- 忽略警告: warnings.filterwarnings("ignore")
import warnings
warnings.filterwarnings("ignore")- 读取文件格式: pd.read_csv(train_data_file, sep='\t') # 注意sep 是 ',' , 还是'\t'
- train_data.info() # 查看是否存在空数据及数据类型
- train_data.describe() # 查看数据分布
- 删除无关特征: train_data_drop = train_data.drop(['V5','V9','V11','V17','V22','V28'], axis=1)
- 获取特征相关性: train_corr = train_data_drop.corr()
- 同时删除训练数据和测试数据分布不均匀的特征:
- train_data.drop(drop_col_kde,axis = 1,inplace=True)
- all_data.to_csv('./processed_zhengqi_data.csv',index=False) # 保存数据
工业蒸汽量预测
项目描述
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
天池官网链接: 工业蒸汽量预测_学习赛_天池大赛-阿里云天池
第一部分 数据探索
1.1 导入数据探索工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
1.2 加载数据
- csv是 txt 格式 .
train_data_file = "./zhengqi_train.txt"
test_data_file = "./zhengqi_test.txt"train_data = pd.read_csv(train_data_file, sep='\t')
test_data = pd.read_csv(test_data_file, sep='\t')
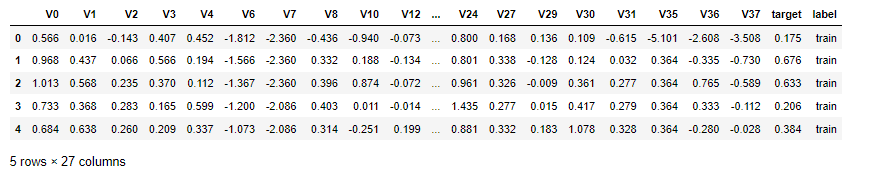
train_data.head()1.3 查看数据集变量信息
1.3.1 查看数据集字段信息
test_data.head() # 查看开始部分的数据信息

1.3.2 查看详细数据信息
测试集数据共有1925个样本,数据中有V0-V37共计38个特征变量,变量类型都为数值类型。
train_data.info() # 查看数据详情
1.3.3 查看数据统计信息
train_data.describe() # 查看数据分布 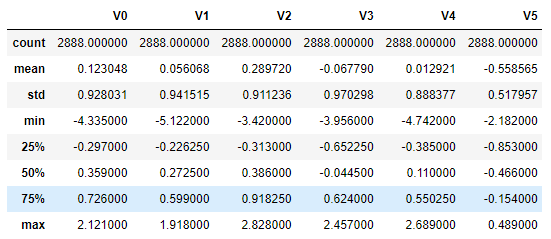
