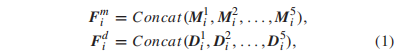
其中Fmi和Fdi代表框架i的多尺度均值特征和std特征。然而,由于Fmi与语义信息[54]的高度相关性,直接将这两个集合特征连接起来进行质量回归可能是不可行的。因此,学习到的模型往往过于适合训练集中的特定场景。在这里,Fmi并没有被丢弃,如图2所示,而是被视为具有语义意义的特征,作为基于注意力的多尺度特征提取的组成部分。具体来说,对于T帧,给定[Fm1,Fm2,…],FmT 1,FmT],我们首先计算每个通道沿时间维度的标准差,如下所示
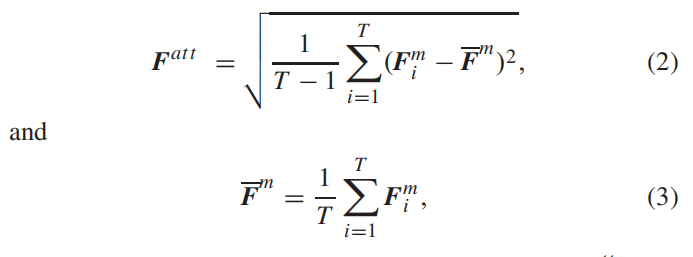
其中框架索引记为i。给定Fatt,学习两个全连接层来实现注意机制,如图2
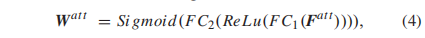
式中FC1(·)和FC2(·)表示两个全连接层。其基本原理是每个信道( channel )的注意权取决于相应的时域方差, 而时域方差与视频内容的变化高度相关。因此,这种具有spatial mean and temporal std的嵌套池可以通过将空间和时间变化逐步编码为一个全局描述符来提供注意力地图。然后由Fdi及其注意权重可以得到框架特定的质量表征Fqi如下:
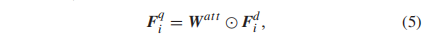
其中““表示 element wise的乘法
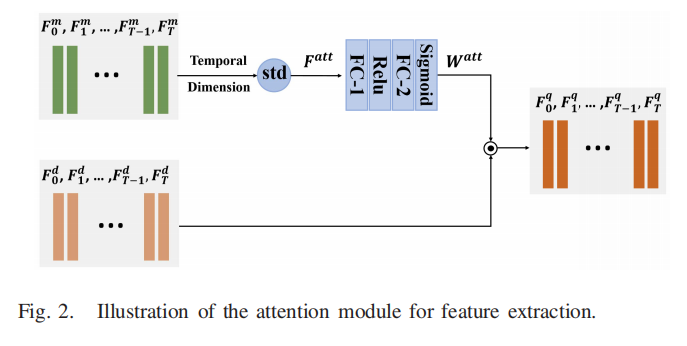
== B. Feature Regularization With Gaussian Distribution==
在帧级质量特征Fqi的基础上,利用门控循环单元(GRU)[55]层通过引入时间信息来细化(refine)帧级特征。特别地,我们使用全连接层(FC3)来减少VGG特征的冗余,然后由GRU层处理生成的特征
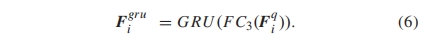
然而,我们认为Fgru i对于不同的场景和失真类型还不够一般化(still not generalized enough)。为了提高Fgru i的泛化能力,我们采用特征正则化,希望学习到分布统一的质量特征。推广到一个不可见域的基本假设是存在一个离散属性将数据分成不同的域。然而,VQA的naïve扩展可能会被用于领域分类的许多离散或连续属性(例如,场景、失真类型、运动、分辨率)所混淆。因此,我们没有将数据划分到不同的域,而是通过GAN模型限制帧级特征服从混合高斯分布,而且假设的高斯分布的均值和方差也可以自适应学习。如图1所示,我们首先对提取的每一帧的Fgru进行平均,如下所示:
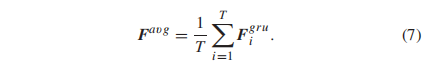
在此,我们将特征Favg提取器作为GAN模型的发生器G(·),并从先验高斯分布中采样相同的维向量(记为Fgaus)作为参考。然后判别器D(·)尝试将生成的特征从采样的向量中区分出来。GAN模型通过以下对抗性损失进行训练:
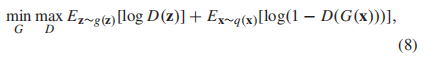
其中z是采样自高斯分布g(x)的向量Fgaus, x是输入视频,G(x)生成特征Favg。当网络在前N个时刻训练时,我们约束g(x)为平均μ = 0,方差σ = 1的标准高斯分布。然而,这就增加了一个很强的约束条件,即各维特征具有相同均值和方差的高斯分布。一般来说,特征的每个维度都被期望代表一个质量推断的感知相关性属性,这样它们最终遵循由不同的μ和σ参数化的不同高斯分布。这促使我们通过学习来适应每个维数的先验高斯分布的均值和方差。更具体地说,为了学习参数μ=[μ1,μ2,…,μL]和σ=[σ1,σ2,…,σL],其中L是Favg的维数,我们对Favg施加约束以回归质量分数
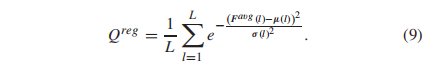
这里,我们使用Qreg来表示输入视频的预测质量分数,我们的目标是通过学习最优μ和σ,将Qreg回归到地面真实均值意见分数(MOS)。l表示第l维。在网络训练过程中,每N个epochs后,我们用学习过的μ和σ的高斯分布来代替前N个纪的分布。实验结果还表明,与标准高斯分布相比,这种自适应刷新机制可以进一步提高模型的性能。
== C. Pyramid Feature Aggregation==
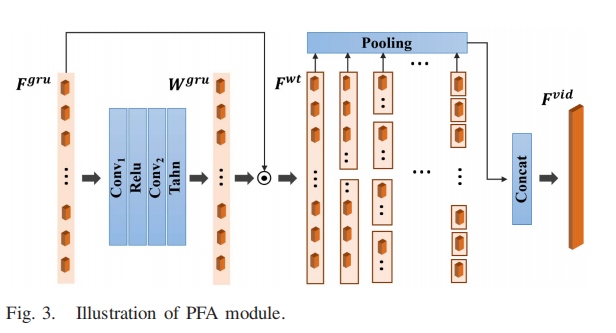
时域聚合在客观VQA模型中起着不可或缺的作用。我们考虑视觉质量知觉的两种认知机制[56]和[57]。短期记忆效应说服我们考虑每个局部化时间段的视频质量,因为我们的共识是,受试者在观看视频时倾向于保持一致的质量。此外,长期记忆效应表明,以粗到细的方式对整个视频序列进行全局池化可能会导致最终的视频质量。因此,我们使用金字塔特征聚合(PFA)策略来模拟这种感知机制。该算法融合了短时记忆和长时记忆,聚合结果与帧数无关。更具体地说,如图3所示,在金字塔的底层,对于Fgru,我们通过将其与周围的k帧综合计算其权重Wgru
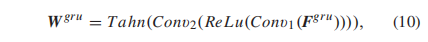
其中Conv1(·)和Conv2(·)是两个1d - cnn,它们的内核大小都设置为2k + 1。其中,Tahn(·)和Relu(·)为激活函数,Tahn(·)定义如下
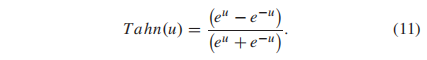
然后得到加权帧级质量特征Fwt
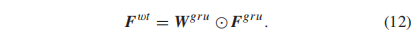
然后,沿着时间维度的加权框架级特征以金字塔的方式聚合。一般来说,是时间维度上的可感知性确定由层数控制的采样密度。在这里,我们根据经验将层数设置为常数7。具体来说,对于第m层(m∈{1,2,3…,7}),加权帧级特征被聚合成一个维度为h×2^m−1的向量,其中h表示Fgrui中的特征维度。换句话说,将视频平均划分为2m−1个时隙,在每个时隙内进行平均特征池进行聚合。最后,我们将所有层的聚合特征连接起来,从而得到一个与帧数和帧率无关的视频级质量特征,Fvid∈Rh×(2m−1)。我们首先应用一个全连接层(FC4)将信道从h减少到1,然后采用另一个全连接层(FC5)来合成金字塔聚合特征。因此,输入视频的质量可以预测如下
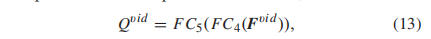
其中Qvid为预测得分。通过合并时间维度上的变化,该策略比单层聚合提供了更大的灵活性。
== D. Objective Loss Function==
最后的损失函数包括Eqn.9中得到的帧级和视频级质量回归结果和Eqn(13),以及基于分布的特征正则化
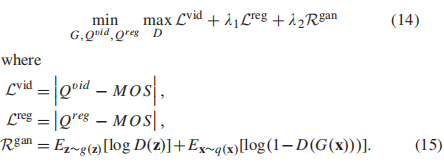
其中,λ1和λ2是两个权衡参数。在测试阶段,我们使用Qvid作为模型预测的最终质量分数。
EXPERIMENTAL RESULTS
== Experimental Setups==
实现细节:我们通过PyTorch[63]实现我们的模型。在表I和图5中,我们详细说明了分层网络,我们提出的方法。特别地,我们保留每帧的原始大小作为输入,而不进行调整大小操作。VGG-16网络在ImageNet[64]上进行预训练,训练时对其参数进行修正。训练阶段的批大小为128。特别地,我们将128个视频的预先提取的深度特征批量输入到我们的模型中。模型是端到端训练,以每个视频的MOS作为回归的标签。我们采用Adam optimizer进行优化,学习速率固定为1e-4。Eqn14中的加权参数λ1, λ2分别设为0.5和0.05。我们以对抗性的方式训练我们的模型,生成器和鉴别器交替学习。特别地,对于每一批,我们首先通过最大化Rgan loss和保持住我们模型的其他部件(generator)来训练鉴别器。然后通过最小化Lvid、Lreg和鉴别器的loss来维护鉴别器和更新发生器。
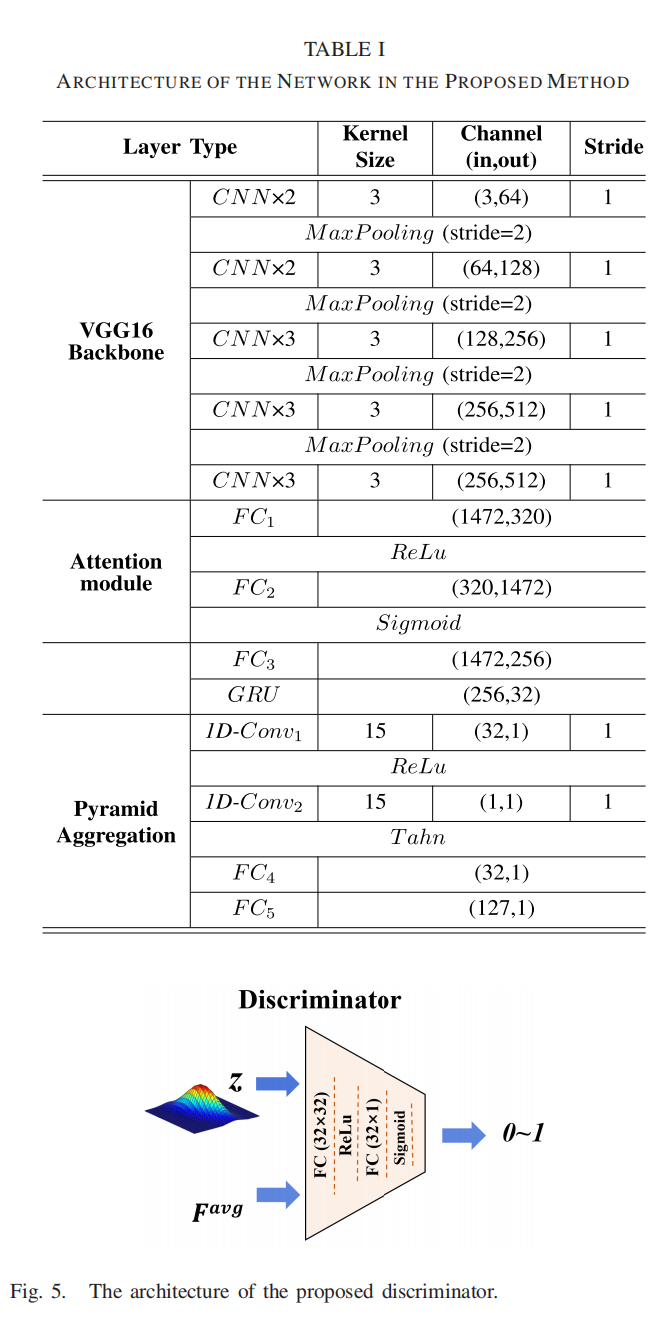
在跨数据集和数据集内的实验中,我们将最大epoch确定为200,并使用最后的第200epoch学习的模型进行测试。对于每20个epoch (N = 20),我们更新Eqn8中预定义分布g(x)的均值和方差。值得一提的是,所有的实验设置(超参数和学习策略)都是固定的。本文报道了5个评价指标,包括:Spearman秩次相关系数(SROCC)、Kendall秩次相关系数(KROCC)、Pearson线性相关系数(PLCC)、均方根误差(RMSE)和感知加权秩次相关(PWRC)[65]。特别是,PWRC奖励了对高质量图像进行正确排序的能力,抑制了对不敏感排序错误的关注,这被证实在推荐感知偏好的IQA/VQA模型时更加可靠。
如[66]所述,在计算PLCC和RMSE之前,通过非线性逻辑映射函数传递预测的质量分数 s
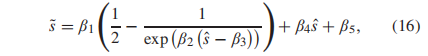
β1 β5是要拟合的回归参数
== B. Quality Prediction Performance==
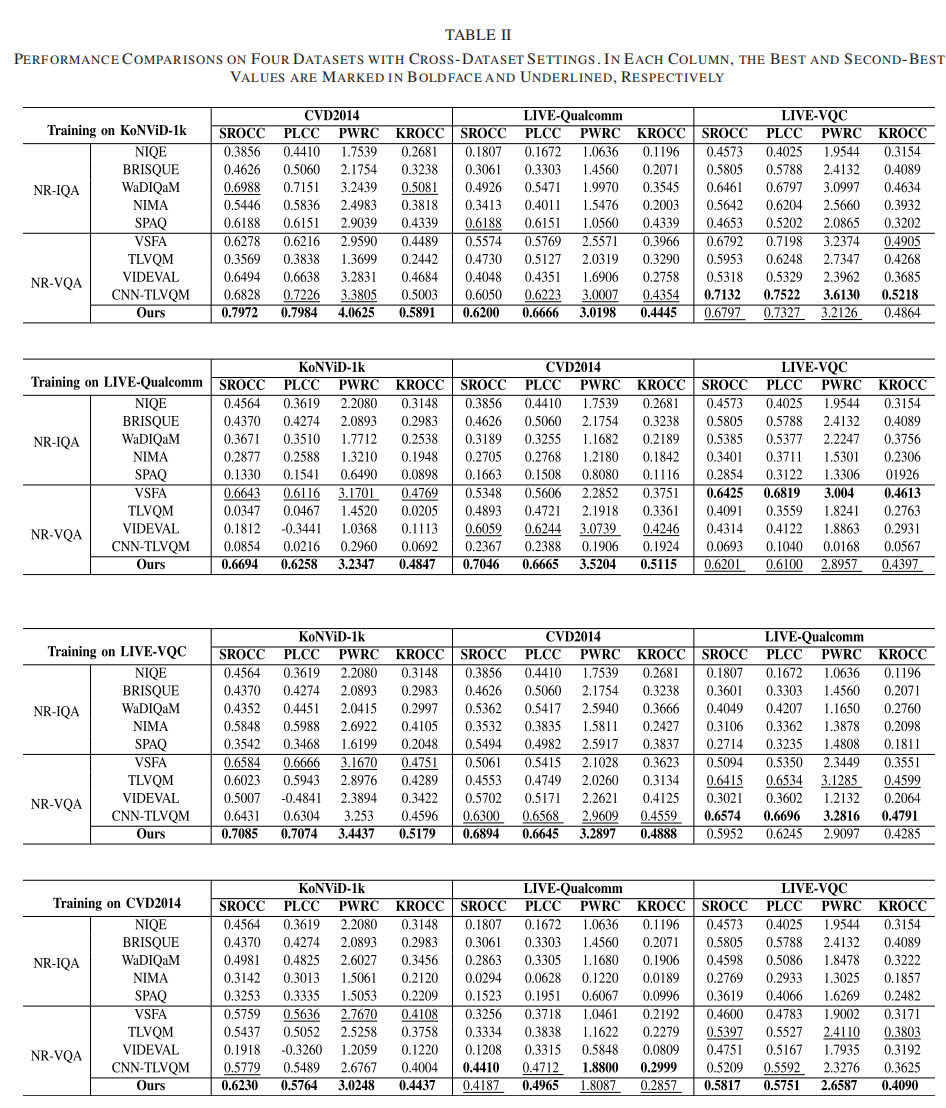
在本节中,我们将使用四种不同的跨数据集设置来评估我们的方法的性能,以验证泛化能力。我们将本文方法与包括NIQE[67]、BRISQ[2]、WaDIQaM[30]、NIMA[27]、SPAQ[7]在内的NR-VQA方法(包括VSFA[35]、TLVQM[33]、VIDEVAL[1]和CNNTLVQM[68])进行了比较。
在每个设置中,模型在一个数据集上训练,在其他三个数据集上测试。对于基于深度学习的NR-IQA模型,我们在训练集中提取每个视频每秒2帧,视频的MOS作为提取帧的质量分数进行模型训练。结果如表2所示,我们的方法在所有单独的跨数据集设置上都能取得最好的性能,这表明我们的方法具有优越的泛化能力。与NR-VQA方法相比,我们可以观察到NR-IQA方法在丢弃时间信息时整体性能并不理想。然而,即使是基于VQA的方法也不能在这种具有挑战性的设置中获得非常有前途的性能。例如,当方法VIDEV在LIVE-Qua数据集上训练时,SROCC在CVD2014数据集上的测试结果为0.6059,而在KoNViD-1k数据集上的测试结果明显下降到0.1812,进一步说明了两个数据集之间的领域差距很大。如表二所示,对CVD2014数据集的训练和对其他三个数据集的交叉测试是最具挑战性的设置,因为CVD2014只涉及234个视频和5个场景。有限的数据导致过拟合问题。然而,我们的方法仍然领先于第二好的方法VSFA,显示了我们的方法的鲁棒性和有希望的泛化能力
此外,我们还提供了我们的特征正则化模块的性能(也称为输出的Eqn(9))。与特性聚合模块的比较结果如表三所示。从表中我们可以看到,特征聚合模块的平均值(SROCC和PLCC)在所有跨数据集设置上都优于特征正则化模块,表明特征聚合具有更高的泛化能力。然而,平均帧级特征也可以提供输入视频的全局质量估计。因此,我们进一步融合方程(9)和(13)的输出(分别为Qreg和Qvid),其权值由λ设置为
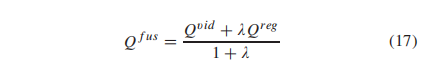
我们将λ设置为0.0 - 1.8,实验结果如表4所示。从表中,我们可以发现,当λ设置为0.4左右时,可以获得更高的整体性能。这一现象表明,通过平均池化获得的全局质量信息的组合最终有利于泛化能力的提高。

