爬取手机壁纸
1. 准备工作
1.1 环境
python3.9
1.2 用到的库
requests、re
1.3 爬虫的过程分析
当人类去访问一个网页时,是如何进行的?
①打开浏览器,输入要访问的网址,发起请求。
②等待服务器返回数据,通过浏览器加载网页。
③从网页中找到自己需要的数据(文本、图片、文件等等)。
④保存自己需要的数据。
对于爬虫,也是类似的。它模仿人类请求网页的过程,但是又稍有不同。
首先,对应于上面的①和②步骤,我们要利用python实现请求一个网页的功能。
其次,对应于上面的③步骤,我们要利用python实现解析请求到的网页的功能。
最后,对于上面的④步骤,我们要利用python实现保存数据的功能。
因为是讲一个简单的爬虫嘛,所以一些其他的复杂操作这里就不说了。下面,针对上面几个功能,逐一进行分析。
2. Python如何请求网页?
2.1 requests库
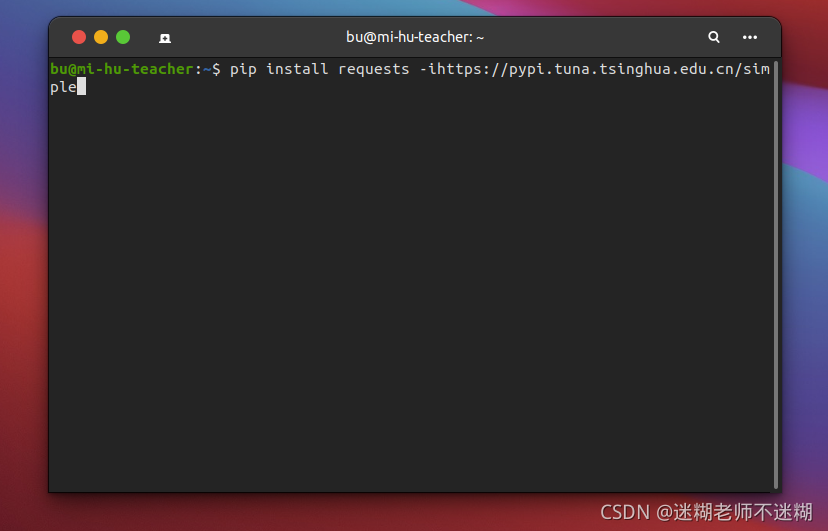
安装requests库
通过python自带的库pip下载requests库
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple #-i 设置下载源
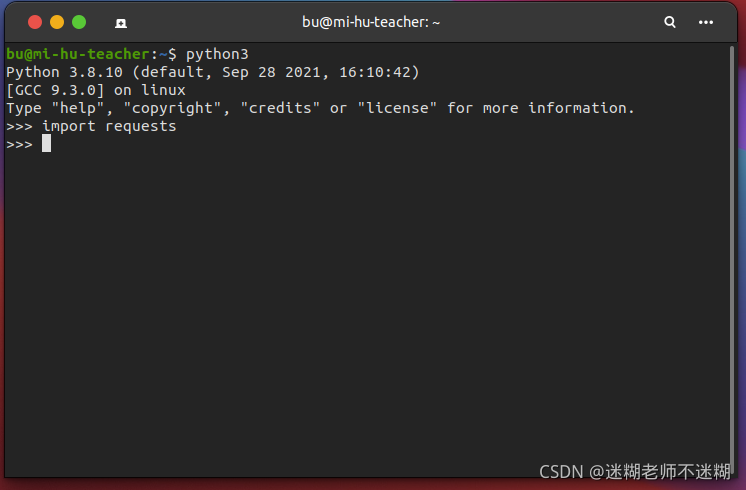
2.1.2 测试是否安装成功
在命令行中输入python,敲击回车,进入python交互环境。在里面输入以下代码并回车:
import requests
3. 开始吧
3.1 将我们用到的库引入一下
import requests
import re
3.2 使用requests请求网页
url = "https://www.3gbizhi.com/tag/dongman/1.html" #网站地址
resp = requests.get(url) #请求网页
print(resp.text) #输出获取的网页源码