1.3.4 箱式图数据探索
fig = plt.figure(figsize=(6, 4)) # 指定绘图对象宽度和高度
sns.boxplot(train_data['V0'],width=0.5)
plt.savefig('./2-特征箱式图.jpg',dpi = 200)# 画箱式图
column = train_data.columns.tolist()[:39] # 列表头fig = plt.figure(figsize=(20, 60)) # 指定绘图对象宽度和高度
for i in range(38):plt.subplot(13, 3, i + 1) # 13行3列子图sns.boxplot(train_data[column[i]], width=0.5) # 箱式图plt.ylabel(column[i], fontsize=8)箱型图的作用:
- 直观明了地识别数据批中的异常值
- 利用箱线图判断数据批的偏态和尾重
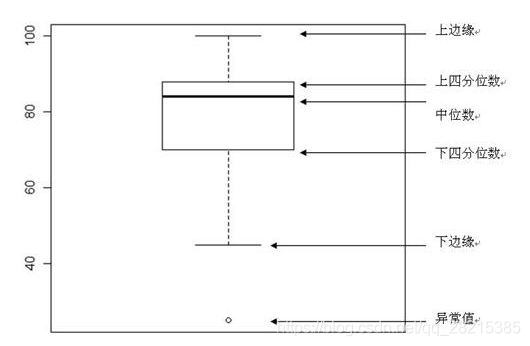
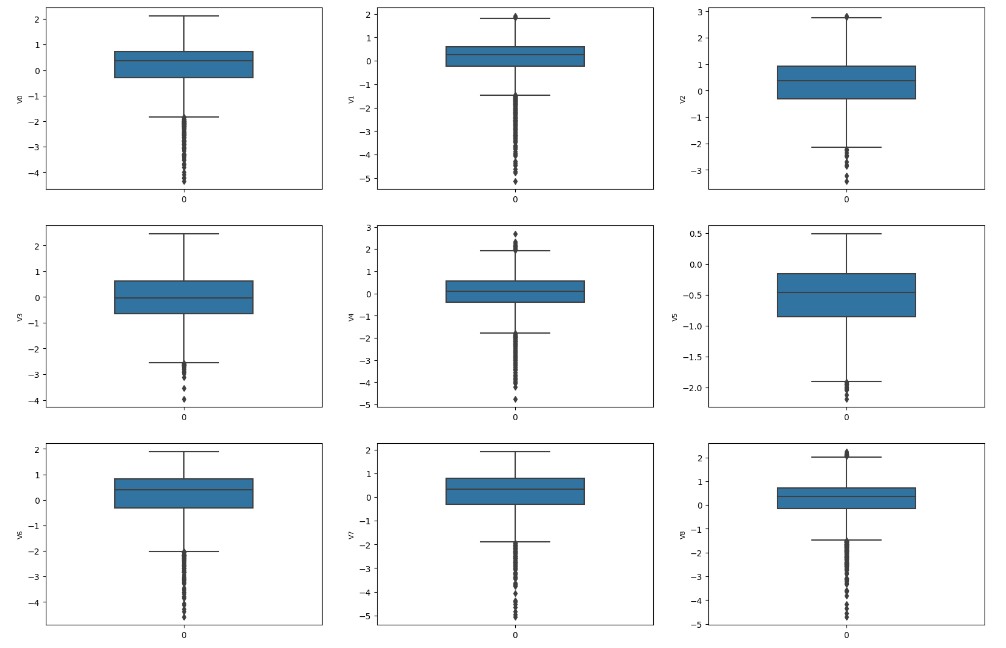
1.4 数据分布查看
- sns.kdeplot() 查看训练数据和测试数据的对比, 是否分布一致 .
dist_cols = 6
dist_rows = len(test_data.columns)//6 + 1plt.figure(figsize=(4*dist_cols,4*dist_rows))i=1
for col in test_data.columns:ax=plt.subplot(dist_rows,dist_cols,i)ax = sns.kdeplot(train_data[col], color="Red", shade=True)ax = sns.kdeplot(test_data[col], color="Blue", shade=True)ax.set_xlabel(col)ax.set_ylabel("Frequency")ax = ax.legend(["train","test"])i+=1
查看指定特征(查看特征'V5', 'V17', 'V28', 'V22', 'V11', 'V9'数据的数据分布):
col = 3
row = 2
plt.figure(figsize=(5 * col,5 * row))
i=1