== C. Quality Prediction Performance on Intra-Dataset==
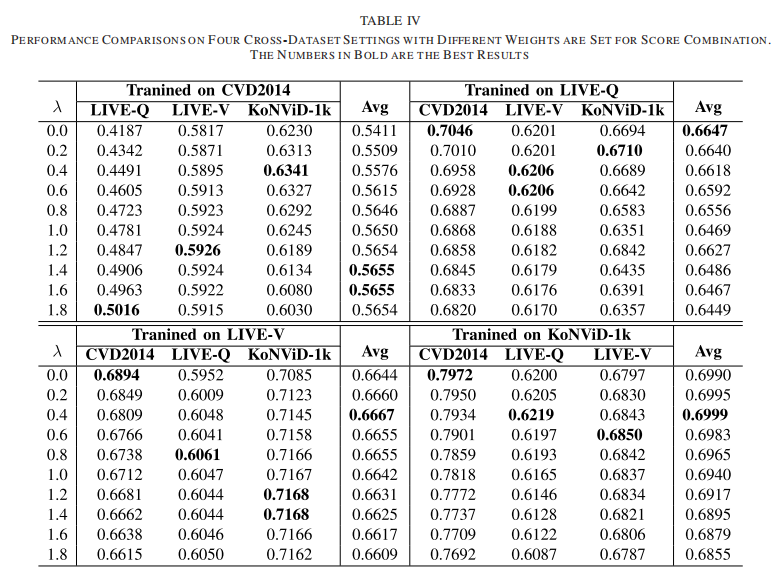
在本小节中,为了进一步验证我们的方法的有效性,我们在三个内部数据集上评估了我们的方法,包括LIVE-Qualcomm, KoNViD-1k和CVD2014。我们将提出的方法与NIQE[67]、BRISQ[2]、CORNIA[69]、video[4]、VIDEVAL[1]、VSFA[35]和CNN-TLVQM[68]等7种现有方法进行了比较。更具体地说,对于每个数据集,80%和20%的数据分别用于培训和测试。这个过程重复10次和性能的平均值和标准偏差值在表诉从表V,我们可以观察到,我们的方法可以实现次优性能方面的总体性能预测单调性(SROCC KROCC)和预测精度(PLCC (RMSE)。特别是对于LIVE-Qualcomm数据集和KoNVid-1k数据集,我们的方法取得了可与目前最先进的方法CNN-TLVQM相媲美的次优性能,并且比其他方法有较大的增益。这一现象表明我们的方法可以在不牺牲数据集内性能的情况下,拥有优越的泛化能力
== D. Ablation Study==
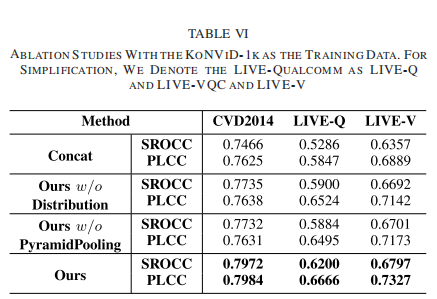
在本节中,为了揭示所提出方法中不同模块的功能,我们进行了烧蚀分析。实验采用跨数据集设置(在KoNViD-1k上训练,在其他三个数据集上测试)。如表六所示,性能按SROCC和PLCC提供。为了识别注意模块在多尺度特征提取中的有效性,我们在不进行注意的情况下直接将均值和标准池化特征连接起来,并维护其余部分进行训练。该模型在表VI中表示为Concat,在表VI中我们可以看到,所有测试集的性能都下降了,尤其是在LIVE-Qualcomm数据集上。在去除金字塔轮询模块时也可以观察到类似的现象(表VI中称our w/o PymidPooling)。原因在于LIVE-Qualcomm数据集中的视频挑战了人类实验对象和客观VQA模型,如[10]。像这样需要在空间和时间领域进行更专门的设计。此外,我们从原始模型中去掉高斯分布正则化模块,得到我们的w/o分布模型。从结果中我们可以发现,与我们的原始方法相比,SROCC和PLCC都是退化的,这表明特征空间上的正则化对于广义VQA模型也是重要的。
== E. Visualization==

为了更好地理解在我们提出的方法中学习到的质量相关特征,我们在一个特定的数据集上训练我们的模型,并可视化四个数据集的所有视频的质量特征。更具体地说,对于每个视频,我们首先提取它的特征Favg(如Eqn8所示分别有/没有基于高斯分布的正则化生成。随后,通过T-SNE[70]将特征维度降为2,如图6所示。我们对KoNViD-1k数据集特别感兴趣,因为它提供了大量具有不同质量级别的视频。如图6所示,我们可以发现,KoNViD-1k数据集和其他三个数据集的特征在正则化后更加紧凑。更具体地说,当模型在CVD2014数据集上训练时,与训练的模型相比,KoNViD-1k数据集与其他三个数据集之间的领域差距更大,进一步验证了基于高斯分布的正则化模块的有效性。
此外,为了验证高斯分布是否从Favg中每个维度的初始标准分布(mean μ = 0, variance σ = 1)更新,我们还通过四个跨数据集测试绘制了图7中最终的均值和方差值。我们可以观察到每个特征维度的分布是完全不同的。例如,当模型在LIVE-VQC数据集上训练时,第30维的方差是第17维的近1.4倍,这进一步揭示了视频的质量是由不同敏感维的特征决定的。

CONCLUSION
在本文中,我们提出了一种NR-VQA方法,旨在提高训练和测试视频具有不同内容、分辨率和帧率时质量评估模型的泛化能力。该方法基于统一分布约束和金字塔时态聚合的特征学习,在跨数据集和数据集内都得到了验证。该模型可从多个角度进行扩展。例如,该模型可以进一步应用于原始参考视频不可用时的优化任务。此外,该设计理念还可以进一步应用于其他领域(如高动态范围、屏幕内容、虚拟现实)。
[2022] (CVPRW) Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network

摘要
图像质量评估(IQA)算法旨在量化人类对图像质量的感知。不幸的是,当评估具有看似真实纹理的生成式对抗网络(GAN)生成的失真图像时,性能会下降。在本工作中,我们推测这种不适应在于IQA模型的主干,其中补丁级预测方法使用独立的图像斑块作为输入,分别计算它们的分数,但缺乏图像斑块之间的空间关系建模。因此,我们提出了一种基于注意力的混合图像质量评估网络(AHIQ)来应对这一挑战,并在基于gan的IQA任务上获得更好的性能。首先,我们采用了一个双分支结构,包括一个视觉变压器(ViT)分支和一个卷积神经网络(CNN)分支进行特征提取。该混合结构结合了ViT捕获的图像补丁之间的交互信息和CNN的局部纹理细节。为了使浅层CNN的特征更集中在视觉显著区域,利用ViT分支的语义信息进行变形卷积。最后,我们使用 patch-wise评分预测模块来获得最终评分。实验表明,我们的模型在四个标准IQA数据集上优于最先进的方法,AHIQ在NTIRE 2022感知图像质量评估挑战赛的全参考(FR)轨道上排名第一。
引言
-
图像质量已经成为大多数图像处理应用中的关键评价指标,包括图像去噪、图像超分辨率、压缩伪影抑制等。直接从人类观察者那里获取感知质量分数是准确的。然而,这需要耗时和昂贵的主观实验。图像质量评估(IQA)的目的是让计算机模拟人类视觉系统(HVS),通过算法对图像的感知质量进行评分。在这种情况下,要评估的图像往往在压缩、获取和后处理过程中退化。
-
近年来,生成对抗网络(GANs)[12]的发明极大地提高了图像处理能力,尤其是图像生成[14,46]和图像恢复[41],同时也给图像质量评估带来了新的挑战。基于gan的方法可以制造看似真实但虚假的细节和纹理[17]。在纹理密集的区域,HVS很难分辨边缘的错位和纹理下降(the misalignment of the edges and texture decreases)。只要纹理的语义相似,HVS就会忽略部分纹理的细微差异。传统失真图像的IQA方法大多通过像素级的比较来评估图像质量,这将导致gan生成的图像[43]被低估。为了处理纹理不对齐问题,近年来的研究引入了逐斑块预测方法。随后的一些研究[17,33]进一步对基于cnn的IQA网络提出了不同的空间鲁棒性比较操作。但是他们将每个patch作为一个独立的输入,分别计算它们的得分和权重,这样会导致context information的丢失,无法对patch之间的关系建模。
-
因此,在patch-level比较的基础上,我们需要更好地对patch之间的相互关系建模。为此,我们使用Vision Transformer (ViT)[11]作为特征提取器,该特征提取器可以通过多头注意机制有效地捕获补丁之间的远程依赖关系。然而,vanilla ViT在进入网络之前使用一个大的卷积核在空间维度上对输入图像进行下采样;一些应该考虑的细节丢失,这也是至关重要的图像质量评估。通过观察,我们发现浅层CNN是提供详细空间信息的好选择。浅层CNN提取的特征中含有不需要的噪声,将ViT特征与之合并会降低性能。为了减轻噪声的影响,我们提出模拟HVS的特点,即人类始终关注图像的显著区域。我们没有将浅层CNN的完整特征注入到ViT的特征中,而是只使用那些传达显著区域空间细节的特征来评估图像质量,从而缓解了前面提到的噪声。此外,使用最大池化或平均池化来直接预测图像的评分会丢失关键信息。因此,我们使用一种自适应加权策略来预测图像的分数。
-
在这项工作中,我们引入了一种有效的混合架构的图像质量评估,利用浅层CNN的局部细节和ViT捕获的全局语义信息,进一步提高IQA的准确性。具体来说,我们首先采用了一个双分支特征提取器。然后,利用ViT获取的语义信息,通过可变形卷积[8]找到图像中的显著区域。考虑到深度特征图中的每个像素对应于输入图像中的不同patch,我们引入了逐patch预测模块,该模块包含两个分支,一个是为每个图像patch计算一个分数,另一个是计算每个分数的权重。

图1所示。NTIRE 2022感知图像质量评估挑战赛[13]验证数据集上的客观评分与MOS评分的散点图。相关性越高,IQA方法的性能越好。 -
大量实验表明,我们的方法在四个基准图像质量评估数据集上优于现有方法。预测得分和MOS之间相关性的散点图如图1所示,其中IQT的图来自我们自己的实现。可视化实验表明,该方法与MOS值几乎是线性的,这意味着我们可以更好地模拟人类的图像感知。
-
我们提出了一种有效的混合图像质量评估体系,该体系在patch层面对图像进行比较,加入空间细节作为补充,并考虑到patch之间的关系和每个patch的不同贡献,对每个patch进行评分。
-
我们的方法在四个基准图像质量评估数据集上优于最先进的方法。特别是,所提出的架构在PIPAL数据集上具有各种基于gan的失真,并在NTIRE 2022感知图像质量评估挑战中排名第一。
相关工作
Deformable Convolution
可变卷积[8]是一种高效、强大的机制,最早被提出用于处理高级视觉任务中的稀疏空间位置,如目标检测[2,8,56]、语义分割[56]和人体姿态估计[35]。通过使用偏移量可学习的变形采样位置,变形卷积增强了空间采样位置,提高了cnn的变换建模能力。近年来,形变卷积在低水平视觉任务中,如视频去模糊[40]、视频超分辨率[6]等,仍有较好的表现。Shi等人[33]首先将其与IQA方法相结合,在全参考场景下进行了面向参考的可变形卷积。
Methodology
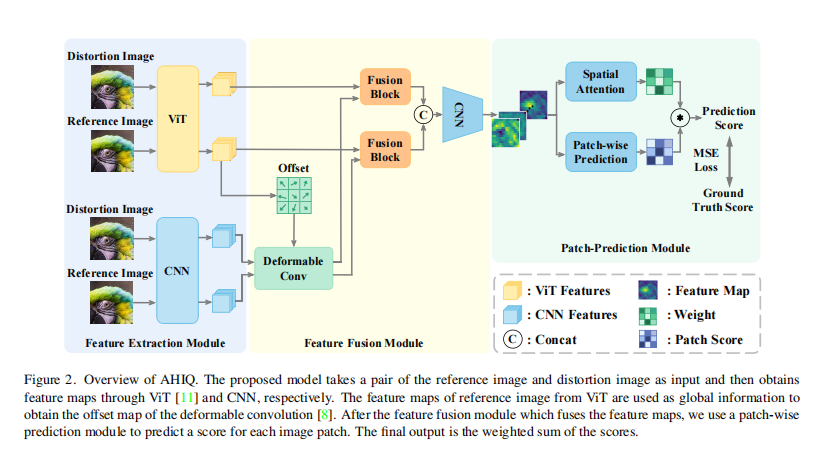
图2。AHIQ的概述。该模型以一对参考图像和失真图像作为输入,分别通过ViT[11]和CNN得到特征映射。利用ViT参考图像的特征映射作为全局信息,得到可变形卷积[8]的偏移映射。在融合特征映射的特征融合模块之后,我们使用基于patch的预测模块来预测每个图像patch的分数。最终输出是分数的加权和。
在本节中,我们介绍了基于注意力的混合图像质量评估网络(AHIQ)的总体框架。如图2所示,本文提出的网络以参考图像和失真图像对作为输入,由三个关键部分组成:特征提取模块、特征融合模块和patch-wise预测模块。
由于基于gan的图像恢复方法[14,41]往往会制造出看似可信的细节和纹理,因此网络很难通过像素级的图像差异将gan生成的纹理与噪声和真实纹理区分开来。我们提出的模型旨在解决这个问题。我们使用Vision Transformer为关系建模,并捕获补丁之间的长期依赖关系。引入浅层CNN特征来增加详细的空间信息。**为了帮助CNN聚焦于显著区域,我们采用ViT语义信息引导的可变形卷积。**采用自适应加权评分机制进行综合评价。
Feature Extraction Module
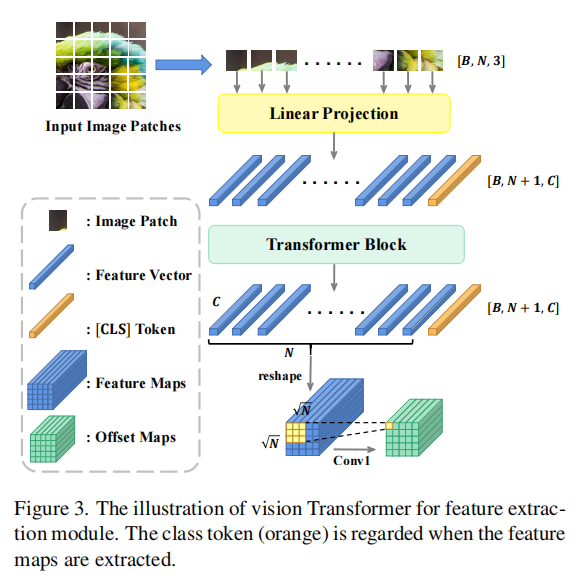
图3。用于特征提取模块的视觉变压器的说明。提取特征映射时,会考虑类标记(橙色)。
如图2所示,该架构的前部是一个由ViT分支和CNN分支组成的双分支特征提取模块。变压器特征提取器主要用于提取全局和语义表示。变压器中的自我注意模块使网络能够对远距离特征进行建模,并将输入的图像补丁编码为特征表示。Patch-wise编码提高了对空间错位的容忍度,有助于评估基于gan的图像恢复的输出图像质量。由于人类在判断图像质量时也会注意细节,所以细节和局部信息也很重要。为此,我们在变压器分支之外引入了另一个CNN提取分支,以增加更多的局部纹理。
在前向过程中,将一对参考图像和失真图像分别输入到这两个分支中,然后在早期阶段取出它们的特征图。对于变压器分支,如图3所示,视觉变压器[11]的输出序列被重塑(reshape)为特征图f_T∈Rp×p×5c,丢弃类CLS令牌,其中p表示特征映射的大小。对于CNN分支,我们从ResNet[16]fC∈R4p×4p×C中提取浅层特征图,其中C=256×3。最后,我们将得到的特征映射放到特征融合模块中,接下来将指定。
Feature Fusion Module
我们认为CNN早期的feature map提供了低级的纹理细节,但也带来了一些噪声。为了解决这个问题,我们利用变压器架构来获取全局和语义信息。在我们提出的网络中,利用语义丰富的ViT特征映射来寻找图像的显著区域。该感知过程以内容感知的方式执行,并允许网络更好地模仿人类感知图像质量的方式。特别地,使用ViT的特征映射学习可变形卷积的偏移映射,如图3所示。然后,我们对来自CNN的特征图执行这种可变形的卷积[8]操作,这是我们之前详细阐述的。这样可以更好地对浅层CNN的特征进行修改,并利用其进行进一步的特征融合。显然,在前面的描述中,来自这两个分支的特征映射在空间维度上彼此不同,需要对齐。因此,我们应用一个简单的2层卷积网络,将可变形卷积后的特征图投影到相同的宽度W和高度H。整个过程可表述如下:

其中fT表示来自VIT分支的特征图,∆p表示偏移图,f_org和f_C表示来自CNN的特征图,DConv表示可变形卷积。请注意,Conv2是一个卷积操作,步幅为2的卷积操作,将fC∈R4p×4p×C降采样4倍到f‘C∈Rp×p×C。
== Patch-wise Prediction Module==
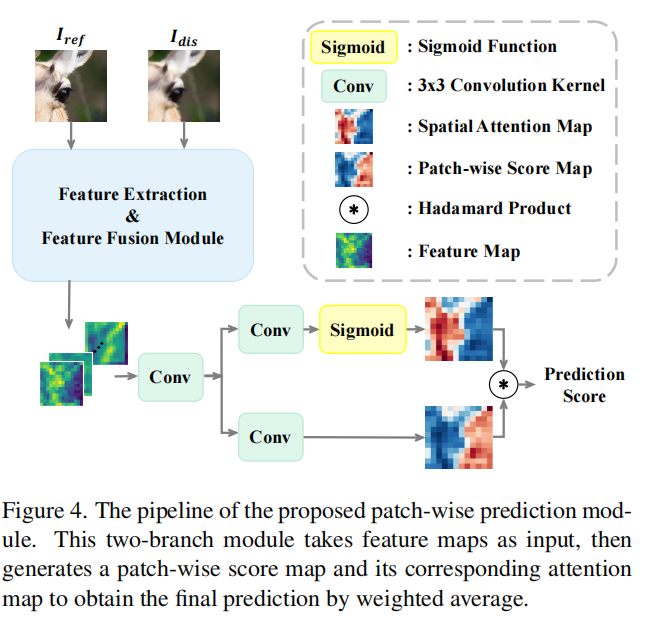
图4。提出的patch-wise 预测模块的流水线。这个双分支模块以特征图为输入,生成一个patch分值图及其对应的注意力图,加权平均得到最终的预测结果。
由于深度特征图中的每个像素对应于输入图像的不同patch,且包含丰富的信息,因此空间维度上的信息是必不可少的。然而,在以往的工作中,空间池化方法如最大池化和平均池化应用于获得最终的单项质量分数。这种池策略会丢失一些信息,并忽略图像补丁之间的关系。因此,我们引入了由预测分支和空间注意分支组成的双分支patch-wise预测模块,如图4所示。预测分支为特征图中的每个像素计算一个分数,而空间注意分支为每个对应的分数计算一个注意图。最后,我们可以通过加权求和得到最终的分数。加权和运算有助于模拟区域的意义,以模拟人类视觉系统。这可以表述如下
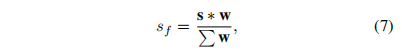
式中,s∈RH×W×1表示得分图,w∈RH×W×1表示对应的注意图,∗表示阿达玛乘积,sf表示最终预测得分。在我们提出的方法中,在训练过程中使用了预测分数和地面真实分数之间的MSE损失。

全参考注意力VTAMIQ: Transformers for Attention Modulated Image Quality Assessment

摘要
继自我注意和Transformer在图像分析方面的成功之后,我们研究了这种注意机制在图像质量评估(IQA)中的应用,并提出了一种全新的全参考IQA方法——视觉变形注意调制图像质量(VTAMIQ)。我们的方法在现有的IQA数据集上实现了具有竞争力的或最先进的性能,并在跨数据库评估中显著优于以前的指标。大多数针对patch的IQA方法独立对待每个patch;这部分地丢弃了全局信息,限制了模拟远距离交互的能力。我们通过使用转换器将一系列补丁编码为一个单一的全局表示来完全避免这个问题,这在设计上考虑了补丁之间的相互依赖性。我们依靠各种注意机制,首先是Transformer中的自我注意,其次是差分调制网络中的通道注意,**以揭示和增强整个架构中更显著的特征。**通过对分类和IQA任务进行大规模的预训练,VTAMIQ可以很好地推广到不可见的图像集和失真,进一步证明了基于变压器的网络在视觉建模方面的实力。
Introduction
随着消费者越来越习惯于高保真图像和视频,在许多图像处理和计算机视觉应用中,图像质量已经成为一个重要的评价指标。直接要求人类观察者评价视觉质量需要缓慢而昂贵的主观实验。作为一种实用的替代方案,客观图像质量评估(IQA)方法通过模仿人类视觉系统(HVS)的行为来实现图像质量评估的自动化。
由于人类对图像质量感知的高度主观性[69,37,47],朴素的计算IQA方法的成功有限[68];更感知准确的全参考(FR)图像质量指标(IQMs) 要求建模HVS的关键特征,例如它对基于亮度、对比度、色度、频率内容等的各种视觉刺激的敏感性[4,33,62],以及描述图像模式和结构的自然图像统计[59,57,14]。也就是说,传统的IQA方法往往受到各自关于HVS的假设的限制,在实际的IQA任务中容易表现不佳[67]。
随着深度卷积神经网络(cnn)在计算机视觉研究[32]的许多领域的主要进展,IQA领域逐渐被深度学习所吸引。直接从原始图像数据联合优化特征表示和推断解决了依赖手工机制的经典方法的常见局限性。当然,现有的IQA数据集通常规模不大,图像种类也有限;这使得从头开始训练深度IQMs成为一项具有挑战性的任务。
**为了方便使用有限的数据进行训练,许多最近的深度IQMs将图像视为更小补丁的组合。**与其直接处理全分辨率的输入,不如独立计算斑块度量,然后聚合最终的图像质量预测[25,27,7,49,52]。由于注意力从本质上调节了扭曲的可见性[74,18],因此对补丁重要性或注意力的估计可以用于对各补丁分数的加权平均。然而,现有的大多数方法都没有关注复杂的注意力模型,只是简单地对每个patch进行独立处理。在不需要完全全局知识的情况下估计Patch分数和权重;因此,在全分辨率输入中考虑大的多尺度特征和远距离交互的能力是有限的。
此外,神经网络中任意定义的信号需要专门的注意机制。卷积算子只利用预定义接收域中的局部信息;**它们对空间和通道相关性建模的能力是有限的。**因此,各种注意力策略被引入,以注意力来补充传统架构[17,60,66]。例如,通道注意(CA)[23,77]和自我注意(SA)[65]明确地分别评估对特征通道或序列元素的注意。 当cnn在计算机视觉领域占据主导地位时,基于sa的变形金刚[65,26]已经取代了自然语言处理(NLP),因为它们具有出色的序列建模能力和长距离依赖关系,而这是以前的方法常常缺乏的[3,43,9]。通过足够的数据、适当的预训练和巧妙的架构修改,变形金刚在视觉任务中获得了最先进的结果[50,13],说明了SA的灵活性和有效性。
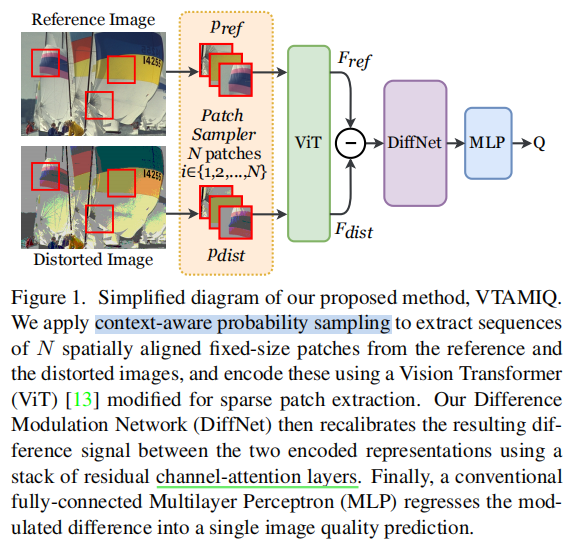
图1所示。简化图,我们提出的方法,VTAMIQ。我们采用上下文感知的概率抽样方法,从参考图像和失真图像中提取N个空间对齐固定大小的patch序列,并使用改进的Vision Transformer (ViT)[13]进行编码,用于稀疏patch提取。我们的差分调制网络(DiffNet)然后重新校准两个编码表示之间的结果差分信号,using a stack of residual channel-attention layers。最后,利用传统的全连接多层感知器(MLP)将调制差回归到单个图像质量预测。
我们的关键观察是基于补丁的IQA和基于变压器的架构之间的相似性:输入是一系列标记或图像补丁。我们进一步研究了这种类比以及IQA中的各种注意机制,并提出了一种全新的全参考IQA方法,Vision Transformer for attention Modulated Image Quality (VTAMIQ)。我们的方法建立在视觉转换器(Vision Transformer, ViT)[13]在视觉任务上的成功基础上,并利用自我注意的能力来联合编码图像补丁序列,通过设计考虑补丁的相互依赖性,不同于以往的补丁IQA方法。使用变压器允许VTAMIQ避免计算独立的patch级质量度量,而是直接确定每个输入图像的单个潜在表示,然后是单个全局图像质量分数。我们的方法的简化图如图1所示。
此外,以前的深度FR IQA方法通常可以分解为几个关键步骤:i)计算输入图像或补丁的编码表示(特征),ii)计算编码特征之间的差异,iii)将特征差异与图像质量关联起来。这种方法假设深度特征差异是即时信息(immediately informative),可以直接与图像质量相关。我们进一步提出了一个额外的步骤:智能调节两个输入之间的差异,以便在回归到单个质量分数之前增强更有意义的信息。我们通过利用一种受[77]研究启发的 a specialized channel attention-based network来实现这一点。
注:在具有多个通道(核)的深度特征响应的背景下,挤压和激发(SE)模块[23,22]显式地建模通道之间的相互依赖性,以自适应缩放(rescale)更显著的通道级特征响应。现有的网络架构,例如VGG[58]和ResNet[17]的变体,可以通过SE模块进行增强,以超过其原始基线。在[77]中,SE被直接称为通道注意(Channel Attention, CA);利用堆叠的CA模块构建深度残差网络进行超分辨,该网络专门针对高频信息的学习,明显优于以往的所有方法
VTAMIQ: Vision Transformer for IQA
如图1所示,我们提出的FR IQA方法VTAMIQ,利用改进的Vision Transformer (ViT)将每个输入图像编码为单个潜在表示,计算参考图像和失真图像的编码表示之间的差异,智能调节这种差异,最后,将调制差解释为图像质量分数。
虽然许多以前的深度FR IQA算法独立计算和聚合补丁级质量指标,但我们通过使用Transformer将每个输入图像编码为单个全局表示,直接避免了这一点。虽然我们仍然提取了一系列空间对齐的补丁来最初描述参考图像和扭曲的图像,但我们的模型对输入的补丁进行了整体处理,并考虑了补丁之间的相互依赖性。更具体地说,这是通过对输入补丁的完整序列进行ViT计算自我注意来实现的。通过这种方式,全分辨率图像的全局信息和远距离交互被考虑在内,然后在图像质量评估中隐含地使用。
我们的差分调制网络的目标是增强编码表示之间的差异的更显著的特征。大多数深度智能模型直接使用全连通层对差分向量进行回归;这是假设特征差异可以立即与图像质量相关。我们的结果强调了在应用回归之前调制差分向量的重要性:通道注意77完全满足了这项任务的要求。
== Feature Extraction==
我们使用一个为稀疏无序补丁输入序列修改的视觉变压器,将每个输入图像编码为一个维数为D的向量,对应于变压器的隐藏大小。与ViT一样,输入图像I∈RH×W×3用N个固定大小的RGB色块pi∈RN×p×p×3表示,其中p为补丁维数。通过应用可训练的线性投影来计算补丁嵌入,从补丁维度映射到潜在的Transformer维度。然后将学习到的位置嵌入注入到补丁嵌入中,以解释位置信息。ViT的总体结构和组成如图2-3所示。
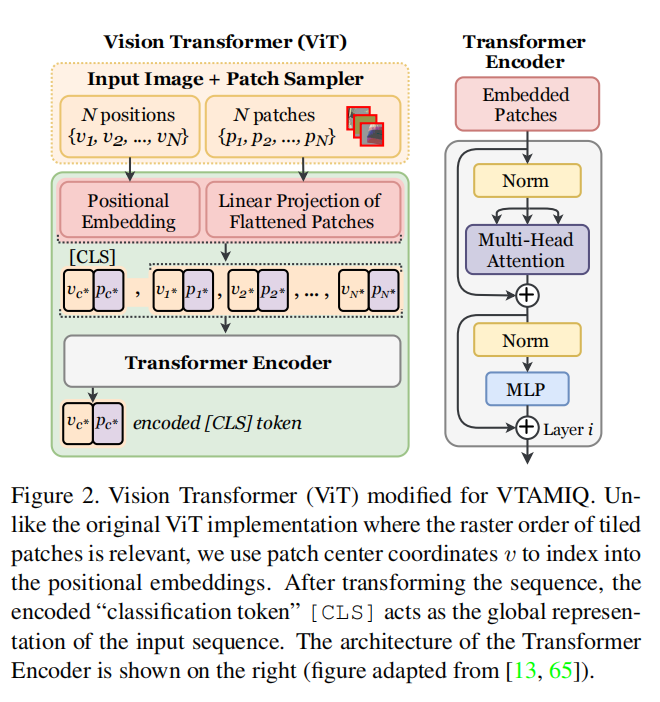
图2。Vision Transformer (ViT)修改为VTAMIQ。与原始的ViT实现不同的是,我们使用补丁中心坐标v索引到位置嵌入中。转换序列后,编码的分类标记[CLS]充当输入序列的全局表示。变压器编码器的架构如图所示(图改编自[13,65])。
虽然我们像在ViT中一样重用位置嵌入的整体结构(reuse the overall structure of positional embeddings as in ViT),但我们采用了不同的策略来为每个补丁分配位置嵌入。不像在ViT中那样对输入图像平铺,而是采用随机抽样的方法提取N个patch;由此产生的序列是无序的,可能包含重叠的斑块。为了解决这个问题,我们使用每个patch的位置 uv 坐标(在采样时可用),索引到位置嵌入数组。这个小小的修改补充了原来的ViT架构,允许我们微调预先训练的ViT。
== Patch Sampling Strategies==
提取像素块最简单的方法是平铺图像。在理想的情况下,我们希望完全覆盖全分辨率输入,**但由于与操作深度神经网络相关的内存和计算限制,这通常是不切实际的。**与之前的工作类似,我们选择从输入图像中随机抽取一组可能稀疏的补丁。这提供了数据增强的潜在好处,有利于模型训练和减少过拟合:每次处理图像时,都会提取一组新的、看不见的随机补丁。
以往的基于patch的IQA方法采用原始平铺或随机抽样的方法在图像上均匀地绘制patch样本;在此基础上,我们采用了一种特殊的上下文感知的patch采样策略来提取更多的信息造型的补丁。在我们的抽样方案中,我们利用了人类视觉感知的关键属性以及全参考IQA的性质。首先,为了解释人类视觉注意的中心偏差[30,29],我们以更高的概率抽样更显著的中心区域。其次,考虑到提取参考图像和失真图像之间相似的小块不会增加图像质量失真的信息,我们将采样偏置到参考图像和失真图像之间感知差异较大的区域。感知差异的估计可以通过简单的度量来计算,如MSE或SSIM[69],得到类似的结果。
总之,我们的上下文感知补丁采样(CAPS)策略允许我们使用更少的补丁样本来达到相同的精度水平,有效地减少了内存和计算需求。CAPS只需要最小的开销并加速模型训练,例如,当每幅图像使用256个补丁样本进行训练时,使用CAPS可以使VTAMIQ训练速度提高15%(更少的epoch)。注意,当使用较大的patch计数时,CAPS的好处会变得不那么明显,因为采样方差会自然降低。
def binary_search(arr, x, low, high):if low < high:mid = (high + low) // 2if x < arr[mid]:return binary_search(arr, x, low, mid - 1)else:return binary_search(arr, x, mid + 1, high)else:return low - 1def get_n_random_crop_params_bias(h, w, ho, wo, sample_prob, num_samples=1):rsamples = np.random.rand(num_samples).astype(np.float32)sample_prob = sample_prob.reshape(-1, 1).astype(np.float32)samples = []for i in range(num_samples):sample = rsamples[i]ind = binary_search(sample_prob, sample, 0, len(sample_prob))# convert to i, j indicespos_i = int(ind / w)pos_j = int(ind % w)samples.append((pos_i, pos_j, ho, wo))return samples
== Deep Feature Difference Modulation==
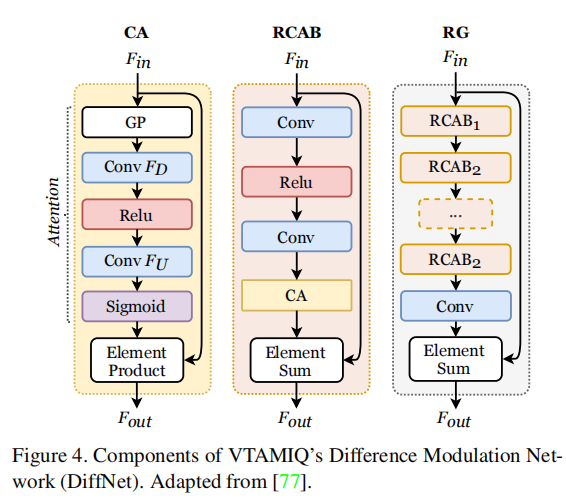
图4。VTAMIQ差分调制网络(DiffNet)的组成。改编自[77]。
我们使用[77]中提出的残差通道注意块(rcab)和残差组(RG)来调制参考图像和失真图像的编码表示之间的差异。为了简单起见,我们的差分调制网络由N个RGs组成的堆栈。同样,每个RG由M个堆叠的rcab组成,附加剩余的跳过连接。每个RCAB还包含一个跳跃式连接,连接乘法信道注意(CA)的输出和输入。CA、RCAB和RG的总体结构如图4所示。方程1-4定义了DiffNet的基础数学计算,其中Attention对应于CA的学习激发阶段,负责计算信道权值[23,77],URG和URCAB是可学习的线性变换