3.3 使用re进行正则表达式过滤获取子页面
obj = re.compile(r'https://www.3gbizhi.com/wallDM/.*.html',re.S) #正则匹配
url_list = obj.finditer(resp.text) #找出所有符合标准的的内容
利用for循环提取出网页中的所有url
for i in url_list:page_url = i.group()print(page_url) #输出匹配到的内容
3.4 再次请求网页的子页面
resp2 = requests.get(page_url) #请求子页面
print(resp2.text) #输出网页源码
使用正则匹配出他的图片名和图片地址
obj2 = re.compile(r'<title>(?P<img_name>.*?)</title>') # 图片名字
for i in obj2.finditer(resp2.text)file_name = i.group("img_name")
obj3 = re.compile(r'<div class="morew">.*?<a href="(?P<url>.*?)"',re.S) #图片地址
for i in obj3.finditer(resp2.text)img_url = i.group("url")
3.5 最后请求图片地址然后保存到文件夹就完成了
resp3 = requests.get(img_url)
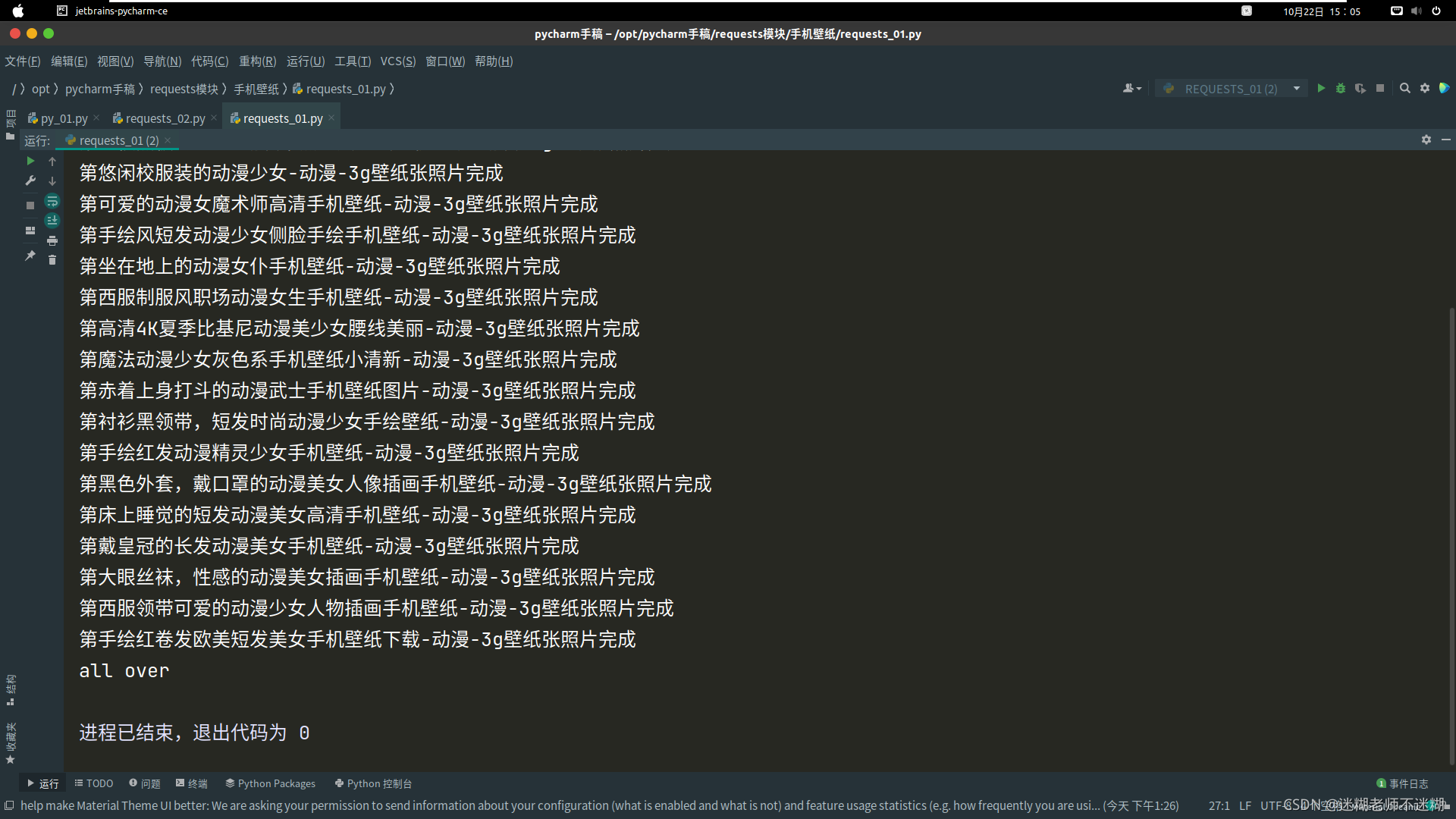
with open("Images/"+file_name+".jpg","wb")as f:f.write(resp3.content)f.close()print(f"第{file_name}张照片完成")
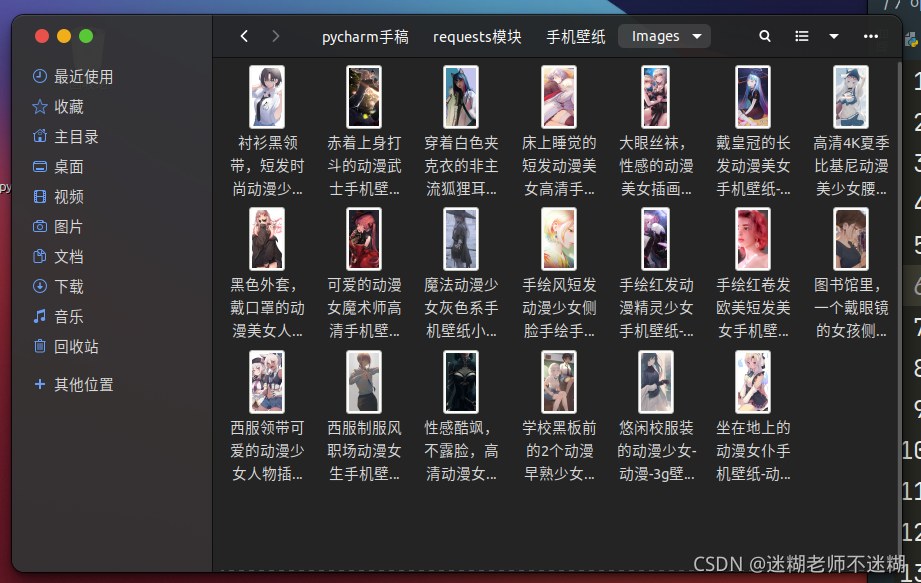
3.6 成果图