for c in ["V5","V9","V11","V17","V22","V28"]:ax = plt.subplot(row,col,i)ax = sns.kdeplot(train_data[c], color="Red", shade=True)ax = sns.kdeplot(test_data[c], color="Blue", shade=True)ax.set_xlabel(c)ax.set_ylabel("Frequency")ax = ax.legend(["train","test"])i+=1
plt.savefig('./4-数据分布.jpg',dpi = 200)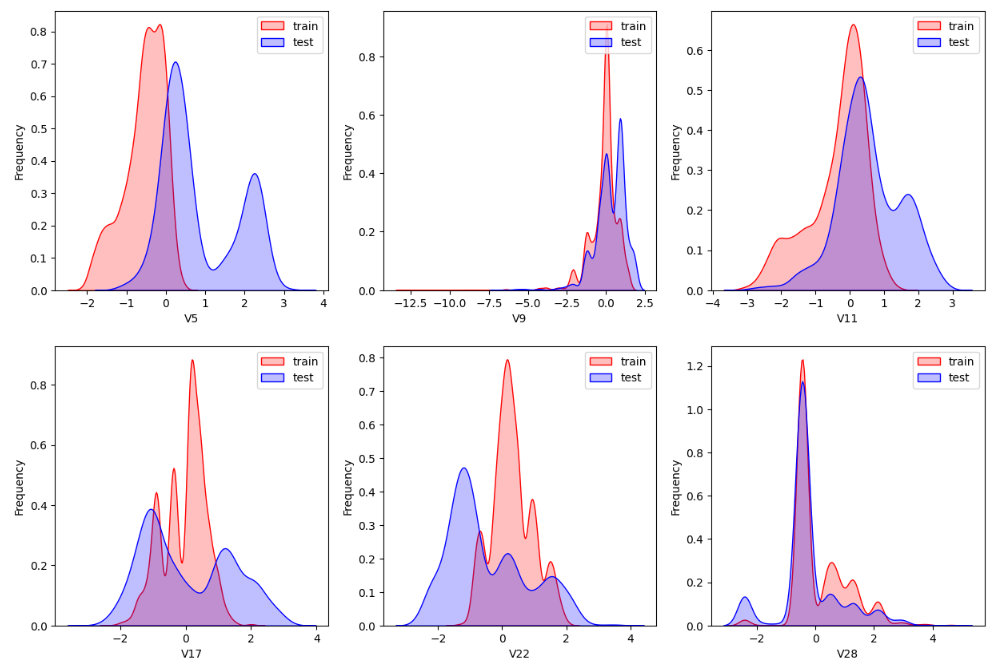
1.5 特征相关性
- train_corr = train_data_drop.corr() # 求取数据的相关性系数
drop_col_kde = ['V5','V9','V11','V17','V22','V28']
train_data_drop = train_data.drop(drop_col_kde, axis=1)
train_corr = train_data_drop.corr()
train_corr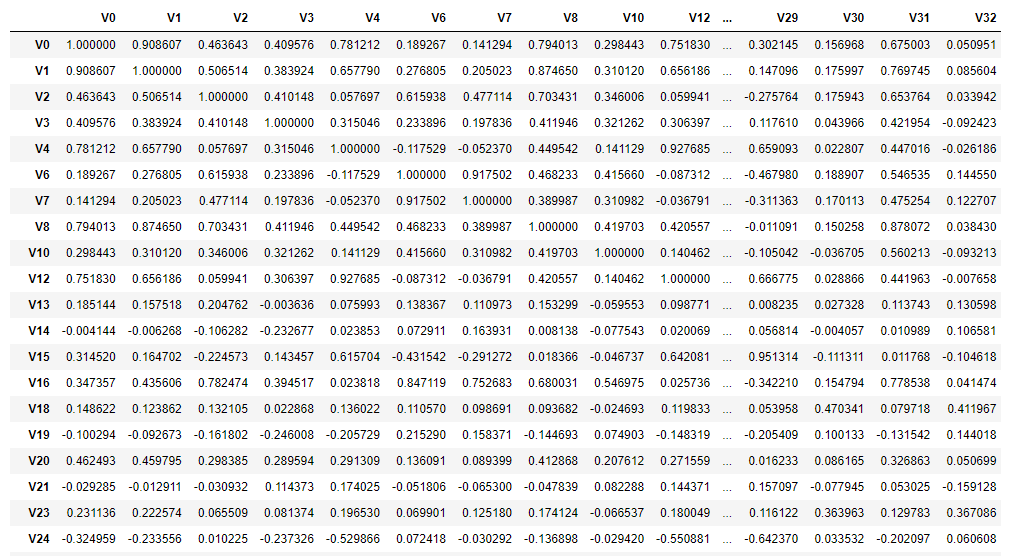
1.5.1 热力图 (相关性显示)
- ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True) # 根据相关系数画热力图
# 画出相关性热力图
ax = plt.subplots(figsize=(20, 16))#调整画布大小
# 画热力图 annot=True 显示系数
ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True)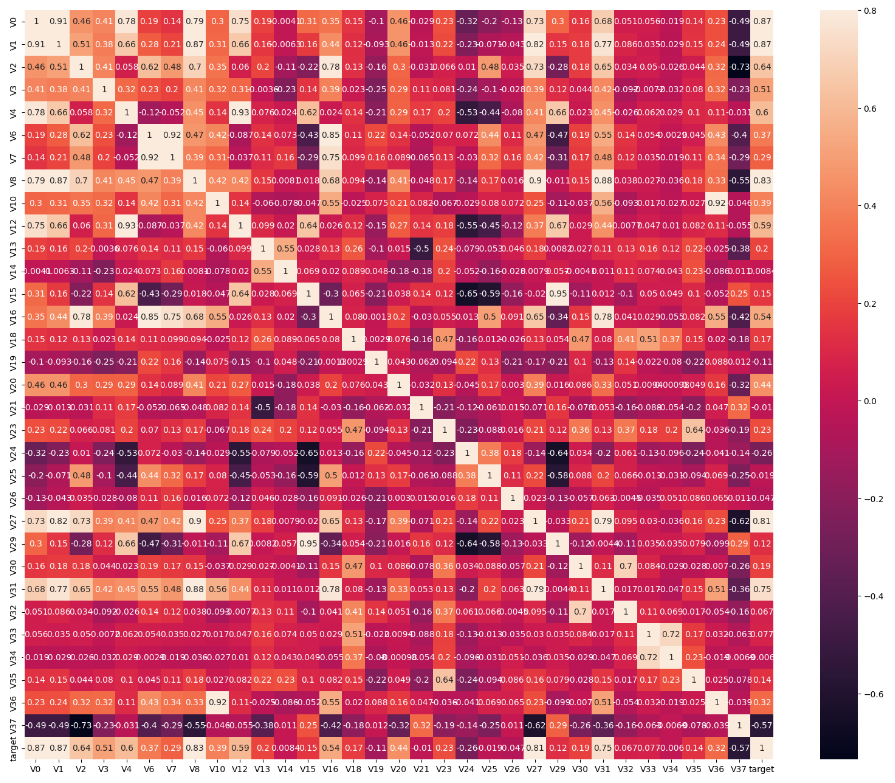
左下角热力图:
- mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
- mask[np.triu_indices_from(mask)] = True # 角分线右侧为True,右上角设置为True
- sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, fmt='0.2f') # 画热力图
plt.figure(figsize=(24, 20)) # 指定绘图对象宽度和高度
colnm = train_data_drop.columns.tolist() # 列表头
# 相关系数矩阵,即给出了任意两个变量之间的相关系数
mcorr = train_data_drop.corr()# 构造与mcorr同维数矩阵 为bool型