以前在IQA中,CA模块用于特征提取[52],但从未用于调制差分向量。此外,在[77]中,一个与我们的DiffNet相似的结构被称为残差中的残差(RIR),被证明有助于提取更多信息的高频特征。与原始RIR不同,我们在我们的变体中不包括最终残差跳过连接,以强调其信号缩放特性。最后,与最初的10个RGs和总共200个RCABS不同[77],我们的最佳IQA预测精度是通过一个更浅的网络实现的,每个网络只有4个RGs和4个RCABS。
== Model Training==
平均绝对误差(Mean Absolute Error, MAE)和均方误差(Mean Squared Error, MSE)是训练IQA模型常用的损失函数[25,27,7,52]。这两个函数都计算期望值与预测值之间的差值;由于附加的平方操作,MSE惩罚较大的差异比MAE更严厉。我们用MAE和MSE评估训练我们的模型,发现MAE损失得到了更一致的结果。
除了上述,我们还发现使用排名损失优化[38,76,52]有利于我们的模型。知道图像可以根据其质量进行排名,例如图像A的质量比图像B高,排名损失明确惩罚了与预期排序不一致的预测。因此,排序损失通过提供不同的制导信号来补充更一般的MAE损失;它并没有直接揭示预期预测的大小,但具体来说是它们的相对排名,这在IQA中同样具有意义。对于一对图像质量预测,两两排序损失可以按照公式5计算,其中y1, y2, y1, y2分别对应两个预测分数和两个期望分数,是一个小的稳定常数。当两幅图像的预测排名与期望结果一致时,分子值为负,从而通过max算子将结果箝制为零;当排名不一致时,排名损失对应两个分数的绝对差值,从而指向正确的排序
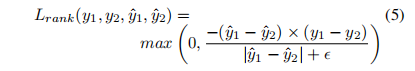
[2018] (CVPR)The Unreasonable Effectiveness of Deep Features as a Perceptual Metric

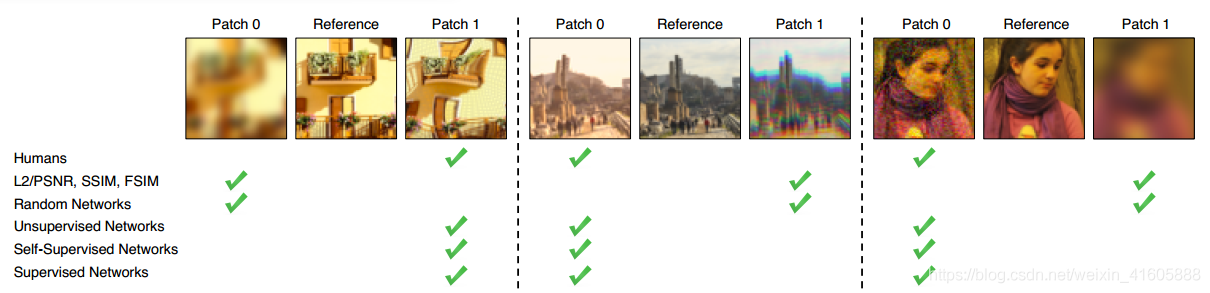
图片显示基于学习的感知相似度度量比传统的目前广泛应用的方法更符合人类的感知。(L2/PSNR, SSIM, FSIM属于目前广泛应用的度量方法,Random Networks效果不理想是因为未经训练)
摘要
虽然人类几乎可以毫不费力地快速评估两幅图像之间的感知相似性,但潜在的过程被认为是相当复杂的。尽管如此,今天最广泛使用的感知指标,如PSNR和SSIM,都是简单、肤浅的函数,无法解释人类感知的许多细微差别。最近,深度学习社区发现,通过ImageNet分类训练的VGG网络的特征作为图像合成的训练损失非常有用。但是这些所谓的知觉损失有多感性呢?什么因素对他们的成功至关重要?为了回答这些问题,我们引入了一个新的人类感知相似性判断数据集。我们系统地评估跨不同架构和任务的深度特性,并将它们与经典指标进行比较。我们发现,在我们的数据集中,深度特征的表现大大超过了之前的所有指标。更令人惊讶的是,这个结果并不局限于imagenet训练的VGG特性,而是跨不同的深度架构和监督级别(有监督、自我监督,甚至无监督)。我们的研究结果表明,感知相似性是深度视觉表征中共有的一种突现属性。
结论
这篇文章通过大量的实验分析了使用深度特征度量图像相似度的有效性。得到了如下结论:
- perceptual similarity比traditional similarity(such as L1)有效。而不同的分类网络的特征对最终perceptual similarity的影响不大
- 网络不一定在分类任务训练。BiGAN,Puzzle,Splitbrain等自监督、无监督任务模型的特征也能很好的度量相似度
- 网络可以学习perceptual similarity
图像的相似度度量存在的困难主要在
- 相似度的比较依赖图像结构。L2距离等度量逐像素的比较相似度,忽视了图像的结构信息,因此不适合比较图像的相似度。
- 上下文相关。比如红色的圆和红色的正方形更像还是和蓝色的圆更像?
- 相似度有可能不满足距离的定义
为了验证图像相似度的有效性,作者设计了一个庞大的图像相似度评估数据集;引入了2AFC、JND两个评估指标;设计了用于学习perceptual similarity 的LPIPS模型;进行了大量的实验。接下来的部分将依次介绍作者的上述工作。
引言
-
比较数据项的能力可能是所有计算基础上最基本的操作。在计算机科学的许多领域,它并不构成多大的困难:人们可以使用汉明距离来比较二进制模式,编辑距离来比较文本文件,欧几里得距离来比较矢量,等等。计算机视觉的独特挑战在于,即使是比较视觉模式这一看似简单的任务,仍然是一个大问题。视觉模式不仅是非常高维和高度相关的,而且,视觉相似性的概念往往是主观的,目的是模仿人类的视觉感知。例如,在图像压缩中,目标是使压缩后的图像与原始图像难以区分,而不考虑它们的像素表示可能非常不同的事实。
-
经典的逐像素测量方法,如“L2欧氏距离”,通常用于回归问题,或相关的峰值信噪比(PSNR),对于评估图像等结构化输出不足,因为它们假设像素级独立性。一个众所周知的例子是,模糊会导致较大的感知变化,但L2变化很小。
-
我们真正想要的是一种感知距离,它以一种符合人类判断的方式衡量两幅图像的相似程度。这个问题一直是一个长期的目标,已经有许多感知驱动的距离度量被提出,如SSIM [58], MSSIM [60], FSIM[62]和HDR-VDP[34]。
-
然而,构建一个感知度量是具有挑战性的,因为人类对相似度的判断**(1)依赖于高阶图像结构[58],(2)依赖于上下文,(3)实际上可能不构成距离度量**[56]。
-
相反,有没有一种方法可以在不直接训练的情况下学习感知相似性的概念?计算机视觉界已经发现,深度卷积网络的内部激活,虽然是在高级图像分类任务中训练的,但作为更广泛的任务的表征空间,常常是令人惊讶的有用的。例如,来自VGG架构[52]的特征已被用于风格迁移]、图像超分辨率[23]和条件图像合成等任务[14,8]。这些方法在VGG特征空间中测量距离,作为图像回归问题的感知损失[23,14]。
-
但是,这些“知觉损失”与人类的视觉感知究竟对应得如何呢?它们与传统的感知图像评价指标相比如何?网络架构重要吗?它是否必须在ImageNet分类任务上进行训练,或者其他任务也同样有效?网络是否需要进行培训?
-
在本文中,我们在一个新的大规模人类判断数据库上评估了这些问题,并得出了几个令人惊讶的结论。我们发现,为高级分类任务训练的网络的内部激活,甚至跨网络架构[20,28,52],并没有进一步校准,确实符合人类的知觉判断。事实上,它们的对应比常用的指标(如SSIM和FSIM[58,62])要好得多,这些指标不是设计来处理空间歧义是[49]因素的情况。此外,表现最好的自我监督网络,包括BiGANs[13]、跨通道预测[64]和解谜[40],即使没有人类标记的训练数据,在这项任务中也表现得一样好。即使是使用堆叠的k-means[26]进行简单的无监督网络初始化,也大大超过了经典的度量标准!这说明了跨网络、甚至跨架构和训练信号共享的一种新兴属性。然而,重要的是,有一些训练信号显得至关重要,随机初始化网络的性能要低得多。
-
我们的研究基于一个新收集的感知相似数据集,使用了大量的扭曲和真实的算法输出。它包含了传统的失真,如对比度和饱和度调整、噪声模式、滤波和空间扭曲操作,以及基于cnn的算法输出,如自动编码、去噪和着色,由各种结构和损失产生。我们的数据集比以前的这类数据集[45]更丰富、更多样化。我们还收集来自超分辨率、帧插值和图像去模糊任务的真实算法输出的判断,这是特别重要的,因为这些是感知度量的真实用例。我们表明,我们的数据可以用来校准现有的网络,通过学习层激活的简单线性缩放,以更好地匹配低水平的人类判断。
文章的主要贡献大致可以分为以下几个部分:
- 引入了一个大规模、高度变化的感知相似性数据集,包括484K个人类的判断。这个数据集不仅包括参数化的变化/失真(distortions),还包括算法导致的变化。还收集了对不同感知测试(perceptual test)的判断,最小可察觉误差(Just Noticeable Difference)。
- 证明了在监督、自监督、无监督模型上得到的深度特征在模拟低层次感知相似性(low-level perceptual similarity)上都比以往广泛使用的方法要表现得更好。
- 证明了仅靠网络结构并不能完全解决性能问题:一个没有训练过的网络会表现很差。
- 利用作者团队的数据,可以通过”标定/校准“来自预训练网络的特征响应来提升性能。
数据集
BAPPS Dataset包括两个部分:2AFC(two alternative forced choice,双向强迫选择)和JND(Just Noticeable Difference)。该数据集重于感知相似性,而不是质量评估。

这个工作造了一个包含 484k 个标签的超大数据集,每个样本是一个双向强迫选择(2AFC),即给原图和两张噪声图,询问哪一张更像原图。
**Traditional distortions:**使用了亮度失真(photometric distortions),随机噪声(random noise),模糊(blurring),空间移位(spatial shifts),损坏(corruptions),压缩伪影(compression artifacts)等20种传统方法进行顺序组合成308种顺序的失真。
**CNN-based distortions:**通过探索各种图像任务、网络结构和损失函数来模拟可能的算法输出,比如编码(autoencoding)、去噪(denoising)、着色(Colorization)、超分辨(Superresolution)、去模糊(Video deblurring)、帧插值(Frame interpolation)等。总成生成了96个”denoising autoencoders(去噪自动编码器)“,每个网络的目标不是本身解决任务,而是探索困扰基于深度学习方法输出的常见工件。
还从实际算法的生成图中收集了一些图片作为一个测试集。
数据集中的数据都被分割为64*64的patch,分成小图像块可以带来以下好处:
- 更关注低层次的相似度(针对上述第2个难点)
- 整张图像的空间很大,局部的图像空间会小很多
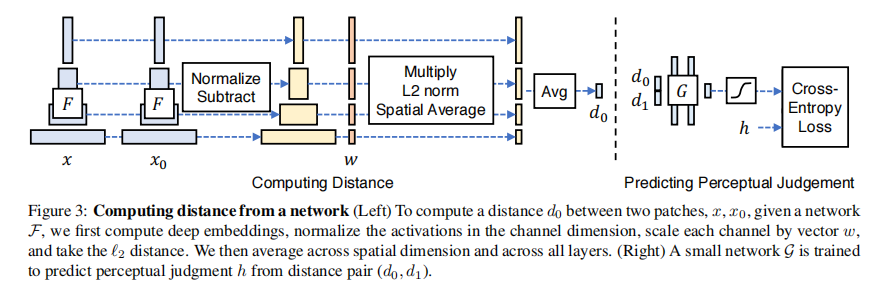
感知相似性度量

Deep Feature Spaces
评估不同网络中的特征距离。对于给定的卷积层,计算余弦距离(in the channel dimension)以及网络空间维度和层之间的平均值。



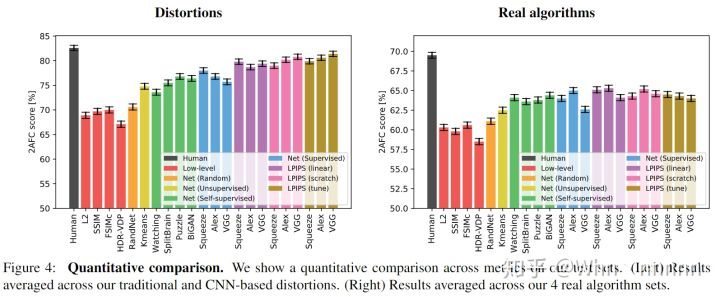
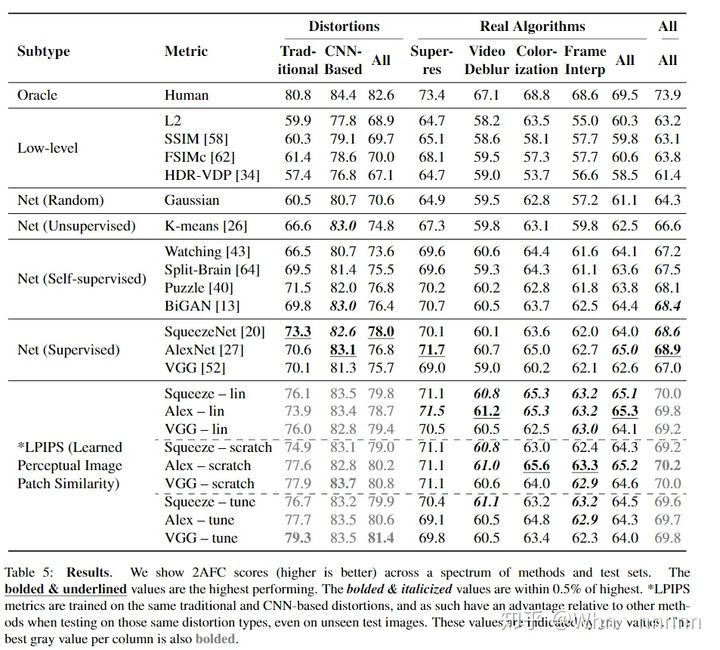
基于不同任务的学习的方法普遍优于广泛使用的“**low-level”**方法。(图见论文的附录)
自然数据集KonIQ10k: An Ecologically Valid Database for Deep Learning of Blind Image Quality Assessment

摘要
由于现有数据集规模较小,用于图像质量评估(IQA)的深度学习方法有限。大量的数据集需要大量的资源来生成可发布的内容和准确地注释它。我们提出了一种系统的、可扩展的方法来创建KonIQ-10k,这是迄今为止最大的IQA数据集,包含10073张经过质量评分的图像。它是第一个以生态效度为目标的野外数据库,涉及失真的真实性、内容的多样性和质量相关指标。通过众包,我们从1459名众包工作者中获得了120万份可靠的质量评分,为更通用的IQA模型铺平了道路。我们提出了一个新的深度学习模型(KonCept512),展示了一个优秀的泛化,超越了测试集(0.921 SROCC),到目前最先进的数据库LIVE-in-theWild (0.825 SROCC)。该模型的核心性能来自于InceptionResNet架构,其训练分辨率比以前的模型(512 384)更高。相关分析表明,KonCept512对每张测试图像的主观评分与9分相近。
引言
- 图像质量评估(IQA)在从图像压缩到机器视觉以及更多[1][4]的广泛应用中发挥着至关重要的作用。理想情况下,图像的视觉质量是由专家在受控环境下进行的主观用户研究来评估的,得出平均意见分数(MOS)。MOS是对图像感知质量的直接衡量,对于选择正确的技术和进一步改进现有的成像技术都很重要。然而,主观研究是耗时、昂贵,在实际应用中适用性有限。因此,客观IQA,即视觉质量的算法估计,一直是一个由来已久的研究课题,最近也受到了更多的关注。
- 根据原始参考图像的可用性,客观IQA方法被分为全参考(FR),如SSIM[5],减少参考(RR),如RRED[6],和无参考(NR),如CORNIA [7], HOSA[8]。相对于FR和RR, NR或Blind IQA (BIQA)是三者中更具挑战性的问题。BIQA也是三种方法中最实用的一种,因为基于参考的比较在许多应用中并不适用。
- 客观IQA方法的发展需要提供图像和仔细收集的主观质量分数的数据库。还需要这种数据库通过制定基准来改进现有方法,并为训练和参数拟合新模型提供数据来源。为了使训练的模型具有普遍适用性,它们需要使用来自真实世界的代表性数据,在真实性、规模和多样性方面。IQA数据库的生态有效性指的是视觉集合对大量真实世界照片(如互联网上的照片)的代表性,以及在此基础上训练的模型的泛化潜力。这两个都是我们工作的重要目标。
- 通常,创建IQA数据库遵循一个标准过程:收集原始图像并人为地降低它们的质量。然后,一些志愿者(通常是天真的参与者)会被要求评估失真图像的质量。这种方法的第一个缺点是图像内容的多样性是有限的,因为所有扭曲的图像都是从一小组原始图像退化的。第二,扭曲应用在非常有限的组合中,而生态上有效的扭曲,例如公共互联网图像的扭曲,是由不同于数据库中的扭曲类型的组合造成的。例如,一些真实的退化类型,如由于对象移动而产生的错误对焦或运动模糊,很难通过扭曲原始图像来人为地再现。最后,但并非最不重要的是,创建IQA数据集的传统方法会导致较小的数据库,因为在实验室环境中评估大量图像的质量过于昂贵。尽管如此,实验室研究通常控制良好,产生强烈一致的意见。
- 近年来,深度学习在许多计算机视觉任务中取得了可喜的成果:图像分类[9][10],对象检测[11][12],BIQA[13][14][15]。人们普遍认为,一个内容多样、失真真实的大型IQA数据库有助于深度学习方法的开发和评估。然而,现有的所有基于深度学习的BIQA方法都是在小型和人为扭曲的IQA数据库上进行训练和评估的。在实验室环境下评估大量图像的质量将需要太多的参与者和太多的时间来准备和运行实验。
- 为了解决现有数据库的局限性,我们的工作提供了以下重要贡献:
- 我们设计了一种易于扩展的方法,允许我们创建迄今为止最大的IQA数据库(KonIQ-10k),涉及图像数量和主观评分:由10073张图像组成,从1000万YFCC100M[16]条目中选择。我们的采样算法确保了内容的多样性和失真,使用了7个质量指标和1个基于深度特征的内容指标。对于每幅图像,通过众包获得了120个可靠的质量评级,由1459名群众工作者执行。
- 我们提出了一种基于深度学习的端到端BIQA方法:它是一种统一的迁移学习方法,基于微调预先训练的卷积神经网络(CNN)。在统一的架构下,比较5个最先进的cnn的性能。比较五种损失函数的表现,其中两种直接用于预测MOS,另外三种用于预测评分分布。探讨训练集大小对所提出的最佳模型KonCept512性能的影响。通过跨数据库测试,在KonIQ-10k基础上训练的KonCept512在另一个IQA数据库上运行良好。
数据库生成
- 我们的IQA数据库的主要用途是训练更好的深度学习模型。现有的IQA数据库要么太小,要么依赖于有限的原始图像和人工的、不真实的质量退化。由于IQA依赖于内容,而真实的图像退化对于准确的质量预测至关重要,因此我们创建了一个广泛的野外图像集合,以描述广泛的适当内容和真实的扭曲。
- 为了构建一个平衡的数据集,我们依赖于表征图像质量的多个指标。野外的指标值主要是不平衡的。Vonikakis等人[46]主张通过重新定位多个指标的分布来创建更好的数据集,这样每个维度上的所有值都能得到更平等的表示。类似地,Hosu等人[27]采用了与质量相关的指标,通过“公平采样”(另一种描述平衡过程的方式)创建不同的数据集。
A. Overview
-
通过从YFCC100m[16]大型公共多媒体数据库中选择图像,我们实现了创建真实失真数据库的目标。我们随机选择了大约1000万(9974030)张图像记录。然后我们将它们分成两个阶段进行筛选,得到最终的数据库。
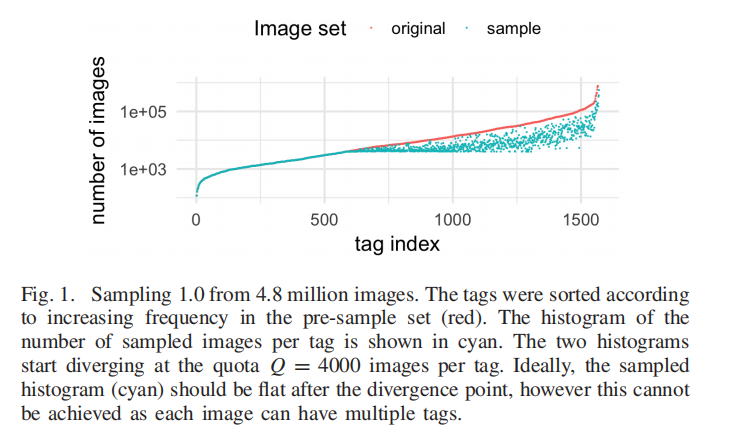
图1所示。从480万张图像中采样1.0。标签在预样本集中按照增加的频率进行排序(红色)。每个标签的采样图像数量的直方图显示为青色。两个直方图在每个标签的配额Q = 4000张图片时开始分化。理想情况下,采样直方图(青色)在散度点之后应该是平坦的,但这不能实现,因为每幅图像都可以有多个标签。 -
在第一阶段,我们选择图片与适当的创作共用(CC)许可,允许编辑和重新分配,并选择那些具有可用机器标签(从YFCC100m)和分辨率在960 540和6000 6000之间的。从这组4,807,816张图像中,我们提出了一种新的基于标签的采样程序,用于选择100万张图像,使其机器标签分布很好地覆盖更大的集合,见图1。
-
第二阶段,下载100万张大于1024768的图片,并将其缩放到1024768像素,并进行裁剪以保持像素-长宽比。为了使人脸突出部分保持在帧内,我们设计了自己的裁剪方法。它依赖于Viola-Jones人脸检测器和Hou等人[47]的显著性方法。然后对13000张图像进行采样,并强制在8个图像指标上进行均匀分布。采用考虑类别和指标的抽样策略,去除重复项。该集合被手动过滤了不适当的内容,导致我们的KonIQ-10k1数据集有10073张图片,略高于我们设置为10,000的目标大小。
==B. Initial Tag-Based Content Sampling]==
下载480万张图片会消耗大量带宽和存储空间。因此,我们设计了一种从100万张图片中缩小集合的方法,以保持内容的多样性。我们的目标是通过对每个标签取样至少一定数量的图像(配额)来实现标签的“统一”覆盖。这通常是不可能的,因为图像有不止一个标签(平均9.2)。因此,我们在考虑上述目标的同时,设计了一个简单且计算效率高的抽样启发式算法。启发式算法首先选择填充不太受欢迎的标签的给定配额的图像,直到所需图像的总数被选择。详见附录。图片按标签的分布如图1所示。
C. Selective Image Cropping
-
对数据库中所有图像的分辨率进行标准化是很重要的。它适用于用户研究,计算各种度量,并使用图像进行训练,或对IQA方法进行基准测试。我们选择了1024*768像素作为标准分辨率,因为我们发现95%的人群工作者设备至少有这个分辨率。我们没有不均匀地收缩图像从而改变它们的纵横比,而是裁剪,因为改变图像的长宽比会影响图像的感知质量,并降低图像采集的真实性。
-
一种简单的裁剪图像的方法是选择它们的中心区域,然后去掉其余部分。在早期实验中尝试了这个策略后,我们观察到,与呈现整个图像的情况相比,错误的作物,如那些删除图像的重要部分,如人脸,降低了图像的感知质量。因此,我们设计了一种选择性的方法,它不会产生一些更频繁的意外降级。
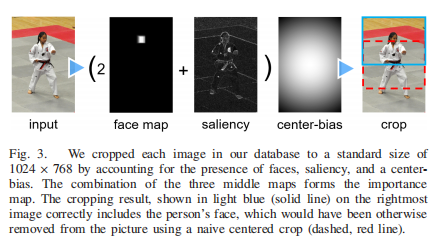
图3所示。通过考虑人脸、显著性和中心偏差,我们将数据库中的每张图像裁剪为标准大小1024768。中间三个图的组合就形成了重要性图。在最右边的图片中,浅蓝色(实线)的裁剪结果正确地包含了这个人的脸,否则使用朴素的居中裁剪(虚线,红线)就会从图片中删除。 -
其目的是将人脸和突出区域保留在作物中,并以足够快的速度处理100万张图像。我们将Viola-Jones面部检测器[48]与显著性检测方法[47]组合成重要度图,如图3所示。[47]的作者认为,实验数据表明他们的方法很好地识别了前景内容,对我们具有重要意义。更清晰的区域更可能与图像质量相关,例如,在图像有非焦点区域的情况下,我们宁愿聚焦在主题上。最后,但并非最不重要的是,我们使用的显著性方法具有较小的计算成本。
D. Diversity Sampling
我们的目标是选择图像的子集,同时确保内容的多样性和失真的真实性。后者由于图像的来源而显得含蓄。我们采用了基于质量相关指标和类别特征的抽样程序,以确保内容的多样性。
== 1) Image Quality Indicator Selection==
- 我们收集了几个与亮度、色彩、对比度、噪声、锐度和无参考(NR) IQA措施相关的图像质量指标。对于其中的一些,有几种实现可用。我们丢弃了那些太慢而无法在我们的100万张图像集中运行的图像。我们进行了初步的主观研究,保留了与人类感知良好相关的四个测量指标,分别是亮度、色彩[49]、均方根对比度(RMS)和清晰度[50]。除此之外,我们还考虑了其他三个指标:图像比特率、分辨率(高度宽度)和JPEG压缩质量(图像元数据);这些与图像质量高度相关。
- 每个质量指标标识一个图像属性,以标量值度量其大小或存在。某一指标的极值与严重失真有关,这是由于没有或不正常地强调该方面。如果我们对图像数据库进行随机抽样,不太可能选择具有异常属性值的图像。因此,我们采样的图像具有更广泛的指标值范围,因此可能有更多的扭曲类型。
- 尽管如此,指标范围的绝对极端被扭曲到一个过度的程度,并且没有信息,即,过暗或明亮,过于丰富多彩的,以及其他。因此,在执行采样程序之前,我们修剪了每个指标分布的极值。我们计算一个指标值x的z得分为z = (x- X)/S,其中X和S是给定指标的样本的均值和标准差。通过删除所有z评分指标绝对值大于3的图像,数据集的大小从100万缩小到866976。
== 2) Choice of Content Indicator==
- 至此,我们基于YFCC100m提供的机器标签对100万张图片进行采样,保证了内容的多样性。标签是使用深度神经网络进行分类分配的,并代表每张图片中几个最有可能的类别。此外,我们选择了866,976张图像的子集,以排除极端质量指标值。
- 为了进一步改进内容描述,我们使用了从ImageNet[9]上预训练的VGG-16模型中提取的更全面的4096维深度特征。这些特性表示在返回类可能性的最后一层之前,最后一个完全连接的层(通常命名为FC7)的激活。
- 由于深度特征为4096维向量,我们采用词袋模型对其进行量化。也就是说,我们使用k-means计算200个质心,将每个深度特征映射到最近的簇。聚类指数代表了我们的内容指标。
== 3) Sampling Strategy==
- 对于实际采样,我们采用Vonikakis et al.[46]提出的方法,使每个指标的目标分布均匀。质量指标时,我们将每个指标的值量化为N个箱子。内容指标已经被量化为聚类指标。采样过程使用混合整数线性规划(MILP),沿着所有指标维度联合优化直方图的形状。
- 我们为所有7个标量指示器使用N = 200个箱子。我们运行了采样程序,生成了13000张具有均匀采样指标的图像。这个集合比目标10,000要大,以允许删除重复项和其他后过滤。
== E. Removal of Duplicates and Inappropriate Content==
- 均匀采样策略保证了图像数据库在大范围内的多样性。然而,由于分箱程序,相同的副本或接近重复的图像可以采样在一起,即,从略有不同的观点拍摄的场景的照片。
- 我们设计了一种方法来去除接近的重复。首先,将各指标的值缩放到区间[0,1]。我们在8维指标加上内容空间中计算了来自源数据集的图像i, j之间的所有两两欧氏距离D(i, j)。如果两个图像属于同一个集群,则将内容空间中的距离设置为0,否则设置为1。重复和接近重复的图像i, j期望对应的距离较小,D(i, j)。因此,通过迭代移除最近对中的一个成员,我们可以有效地移除接近重复的图像。我们用这种方法删除了2000张图片
- 为了保证数据库的质量,我们手动删除了显示内容太少的图片,即文本截图、文本扫描、曝光严重不足的图片,或者显示成熟内容的不合适的图片最后,剩下10073张图片组成了我们的KonIQ-10k数据库;参见图2。
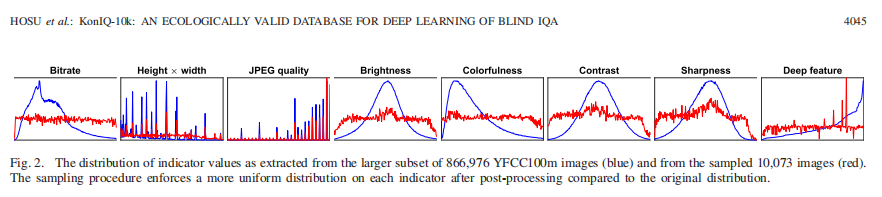
图2所示。从866976张YFCC100m图像(蓝色)和10073张采样图像(红色)中提取的较大子集的指示值分布。与原始分布相比,经过后处理的采样过程使每个指标的分布更加均匀。
== F. Diversity Analysis==
-
我们选择了LIVE-itW和TID2013来比较它们与KonIQ-10k在某些方面的多样性。在这里,LIVE-itW和TID2013是最具代表性的、真实失真的和人为失真的数据库。他们分布在亮度、色彩、对比度和锐度分别在图4(a)-(d)中描述。KonIQ-10k在这些指标中比比较数据库更加多样化。KonIQ-10k的图像示例如图17 (Supplementary Material)所示,在4个指标中每个指标均匀采样5张图像。
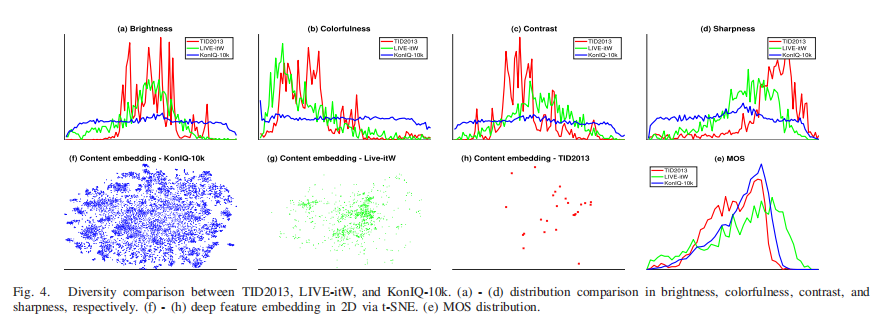
图4所示。TID2013、LIVE-itW、KonIQ-10k的多样性比较。(a) - (d)分别在亮度、色彩、对比度和锐度上的分布比较。(f) - (h)深度特征通过t-SNE嵌入2D。(e) MOS分布。 -
为了比较内容多样性,我们利用t-SNE[51]将数据库中4096维的VGG-16深度特征嵌入到2D子空间中。可视化如图4(f)-(h)所示。因为只有少数摄影师拍摄了LIVE-itW的图片,所以他们的内容只覆盖了KonIQ-10k的一小块区域,更不用说TID 2013了,它是由25张参考图片生成的。校准刻度后,其MOS分布如图4(e)所示。均匀采样MOS的图像示例如图18 (Supplementary Material)所示。
IV. SUBJECTIVE IMAGE QUALITY ASSESSMENT
为了评估10073张精选图片的视觉质量,我们在CrowdFlower.com(现在的Figure-Eight.com)上进行了一项大规模的众包实验。实验首先向工作人员提供了一套指导,包括“技术图像质量”的定义,评分时的一些考虑,经常遇到的失真类型的例子,以及不同质量的图像。然后要求受试者考虑以下退化类型:噪声、JPEG伪影、混叠、镜头和运动模糊、过度锐化、错误曝光、颜色流光和过饱和。我们使用标准的5点绝对分类评级(ACR)量表,即差(1)、差(2)、一般(3)、好(4)和优秀(5)。
== A. Domain Experts and Test Questions==
- 我们设计了一组测试问题,即用已知答案对问题进行评级,以筛选可靠的人群工作者,并分析收集的评级的整体质量。领域专家的意见通常更可靠,因此为设置测试问题提供了良好的信息来源。我们采访了11位自由摄影师,他们平均拥有超过三年的专业经验。我们让他们对240张图片的质量进行评价:29张是事先精心挑选的原始高质量图片,其中21张照片使用12种类型的失真进行了人工退化,其余190张照片是从Flickr中随机选取的(不属于我们的10k数据集)。失真包括模糊、伪影、对比度和颜色退化。
- 基于这组图片和自由职业者的平均意见得分,我们为我们的众包实验生成了测试问题。正确答案基于自由职业者的四舍五入值MOS一个标准差。我们允许犯错的余地,容忍参与者在评价行为时的一些主观性。结果,所有的图片最多有三个有效的答案选择。
== B. Crowdsourcing Experiment==
-
共有2302名人群工作者参与了这项历时三周的研究。实施并验证了几个过滤步骤,以确保产生的平均意见评分(MOS)达到可接受的质量水平。
-
测验。在开始实际实验之前,工人们要做一个包含20个测试问题的测验。只有1749名准确率超过70%的工人有资格继续工作。
-
隐藏的试题。在整个实验的主要部分都出现了隐藏的测试问题,以鼓励参与者始终保持充分的注意力。同样,只有准确率在70%以上的员工被允许完成他们的工作,剩下1648人。他们的评级产生了一组初步的MOS值。
-
离群值。与初步MOS协议很低的工人被视为异常值。68名PLCC和初始MOS低于0.5的工人被排除在研究之外。
-
点击器。在多项选择问卷[29]中,直线点击者对于任何一个单一答案的选择都有着异常高的频率。为了检测行点击器,我们计算了所有五个选项中每个工人的得分计数。然后我们取最大计数与四个较低计数之和之间的比率。剔除了121名比例大于2.0的工人。
-
总而言之,在2302名人群工作者中,有1459人通过了这些筛选步骤。结果,为了标注整个数据库的10073张图像,每个图像至少有120个分数,提交了120多万个可信的判断。
-
最后,为了弥补个别工人的不同评分范围,我们将他们的分数重新调整到[1,100]
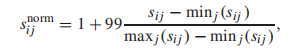
其中sij为第i个工人在第j个图像上的得分。 -
为了检验人群MOS的可靠性,我们将其与11名专家小组的结果进行了比较。在所有240张试题图片中,我们有187张图片,每一张都是由11位专家和592位或更多的群众工作者打分的。当187张图片中绝大多数的人群MOS值都包含在专家MOS值的95%置信区间内时,我们可以将专家的意见(MOSexperts)作为基本事实,接受众包结果是可靠的。
-
我们通过拟合线性模型来补偿两个数据源之间MOS范围的差异
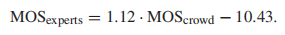
请注意,人群对专家MOS量表的对齐并不用于转换数据库的最终分数。