mask = np.zeros_like(mcorr, dtype=np.bool) # False# 角分线右侧为True,右上角设置为True(戴面具,看不见)
mask[np.triu_indices_from(mask)] = True# 设置colormap对象,表示颜色
cmap = sns.diverging_palette(220, 10, as_cmap=True)# 热力图(看两两相似度)
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f')
plt.savefig('./5-特征相关性.jpg',dpi = 400)
1.6 特征筛选
1.6.1 根据数据分布进行特征删除
- 根据数据分布判定是否删除 , 根据前方的显示图对比
# 删除训练数据和预测数据 分布不均匀,不够正太分布的特征
train_data.drop(drop_col_kde,axis = 1,inplace=True)
test_data.drop(drop_col_kde,axis = 1,inplace= True)
train_data.head()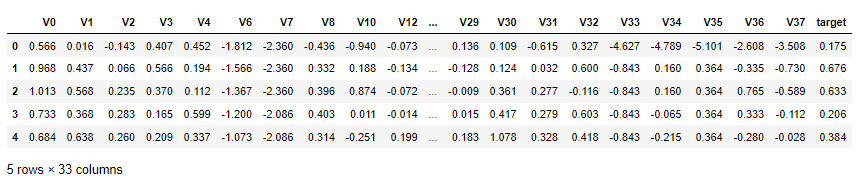
1.6.2 根据相关性系数进行特征筛选
- cond = mcorr[ 'target' ].abs() < 0.1 # 根据相关性判定
- drop_col_corr = mcorr.index[ cond ]
cond = mcorr['target'].abs() < 0.1
drop_col_corr = mcorr.index[cond]
display(drop_col_corr) # ['V14', 'V21', 'V25', 'V26', 'V32', 'V33', 'V34']# 删除
train_data.drop(drop_col_corr,axis = 1,inplace=True)
test_data.drop(drop_col_corr,axis = 1,inplace=True)display(train_data.head())
1.7 数据保存
- train_data[ 'label' ] = 'train' # 添加标签
- data.to_csv(./data.csv, index=False)
train_data['label'] = 'train'
test_data['label'] = 'test'all_data = pd.concat([train_data,test_data])
all_data.to_csv('./processed_zhengqi_data.csv',index=False)
all_data.head()