- 重新校准后,我们比较了两个数据源:专家和人群。对于人群数据,我们对KonIQ-10k中多达120个评级数量的子样本进行了MOS计算。将每组MOS值与地面真值MOS进行比较,产生一个均方根误差(RMSE),见图5(a)。我们发现这个RMSE很快收敛到一个下限11.35在100点尺度。我们还对规模为11的专家组进行了bootstrap,发现bootstrap MOS值的标准差为6.63。
== C. Reliability of the Crowd==
- 在图5(b)中,我们展示了人群MOS在所有187幅图像上的误差分布。我们注意到,187张图像中的137张(73%),误差在专家MOS(95%置信区间)的2个标准差内。因此,大约四分之三的图像被人群评为足够好,以至于他们可能会与专家的评级相混淆。
- 对于剩下的50张图片,人们的看法与专家们的看法分歧更大。初步检查显示,在人群评分低于专家评分的27个项目中,有11个代表较浅的景深图像,例如图16(补充材料)中的前5个项目。一般来说,对于群众摄影工作者来说,大量的模糊被认为是一种严重的退化,而专业摄影师认为这是一种艺术效果,并不会降低画质。观察到的分歧,至少部分是专家(自由职业者)和新手(大众)之间领域知识分歧的结果。
- 此外,为了支持我们实验的可靠性,Hosu等人[29]的工作表明,基于图像质量测试问题筛选用户可以提高类内相关系数(ICC)。他们发现,他们的IQA实验ICC从0.37提高到0.50,因为在质量测试问题上要求70%的正确率。我们在这里工作的方法有类似的效果,导致整个数据库的ICC为0.46。这表明KonIQ-10k比类似的众包评估研究有更好的结果[28];在后一部作品中,作者对抽象图像进行了审美质量评估。经过仔细的可靠性检查,ACR量表的ICC为0.403。
- 另一个相关指标的一致性得分生产是平均组间协议。在图6中,我们展示了随着用户数量的增加,非重叠随机用户组的MOS值之间的平均一致性增加。在我们的实验中考虑贡献者的随机一半之间的相关性时,平均SROCC达到了一个优秀的值0.973。为了进一步分析,我们将提供完整的原始众包数据,作为我们数据库最终版本的一部分。这包括关于观察者上下文的信息,如屏幕分辨率、浏览器缩放、回答时间等。
美学图像[2018] NIMA: Neural Image Assessment

摘要
图像自动学习质量评估由于其在图像捕获管道评估、存储技术和共享媒体等各种应用中具有广泛的用途,近年来成为一个热门话题。尽管这一问题具有主观性,但现有的大多数方法只能预测AVA[1]和TID2013[2]等数据集提供的平均意见评分。我们的方法不同于其他方法,我们使用卷积神经网络来预测人类意见得分的分布。我们的架构还有一个优势,那就是与其他具有同等性能的方法相比,它要简单得多。我们提出的方法依赖于经过验证的、最先进的深度目标识别网络的成功(和再训练)。我们得到的网络不仅可以用于可靠地对图像进行评分,并与人类感知高度相关,还可以帮助摄影流水线中的照片编辑/增强算法进行适配和优化。所有这些都不需要一个黄金参考图像,因此允许单一图像、语义和感知感知、无参考的质量评估。
引言
图像质量和美学的量化一直是图像处理和计算机视觉中一个长期存在的问题。技术质量评估处理的是测量低水平的退化,如噪声、模糊、压缩伪影等,而美学评估量化的是与情感和图像美感相关的语义级别特征。一般来说,图像质量评价可分为全参考法和无参考法。虽然前一种方法假设参考图像的可用性(如PSNR、SSIM[3]等指标),但典型的盲(无参考)方法依赖于扭曲的统计模型来预测图像质量。这两种分类的主要目标是预测一个与人类感知良好相关的质量分数。然而,图像质量的主观性质仍然是根本问题。最近,更复杂的模型,如深度卷积神经网络(CNNs)被用来解决这个问题[4][11]。人类评级的标记数据的出现鼓励了这些努力[1],[2],[12][14]。在典型的深度CNN方法中,通过训练分类相关数据集(如ImageNet[15])初始化权重,然后对注释数据进行精细调整,用于感知质量评估任务。
贡献
- 在这项工作中,我们介绍了一种新的方法来预测图像的技术和美学质量。我们展示了使用相同的CNN架构的模型,在不同的数据集上进行训练,可以导致这两个任务的最先进的性能。由于我们的目标是与人类评分有更高相关性的预测,而不是将图像分类为低/高评分或回归到平均评分,而是将评分的分布预测为一个直方图。为此,我们使用了在[21]中提出的平方EMD(运地机的距离)损失,它显示了与有序类分类的性能提高。我们的实验表明,这种方法也可以更准确地预测平均分。此外,如审美评估案例[1]所示,图像的非常规性与评分标准差直接相关。我们提出的范式也允许预测这个度量。
- 最近的研究表明,感知质量预测器可以作为学习损失来训练图像增强模型[22],[23]。同样,图像质量预测器可以用来调整增强技术[24]的参数。在这项工作中,我们使用我们的质量评估技术来有效地调整图像去噪和色调增强操作的参数,以产生感知优越的结果。
- 本文提出一个新颖的预测图片质量和图片美学的方式,致力于预测人类对于图片的打分分布而不是对图片质量的高低进行一个分类,更不是回归平均评分。
由于平方EMD(earth mover’s distance)损失在有序类别的分类上效果很好,所以本文采用该损失作为损失函数。与此同时,该模型还可以预测平均得分、对图片进行增强。
数据集
- AVA数据集–美感视觉分析的大规模数据集
AVA数据集包含25.5w张图片,其中每张图片都由平均200个人给出1-10的整数分数。
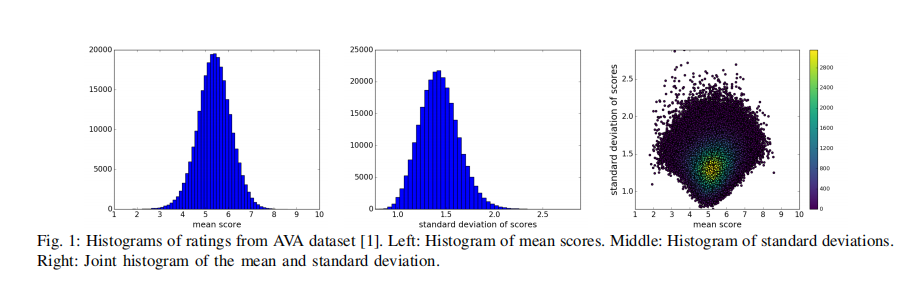
图1:AVA数据集[1]评分直方图。左:均分直方图。中:标准差直方图。右:均值和标准差的联合直方图。

图2:AVA数据集[1]带有质量评分(σ)的一些示例图像,其中和σ分别表示评分的均值和标准差。(a)高美学、低非常规(挑战名:2007年最佳,= 6.36,σ = 1.04)、(b)高美学、高非常规(挑战名:极限超级月亮,= 7.84,σ = 2.08)、©低美学、高非常规(挑战名:Travel, = 2.62, σ = 2.15)、(d)低美学、低非常规(挑战名:人的形体片,= 3.12,σ = 1.28)。
PROPOSED METHOD
- 我们提出的质量和美学预测站在图像分类器架构上。更明确地说,我们探索了一些不同的分类器架构,如VGG16[18]、Inception-v2[28]和MobileNet[29]用于图像质量评估任务。VGG16由13个卷积层和3个全连通层组成。深度VGG16架构[18]中使用了大小为3 3的小卷积滤波器。Inceptionv2[28]基于Inception模块[30],它允许并行使用卷积和池化操作*。此外,在Inception架构中,传统的全连接层被平均池取代,这导致参数的数量显著减少。MobileNet[29]是一种高效的深度CNN,主要针对移动视觉应用而设计。在该架构中,稠密卷积滤波器被可分离滤波器所取代。这种简化使得CNN模型更小、更快。
- 我们将基线CNN的最后一层替换为10个神经元的全连接层,然后进行软最大激活(如图8所示)。在ImageNet数据集[15]上训练初始化基线CNN的权值,然后进行端到端质量评估训练。在本文中,我们讨论了该模型在不同基线cnn下的性能。
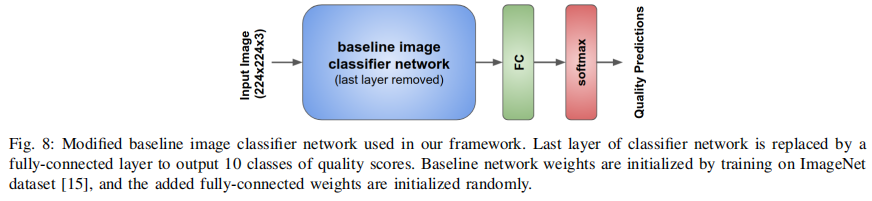
图8:我们框架中使用的改进基线图像分类器网络。将分类器网络的最后一层替换为全连通层,输出10类质量分数。在ImageNet数据集[15]上训练初始化基线网络权值,并随机初始化添加的全连接权值。
- 在训练时,将输入图像缩放为256*256,然后随机提取大小为224 *224的裁剪。这减少了潜在的过拟合问题,特别是在相对较小的数据集上训练时(例如TID2013)。值得注意的是,我们还尝试使用随机裁剪进行训练,而不需要调整比例。然而,结果并不令人信服。这是由于图像构成的不可避免的变化。在我们的训练过程中,另一个随机数据增强是水平翻转图像裁剪。
- 我们的目标是预测给定图像的评分分布。我们可以通过分数的平均值和标准差来定性地比较图像。
损失函数
- Soft-max cross-entropy被广泛用于分类任务的训练损失。这种损失可以表示为
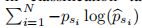
(其中pbsi_表示第i个得分桶的估计概率),以最大限度地提高正确标签的预测概率。然而,在有序类的情况下(如美学和质量估计),交叉熵损失缺乏类间的关系between score buckets。有人可能会说有序类可以用实数表示,因此可以通过回归框架学习。然而,它已经表明,对于有序类,分类框架可以优于回归模型[21],[31]。Hou等人[21]表明,在类之间具有内在排序的数据集上训练可以受益于基于emd的损失。这些损失函数根据类的距离对错误分类进行惩罚。
- 对于图像质量评级,类的排序固有为s1<…<sN;类间的r范数距离定义为||si - sj||_ r,其中1 <=i, j <=N. EMD被定义为将一个分布的块移到另一个分布的最小成本。给定地面真值和估计的概率质量函数p和p帽,距离||si - sj||_ r为N阶类,归一化的推土距离可表示为:
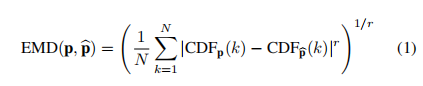
其中CDFp(k)为累积分布函数。我们的预测质量概率被输入到一个软-最大函数,以保证pni =1 b psi =1。

在我们的训练框架中,r被设为2来惩罚cdf之间的欧氏距离。R = 2使得使用梯度下降法时更容易进行优化。
夜间图像[2020] Blind Night-Time Image Quality Assessment:Subjective and Objective Approaches

摘要
- 盲图像质量评估(BIQA)的目的是在不需要任何参考图像信息的情况下,自动准确地评估图像的视觉质量。长期以来,这一问题一直备受关注;然而,关于夜间图像的研究却很少,而夜间图像对于消费者摄影和自动驾驶系统等实际应用至关重要。在本文中,据我们所知,我们对夜间图像的主观和客观质量评价进行了首次探索。首先,我们建立了一个大型自然夜间图像数据库(NNID),该数据库包含2240幅图像,其中448幅不同的图像内容是由不同的摄影设备在真实场景下拍摄的。随后,我们进行了一个主观实验来评价NNID数据库中所有图像的感知质量。
- 随后,我们提出了一种基于亮度和纹理特征(BNBT)的盲夜间图像质量评估指标,对夜间图像进行客观评估。
- 最后,在NNID数据库上进行了大量的实验,以评估所提出的BNBT指标的性能和效率。实验结果表明,该指标在所有评价标准上都优于现有的BIQA方法,同时具有可接受的计算成本。
引言
- 在弱光的夜间环境下拍摄的夜间图像,其特点是对比度低、细节模糊和能见度降低,因此通常表现出视觉质量受损。随着消费摄影的日益繁荣,消费者对夜间环境下的图像捕捉能力提出了很高的要求,图像质量直接影响着消费者的体验质量(QoE)。在这种情况下,可以使用适当的夜间图像IQA指标来量化消费者的QoE。此外,许多实时图像处理算法和图像驱动应用(如视觉监控和自动驾驶)的性能都受到输入图像质量的强烈影响。IQA指标可以对这些算法和系统[1],[2]进行有效的基准测试和优化。
- 夜间图像视觉质量评估是一项具有挑战性的任务,原因有二。1,缺乏公共的夜间图像质量评价数据库,合适的图像数据库是图像质量评价的基本要求。2,目前还没有针对夜间图像的具体质量评估指标。不同畸变的图像需要不同的质量评价指标,通常根据畸变的特点来设计质量评价指标。例如,特定畸变盲图像质量评估(BIQA)指标是根据每种类型的图像畸变的特征设计的。
- 现有的IQA解决方案在用于夜间图像质量评估时存在许多局限性。1,传统的BIQA方法 关注的是模拟失真,而不是夜间图像的自然失真。具体地说,夜间图像的畸变不是由于对高质量图像引入分级模拟畸变,而是由于图像采样过程所致。2,现有的通用BIQA[3][11]方法虽然可以用于夜间图像的视觉质量评价,但其结果不理想,与主观评价结果不一致。具体而言,具有较高平均意见评分(MOS)的夜间图像可能无法获得较高的预测客观评分。以图1为例,我们可以看到图1(a)和图1©的感知主观质量分别明显优于图1(b)和图1(d),但后两幅图像用现有BIQA方法预测的客观得分更好。造成这种不一致的原因是,现有的大多数通用BIQA指标都是针对模拟失真的图像设计的。

- 本文从主观和客观两个方面对夜间图像的视觉质量评价问题进行了探讨。考虑到在相对黑暗的场景下,任何相机设置都无法获得无失真、质量完美的图像作为参考图像,因此本文重点研究BIQA方法。首先,我们建立了一个专用的大型自然夜间图像数据库(NNID),其中包含2240张夜间图像,448张不同的图像内容,这些图像是由不同的摄影设备在不同的曝光时间和其他设置下拍摄的,分别是数码相机(尼康D5300)、手机(iPhone 8plus)和平板电脑(iPad mini2)。然后,采用国际电信联盟(ITU)推荐的单刺激(SS)方法对NNID数据库进行主观评估。在一个精心准备的测试环境中,我们邀请了74名经验不足的观察者根据自己的视觉感知来评估NNID数据库的图像,然后经过必要的后处理程序,将所有有效分数平均得到最终的MOS值。
- 提出了一种基于亮度和纹理特征的夜间图像质量盲评价指标(BNBT),对NNID进行了客观评价。亮度特征提取自夜间图像的超像素段,纹理特征提取自灰度共生矩阵(GLCM)。将亮度和纹理特征结合起来作为SVR的输入,得到最终的质量评分。与最先进的BIQA方法相比,我们提出的BNBT度量在判断夜间图像质量时与人类视觉感知的一致性更高。
- 我们的贡献可以概括为:1, 建立了第一个专用的大型自然夜间图像数据库(NNID),其中包含2240张图像,448张不同的图像内容,由不同的摄影设备在现实场景中捕获。对于每个图像内容,我们使用一个具有五种不同设置的设备来捕获五种不同视觉质量的图像。对于不同的图像内容,这五个设置是不同的。我们采用国际电信联盟(ITU)推荐的单刺激(SS)方法对NNID数据库中的图像进行综合主观评价。通过精心设计的实验和后处理程序,得到了每幅图像的基本GT,即平均意见评分(MOS)。2, 我们提出了一种基于亮度和纹理特征(BNBT)的夜间图像质量盲评价指标,对夜间图像进行了客观评估。与传统的从非重叠图像块中直接提取亮度特征的方法不同,我们从图像的超像素段中提取亮度特征,以更好地与视觉感知的一致性。我们还从亮度和色度通道中提取亮度特征,使所提出的BNBT对夜间图像的失真更加敏感。
NNID DATABASE
使用不同的设备,捕捉不同的内容
Subjective Assessment Methodology
- 图像质量评价的主观评价方法已被国际电信联盟(ITU)[40]推荐,包括单刺激(SS)、双刺激和配对比较。由于SS方法接近于在黑暗场景中无法获得无失真和质量完美的参考图像的观看体验,在我们的研究中,使用SS方法进行实验,有11个从0到1的离散评级量表,分别对应5个质量等级:差、差、一般、好和优秀。评分量表与质量水平的关系如图3所示。给定一个显示在屏幕上的图像,观察者被要求根据她/他的视觉感知给图像质量打分。在评分过程中,每幅图像以随机的顺序呈现,以减少记忆对评分的影响。

- 在主观测试中,将NNID中的图像随机分为两个大小相等的子集。我们邀请了74名观察员参加我们的测试,其中女性33名,男性41名。一半的观察者参与其中一个子集的测试,另一半参与另一个子集的测试。所有这些观察员都是主修艺术、科学、工程和商业的大学生;他们都没有图像处理的背景知识。他们都有正常或矫正视力,年龄在20到30岁之间。
- 我们设计了一个交互式系统,使用图形用户界面(GUI)自动显示测试图像和收集主观意见得分。图像质量评级界面如图4所示。我们测试中的查看条件符合ITU建议[40]。主观体验是在正常室内光线条件下的实验室中使用两台监视器进行的。一台显示器配置高清分辨率(1920 1080),另一台配置4k分辨率(3840 2160)。所有的图像都以原来的分辨率显示,因此没有额外的失真。照射到屏幕上的入射光是80勒克斯,从监视器后面的环境照明是240勒克斯。所有的观察者都需要坐在四倍于图像高度的观看距离。表二总结了测试条件和参数配置的主要信息。

- 在开始测试之前,所有的观察者都要接受一次培训。在培训课程中,我们会提供一些具有代表性的质量水平的例子。这些示例不包括在测试阶段。观察者被告知主要考虑三个方面来评估他们的质量:内容识别度、清晰度和观看舒适度[31]。内容可识别性用于检查是否可以识别自然夜间图像的内容。内容清晰度用于判断图像的损伤外观。观看舒适度反映了观看者的观看体验。
C. Processing of Raw Data
- 在收集所有观察者的原始评分后,我们进一步处理它们,以获得每个夜间图像的最终平均意见评分(MOS)。处理过程包括异常点检测和观察者抑制,这里采用了一种简单有效的方法,[31],[41],[42]也采用了这种方法。
- 在离群值检测中,如果一个原始评级分数超出其置信区间,则认为它是离群值。具体来说,对于每一幅图像,首先计算主观评分的平均值
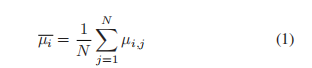
式中,μi,j为观察者j对图像i的主观评分,N为观察者总数。然后,计算标准差为:
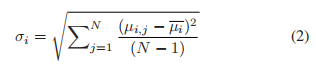
当置信区间设置为95%时,图像i的置信区间定义为[μi−δi,μi+δi],其中δi=1.96∗σi√N。
- 在观察者拒绝中,如果一个观察者的丢弃评级分数的数量超过离群点检测的阈值R,那么该观察者的所有质量评级都将被拒绝。R由

其中NI表示每个观测者打分的图像数量,OC是下面定义的异常值系数,它量化了数据库的主观一致性
其中NO表示所有观察者的异常值个数,NT表示所有观察者的评分总分。通过这个计算,我们的实验中R = 16,拒绝了4个观察者。
D. Analysis of MOS
-
一般来说,NNID数据库中图像的MOS值应该表现出良好的感知质量分离,并且覆盖了整个视觉质量范围(从差到优)[31],可以作为客观质量指标性能评估的基础真理。
-
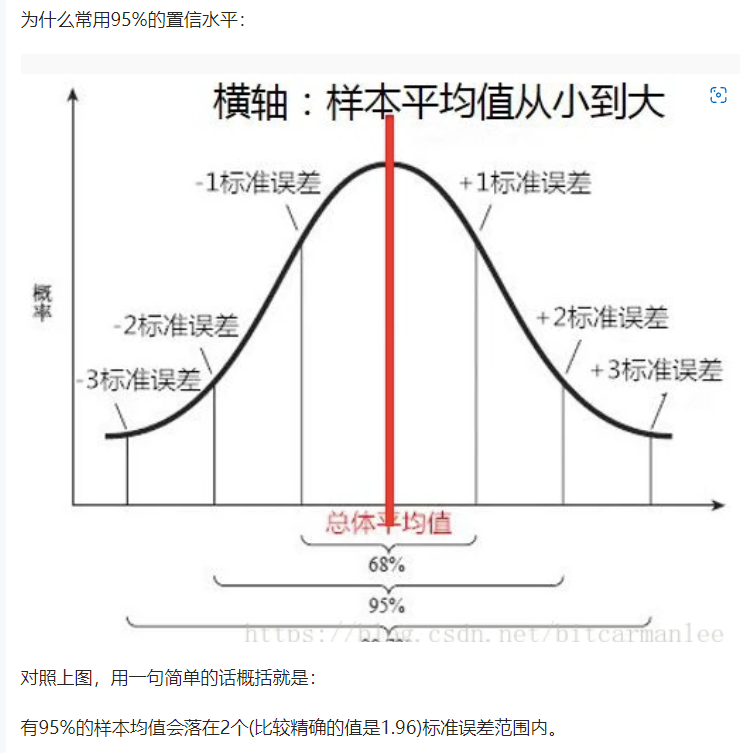
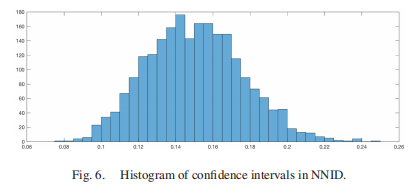
在图5中,我们展示了NNID数据库中所有MOS值的直方图分布。我们可以观察到MOS值跨越了整个视觉质量量表[0,1],在不同的视觉层次上有较好的传播。此外,MOS值的分布也表明了构建的NNID数据库中图像的多样性。此外,我们评估所有观察者之间的一致性,由每个图像[40]评分的均值和标准差得出的95%置信区间来衡量。置信区间分布如图6所示。可以看出,置信区间主要分布在0.12 - 0.18之间。这是一个有用的证据,表明所有观测者在评价NNID数据库中夜间图像的视觉质量方面有很高的一致性。
-
图7为不同设备采集图像MOS值的箱线图。Device-I和Device-II捕捉到的图像MOS值大部分在[0,1]范围内,Device-III捕捉到的图像MOS值在[0,0.6]范围内。这是因为Device-I和Device-II是高端设备,而Device-III是低端相机,拍摄的图像视觉质量较差,噪声过大。这个观察结果证实了我们的主观测试和他们的事后分析的结果。

THE PROPOSED BNBT METRIC
在本节中,我们提出了基于亮度和纹理特征(BNBT)的盲夜间图像质量评估指标。首先,我们介绍了该方案的基本思想和框架。然后,我们详细描述了我们提出的BNBT的三个主要部分,即亮度特征提取、纹理特征提取和预测模型回归。
A. Basic Idea
-
该方法的基本概念是通过提取对可视化至关重要的视觉特征来测量夜间图像的质量程度,这些特征在弱光照环境下仍然可以保存。
-
由于夜间图像通常表现为对比度低、细节模糊和能见度降低,其视觉质量评价指标应具有测量不同质量夜间图像之间视觉特征变化的能力。基于人眼视觉的心理视觉特性,亮度和纹理是夜间图像最重要的两个视觉特征。
-
首先,亮度信息在视觉感知中是最重要的,特别是对于弱照明的夜间图像。例如,在夜间图像采集中,曝光时间过短或过长可能导致图像较暗或较亮;亮度决定了图像的基本质量水平。
-
其次,纹理信息对夜间图像的视觉质量也有重要意义,因为它包含了视觉内容的细节。给定相同的亮度信息,纹理信息作为失真强度的附加指标。因此,结合亮度和纹理信息,我们可以评估夜间图像的视觉质量。
B. Framework
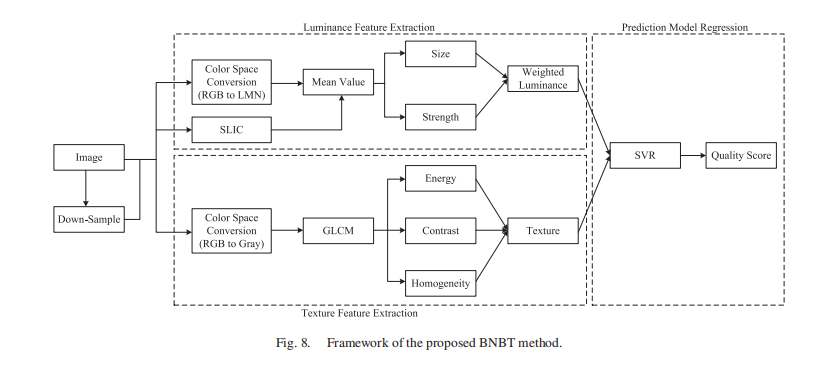
- 在介绍了我们的基本思想后,我们现在提出了一种基于亮度和纹理特征的盲夜间图像质量评估指标(BNBT)。我们提出的BNBT框架如图8所示。简而言之,我们的方案工作原理如下。首先,我们从感知颜色空间中通过计算超像素上的平均值来提取夜间图像的亮度信息,并精心设计加权亮度特征。
- 然后,利用灰度共生矩阵(GLCM)提取夜间图像的纹理特征。在两个尺度下同时计算亮度和纹理特征,以减小观察距离和图像分辨率的变化。最后,我们将亮度和纹理特征结合到支持向量回归(SVR)中,模拟从特征空间到客观质量评分的非线性映射。在本节的后续语句中,我们将详细描述这三个过程。
C. Brightness Feature Extraction
3. 我们首先提取夜间图像的亮度特征,因为它在弱照明的夜间图像的视觉感知中是最重要的。
4. 传统的IQA方法通常将图像划分为不重叠的块,并从这些块[25],[27]中提取相应的视觉特征。该方法便于特征计算,但与视觉感知不一致。图像内容通常包含在不同的区域,对视觉质量有不同的影响,但这些区域的形状通常不是矩形,不能完全被块覆盖;因此,图像块及其提取的特征对于视觉感知通常是没有意义的。
5. 为了解决这一问题,我们在感知相似的像素上提取亮度特征,以创建视觉上有意义的区域。具体地说,一个超像素是由空间上相邻的共享类似低级特征(如颜色、强度或结构)的像素组成的。基于这一特性,超像素受到了广泛的关注,并被广泛应用于图像分解[44]、多感官视频融合[45]、图像合成[46]等视觉任务中。
6. 本研究采用了一种计算效率高的超像素分割算法——简单线性迭代聚类(SLIC)[47]。SLIC是k-means聚类的一种改编,可以显示图像的边界坚持性。SLIC首先初始化一些簇中心(Nc),然后根据预定义的距离度量将每个像素分配到最近的中心。然后,每个聚类中心由其对应元素的均值属性更新。最后,通过重复上述步骤生成超像素。我们以图9中SLIC算法生成的超像素为例,展示了具有超像素的图像区域的特性,其中簇中心数Nc = 400。

- 由于从图像亮度通道提取的亮度特征不能很好地表征颜色畸变,因此我们同时考虑亮度通道和色度通道。我们通过SLIC算法获取夜间图像的超像素段后,将图像的RGB颜色空间转换为LMN颜色空间[48],计算其亮度特征。LMN颜色空间在物理基础上定义良好,在HVS[49]上进行优化,转换可以消除亮度分量(L)和色度分量(M, N)之间的相关性
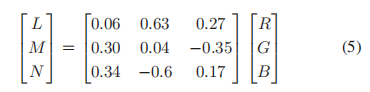
- 经过颜色空间转换后,我们计算每个通道L、M、n上的亮度特征,不失一般性,我们以L通道为例。假设SLIC方法将一幅夜间图像划分为η超像素;我们首先计算每个超像素的平均强度
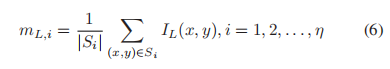
其中IL(x, y)为通道L坐标(x, y)处的像素值,Si为第i个超像素的坐标集合,|Si|为Si中的元素个数。 - 然后我们建议使用基于排序的加权函数来对亮度强度进行加权。利用每个超像素的平均值来生成权值。其中,超像素的均值mL,i按升序排序。设排序后的排序索引为Rank_i;定义超像素的权值为
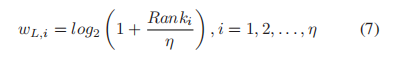
自从Ranki 1,2…,η时,很容易知道wi[0,1],且超像素的均值越大,权重越大。 - 最后,得到通道L上的亮度特征
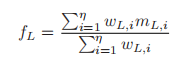
同样,我们可以得到M和N通道上的另外两个亮度特征fM和fN
D. Texture Feature Extraction
-
除了亮度特征,我们还考虑了纹理特征,因为它是人类视觉感知不可或缺的元素,是预测夜间图像质量的必要因素。夜间图像受光照限制,通常具有对比度低的特点。在这种情况下,可以用纹理来描述的图像细节的视觉感知与图像质量密切相关。因此,在评价夜间图像质量时考虑纹理特征是合理的。
-
利用灰度共生矩阵(GLCM)[50]提取纹理特征。GLCM是一种著名的描述纹理的方法,通过测量一定距离内像素之间特定的空间相关属性。给定大小为m *n的图像I, GLCM定义如下

其中(x, y)是I中的空间坐标,(Δx, Δy)是偏移量。 -
我们通过计算GLCM的能量fe、对比度fc和均匀性fh来描述图像的纹理特征。
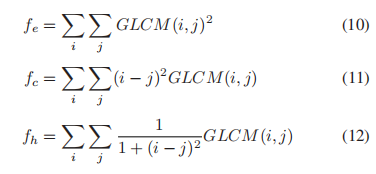
式中fe, fc, fh属于[0,1]。能量度量图像中的信息量,表示图像的复杂度,fe = 1表示图像是一个常数。对比度度量整个图像上一个像素与其相邻像素之间的强度对比度。同质性度量了GLCM元素分布的对角线的空间接近程度,当GLCM为对角线矩阵时,同质性达到最大值。 -
然后,通过计算能量(fe, fδe)、对比度(fc, fδc)和均匀性(f h, fδh)特征的均值和标准差得到纹理特征。总共可以从一幅夜间图像的尺度中提取六种纹理特征。
E. Prediction Model Regression
- 我们从图像的两个尺度中提取亮度和纹理特征后,采用SVR[51]学习从特征空间到质量测度值的映射函数,进行特征池化。请注意,传统的深度学习方法不适合我们的工作,因为它们需要大量的数据样本进行训练,但我们在这里只提取了18个特征(9个特征,fL, fM, fN, fe, fδe, fc, fδc, f h, fδh,在每个尺度上)。
- 考虑一组训练数据D = {(xi, yi)|i = 1,…,r},其中r为图像个数,xi R18为提取的特征,yi为对应的MOS值。设参数为t >0和p >0;我们可以得到SVR的标准形式为
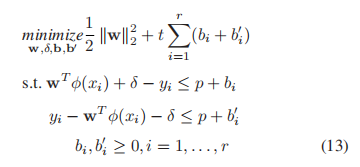
其中,K(xi,xj)=φ(xi)Tφ(xj)为核函数。我们使用径向基函数(RBF)核,它被定义为K(xi,xj)=exp(−k||xi−xj||2)。基于训练样本,我们的目标是确定参数t、p和k,从而找到相关的回归模型。
Statistical Significance Comparison
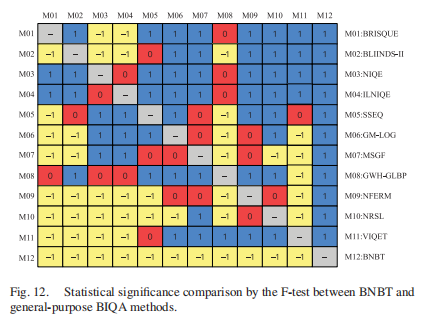
- 统计显著性检验是一种从样本数的角度对不同IQA指标的性能作出定量说明的方法。当只测试少量图像时,一个IQA指标可能在统计上较差,而另一个IQA指标在数千张图像上测试时可能在统计上较差。采用基于方差假设检验的f -检验[41]来衡量各客观度量标准之间的差异是否具有统计学意义,从而对各客观度量标准的优劣进行统计判断。该检验衡量预测的客观得分(非线性拟合后)与主观得分(MOS)之间的残差的高斯性,目的是确定这两个集合是否来自同一个分布。在我们的实验中,如果预测残差的峰度在2到4之间,则认为它们具有高斯性。
- 图12和图13分别给出了我们所提出的BNBT和现有的通用和对比度失真BIQA方法在NNID数据库上的假设检验结果。这两个图中(i, j)的符号为1表示第i行度量在统计上优于第j列度量,符号为-1表示第i行度量在统计上不如第j列度量,0表示这两个度量在统计上是不可区分的。为了方便查看,我们还用不同的颜色填充了不同值的单元格。从图12和图13可以很容易地发现,在NNID数据库上,所提出的BNBT指标的性能在统计上优于所有被认为是现有的最先进的BIQA方法,无论它们是通用的还是对比度失真的。

夜间图像Blind quality assessment of night-time image
引言
- 到目前为止,提出的夜间图像的 BIQA 方法非常有限。在[34]中,向等人提出了第一个夜间图像的BIQA模型。具体来说,作者利用亮度和纹理特征来表征图像质量下降。亮度特征是在超像素上计算的,这些超像素聚集不同的像素值并生成视觉上有意义的部分。从夜间图像的灰度共生矩阵(GLCM)计算纹理特征。SVR用于整合亮度和纹理特征以得出图像质量得分。
- 在本文中,为了进一步促进夜间图像质量评估,我们建立了一种新颖的 BIQA 模型来更有效地评估夜间图像质量。由于人脑从初步感觉到高级语义理解的图像质量感知[35],我们通过表征初步感觉和语义理解来评估图像质量。具体来说,在初步感觉中,人脑感知图像基本属性以进行质量评估,例如亮度、噪声、锐度等[11],[13]. 相应地,我们提取了一系列质量感知特征来表示亮度、噪声、锐度和对比度来表征图像质量。为了模拟语义理解过程,我们利用深度神经网络提取夜间图像的高级语义特征,表征图像语义对于质量感知。在提取质量感知特征后,我们将它们输入 SVR 并学习盲质量模型来推断图像质量。在这里,我们将我们提出的方法命名为 Blind Night-time Image Quality Measure (BNIQM)。在具有代表性的夜间图像质量数据库上进行的实验结果表明,所提出的 BNIQM 优于最先进的通用 BIQA 方法和专用的夜间图像质量测量方法[34]。
方法
在我们提出的方法中,我们提取质量感知特征来表征在质量评估的初步感觉和语义理解。
初步感觉的表征
在初步质量感知中,人脑感知图像的低级属性,如亮度、饱和度、锐度、噪声、对比度等[13]、[29]、[22]。因此,我们首先表征夜间图像的这些低级属性以进行质量评估。
亮度测量
-
夜间拍摄的图像经常出现亮度低或不均匀的问题,从根本上影响图像质量。因此,我们首先检查夜间图像亮度。具体来说,给定夜间图像I,我们通过以下方式将其转换为灰色版本:
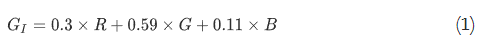
其中GI为I对应的灰度图像,R、G、B分别代表I的红、绿、蓝通道,我们取GI的均值来评价夜间图像的整体亮度,记为

其中μ为I的整体亮度,N为I的像素总数。 -
亮度不均匀性是影响夜间图像质量的另一个重要因素。夜间图像的一个典型情况是,夜间图像中可能存在一些高强度的光源,导致局部亮度过高,从而导致视觉质量低下。我们在图1中给出了一个例子,它取自夜间图像数据库[34]。可以清楚地观察到,图像底部存在强光,导致亮度不均,因此平均评价分数(MOS)值仅为0.44左右。因此,我们进一步计算夜间图像的亮度均匀性来进行质量评价。为此,我们将灰色夜间图像分成大小为m* m的patch (m根据经验取64)。对于每个图像块,我们计算其平均亮度值,表示为v。然后我们计算所有得到的平均亮度值的标准差来表示图像的亮度均匀程度,定义为:

其中h表征图像亮度均匀性,M是图像块的数量,是所有平均亮度值的平均值。

饱和度测量
- 图像的饱和度描述了人类视觉系统如何自然地响应颜色信息。过饱和或欠饱和会使图像看起来不自然、不逼真,从而降低视觉质量。对于夜间拍摄的图像,由于光照较弱,它们往往会出现饱和度不足的情况。为了表征夜间图像的饱和度,我们将图像从 RGB 颜色空间转换为 HSV 颜色空间,其中可以明确评估图像的饱和度。根据 RGB 空间到 HSV 空间的变换,可以推导出饱和度通道为:
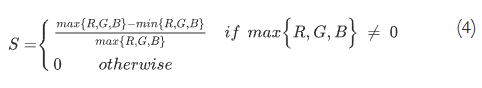
其中S是指饱和通道。然后我们计算S的平均值来评估夜间图像的整体饱和度,描述为:

其中s是指饱和度指数,N是夜间图像中的像素总数。
锐度测量

噪声测量
噪声是在初步视觉知觉[15]中感知到的另一种低水平图像属性。夜间图像很容易受到噪声的影响,这些噪声表现为光滑表面上的随机斑点,导致图像质量严重下降。图像的噪声水平通常取决于曝光的长度、物理温度和数码相机感光元件的灵敏度。如[41]所示,对于干净的图像,其边缘滤波器响应分布的峰度值为未知常数,该值会随着引入的噪声而改变。这些统计数据可以用来评估噪声图像的噪声水平。
对比度测量
-
对比度是一个场景中明亮和昏暗区域之间亮度差异的度量,使图像显示更多的细节。由于采集夜间图像时亮度不足,获取的图像经常存在对比度低的问题。在图像处理中,直方图均衡化方法通过调整图像的直方图分布来增强图像的对比度。
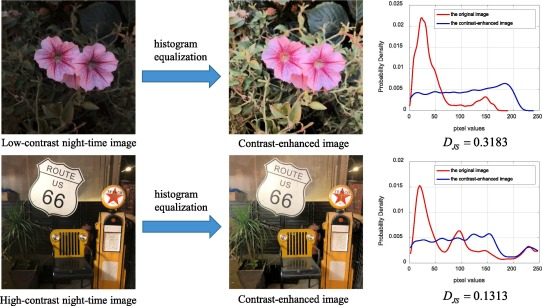
图 2。原始夜间图像及其对比度增强图像的直方图分布比较。 -
对于低对比度的图像,直方图均衡化会对其直方图进行较大的修改,以增强其对比度。因此,原始图像与增强图像直方图分布之间的距离是衡量图像对比度的有效方法。为了说明这一点,在图2中,我们从夜间图像数据库[34]中选取了两幅对比度不同的图像,分别用直方图均衡化进行增强。右侧是原始图像和增强后图像的直方图分布。从图中我们可以看到,对于低对比度图像,其直方图分布与增强后的图像在视觉上的差异要大于高对比度图像。同时,我们使用Jensen-Shannon (J-S)散度来量化直方图分布之间的距离,这是一种被广泛采用的测量两个概率分布之间统计差异的方法,我们将其表示为dj。低对比度图像的DJS值为0.3183,也大于高对比度图像的0.1313。在以上分析的基础上,我们利用dj对夜间图像的对比度进行表征。假设u和v分别为夜间图像及其增强图像的直方图分布,则u和v之间的J-S散度可定义为
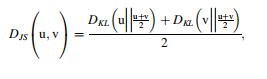
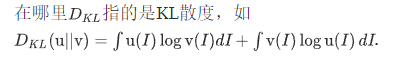
语义特征提取 -
在质量评价中忽略语义可能会导致一些矛盾的结果,如对晴空的质量评分较低,这与主观质量评价[24]不一致。因此,我们进一步表征了用于夜间图像质量评估的图像高级语义。
-
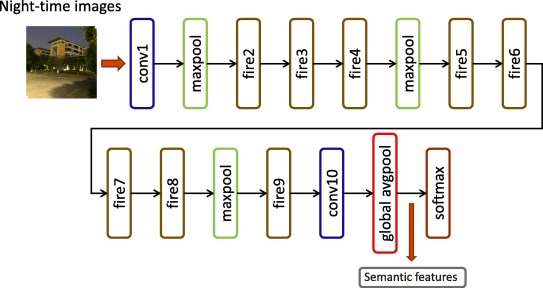
一种比较流行的提取图像语义的方法是将图像输入到预先训练好的深度神经网络(DNN)中,并将顶层的输出作为语义特征[ 43 45]。在本文中,我们也采用这种方法提取了夜间图像的语义特征。Squeezenet[42]被选择为我们的默认DNN模型。SqueezeNet的结构如图3所示,其中消防模块由挤压层和扩展层组成。由于SqueezeNet接收的图像大小为227* 227作为输入,我们提取227* 227的中央patch,并将其输入到SqueezeNet中。然后将全局顶级avgpool层的输出作为1000维向量作为质量评估的语义特征。
质量评估
- 对于提取的质量感知特征,我们需要学习一个回归函数来将特征映射到最终的图像质量分数[46,47]。为此,我们采用著名的SVR来实现这一目标。具体来说,给定训练数据集{(x1,s1),(x2,s2),,(xk,sk)},其中xk和sk为训练数据集中第k个样本的特征向量及其相关的主观质量分数。我们期望学习一个函数f(),它用质量特征向量x来预测图像质量得分,写成


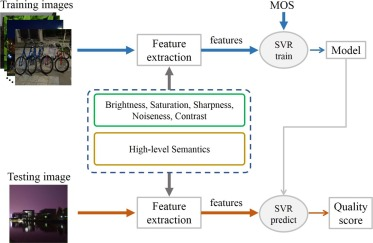
图 5。所提出的夜间图像BIQA方法的总体框架。样本图像取自夜间图像数据库[34]。